







【系列目录】本系列所有文件分章节内容的目录文章请参考:【源码研读系列】目录
【实验代码】本系列所有实验设计的源码都以上传 Gitee码云和GitCode 平台。GitCode代码项目地址:GitCode;在Gitee主页搜索“机器白学”,所有项目中的“YOLO源码实验”就是本系列所有实验代码。Gitee代码项目地址:Gitee
【前情回顾】在之前的本系列博文中,首先记录了关于YOLO项目中各种配置 cfg 参数是如何设置和加载的——博文链接:cfg配置,然后用多篇文章记录了YOLO项目源码中的 data 目录下的代码文件,这是YOLO处理数据的地方,其中包括对数据的增强、训练迭代数据加载等操作——起始博文地址:data数据处理
【本节预告】在理解了ultralytics 官方设计的参数cfg配置和数据预处理加载后,终于进入了整个YOLO项目中最核心的代码部分之一:“模型引擎”——engine源码文件。
engine文件夹下包含了YOLO的模型接口(Python api使用:model.py)、模型的训练器(trainer.py)、验证器(validator.py)、预测器(predicator.py)、导出模型(exporter.py)、模型输出结果格式化(results.py)。YOLO所有功能都是继承engine文件夹下的基类实现的。可以将该文件夹下的内容理解为YOLO项目的地基,所有任务所有模式都是在此基础上的扩展。
本节记录的 model.py 文件是整个模型引擎的“骨干类”,统领所有的训练、验证、预测等操作,定义了所有流程逻辑方法并支持多种任务模式(检测、语义分割、分类、追踪等)、多种模型参数文件来源(如.yaml的配置文件,.pt或.pth的pytorch训练保存结果文件等)以及在训练过程中对模型网络层参数的一些操作。
注意到的是,在model.py中定义的 Model 类也是一个基类(和之前文章中介绍的BaseDataset 基类一样),可以定制其中一些方法(就本类而言,需要定制task_map方法,这在之后的YOLO类可以看到),支持很好的扩展性。
目录
5._smart_load 和 task_map:便捷加载实例
一、model.Model类
编写在 model.py 下的 Model 类是实现YOLO多任务、多模型加载的基类,其统一不同模型参数类型的API。此类为与YOLO模型相关的各种操作提供了一个通用接口,如训练、验证、预测、导出和基准测试。支持加载不同参数来源的模型,包括从本地文件、Ultralytics HUB或Triton Server加载的模型。
1.继承基类:nn.Module
首先,看源码可知,Model类的定义是建立在 Torch 库中的 nn.Module 基类上的。在开始分析此类前,先简单介绍记录一下 nn.Module 这个pytorch中的重要类。

nn.Module 简介:是 PyTorch 中的一个基础类,用于构建神经网络模型。所有自定义的神经网络模型都应该继承这个类,借此实现模型的构建、训练、评估等功能。
为什么要使用 nn.Module
模块化设计——通过继承 nn.Module,模型变得更加模块化,便于管理和扩展;自动管理参数——nn.Module 会自动将所有的层和参数(如权重和偏置)注册为模型的子模块,从而可以方便地进行训练(例如自动计算梯度、优化器的更新等);简化代码——nn.Module 提供了很多有用的功能,如参数初始化、设备管理(CPU/GPU)等,减少了手动管理的工作量。
总而言之,继承了nn.Module基类代表着可以直接使用 torch 已经编写好的相关函数方法,可以便捷的操作 YOLO 模型网络层。继承类方法的具体使用在后续使用到时再进行谈论。
2.类方法总览
由于这是一个代码量比较复杂的重要基类,在此先声明以下内容行文逻辑是:1.分节记录各个函数自身的定义、实现的功能;2.最后再贯彻各个方法来研究如何具体使用完整的Model类。
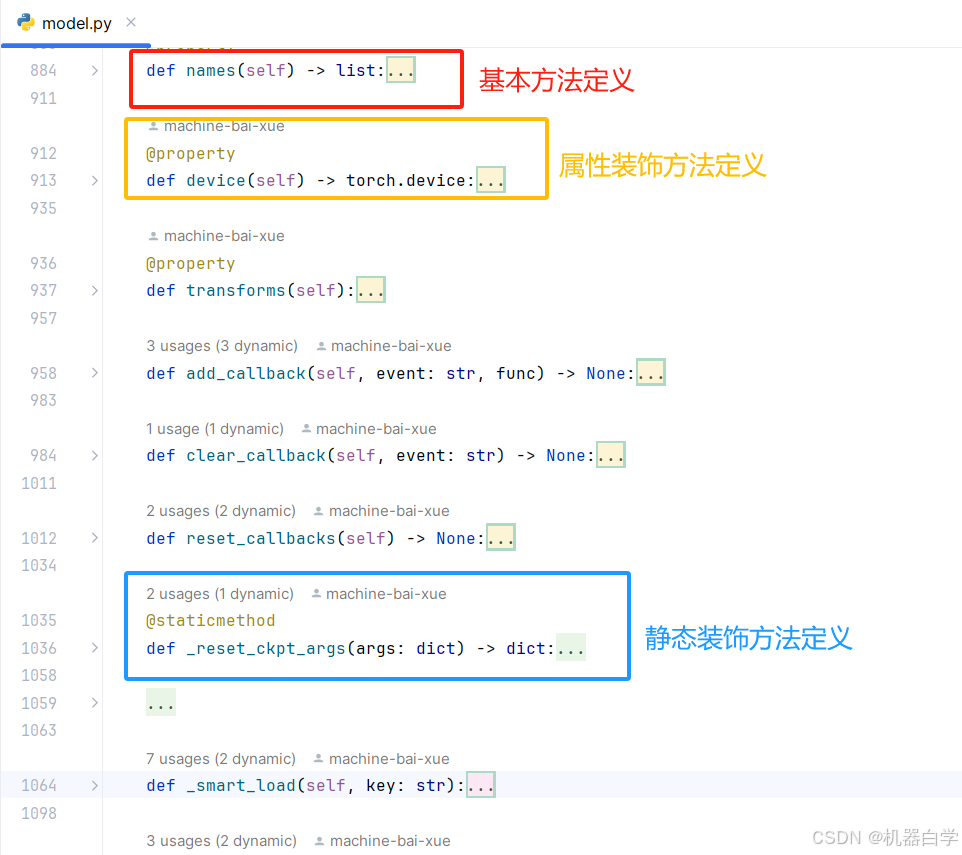
此类下定义的方法总体上可以分为三种类型:基本方法、静态装饰方法、属性装饰方法。
如下图,如果使用 @staticmethod 静态装饰的方法定义,表示该方法不依赖于类的实例或类本身;如果使用 @property 属性装饰的方法定义,表示将一个方法转换为属性,使得方法可以像属性一样访问,通常用于计算属性或只读属性。
下面将此类定义的所有方法的基本功能简单归纳在表格中,方便快速了解使用,如不想了解细节,可直接跳转到最后使用测试该类章节;如想具体解析可在目录处进入到详情章节。
| 类方法名 | 基本功能 |
| 初始化网络模型操作 | |
| __init__ | 选择方式加载 model 模型 |
| __call__ | 本质调用了predict类方法,功能与其一致。定义目的是可以直接输入数据到类运行预测操作(如Model(source=1.jpg),实际是调用了predict方法) |
| is_triton_model | 服务init方法,判断给定的字符串是否是一个有效的 Triton Server URL(一个机器学习服务部署工具) |
| is_hub_model | 服务init方法,检查输入的字符串是否是一个有效的 Ultralytics HUB 模型标识符 |
| _new | 根据提供的 cfg 配置文件或自定义模型实例model 加载新模型 |
| _smart_load & task_map | 服务_new,使用字典快捷加载默认模型模块实例 |
| _load | 加载权重文件(支持多种格式如url、pt等)模型 |
| 网络模型训练过程操作 | |
| reset_weights | 重置模型的权重,回到它们的初始状态,用于训练模型前的参数随机初始化。 |
| _check_is_pytorch_model | 服务reset_weights, 检查当前模型是否为有效的 PyTorch 模型 |
| load | 加载 .pt 权重到模型,适用于加载预训练模型或在训练中恢复模型状态 |
| save | 将训练完的模型的状态 checkpoint 保存到指定的 .pt 文件中 |
| info | 调用pytorch模型实例定义的方法info,返回或打印模型的相关信息(例如模型摘要、各层的详细信息、参数数量等) |
| fuse | 调用pytorch模型fuse方法,融合模型 Conv2d 和 BatchNorm2d 层,以优化推理速度 |
| embed | 接收一个图像源(如图像文件路径、URL、numpy 数组或 PyTorch 张量等)并生成图像的嵌入 |
| 核心方法:模型任务模式 | |
| predict | YOLO 模型对图像源进行预测。它支持多种类型的输入源,并且可以处理图像流式预测或批量预测。 |
| track | 执行目标跟踪任务,本质还是使用predict方法只是更新其参数中task任务 |
| val | 验证给定模型,计算其在指定验证数据集上的性能,通常返回包含验证指标(如 mAP)的结果 |
| train | 指定的数据集和训练配置来训练模型,支持从检查点恢复训练 |
| benchmark | 在不同导出格式下进行基准测试,评估模型的性能。 |
| export | 灵活的导出选项,将 PyTorch 模型导出为各种常见的部署格式(如 ONNX、TorchScript 等) |
| tune | 模型训练超参数调优 |
| 其他功能方法 | |
| _apply | 将一个函数应用于模型中非参数或已注册缓冲区的张量,通常用于将模型移动到不同的设备或更改其精度 |
| names | 返回包含模型框类别名称的字典。 |
| device | 返回当前模型的参数存储所在的设备,用于检索模型参数所在的设备(如 CPU 或 GPU) |
| transforms | 返回在模型中定义的输入数据转换(如大小调整、归一化、数据增强等)用于检索模型输入数据上应用的预处理数据增强转换 |
| add_callback | 为指定的事件(指定事件可以包括YOLO训练中损失几个轮次都不下降就停止训练,或者说一个轮次训练等待时间超过多少时间就停止进入下一个轮次等)添加回调函数 |
| clear_callback | 清除为指定事件注册的所有回调函数 |
| reset_callback | 将所有回调函数重置为默认函数 |
| _reset_ckpt_args | 在加载 PyTorch 模型的检查点(checkpoint)时,过滤掉不必要的或可能冲突的参数,只保留对模型加载相关的重要参数。 |
首先要介绍几个初始化Model类中pytorch网络模型的方法。
3.__init__:初始化构造方法
下面对一些重要(实现该类的主要功能函数)的类方法进行具体详细分析,如果想快速使用不在意细节,可以直接跳到最后测试各种类方法章节。
首先是该类的初始化构造方法,初始化接受三个参数的输入,记录在下。其中model输入的是一个通用模型的加载地址,task是具体该类要处理哪种YOLO任务类型,verbose控制运行中的打印信息开关。
| model | 模型文件的路径或名称。可以是本地文件路径(例如“yolo11n.pt”)、Ultralytics HUB 中的模型名称,或来自 Triton Server 的模型。这个参数用于加载特定的模型。 |
| task | 指定与YOLO模型相关的任务类型。比如目标检测、目标追踪、图像分割等。这个参数帮助根据模型的应用场景定制模型的行为。 |
| verbose | 可视化过程打印信息开关。True会启用详细的日志输出,用于在初始化和后续操作中提供更多信息,帮助调试和理解模型加载过程。 |
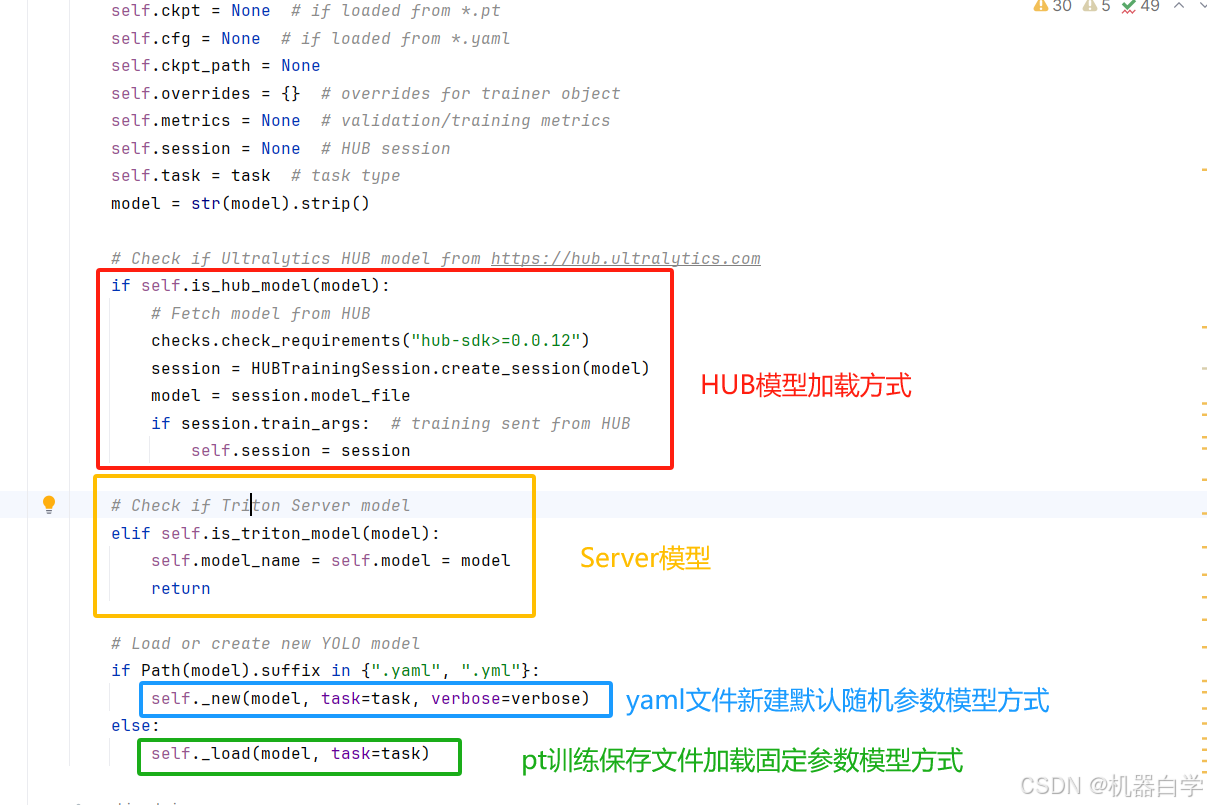
具体来说,__init__最主要的功能就是加载指定的YOLO网络模型到类属性中,方便后续的使用。下图可以看到,模型的加载方式至少存在四种,但本系列暂不涉及HUB和Triton Server的方式,主要分析从本地加载模型的方式(即_new和_load)。
4._new:新建模型方法
承接初始化中新建模型的方法,_new新建模型接受四个参数的输入。这里需要注意的是model参数输入,这里支持输入的是一个模型实例,默认为None。这意味着虽然默认初始化中没有使用到这个参数,但我们自定义模型可以直接通过这个参数传入Model类。
| cfg | 承接init中输入的.yaml配置文件地址 |
| task | 此类负责的任务类型。如果没有提供,将从配置文件cfg推断。 |
| model | 自定义的模型实例。如果提供,将使用此模型实例而不是从配置文件中创建新模型。 |
| verbose | 是否输出详细的模型信息(例如,是否显示加载过程中的日志) |
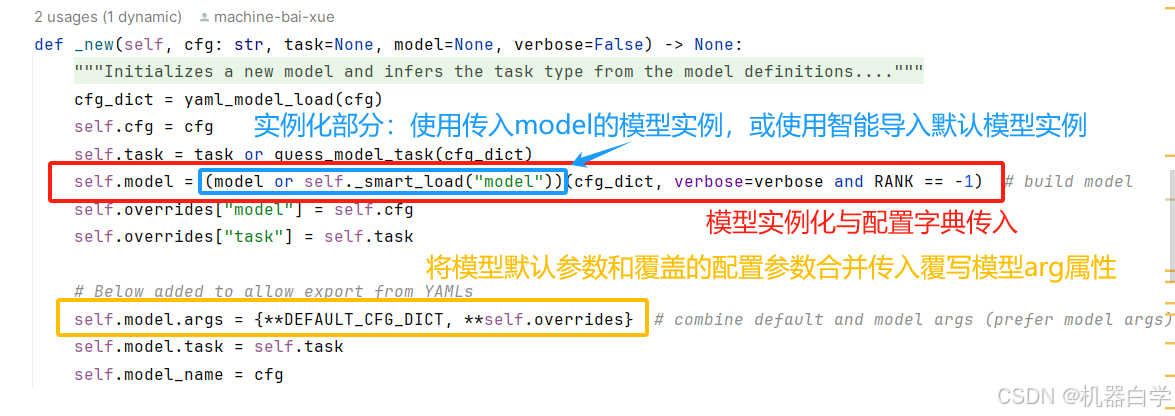
下面看其具体的功能代码。其中最主要的就是加载模型实例,如果传入的model不为None则直接使用,后面继续修改模型实例相关属性;否则使用本类自定义的 self._smart_load 方法便捷加载模型实例,这个方法在下一节具体分析。
5._smart_load 和 task_map:便捷加载实例
这里为了逻辑的流畅性,没有按照源码顺序继续记录,而是直接跳到了最后的关于上节提到的便捷加载模型实例的方法——_smart_load
这个方法实际上是和同属Model类的task_map一起使用的,目的是方便加载YOLO已经定义好的一些默认模块基类。其输入的是一个键值,用于定位想要加载的默认模块。
可以注意到 Model 源码中task_map中没有字典内容,并且直接运行会报没有task map的错。这是因为 Model 是个基类,要实际使用需要在此基础上进行添加。
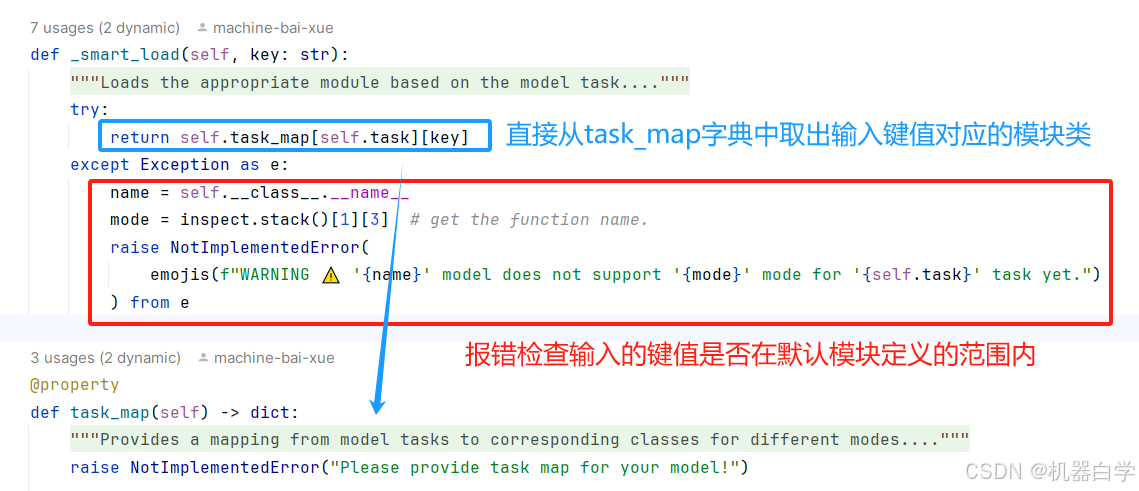
下面先行预告后续的YOLO类,是如何继承Model基类并定义task_map的,这可以方便理解这里的字典内容格式应该是怎么样的。

6._load:加载模型方法
继续 init 中配置模型逻辑中加载已有模型的方法_load。其支持两个参数。
| weights | 模型的权重文件路径,可以是本地路径或URL |
| task | 任务模式 |
下面记录其具体功能代码。其最重要的是加载 .pt 权重文件的方法,这个具体逻辑是在下图中的 attempt_load_one_weight 函数方法中实现,此方法在ultralytics.nn.tasks中定义,在分析该py文件时再深究。

下面介绍的方法都是基于nn.Module的pytorch模型实例类的操作,用于对训练中和后的模型网络参数进行操作。
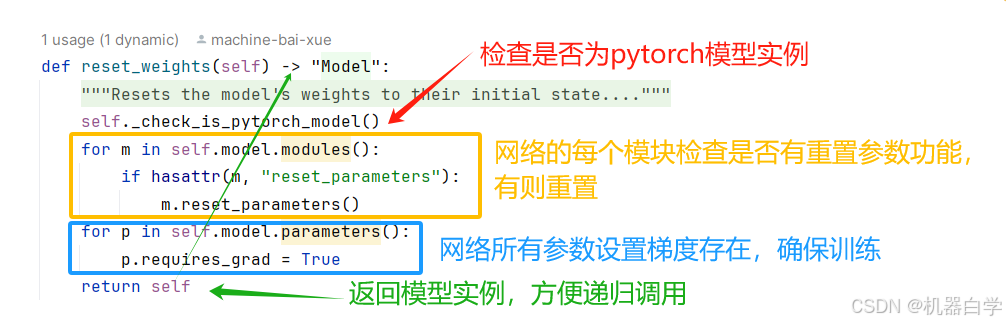
7.reset_weights:重置模型参数
reset_weights是Model定义的第一个基于nn.Module基类pytorch操作方法。其核心功能是调用网络每一层的 reset_parameters方法来重置权重,并确保所有参数都参与训练。
因此该方法用于模型的初始化或重训练,可以在需要重新训练模型时使用,或者在模型加载时对权重进行重新初始化。
下图解释了其核心代码。
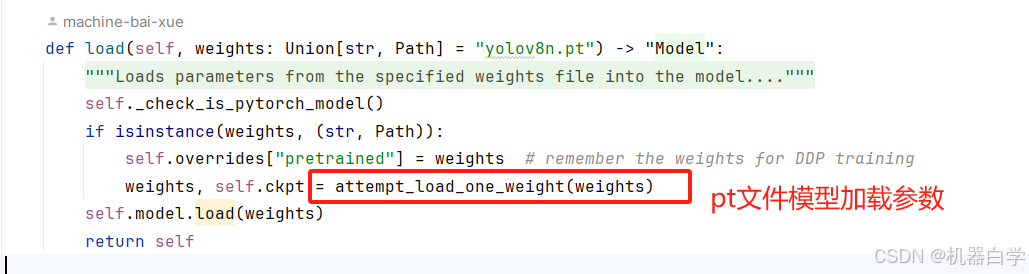
8.load:动态加载pytorch模型参数
该方法要区别于之前章节的 _load 方法,两者最大的区别在于,_load 方法主要用于加载模型,支持多种模型参数文件输入格式,主要用于“训练前”;而此处的 load 方法只支持加载pytorch的 pt 权重参数文件,主要用于“训练中”,适用于加载预训练模型或在训练中恢复模型状态。
具体代码跟_load中pt文件加载一致,也是调用attempt_load_one_weight方法。返回的也是模型实例,支持链式调用(如model = Model(), model.load("yolov8n.pt").train()。即可以在该方法返回的实例上继续进行训练操作)
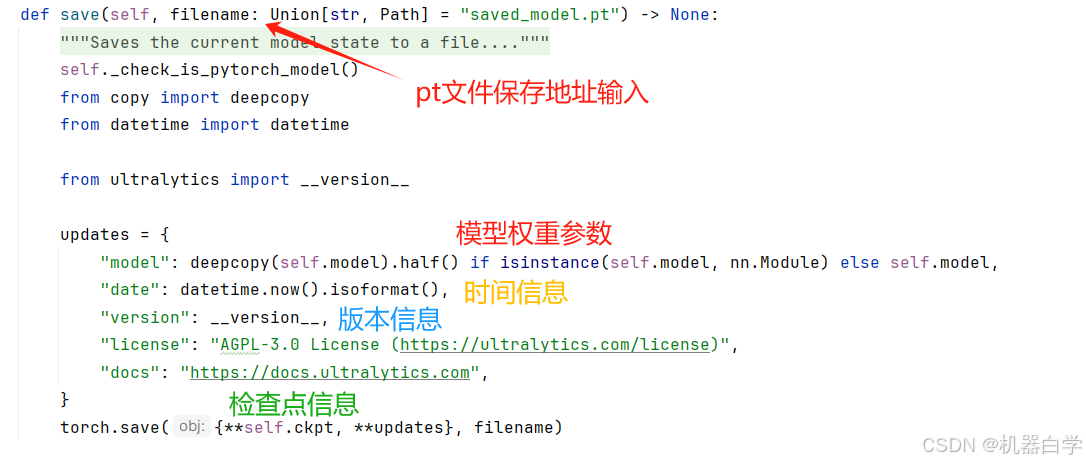
9.save:模型保存
该方法的核心功能是将当前模型的权重和相关元数据保存到指定的文件中,保存的内容包括模型的权重、日期、版本、许可证等元数据,提供了对模型的完整描述,便于后续加载和使用。
下面介绍的是Model类中的几个核心方法,这些方法实现了整个YOLO模型中的训练、预测、验证等任务逻辑。
10.predict:核心方法——预测任务
首先是YOLO的预测任务,Model类中定义了模型预测的基本操作逻辑。其接受四个主要参数的输入。其中**kwargs是传入predictor预测器的参数集合。具体如何传参的参考YOLODataset类章节。从壹开始解读Yolov11【源码研读系列】——Data.dataset.py:模型训练数据预处理/YOLO官方数据集类——YOLODataset_yolo源码分析-CSDN博客
| source | 要进行预测的图像源,支持路径、URL、图像文件、NumPy 数组、PyTorch 张量等 |
| stream | True则输入源视为连续流进行预测 |
| predictor | 自定义的预测器对象。如果未提供,则使用默认的预测器。 |
| **kwargs | 其他用于配置预测器 predictor 的关键字参数 |
下面参看其具体源码,和导入模型_load时一样,这里关键也是传入预测器实例类或者使用_smart_load导入默认预测器类。所有预测逻辑在predictor预测类中实现,将会在分析该类文章时具体分析。
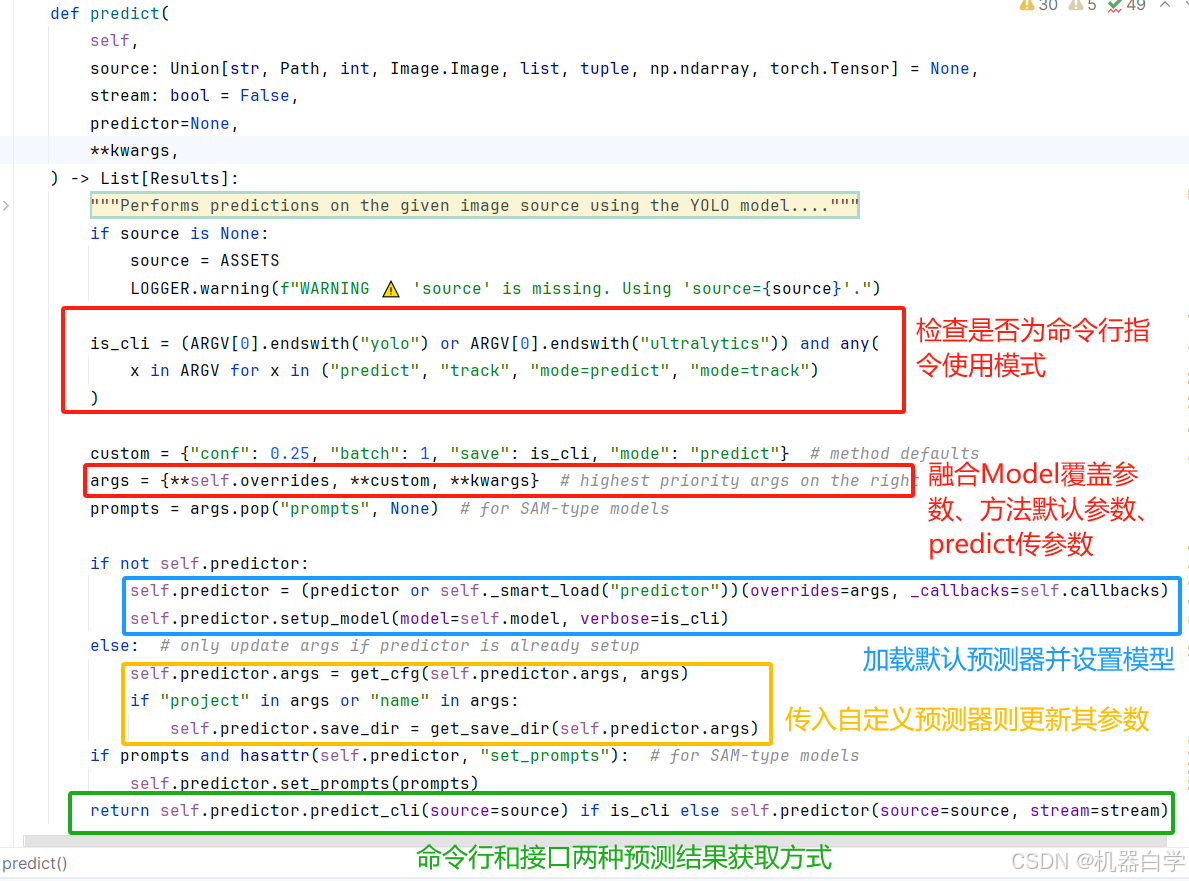
11.val:核心方法——验证任务
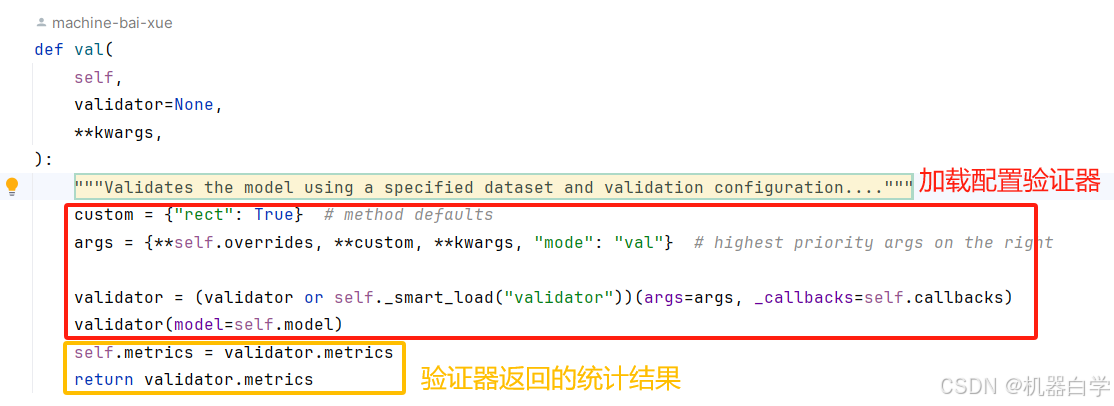
YOLO的验证任务在Model中源码和predict一样,都是支持传入验证器实例或者默认smart加载。也还支持**kwargs传入验证器的参数。
需要注意的是,不像predict那样额外有一个source参数传入自定义的图片,验证器val默认在传入的validator验证器中定义要进行的验证集,因此如果想要传入你想验证的数据地址,要通过**kwargs传入validator对应数据集的参数。
| validator | 自定义验证器实例。如果未提供,则使用默认的验证器。 |
| **kwargs | 用于配置验证器的关键字参数 |
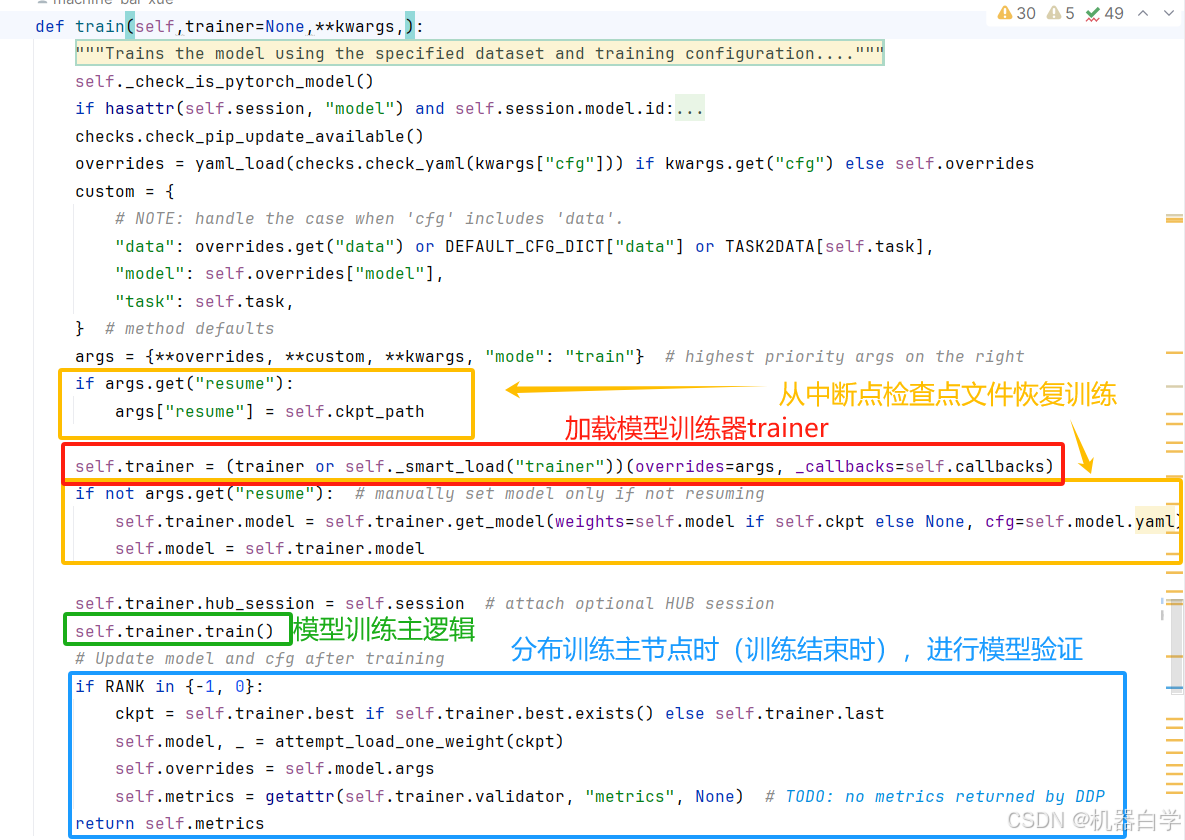
12.train:核心方法——训练任务
YOLO训练任务在Model中的方法 train 也是经过封装的,主要逻辑也是在 trainer 训练器中实现 。该方法也是接受两个参数的传入。
| trainer | 自定义的训练器实例。如果为None,则使用默认的训练器 |
| **kwargs | 任意数量的关键字参数,用于定制训练过程 |
具体到其代码,train方法通过指定的数据集和训练配置来训练模型。它支持灵活的配置,包括自定义训练器实例、数据集路径、超参数(如学习率、批大小等),以及设备设置(如 CPU 或 GPU)。它还支持从检查点恢复训练,并与 Ultralytics HUB 进行集成,以便处理更复杂的训练场景。
需要注意到,整个yolo训练的主逻辑是在下图中绿色框内的 self.trainer.train() 中进行的,在分析训练器类时会重点分析。此处的类主要是明确整个训练的流程。最后返回的metrics是验证后的模型表现的统计信息。
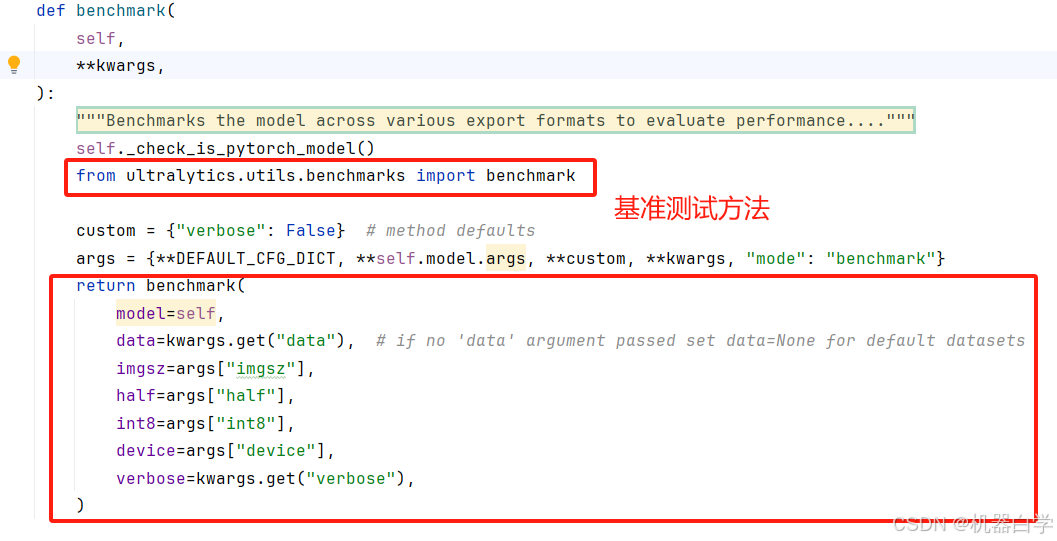
13.benchmark:基准测试
benchmark方法用于评估模型在不同导出格式(如 ONNX、TorchScript 等)下的性能。它使用 ultralytics.utils.benchmarks 来执行基准测试,并评估模型在不同配置下的推理性能。该方法评估模型在不同导出格式和硬件配置下的性能。它帮助用户了解模型在不同精度格式(如 FP16、INT8)和设备设置(如 CPU、CUDA)下的推理表现。
14.export:模型导出
export 方法用于将训练好的模型导出为不同的格式,通常是为了便于部署到不同的硬件平台或框架。它支持多种导出格式(例如 ONNX、TorchScript),并允许根据需求进行一些自定义设置,如精度模式、设备选择等。

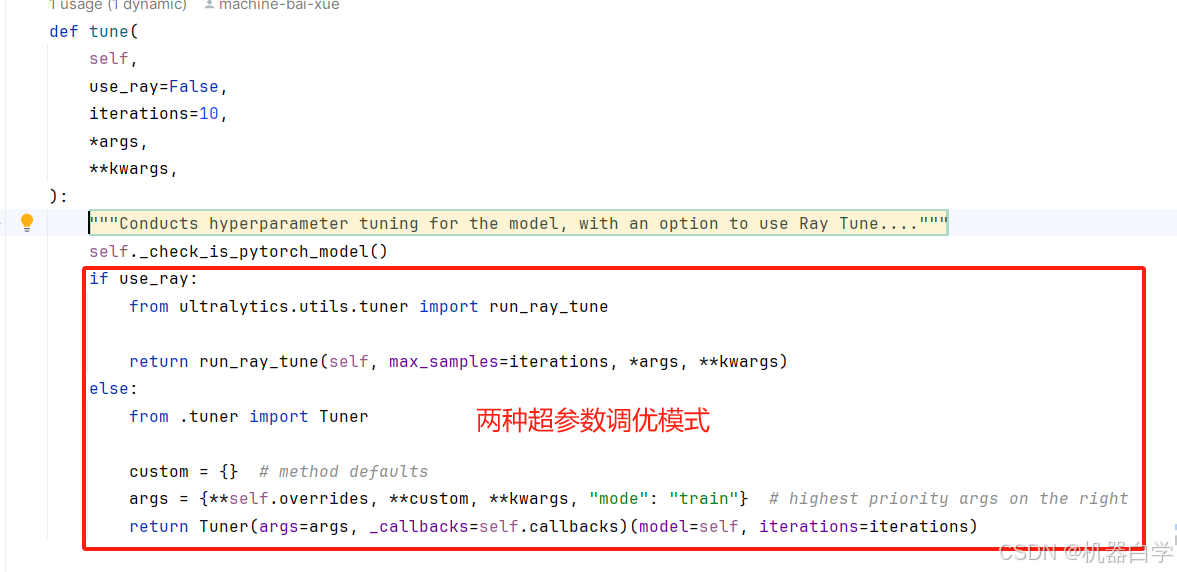
15.tune:超参数调优
tune方法为模型提供了超参数调优功能,支持使用 Ray Tune 或自定义调优方法进行训练过程中的超参数优化。它接受不同的参数配置,并通过调整模型的训练参数来改进模型的表现。此方法中的具体逻辑也在具体章节解析。
至此,Model 重要的方法源码解析结束,其他没有详细解析的源码,可以在总览中看到其功能的基本介绍。下面开始使用测试Model类。
二、model.Model类的实验与测试
1.加载模型测试
Model类的初始化过程主要就是加载网络模型。本文专注于两种网络参数格式来源——.pt权重文件和.yaml配置文件,在类初始化__init__源码中分布对应_load加载模型和_new创建新模型。
(1)官方pt权重文件
首先来看一下加载pt文件,这里的权重文件是官方在coco数据集上训练结果 yolo11n.pt 下载,下载地址:https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt
pt文件代表的是,加载已经训练好的模型参数。由源码解析可知,Model类会自行判断模型参数输入类型,pt文件对应的是_load方法。Model类中定义了一个ckpt属性用于加载训练好模型的检查信息,实验可以打印查看一下。代码如下。
from ultralytics.engine.model import Model
# 官方coco数据集.pt文件加载
model = Model('./yolo11n.pt', task='detect', verbose=True)
print(model.ckpt)分析打印信息。首先是官方模型的训练时间和版本信息,还记录了当前训练的网络架构。
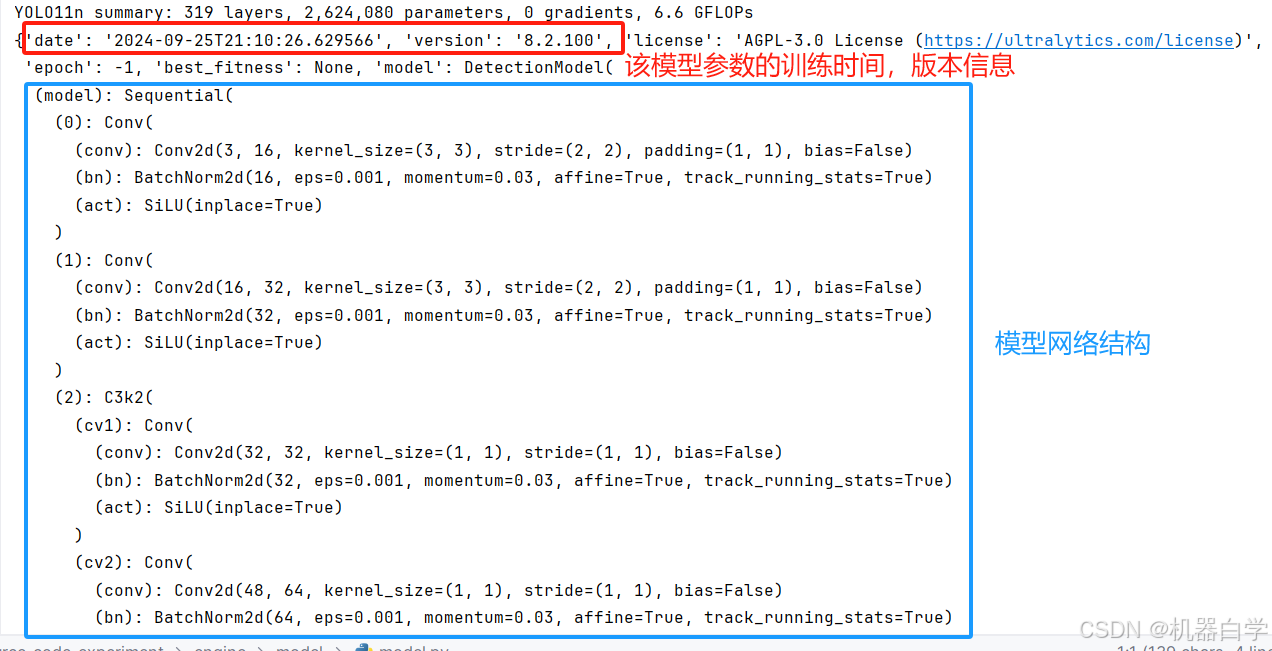
再则记录了训练时使用的配置参数,可知下载的pt文件是detect检查任务的yolo11n小型模型在coco数据集上进行600轮次训练后的最优结果参数。

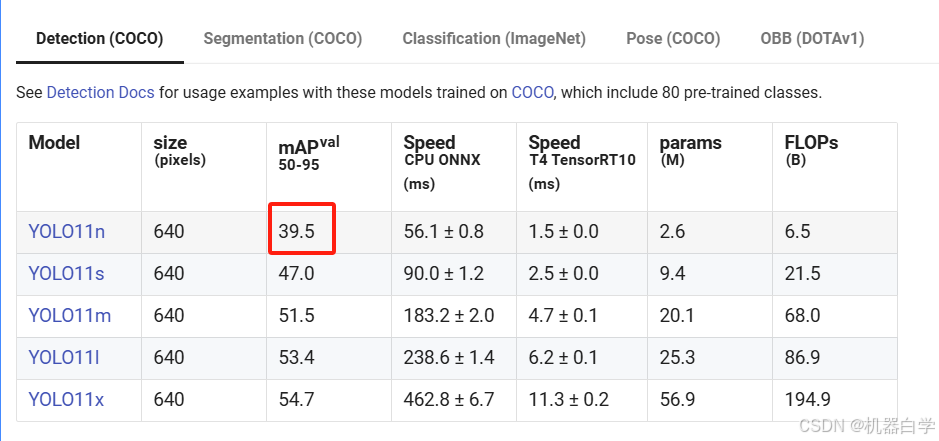
继续ckpt中还记录了模型在coco验证集上的统计信息。包括精度、召回率、map50、map50-95等指标,可以看到结果和官方文档汇报一致。

剩余还有大量训练过程数据,包括训练中的损失、学习率的记录列表,这里不做具体分析。
(2)官方yaml配置文件
使用官方源码在cfg/model/中的模型配置文件也可以加载Model类的模型,对应使用_new方法。直接输入配置文件运行会报错,这是因为Model基类中的task_map没有被定义,_new方法那么接受一个实例化好的模型,要么加载默认设置的task_map实例。
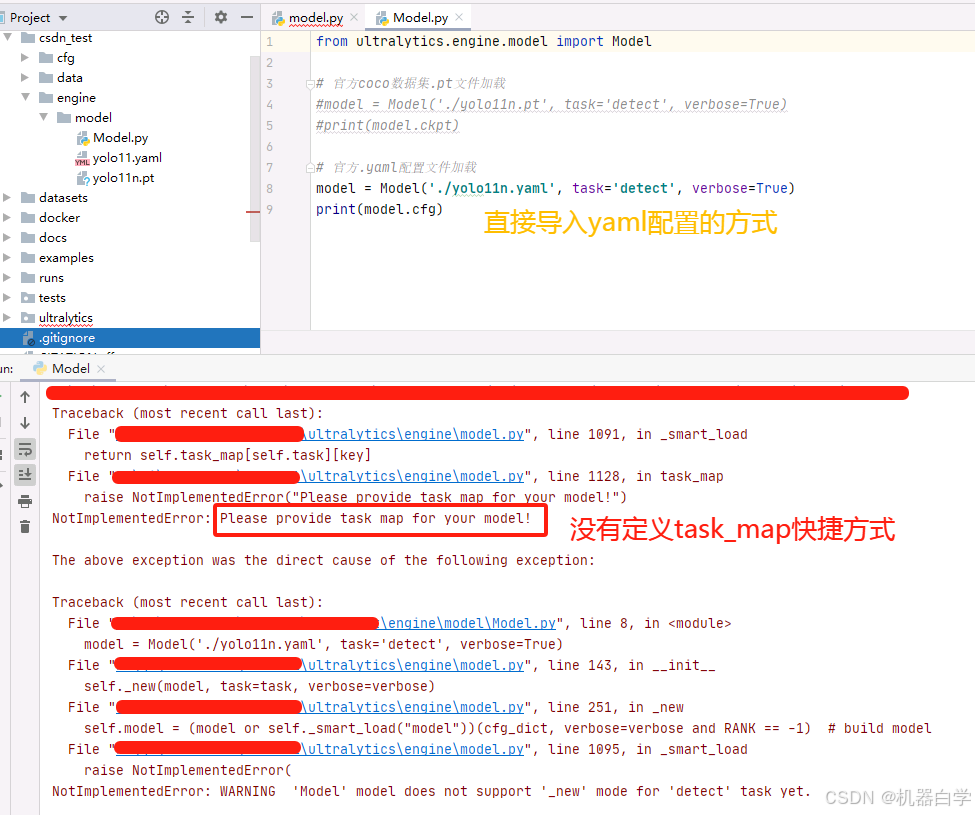
下面从两个方面来解决。
第一种解决方法是不要使用初始化默认的加载方式,而是单独在类外实例化模型,再通过显式调用_new方法加载模型。但此方法需要注意Model类的初始化问题。
# 官方.yaml配置文件加载
from ultralytics.nn.tasks import DetectionModel
model._new('./yolo11n.yaml', model=DetectionModel, task='detect', verbose=True) # 更新model为yaml配置文件
print(model.cfg)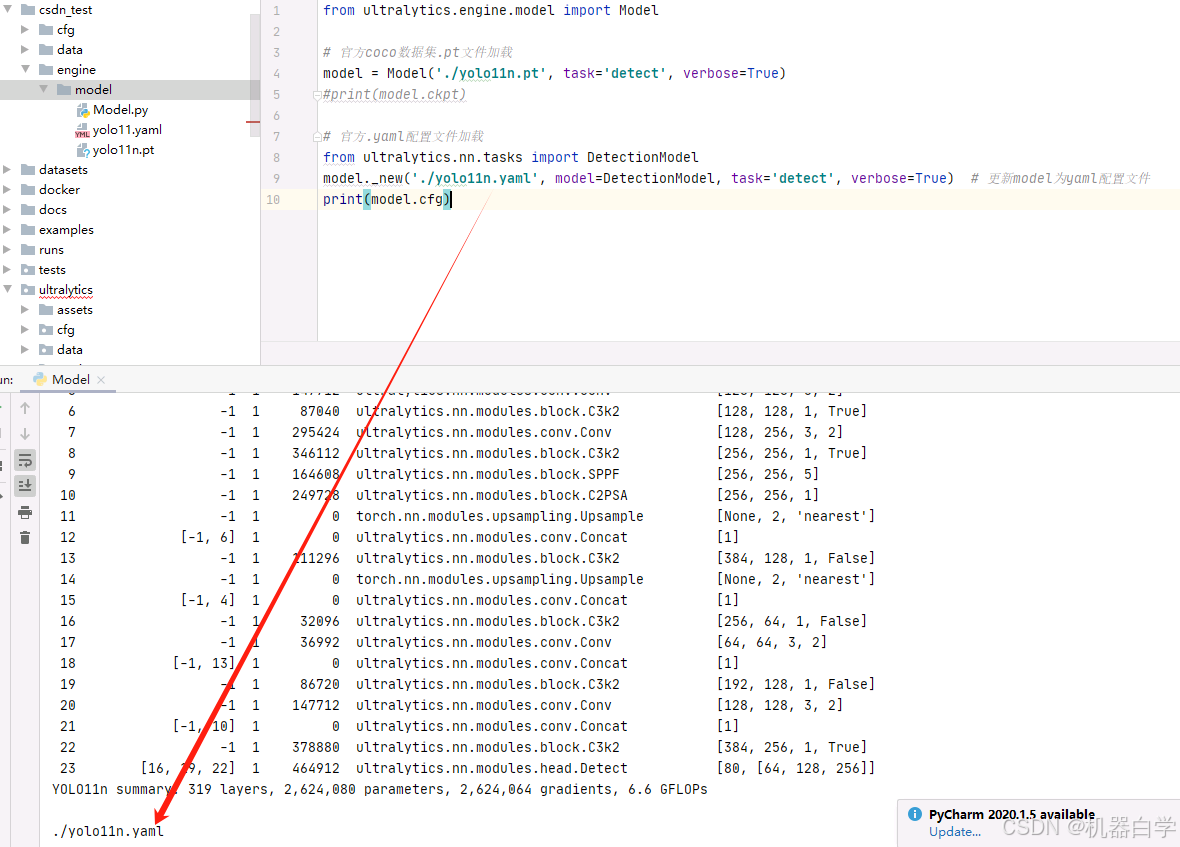
第二种解决方法更加官方,更推荐一些。和官方源码使用方法一样,新建类继承Model,并且自定义task_map中的字典信息,这样做之后就可以直接加载yaml配置了。
from ultralytics.nn.tasks import DetectionModel
# 自定义类继承Model
class My_Yolo(Model):
def __init__(self, model, task=None, verbose=False):
super().__init__(model=model, task=task, verbose=verbose)
@property
def task_map(self) -> dict:
return {'detect':{"model":DetectionModel}}
# 直接加载yaml文件
model = My_Yolo('./yolo11n.yaml', task='detect', verbose=True)
print(model.cfg)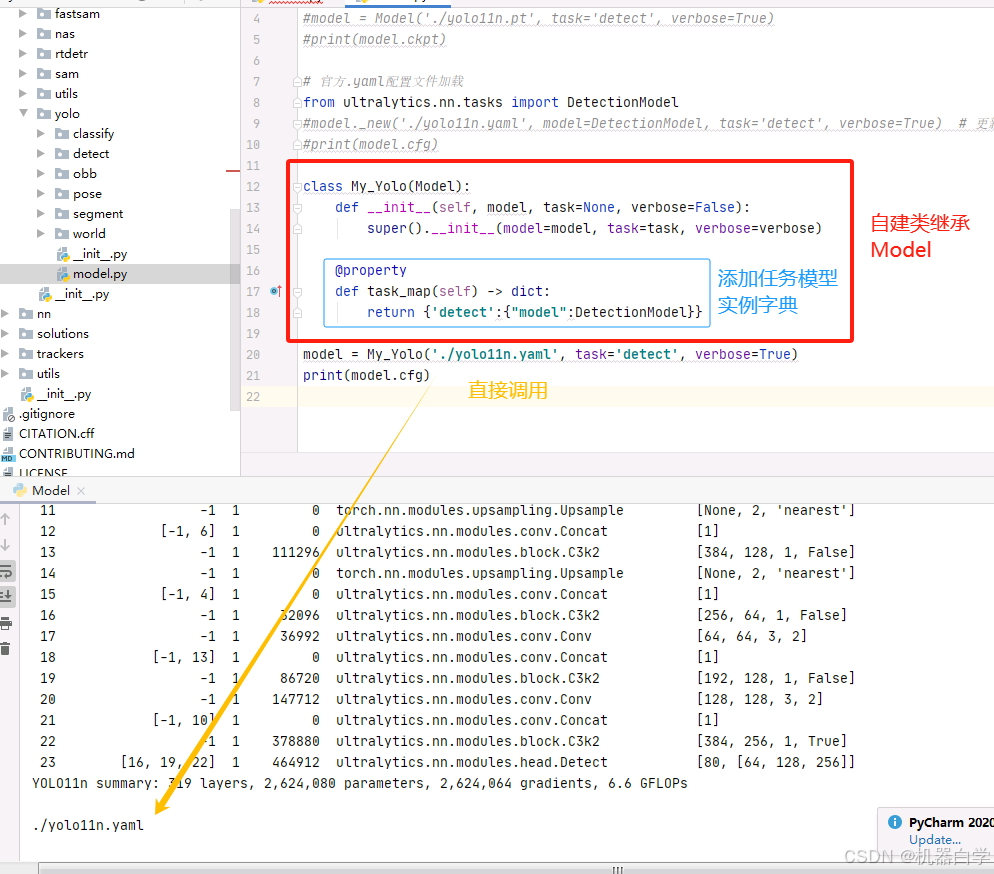
2.模型参数操作测试
测试打印模型参数信息和重置所有模型参数操作——info & reset_weights,先加载官方coco数据集训练好的yolo11n.pt模型参数,我们打印操作前后的第一层的batch norm参数值,对比可以看到变化。
from ultralytics.engine.model import Model
# 查看batchnorm层参数
def check_param(model):
for i, (name, param) in enumerate(model.named_parameters()):
if i == 1:
print(f"Layer:{name},Parameter:{param}")
break
## 参数操作测试
model = Model('./yolo11n.pt', task='detect', verbose=True)
model.info()
check_param(model.model)
model.reset_weights() # 重置网络层参数
check_param(model.model)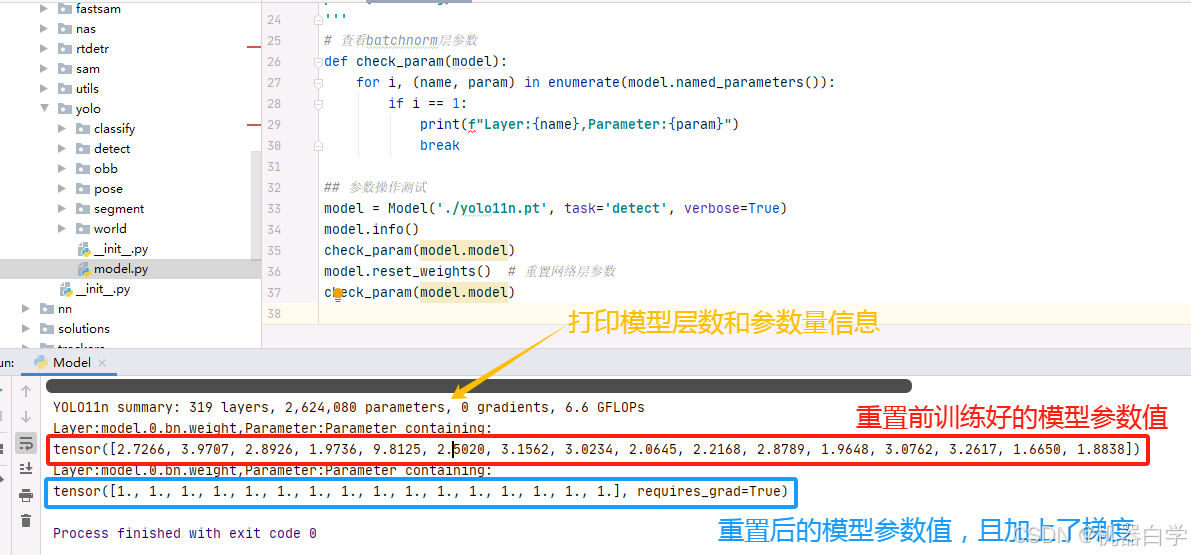
再测试中途加载模型参数(恢复训练)以及将模型参数导出保存为pt文件——load & save。 首先尝试加载yaml配置文件,保存参数,看看默认配置文件新建的模型参数是不是默认值。然后在默认参数基础上加载官方训练好的pt参数,用以模拟中断训练最后的保存点文件。
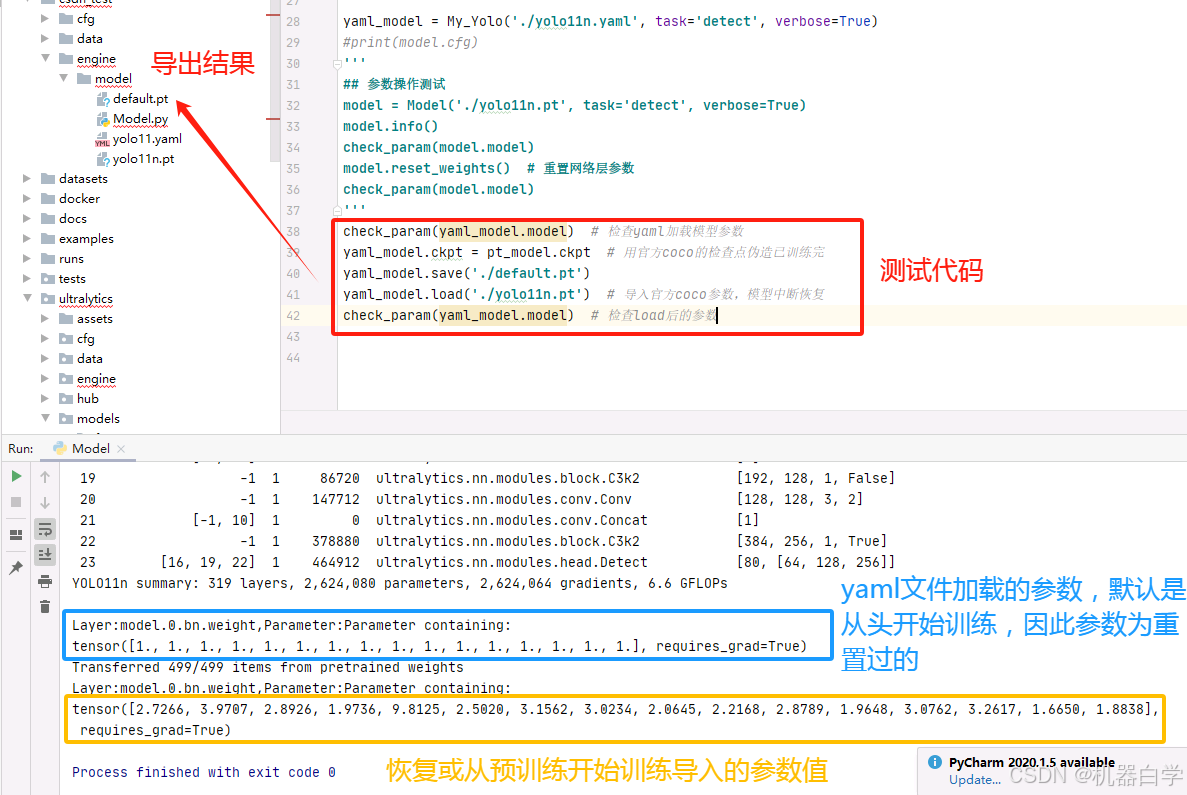
3.核心方法测试
最后测试一下Model中定义的核心方法——训练、验证、预测、基准测试、导出、超参数调优。在测试前还需要改写之前定义的继承类中的task_map,要加上训练器trainer、预测器predictor、验证器validator。同时还要准备好数据集。

然后设置训练参数就可以直接训练了,训练参数要传入数据集目录。实际上训练就会在最后进行验证操作。
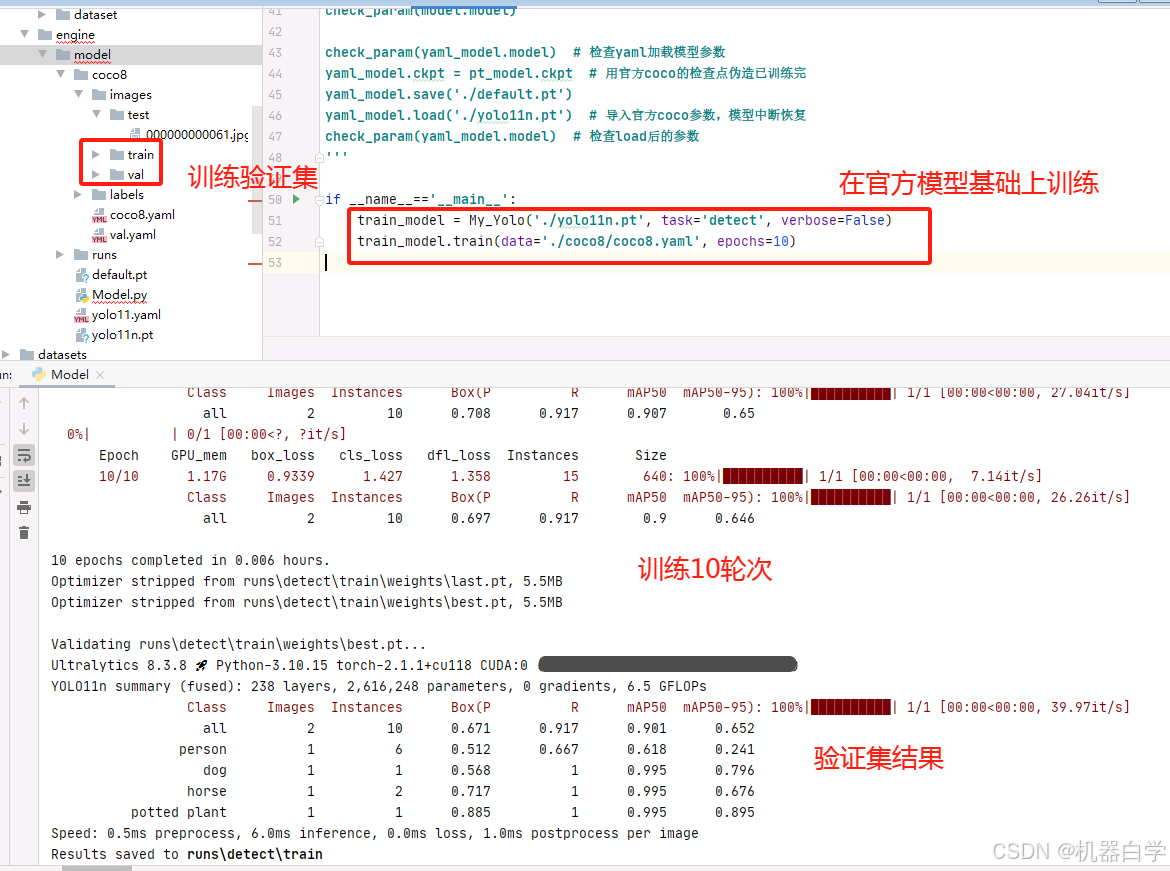
但是为了单独测试验证操作,在数据集中还建了一个测试目录——test,下面单独进行模型验证测试。需要注意val如果要单独对训练集val的数据做评估,需要要为训练集外数据单独创建yaml数据集配置文件,修改其中的val地址,这样才能进行验证,否则报错或在原始数据集val内进行验证。
同时这里使用官方coco训练好的模型pt参数,因为使用yaml加载的初始模型验证为0。
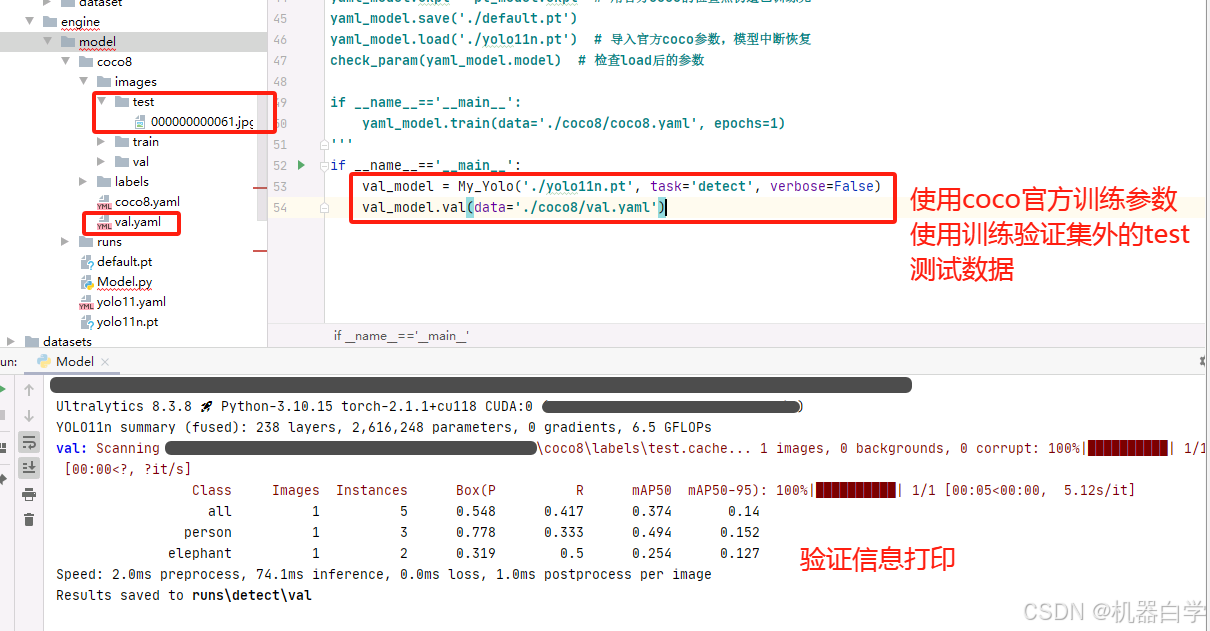
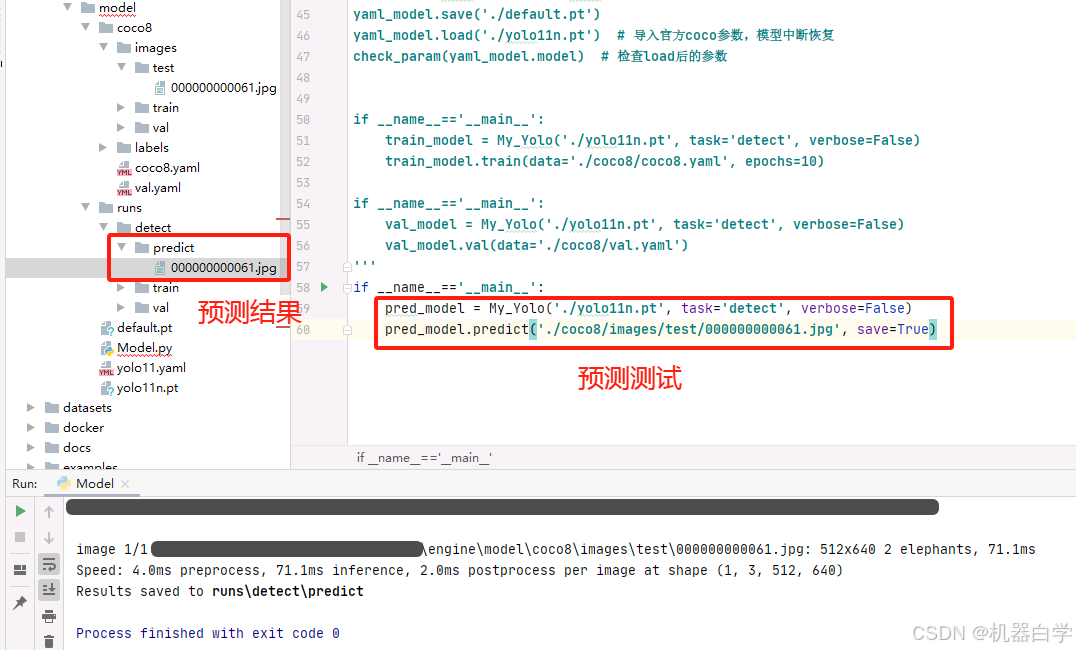
继续进行predict预测测试,预测上面验证测试test目录下的图片,并可视化保存。
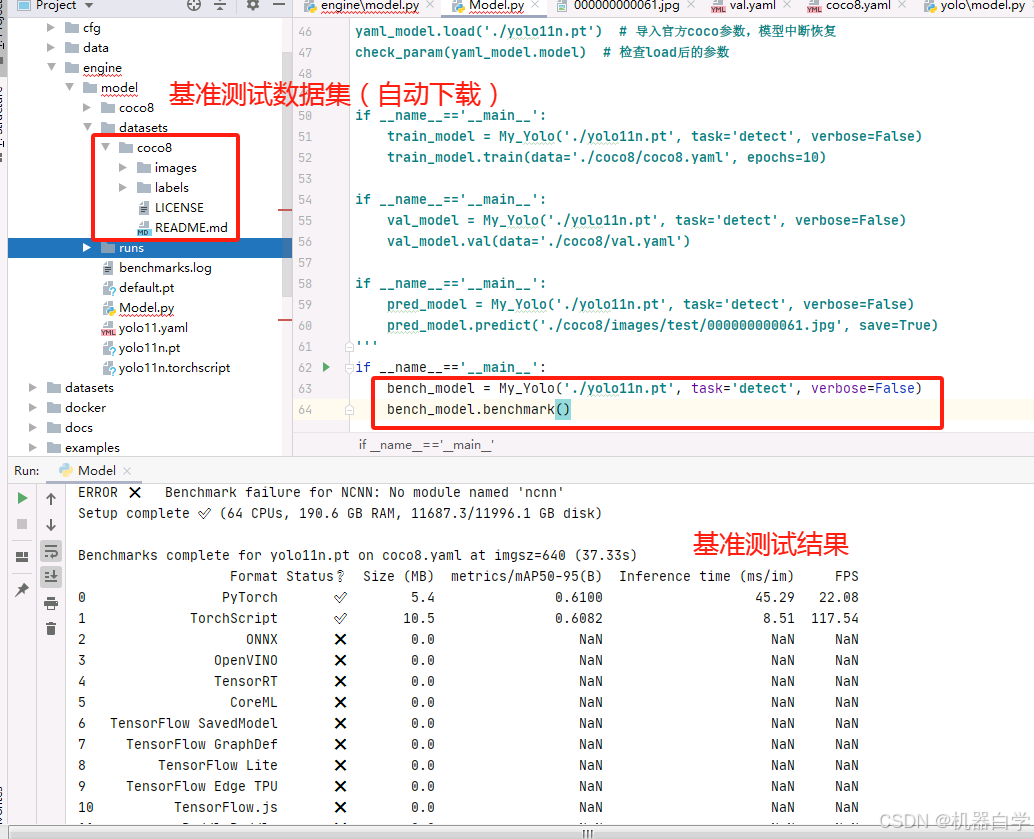
最后测试一下基准测试和超参数调优。下面是基准测试benchmark的结果。
tune超参数是一个非常耗时的操作,其会不断进行训练,根据迭代次数iterations设置训练多个模型,并返回找到的最优超参数设置。
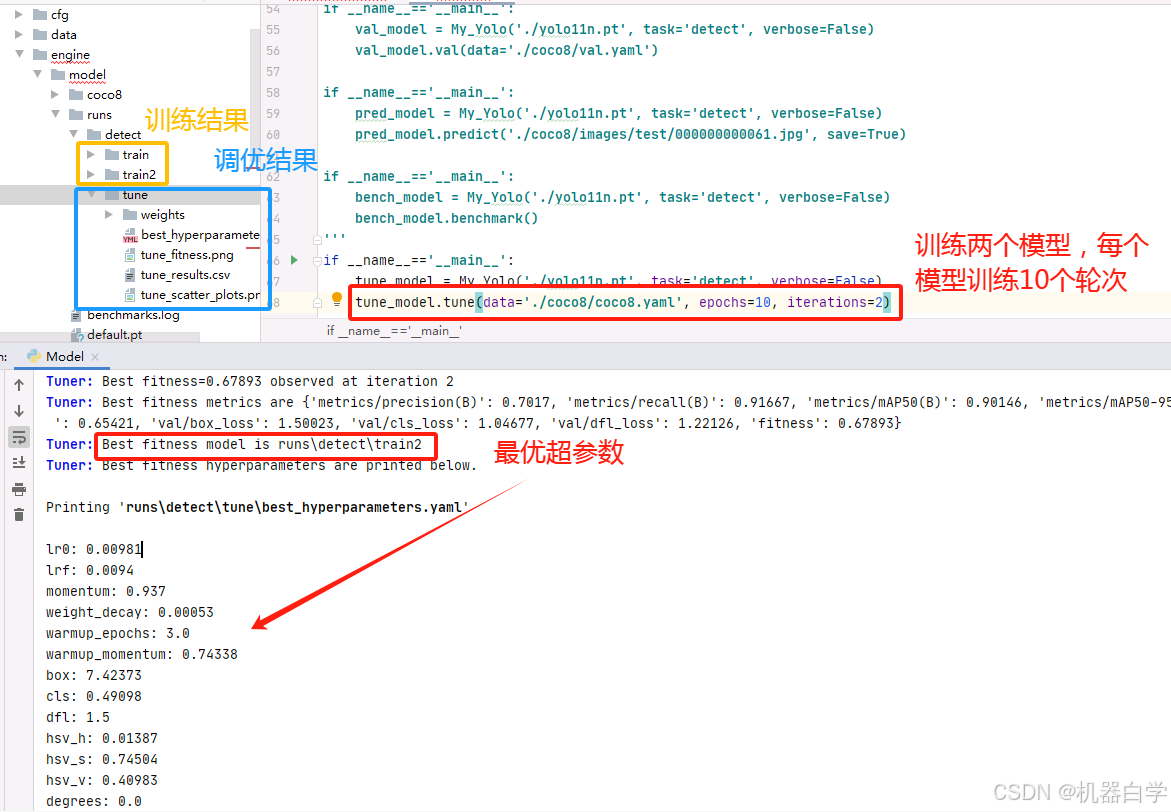
至此,整个Model类测试基本完成。在本章节中对于训练器、预测器、验证器都是从外界导入包直接使用,在后续章节将继续在engine文件下具体分析YOLO构建的训练器、预测器、验证器等的具体源码逻辑。
下一篇介绍YOLO的验证器基类并解读多框多阈值匹配算法:从壹开始解读Yolov11【源码研读系列】——核心源码部分:Engine.validator.py:BaseValidator——模型验证基类:验证流程+多框多阈值匹配算法_yolov11源码-CSDN博客


















 5026
5026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









