











目录
资源
Qwen2.5-VL源码地址:https://github.com/QwenLM/Qwen2.5-VL
Blog地址:https://qwenlm.github.io/zh/blog/qwen2.5-vl/
模型地址:https://modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
一、环境配置
1.基础环境
首先配置基础的python、pytorch环境和比较好安装的依赖包
# 环境配置
conda create -n qwen-vl python=3.10 -y
conda activate qwen-vl
# torch环境
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu118
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124
# 其他依赖包安装
pip install numpy==1.26.2 # 注意这里指明不能安装大于2.x版本以上的numpy库
pip install accelerate
pip install qwen-vl-utils==0.0.102.开发测试版Transformers库源码安装
注意:需要安装最新版的 transformers 库,由于qwen2.5-vl模型加载方法定义在最新测试版的 transformers库中,普通 pip install transformers 不能安装到该部分方法,因此要从源代码上安装测试版的4.49.0.dev0。
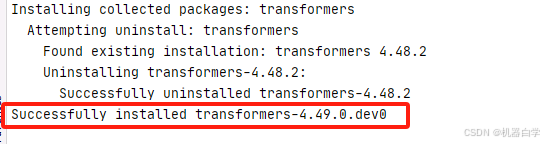
具体方法就是访问下面的源码地址,下载zip包并解压到本地,命令行访问到下载包目录pip install . 安装即可。
源安装transformers库地址:https://github.com/huggingface/transformers
# 源安装transformers指令
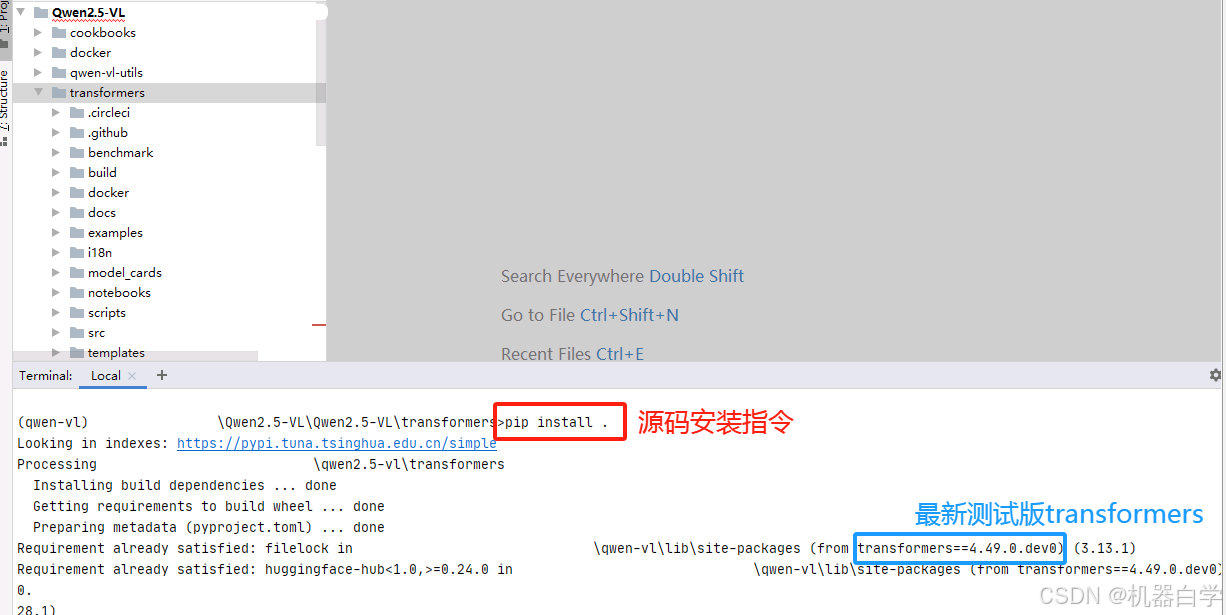
cd transformers-main
pip install .
安装完成后可以测试成功与否,输入下面代码在pycharm环境中不报红色波浪号
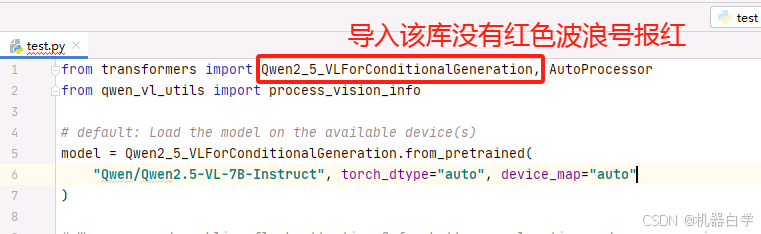
# 测试最新测试版transformers安装是否成功
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor或者运行上面代码不会下方的红色报错。则表明安装成功。
![]()
3.模型参数下载
这里选择使用魔搭社区的下载地址:https://modelscope.cn/collections/Qwen25-VL-58fbb5d31f1d47
可以看到官方开源了三个量级的多模态模型。分别是3B、7B、72B,下面首先以3B模型作为测试环境样例,后续使用将测试三个模型的不同表现。
下载方式可以参考之前Deepseek博文中的模型参数下载部分,这里不多赘述,指令如下。
# 魔搭社区qwen2.5-vl下载指令
## 3B模型
modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir path/to/save
## 7B模型
modelscope download --model Qwen/Qwen2.5-VL-7B-Instruct --local_dir path/to/save
## 72B模型
modelscope download --model Qwen/Qwen2.5-VL-72B-Instruct --local_dir path/to/save
二、基础使用(环境测试)
1.硬件要求
首先测试一下模型加载所需的GPU显存要求,可以用下面代码进行模型加载测试,其中需修改模型加载地址:model_path 和 GPU 选择:"1" 。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1" # 设置模型加载GPU(1号GPU)
model_path = 'path/to/save' # 修改为本地模型下载地址
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_path)三个模型的加载空间记录在下表。
| 模型类别(根据参数量划分) | GPU显存要求 |
| Qwen2.5-VL-3B | 8G+ |
| Qwen2.5-VL-7B | 20G+ |
| Qwen2.5-VL-72B | 158G+ |
2.推理测试
运行下面代码就可以完成使用模型进行单一图片基本推理的过程了。这里需要修改模型参数地址、输入图片地址和针对输入图片的文本提问内容。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
from PIL import Image
# 根据实际情况修改
model_path = "path/to/save" # 修改为本地模型下载地址
img_path = "path/to/jpg" # 输入图片地址
question = "描述一下这张图片的内容。" # 针对图片的提问
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_path)
# 输入配置
image = Image.open(img_path)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
},
{"type": "text", "text": question},
],
}
]
text_prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=[text_prompt], images=[image], padding=True, return_tensors="pt")
inputs = inputs.to('cuda')
# 推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)这里测试使用的是目标检测任务中经典的coco8数据集中的一张关于长颈鹿的图片。模型使用Qwen2.5-VL-3B 的小型模型做推理。

使用 Linux 环境进行测试的指令如下。上述代码被存放在 run.py 文件中。(建议使用Linux环境进行操作,window下可能出现调用cuda不稳定、资源访问过多等报错问题)
# Linux下指定0号GPU测试
CUDA_VISIBLE_DEVICES=0 python run.py有意思的是,同样的代码和模型参数,使用中文和英文提问得到的结果内容不一致。

中文结果如下:

英文结果翻译如下:

有了上面的结果输出代表环境配置和模型参数下载成功,下面根据官方指南,详细测试实验不同功能、不同提示词的效果。
三、实验
官方博客指南地址:https://qwenlm.github.io/zh/blog/qwen2.5-vl/
官方博客中介绍了最新更新的 Qwen2.5-VL 多模态大模型的强大功能和可能的应用场景。

下面所有功能的识别都是基于 Qwen2.5-VL-3B 模型,更大模型在下一篇文章本地部署时记录
1.多图识别
在上一章节测试环境中,已经可以看到 Qwen2.5-VL 对一张图片的内容识别提取能力了,现在将实验扩展到同时输入多张图片,并修改运行代码保存为 run_multi.py 文件。
注意需修改下面的图片地址为保存多张图片的文件夹地址,而且在测试中可以看到英文提问似乎给出的回答效果更好,因此此时提问内容选择英文,只需在最后加上“Please give their names in Chinese”,即可输出中文。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import os
model_path = 'path/to/save' # 修改为本地模型下载地址
img_path = "path/to/jpg" # 输入图片地址
question = "Please describe the entity target content in these images,Please give their names in Chinese."
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_path)
# 输入配置
content = []
for file in os.listdir(img_path):
if file.lower().split('.')[-1] in ['jpg', 'tif', 'jpeg']:
imgdir = os.path.join(img_path, file)
content.append({"type": "image", "image": imgdir})
# 添加文本提问
content.append({"type": "text", "text": question})
messages = [
{
"role": "user",
"content": content,
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)测试图片如下。



模型推理结果如下,可以看到其强大的多图推理识别能力。而且这只是使用最小的3B模型。
![]()
2.目标定位
Qwen2.5-VL 还能输出关注目标的定位框坐标信息,这对目标检测领域无疑是一个重大冲击。要得到目标框坐标信息,只需在提问中加入对坐标信息的索要即可,这十分符合人类的自然交流。
对之前的长颈鹿单张图片的测试代码(基础使用部分),现在只需将提问改成下面即可。
# 目标定位框信息提问
question = "Detect all objects in the image and return their locations in the form of coordinates. The format of output should be like {“bbox”: [x1, y1, x2, y2], “label”: the name of this object in Chinese}"
得到结果如下:
# Qwen2.5-VL-3B定位推理结果
['```json[
{"bbox_2d": [389, 67, 554, 350], "label": "长颈鹿"},
{"bbox_2d": [51, 352, 186, 408], "label": "长颈鹿"}
]```']将其在原图可视化检查一下。
from PIL import Image, ImageDraw, ImageFont
def vis_box(img, cls_lst):
font_path = "C:\Windows\Fonts\SimHei.ttf"
draw = ImageDraw.Draw(img)
for idx, box in enumerate(cls_lst):
if len(box) == 4:
# 图片画框
draw.rectangle(box, outline="black", width=2)
elif len(box) == 5:
bbox= box[:4]
draw.rectangle(bbox, outline="black", width=2)
ord = f'{box[4]}'
conf_x, conf_y = box[2], box[1]
font_conf = ImageFont.truetype(font_path, 30)
draw.text((conf_x, conf_y), ord, fill='red', font=font_conf)
elif len(box) == 6:
b = box[:4]
conf, cls = box[5], box[4]
draw.rectangle(b, outline="black", width=2)
font_conf = ImageFont.truetype(font_path, 30)
conf = f'{conf}/{cls}'
conf_x, conf_y = box[2] + 5, box[1]
draw.text((conf_x, conf_y), conf, fill='red', font=font_conf)
return img
if __name__=='__main__':
cls_lst = [[389, 67, 554, 350, "长颈鹿"], [51, 352, 186, 408, "长颈鹿"]]
savedir = '/vis.jpg'
img = Image.open('/test.jpg')
vis_img = vis_box(img, cls_lst)
vis_img.save(savedir)
3.OCR
官方提到其多模态模型还具备强大的OCR文本提取能力,这里测试一下繁体古文。

官方给出的提示词如下。
question = "Read all texts in the image, output in lines. "古文图片如下。

推理结果如下。
# Qwen2.5-VL-3B的OCR推理结果
['仕而未有禄者違而君亮弗爲服也違大夫\n之諸侯違諸侯之大夫不反照世子不爲']4.文档解析
另一个特殊功能是文档图片解析成 html 格式文本,官方指南给出了很多示例,这里拿网上公开的财报图片做测试。
官方给出的提示词如下。
question = "QwenVL HTML with image caption"财报图片如下。
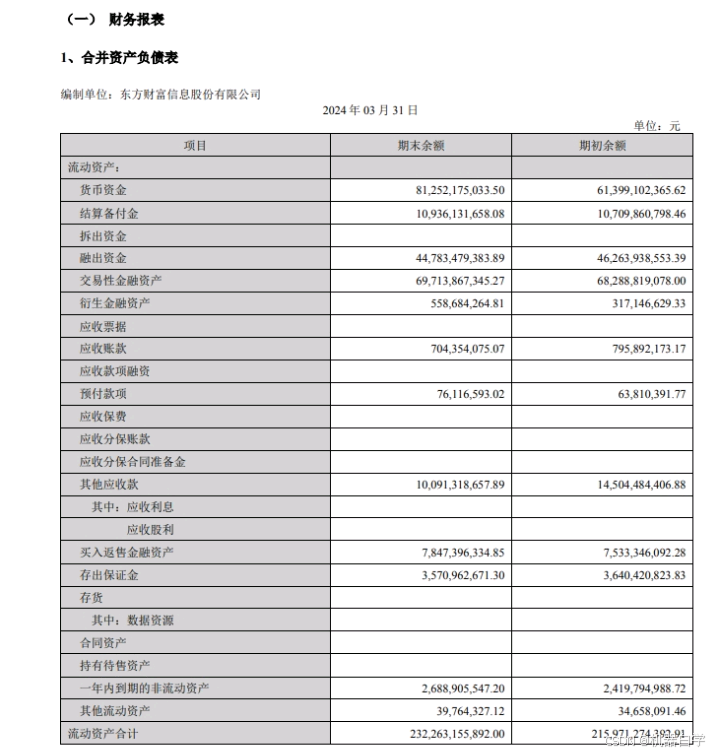
推理结果如下。
# Qwen2.5-VL-3B的文档解析推理结果
['```html\n<table>\n <tr>\n <td>项目</td>\n <td>期末余额</td>\n <td>期初余额</td>\n </tr>\n <tr>\n <td>流动资产:</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>货币资金</td>\n <td>81,252,175.033.50</td>\n <td>61,399,102,365.62</td>\n </tr>\n <tr>\n <td>结算备付金</td>\n <td>10,936,131,658.08</td>\n <td>10,709,860,798.46</td>\n </tr>\n <tr>\n <td>拆出资金</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>融出资金</td>\n <td>44,783,479,383.89</td>\n <td>46,263,938,553.39</td>\n </tr>\n <tr>\n <td>交易性金融资产</td>\n <td>69,713,867,345.27</td>\n <td>68,288,819,078.00</td>\n </tr>\n <tr>\n <td>衍生金融资产</td>\n <td>558,684,264.81</td>\n <td>317,146,629.33</td>\n </tr>\n <tr>\n <td>应收票据</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>应收账款</td>\n <td>704,354,075.07</td>\n <td>795,892,173.17</td>\n </tr>\n <tr>\n <td>应收款项融资</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>预付款项</td>\n <td>76,116,593.02</td>\n <td>63,810,391.77</td>\n </tr>\n <tr>\n <td>应收保费</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>应收分保账款</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>应收分保合同准备金</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>其他应收款</td>\n <td>10,091,318,657.89</td>\n <td>14,504,484,406.88</td>\n </tr>\n <tr>\n <td>其中:应收利息</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>应收股利</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>买入返售金融资产</td>\n <td>7,847,396,334.85</td>\n <td>7,533,346,092.28</td>\n </tr>\n <tr>\n <td>存出保证金</td>\n <td>3,570,962,671.30</td>\n <td>3,640,420,823.83</td>\n </tr>\n <tr>\n <td>存货</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>其中:数据资源</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>合同资产</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>持有待售资产</td>\n <td></td>\n <td></td>\n </tr>\n <tr>\n <td>一年内到期的非流动资产</td>\n <td>2,688,905,547.20</td>\n <td>2,419,794,988.72</td>\n </tr>\n <tr>\n <td>其他流动资产</td>\n <td>39,764,327.12</td>\n <td>34,658,091.46</td>\n </tr>\n <tr>\n <td>流动资产合计</td>\n <td>232,263,155,892.00</td>\n <td>215,971,274,392.91</td>\n </tr>\n</table>\n```']
可以把结果写入 txt 文件中,然后改后缀为 html 后,使用浏览器查看。

5.视频理解
视频同样支持输入,这里不做实验记录了。附上官方示例图片。

需要注意的是视频输入的使用方式,写入 run_video.py 文件,代码如下。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import os
model_path = 'path/to/save' # 修改为本地模型下载地址
video_path = "path/to/jpg" # 输入视频地址
question = "Describe this video."
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_path, torch_dtype="auto", device_map="auto")
processor = AutoProcessor.from_pretrained(model_path)
# 视频输入
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": video_path,
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": question},
],
}
]
# 输入配置
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
fps=fps,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# 推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)至此 Qwen2.5-VL 多模态大模型的环境安装与基本使用测试完成,在下一篇文章将详细记录其更大量级的模型(7B、72B)在服务端的部署操作,并使用客户端上传图片和提问。


















 947
947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









