







pod控制器详解
文章目录
污点和容忍调度
污点(Taints)
前面的调度方式都是站在Pod的角度上,通过在Pod上添加属性,来确定Pod是否要调度到指定的Node上,其实我们也可以站在Node的角度上,通过在Node上添加污点属性,来决定是否允许Pod调度过来。
Node被设置上污点之后就和Pod之间存在了一种相斥的关系,进而拒绝Pod调度进来,甚至可以将已经存在的Pod驱逐出去。
污点的格式为:key=value:effect, key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
- PreferNoSchedule:kubernetes将尽量避免把Pod调度到具有该污点的Node上,除非没有其他节点可调度
- NoSchedule:kubernetes将不会把Pod调度到具有该污点的Node上,但不会影响当前Node上已存在的Pod
- NoExecute:kubernetes将不会把Pod调度到具有该污点的Node上,同时也会将Node上已存在的Pod驱离

使用kubectl设置和去除污点的命令示例如下:
设置污点
kubectl taint nodes node1 key=value:effect
去除污点
kubectl taint nodes node1 key:effect-
去除所有污点
kubectl taint nodes node1 key
接下来,演示下污点的效果:
- 准备节点node1(为了演示效果更加明显,暂时停止node2节点)
- 为node1节点设置一个污点: tag=chenyu:PreferNoSchedule;然后创建pod1( pod1 可以 )
- 修改为node1节点设置一个污点: tag=chenyu:NoSchedule;然后创建pod2( pod1 正常 pod2 失败 )
- 修改为node1节点设置一个污点: tag=chenyu:NoExecute;然后创建pod3 ( 3个pod都失败 )
# 为node1设置污点(PreferNoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=chenyu:PreferNoSchedule
# 创建pod1
[root@k8s-master01 ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
# 为node1设置污点(取消PreferNoSchedule,设置NoSchedule)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag:PreferNoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=chenyu:NoSchedule
# 创建pod2
[root@k8s-master01 ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods taint2 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint1-7665f7fd85-574h4 1/1 Running 0 2m24s 10.244.1.59 node1
taint2-544694789-6zmlf 0/1 Pending 0 21s <none> <none>
# 为node1设置污点(取消NoSchedule,设置NoExecute)
[root@k8s-master01 ~]# kubectl taint nodes node1 tag:NoSchedule-
[root@k8s-master01 ~]# kubectl taint nodes node1 tag=chenyu:NoExecute
# 创建pod3
[root@k8s-master01 ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
taint1-7665f7fd85-htkmp 0/1 Pending 0 35s <none> <none> <none>
taint2-544694789-bn7wb 0/1 Pending 0 35s <none> <none> <none>
taint3-6d78dbd749-tktkq 0/1 Pending 0 6s <none> <none> <none>
小提示:
使用kubeadm搭建的集群,默认就会给master节点添加一个污点标记,所以pod就不会调度到master节点上.
容忍(Toleration)
上面介绍了污点的作用,我们可以在node上添加污点用于拒绝pod调度上来,但是如果就是想将一个pod调度到一个有污点的node上去,这时候应该怎么做呢?这就要使用到容忍。

污点就是拒绝,容忍就是忽略,Node通过污点拒绝pod调度上去,Pod通过容忍忽略拒绝
下面先通过一个案例看下效果:
1、上一小节,已经在node1节点上打上了NoExecute的污点,此时pod是调度不上去的
2、本小节,可以通过给pod添加容忍,然后将其调度上去
创建pod-toleration.yaml,内容如下
apiVersion: v1
kind: Pod
metadata:
name: pod-toleration
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
tolerations: # 添加容忍
- key: "tag" # 要容忍的污点的key
operator: "Equal" # 操作符
value: "chenyu" # 容忍的污点的value
effect: "NoExecute" # 添加容忍的规则,这里必须和标记的污点规则相同
# 添加容忍之前的pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 0/1 Pending 0 3s <none> <none> <none>
# 添加容忍之后的pod
[root@k8s-master01 ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
pod-toleration 1/1 Running 0 3s 10.244.1.62 node1 <none>
下面看一下容忍的详细配置:
[root@k8s-master01 ~]# kubectl explain pod.spec.tolerations
......
FIELDS:
key # 对应着要容忍的污点的键,空意味着匹配所有的键
value # 对应着要容忍的污点的值
operator # key-value的运算符,支持Equal和Exists(默认)
effect # 对应污点的effect,空意味着匹配所有影响
tolerationSeconds # 容忍时间, 当effect为NoExecute时生效,表示pod在Node上的停留时间
Pod控制器介绍
Pod是kubernetes的最小管理单元,在kubernetes中,按照pod的创建方式可以将其分为两类:
- 自主式pod:kubernetes直接创建出来的Pod,这种pod删除后就没有了,也不会重建
- 控制器创建的pod:kubernetes通过控制器创建的pod,这种pod删除了之后还会自动重建
什么是Pod控制器
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod。
在kubernetes中,有很多类型的pod控制器,每种都有自己的适合的场景,常见的有下面这些:
- ReplicationController:比较原始的pod控制器,已经被废弃,由ReplicaSet替代
- ReplicaSet:保证副本数量一直维持在期望值,并支持pod数量扩缩容,镜像版本升级
- Deployment:通过控制ReplicaSet来控制Pod,并支持滚动升级、回退版本
- Horizontal Pod Autoscaler:可以根据集群负载自动水平调整Pod的数量,实现削峰填谷
- DaemonSet:在集群中的指定Node上运行且仅运行一个副本,一般用于守护进程类的任务
- Job:它创建出来的pod只要完成任务就立即退出,不需要重启或重建,用于执行一次性任务
- Cronjob:它创建的Pod负责周期性任务控制,不需要持续后台运行
- StatefulSet:管理有状态应用
ReplicaSet(RS)
ReplicaSet的主要作用是保证一定数量的pod正常运行,它会持续监听这些Pod的运行状态,一旦Pod发生故障,就会重启或重建。同时它还支持对pod数量的扩缩容和镜像版本的升降级。
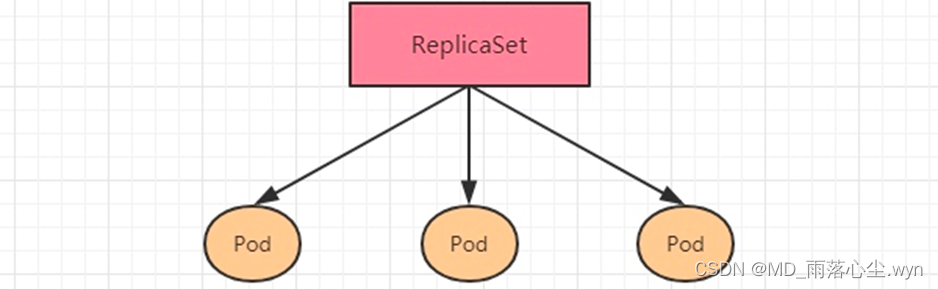
ReplicaSet的资源清单文件:
apiVersion: apps/v1 # 版本号
kind: ReplicaSet # 类型
metadata: # 元数据
name: # rs名称
namespace: # 所属命名空间
labels: #标签
controller: rs
spec: # 详情描述
replicas: 3 # 副本数量
selector: # 选择器,通过它指定该控制器管理哪些pod
matchLabels: # Labels匹配规则
app: nginx-pod
matchExpressions: # Expressions匹配规则
- {key: app, operator: In, values: [nginx-pod]}
template: # 模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
ports:
- containerPort: 80
在这里面,需要新了解的配置项就是spec下面几个选项:
- replicas:指定副本数量,其实就是当前rs创建出来的pod的数量,默认为1
- selector:选择器,它的作用是建立pod控制器和pod之间的关联关系,采用的Label Selector机制
- 在pod模板上定义label,在控制器上定义选择器,就可以表明当前控制器能管理哪些pod了
- template:模板,就是当前控制器创建pod所使用的模板,里面其实就是前一章学过的pod的定义
创建ReplicaSet
创建pc-replicaset.yaml文件,内容如下:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: pc-replicaset
namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.17.1
# 创建rs
[root@k8s-master01 ~]# kubectl create -f pc-replicaset.yaml
replicaset.apps/pc-replicaset created
# 查看rs# DESIRED:期望副本数量 # CURRENT:当前副本数量 # READY:已经准备好提供服务的副本数量
[root@k8s-master01 ~]# kubectl get rs pc-replicaset -n dev -o wide
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
pc-replicaset 3 3 3 22s nginx nginx:1.17.1 app=nginx-pod
# 查看当前控制器创建出来的pod# 这里发现控制器创建出来的pod的名称是在控制器名称后面拼接了-xxxxx随机码
[root@k8s-master01 ~]# kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
pc-replicaset-6vmvt 1/1 Running 0 54s
pc-replicaset-fmb8f 1/1 Running 0 54s
pc-replicaset-snrk2 1/1 Running 0 54s
扩缩容
# 编辑rs的副本数量,修改spec:replicas: 6即可
[root@k8s-master01 ~]# kubectl edit rs pc-replicaset -n dev
replicaset.apps/pc-replicaset edited
# 查看pod
[root@k8s-master01 ~]# kubect 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









