




1 研究目的和方法
研究目的是为了提高目标检测的准确性和速度。
研究方法包括单阶段训练、多任务损失函数、感兴趣区域(RoI)池化层和端到端训练等。
2 主要发现和结论
显著提升检测速度、提高检测准确性、单阶段训练更有优势、多任务损失函数的有效性、感兴趣区域(RoI)池化层的重要性和端到端训练的可行性。
3 Fast R-CNN的结构和训练
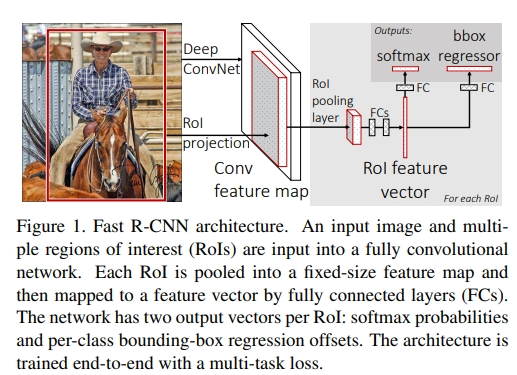
输入是一张图片和一组感兴趣区域,每个RoI被池化为一个固定大小的特征图,然后通过全连接层映射成一个特征向量,输出是两个向量,softmax概率和边界框回归偏移量。
3.1 RoI池化层
RoI池化层的任务是把感兴趣区域的特征转化成固定大小的特征图,特征图的长宽是一个超参数可以自己设置。
这里的RoI层是SPPnets中使用的空间金字塔池化层的一个特例,在SPPnet中,空间金字塔池化层可以有多个金字塔层级,这意味着它可以在多个尺度上对输入特征图进行池化,从而生成一系列不同尺寸的池化特征图。而在Fast R-CNN中,RoI层采用了单一金字塔层级的策略。这意味着对于每个RoI,它只生成一个固定大小的特征向量,而不是一系列不同尺度的特征向量。这样做简化了模型的结构,减少了计算量。
3.2 预训练网络的初始化
作者使用了三个预训练的ImageNet网络进行实验,这些网络各有五个最大池化层和五到十三个卷积层。当一个预训练的网络被用来初始化Fast R-CNN网络时,它会经历三个转换步骤:
-
替换最后一个最大池化层:原始网络中的最后一个最大池化层被替换为一个RoI(区域感兴趣)池化层。这个RoI池化层被配置为设置H和W的值,以确保与网络的第一个全连接层兼容(例如,对于VGG16,H和W都设置为7)。
-
替换最后的全连接层和Softmax:原始网络中的最后一个全连接层和Softmax层(这些层原本是针对1000类ImageNet分类任务进行训练的)被替换为两个新的层。这两个层包括一个新的全连接层和一个新的Softmax层,后者针对K+1个类别(包括背景类别)进行分类,并且还有针对每个类别的边界框回归器。
-
修改网络以接受两个数据输入:网络被修改为接受两个数据输入,一个是图像列表,另一个是这些图像中的RoI列表。
3.3 微调
在R-CNNE和SPPnet的训练中,每个RoI都需要独立处理整个输入图像的接收域,因为每个RoI可能覆盖整个图像的不同部分。这意味着在反向传播过程中,需要对整个接收域进行梯度计算,这导致了计算量大、效率低。
由于每个RoI可能具有非常大的接收域,通常覆盖整个输入图像,因此在前向传播过程中必须处理整个接收域。这使得训练输入的大小通常很大(通常是整个图像),从而导致了训练效率的降低。为了解决这个问题,Fast R-CNN提出了一种更高效的训练方法,该方法在训练过程中利用了特征共享的优势。
在Fast R-CNN的训练中,随机梯度下降(SGD)的小批量样本是分层采样的,首先采样N个图像,然后从每个图像中采样R/N个RoIs。这样,来自同一图像的RoIs在前向和后向传播中共享计算和内存。通过使N保持较小,可以减少小批量计算的规模。例如,当使用N=2和R=128时,所提出的训练方案大约比从128个不同图像中采样一个RoI的策略(即R-CNN和SPPnet的策略)快64倍。
此外,Fast R-CNN还使用了一个简化的训练流程,其中只有一个微调阶段,该阶段联合优化了softmax分类器和边界框回归器,而不是像R-CNN和SPPnet那样在三个独立的阶段中分别训练softmax分类器、SVM和回归器。这种方法提高了训练效率,并允许网络通过反向传播更新所有层的权重,从而提高了目标检测的性能。
多任务损失:
网络有两个输出层,一个是分类层,一个是边界框回归层。
分类层为每一个RoI输出一个离散的概率分布,这个概率分布是通过全连接层的K+1个输出值应用softmax函数计算得到的(K个类别加上一个背景类别)。
边界框回归层输出每个类别的边界框回归偏移量,包括边界框的中心坐标偏移以及宽度和高度的相对偏移。
多任务损
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









