






Abstract
We investigate the design aspects of feature distillation methods achieving network compression and propose a novel feature distillation method in which the distillation loss is designed to make a synergy among various aspects: teacher transform, student transform, distillation feature position and distance function. Our proposed distillation loss includes a feature transform with a newly designed margin ReLU, a new distillation feature position, and a partial L2 distance function to skip redundant information giving adverse effects to the compression of student. In ImageNet, our proposed method achieves 21.65% of top-1 error with ResNet50, which outperforms the performance of the teacher network, ResNet152. Our proposed method is evaluated on various tasks such as image classification, object detection and semantic segmentation and achieves a significant performance improvement in all tasks.
翻译:
我们研究了实现网络压缩的特征蒸馏方法的设计方面,并提出了一种新颖的特征蒸馏方法,其中蒸馏损失被设计为在各个方面之间产生协同作用:教师转换、学生转换、蒸馏特征位置和距离函数。我们提出的蒸馏损失包括一个具有新设计的边界ReLU的特征转换,一个新的蒸馏特征位置,以及一个部分L2距离函数,以跳过给学生网络压缩带来不利影响的冗余信息。在ImageNet上,我们提出的方法使用ResNet50达到了21.65%的top-1错误率,优于教师网络ResNet152的性能。我们的方法在各种任务中进行了评估,如图像分类、目标检测和语义分割,并在所有任务中实现了显著的性能提升
Introduction
Hint learning没有很好地利用特征蒸馏,更多的提点仍来自于输出蒸馏
After FitNets, variant methods of feature distillation have been proposed as follows. The methods in [30, 28] transform the feature into a representation having a reduced dimension and transfer it to the student. In spite of the reduced dimension, it has been reported that the abstracted feature representation does lead to an improved performance. Recent methods (FT [13], AB [7]) have been proposed to increase the amount of transferred information in distillation. FT [13] encodes the feature into a ‘factor’ using an auto-encoder to alleviate the leakage of information. AB [7] focuses on activation of a network with only the sign of features being transferred. Both methods show a better distillation performance by increasing the amount of transferred information. However, FT [13] and AB [7] deform feature values of the teacher, which leaves a further room for the performance to be improved.
翻译:
在FitNets之后,提出了一些变种的特征蒸馏方法,具体如下。在文献[30, 28]中提出的方法将特征转换为具有降维的表示,并将其传输给学生网络。尽管维度降低了,但据报道,提取的特征表示确实导致了性能的提升。最近提出的方法(FT [13]、AB [7])旨在增加蒸馏中传输的信息量。FT [13]使用自编码器将特征编码为‘因子’,以减轻信息泄漏。AB [7]专注于仅传输特征的符号的网络激活。这两种方法通过增加传输的信息量来展现出更好的蒸馏性能。然而,FT [13]和AB [7]会改变教师网络的特征值,这进一步为性能的提升留下了空间
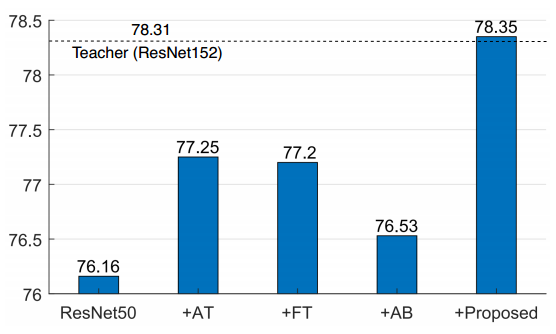
In this paper, we further improve the performance of feature distillation by proposing a new feature distillation loss which is designed via investigation of various design aspects: teacher transform, student transform, distillation feature position and distance function. Our method aims to transfer two factors from features. The first target is the magnitude of feature response after ReLU, since it carries most of the feature information. The second is the activation status of each neuron. Recent studies [20, 7] have shown that the activation of neurons strongly represents the expressiveness of a network, and it should be considered in distillation. To this purpose, we propose a margin ReLU function, change the distillation feature position to the front of ReLU, and use a partial L2 distance function to skip the distillation of unnecessary information. The proposed loss significantly improves performance of feature distillation. In our experiments, we have evaluated our proposed method in various domains including classification (CIFAR [15], ImageNet [23]), object detection (PASCAL VOC [2]) and semantic segmentation (PASCAL VOC). As shown in Fig. 1, in our experiments, the proposed method shows a performance superior to the existing state-of-the-art methods and even the teacher model.
翻译:
本文通过对各种设计方面的调查,包括教师变换、学生变换、蒸馏特征位置和距离函数,进一步改进了特征蒸馏的性能,提出了一种新的特征蒸馏损失。我们的方法旨在从特征中传输两个因素。第一个目标是经过ReLU后的特征响应的幅度,因为它携带了大部分的特征信息。第二个是每个神经元的激活状态。最近的研究[20, 7]表明,神经元的激活强烈地代表了网络的表达能力,并且在蒸馏中应予以考虑。为此,我们提出了一个边缘ReLU函数,将蒸馏特征位置改变到ReLU的前面,并使用一个部分L2距离函数来跳过不必要信息的蒸馏。提出的损失显著提高了特征蒸馏的性能。在我们的实验中,我们评估了我们的方法在各个领域的性能,包括分类(CIFAR [15],ImageNet [23]),目标检测(PASCAL VOC [2])和语义分割(PASCAL VOC)。如图1所示,在我们的实验中,所提出的方法显示出比现有的最先进方法甚至教师模型更优异的性能
总结:
第一个是经过ReLU激活之后的特征响应的大小
第二个是每个神经元的激活状态。
提出了一个margin ReLU激活函数,并且利用一个局部的L2正则化进行距离度量,以此来跳过对非必要信息的蒸馏
Motivation
Teacher transform
Hint learning等方法对教师模型的特征进行变换后再与学生guide,损失了教师信息
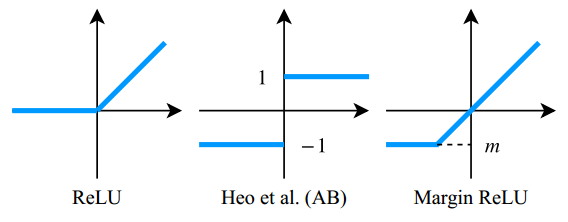
使用一种新的ReLU激活,称为边缘ReLU。正面(有益的)信息被使用而不进行任何转换,而负面(不利的)信息被抑制。
Student transform
使用1×1卷积层作为学生变换来匹配特征维度与教师特征。在这种情况下,学生的特征尺寸没有减少,而是增加了,因此没有信息丢失
Distillation feature position
FitNets使用任意中间层的末端作为蒸馏点,但被证明具有较差的性能
ReLU允许有益信息(正值)通过,并过滤掉不良信息(负值)。因此,知识蒸馏必须在承认这种信息消解的情况下设计。在我们的方法中,我们设计了蒸馏损失,将特征放在ReLU函数的前面,称为pre-ReLU
Distance function
过ReLU之前蒸馏,负的信息本来过ReLU会被排除,但是这里盲目的用L1/L2会传递不利信息,所以需要有选择性的使用L2
Approach
Distillation position
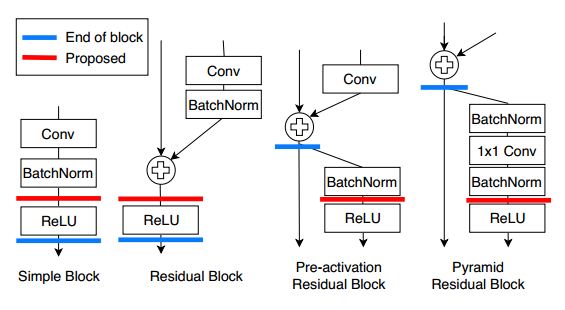
蒸馏的位置位于第一个ReLU和每一个block之间
因为预激活的网络在每一个block后没有ReLU,因此本文的方法需要在下一个block中寻找ReLU。虽然蒸馏位置根据体系结构的不同可能会比较复杂,但是实验证明它对性能有很大的影响
Loss function
如果教师的一个值是正的,学生必须产生与教师相同的值。相反,如果老师的一个值是负的,学生应该产生一个小于零的值,以使神经元的激活状态相同
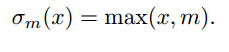
m是一个小于零的边距值。我们将这个函数命名为margin ReLU
余量值m被定义为负响应的每个通道的期望值
期望值可以在训练过程中直接计算,也可以使用之前批归一化层的参数计算。在我们提出的方法中,将余量ReLU σmC(·)用作教师变换Tt,生成学生网络的目标特征值。对于学生变换,使用由1 × 1卷积层和批归一化层组成的回归量
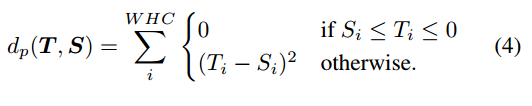
总蒸馏损失为:

使用蒸馏损失蒸馏器进行连续蒸馏。因此,最终的损失函数为蒸馏损失与任务损失之和:
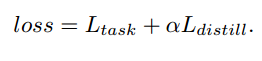
Batch normalization
通常,学生网络的特征是逐批进行归一化的。因此,教师网络的特征也必须以同样的方式归一化。也就是说,教师网络应该在训练时进行批处理归一化。为此,作者在1x1的卷积层之后附加一个BN层,在学生网络的设置上也是如此。
Experiments
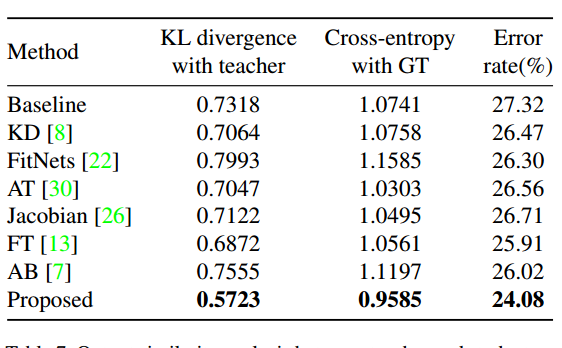
在CIFAR100验证集上,测量了学生网络和教师网络的KL散度以及与Ground-Truth的交叉熵
确实显著降低了散度值
Conclusion
We propose a new knowledge distillation method along with several investigations about various aspects of the existing feature distillation methods. We have discovered the effectiveness of pre-ReLU location and proposed a new loss function to improve the performance of feature distillation.
The new loss function consists of a teacher transform (margin ReLU) and a new distance function (partial L2) and enables an effective feature distillation at pre-ReLU location. We have also investigated about the mode of batch normalization in teacher network and achieved additional performance improvements. Through experiments, we examined the performance of the proposed method using various networks in various tasks, and proved that the proposed method substantially outperforms the state-of-the-arts of feature distillation.
翻译:
我们提出了一种新的知识蒸馏方法,并对现有特征蒸馏方法的各个方面进行了几项研究。我们发现了在ReLU之前的位置的有效性,并提出了一种新的损失函数来改善特征蒸馏的性能。
新的损失函数包括一个教师变换(边缘ReLU)和一个新的距离函数(部分L2),并在ReLU之前的位置实现了有效的特征蒸馏。我们还研究了教师网络中批量归一化的模式,并实现了额外的性能改进。通过实验证明,我们提出的方法在各种网络和各种任务中的性能,远远超过了特征蒸馏的现有技术水平。















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









