







 本文档详细介绍了如何在已安装的Spark-bench和Spark环境下配置并运行性能测试。首先在指定目录创建并编辑配置文件,如test.conf和csv.conf,设置工作负载参数。接着在HDFS上创建数据存储目录,然后启动HDFS和Spark服务。在从节点上执行测试脚本,最后通过Spark历史服务器和监控界面分析执行结果,评估集群性能。
本文档详细介绍了如何在已安装的Spark-bench和Spark环境下配置并运行性能测试。首先在指定目录创建并编辑配置文件,如test.conf和csv.conf,设置工作负载参数。接着在HDFS上创建数据存储目录,然后启动HDFS和Spark服务。在从节点上执行测试脚本,最后通过Spark历史服务器和监控界面分析执行结果,评估集群性能。
需要在spark-bench_2.3.0_0.4.0-RELEASE和spark-2.1.1-bin-hadoop2.7均安装配置完成的情况下进行
1、在/home/hadoop/sparkbench/examples目录下创建测试文件test.conf和csv.conf文件
cd spark-bench_2.3.0_0.4.0-RELEASE/cd examples/1.1、创建test.conf文件
vim test.conf 
在test.conf文件下添加如下内容:
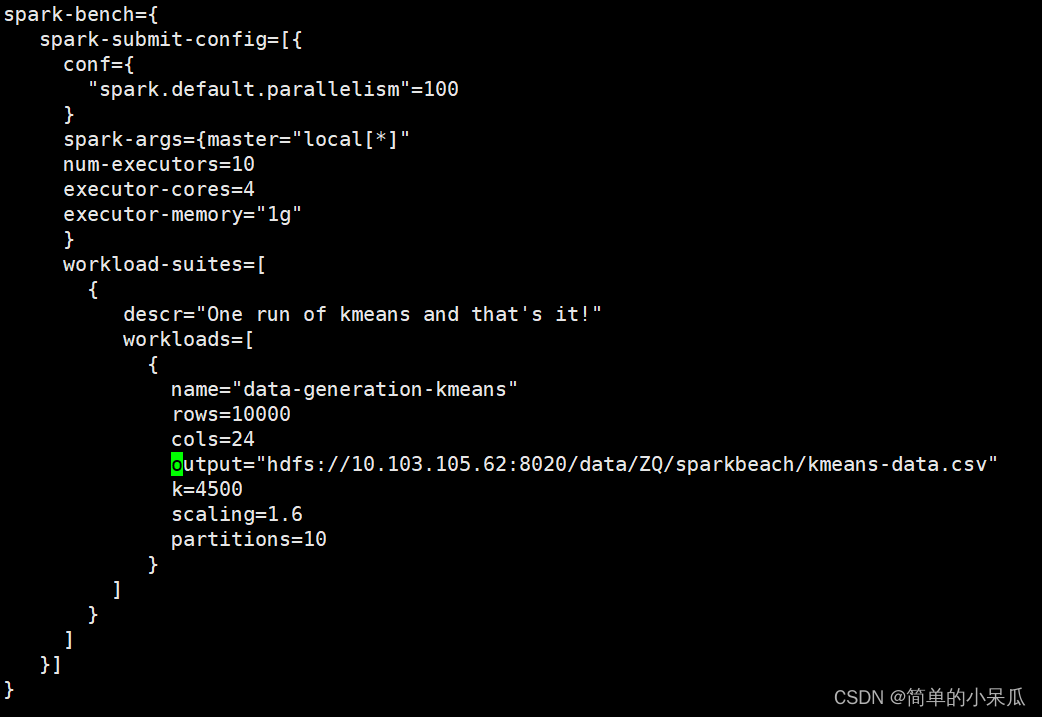
spark-bench={
spark-submit-config=[{
conf={
"spark.default.parallelism"=100
}
spark-args={master="local[*]"
num-executors=10
executor-cores=4
executor-memory="1g"
}
workload-suites=[
{
descr="One run of kmeans and that's it!"
workloads=[
{
name="data-generation-kmeans"
rows=10000
cols=24
output="hdfs://10.103.105.62:8020/data/ZQ/sparkbench/kmeans-data.csv"
k=4500
scaling=1.6
partitions=10
}
]
}
]
}]
}
1.2、创建csv.conf文件
vim csv.conf在文件csv.conf中添加如下内容:
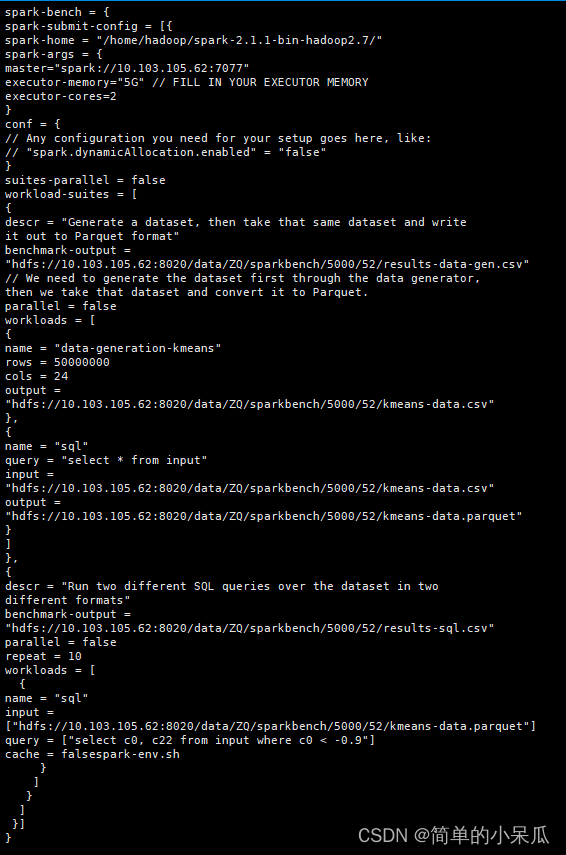
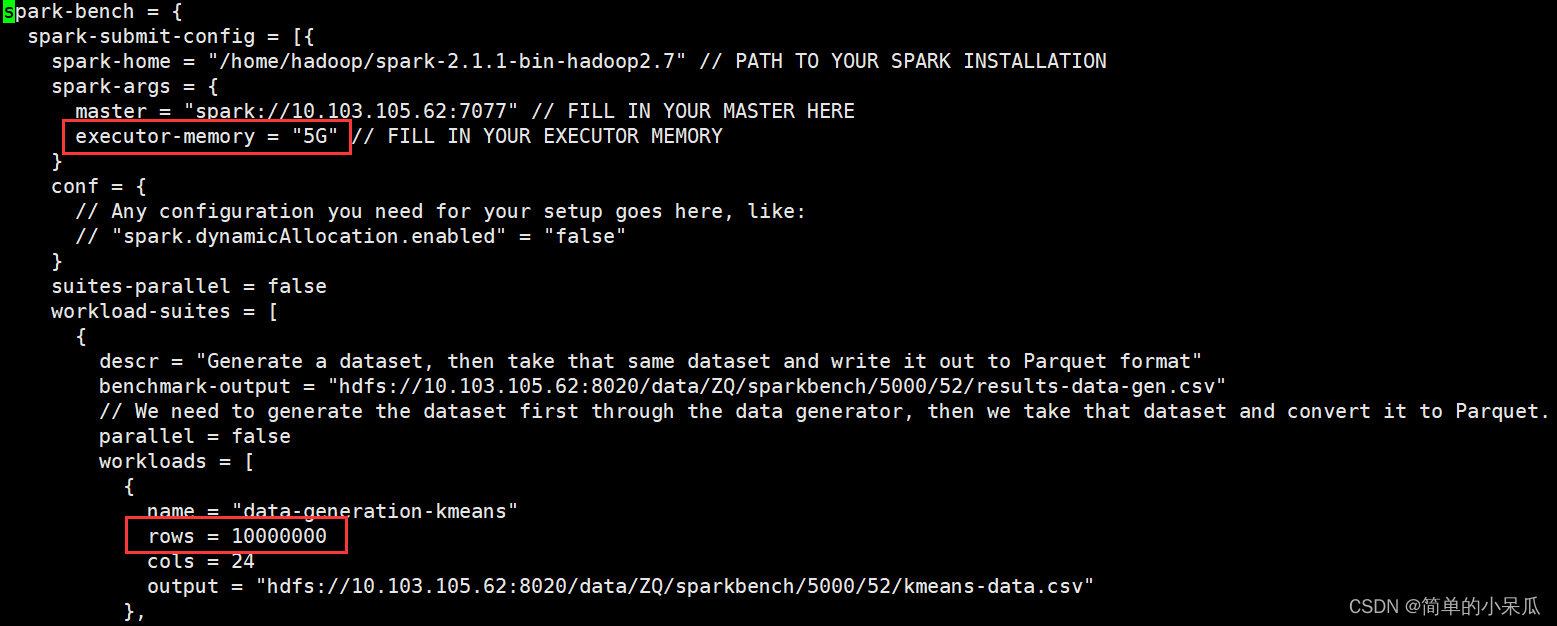
spark-bench = {
spark-submit-config = [{
spark-home = "/home/hadoop/spark-2.1.1-bin-hadoop2.7/"
spark-args = {
master="spark://10.103.105.62:7077"
executor-memory="5G" // FILL IN YOUR EXECUTOR MEMORY
executor-cores=2
}
conf = {
// Any configuration you need for your setup goes here, like:
// "spark.dynamicAllocation.enabled" = "false"
}
suites-parallel = false
workload-suites = [
{
descr = "Generate a dataset, then take that same dataset and write
it out to Parquet format"
benchmark-output =
"hdfs://10.103.105.62:8020/data/ZQ/sparkbench/5000/52/results-data-gen.csv"
// We need to generate the dataset first through the data generator,
then we take that dataset and convert it to Parquet.
parallel = false
workloads = [
{
name = "data-generation-kmeans"
rows = 50000000
cols = 24
output =
"hdfs://10.103.105.62:8020/data/ZQ/sparkbench/5000/52/kmeans-data.csv"
},
{
name = "sql"
query = "select * from input"
input =
"hdfs://10.103.105.62:8020/data/ZQ/sparkbench/5000/52/kmeans-data.csv"
output =
"hdfs://10.103.105.62:8020/data/ZQ/sparkbench/5000/52/kmeans-data.parquet"
}
]
},
{
descr = "Run two different SQL queries over the dataset in two
different formats"
benchmark-output =
"hdfs://10.103.105.62:8020/data/ZQ/sparkbench/5000/52/results-sql.csv"
parallel = false
repeat = 10
workloads = [
{
name = "sql"
input =
["hdfs://10.103.105.62:8020/data/ZQ/sparkbench/5000/52/kmeans-data.parquet"]
query = ["select c0, c22 from input where c0 < -0.9"]
cache = falsespark-env.sh
}
]
}
]
}]
}
1.3、修改csv-vs-parquet.conf文件
vim csv-vs-parquet.conf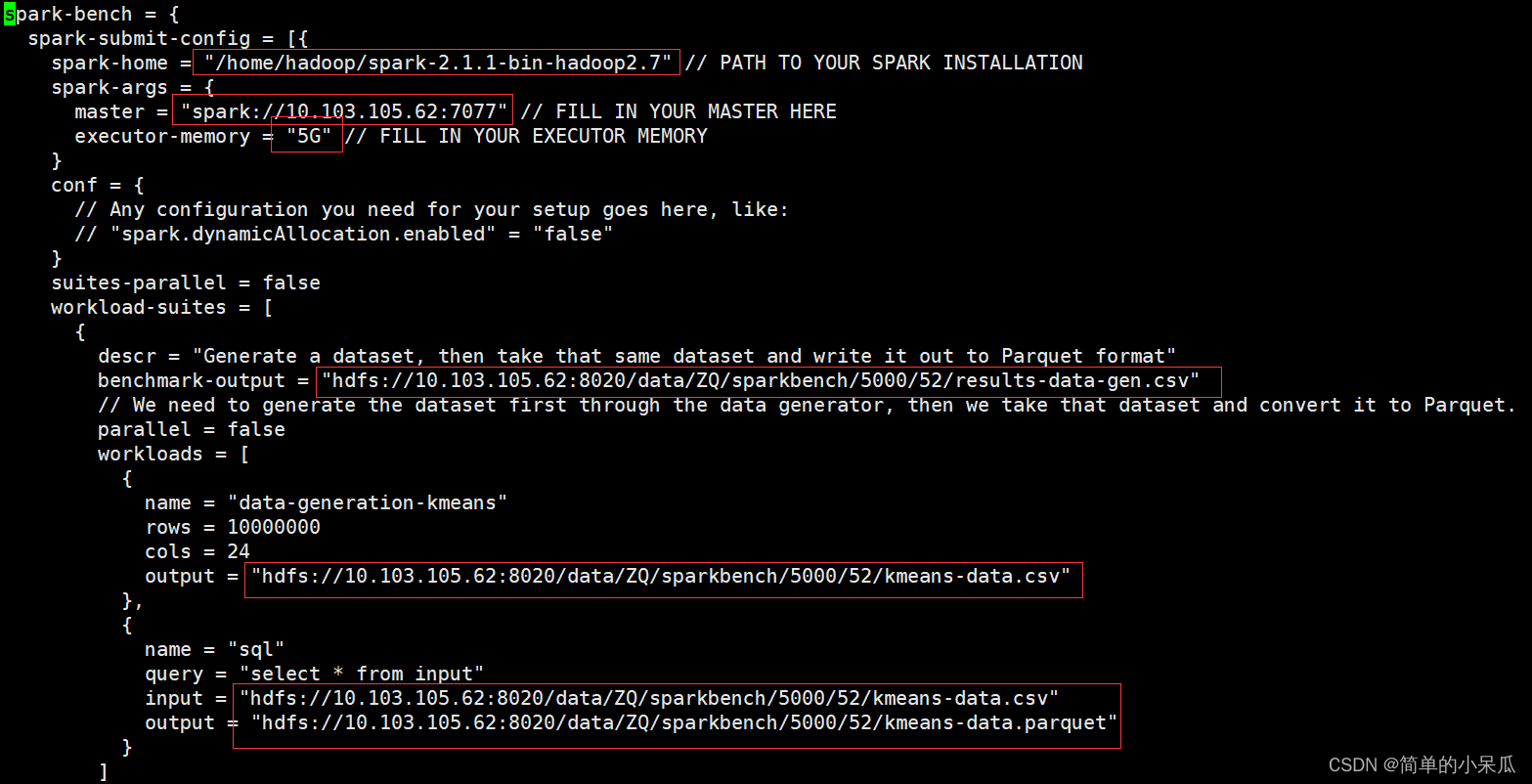

2、在HDFS上创建文件夹/data/ZQ/sparkbench(可以直接创建/data/ZQ即可)
cdhadoop fs -mkdir -p /data/ZQ/sparkbench
3、运行
在主节点上启动HDFS(62)
start-dfs.sh
在主节点上启动Spark
$SPARK_HOME/sbin/start-master.sh$SPARK_HOME/sbin/start-slaves.sh 
在从节点上运行(63)
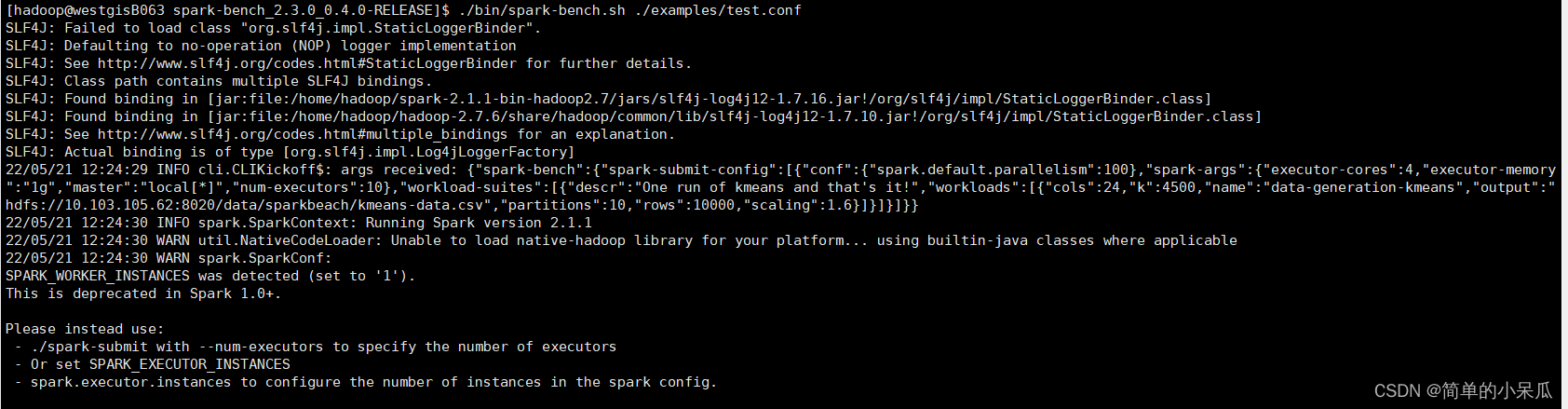
cd spark-bench_2.3.0_0.4.0-RELEASE/./bin/spark-bench.sh ./examples/test.conf
./bin/spark-bench.sh ./examples/csv-vs-parquet.conf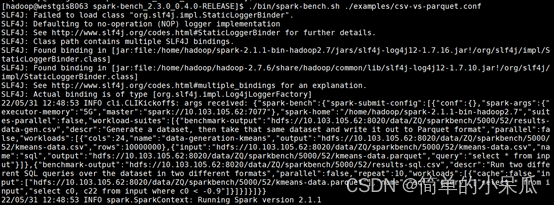
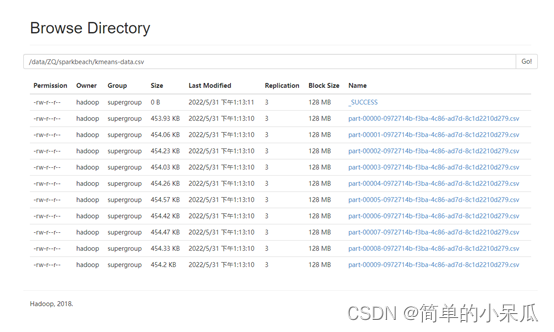
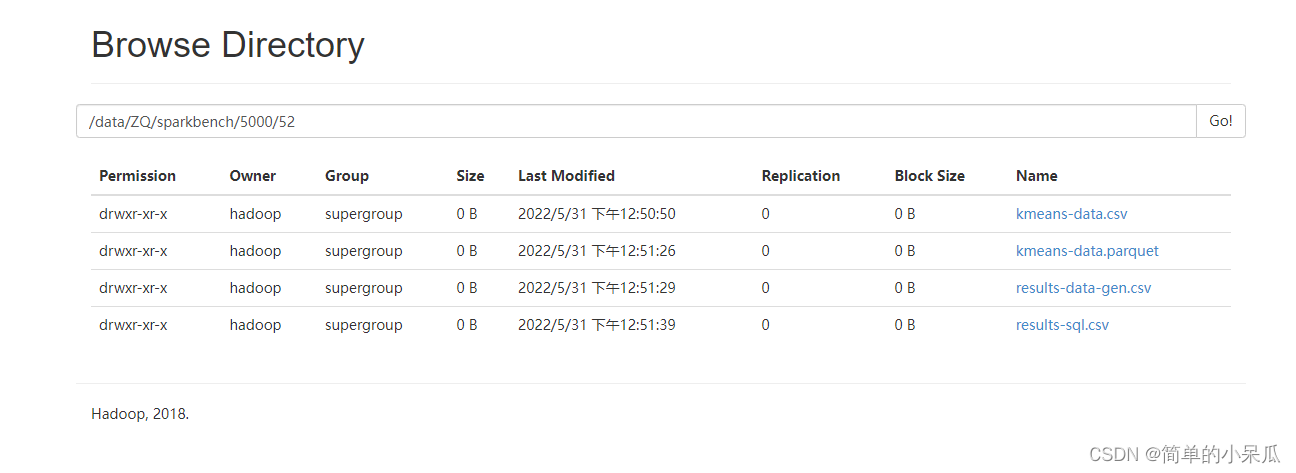
4、查看执行结果
在浏览器下搜索: 10.103.106.62:50070
5、关闭HDFS和Spark(62)
stop-dfs.sh 
$SPARK_HOME/sbin/start-slaves.sh$SPARK_HOME/sbin/stop-master.sh
6、分析结果(62)
6.1、安装配置spark-server
spark-env.sh
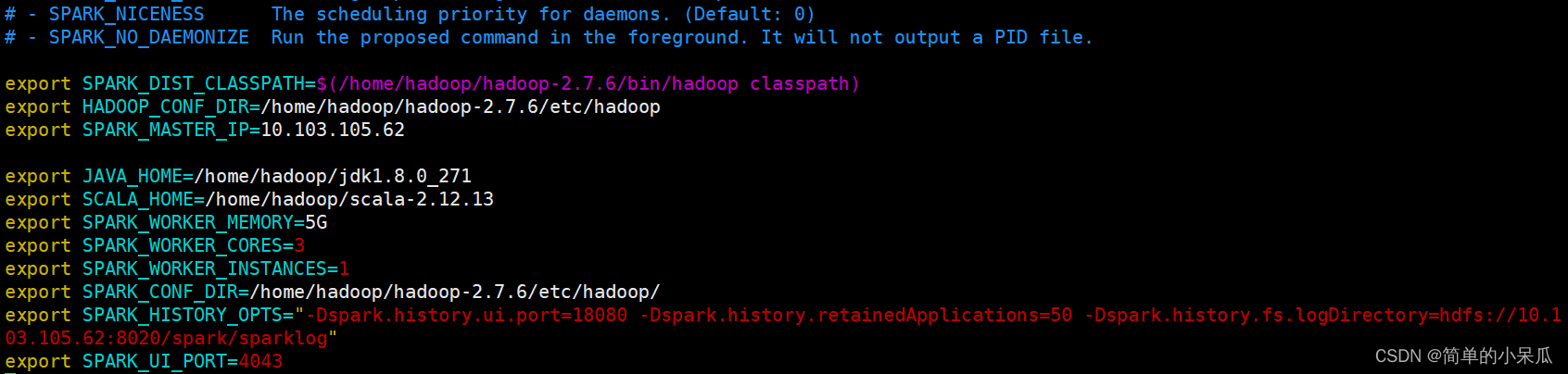
cd spark-2.1.1-bin-hadoop2.7/confvim spark-env.sh
在文件末尾增加如下内容:
export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-2.7.6/bin/hadoop classpath)
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=10.103.105.62
export JAVA_HOME=/home/hadoop/jdk1.8.0_271
export SCALA_HOME=/home/hadoop/scala-2.12.13
export SPARK_WORKER_MEMORY=5G
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_CONF_DIR=/home/hadoop/hadoop-2.7.6/etc/hadoop/
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://10.103.105.62:8020/spark/sparklog"
export SPARK_UI_PORT=4043
spark-defaults.conf
vim spark-defaults.conf 
在文件末尾增加如下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://10.103.105.62:8020/data/spark/sparklog
spark.eventLog.compress true
6.2、启动命令
cd .../sbin/start-history-server.sh
6.3、查看结果
在浏览器中搜索 http://10.103.105.62:18080 即可查看到结果
更改代码中的executor-memory、executor-cores及数据量分析结果 分析集群性能可通过监控界面中的运行时间,内存使用,磁盘使用,核心数等进行分析
6.3、关闭
cd spark-2.1.1-bin-hadoop2.7/ ./sbin/stop-history-server.sh
















 7081
7081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









