







数据准备
1、数据来源:淘宝用户购物行为数据集
数据的相关介绍:
数据的一条记录包括:用户id,商品id,商品类目id,行为类型(行为类型:pv——点击,buy——购买,cart——加入购物车,fav——收藏),时间戳
数据包含了2017年11月25日至2017年12月3日之间淘宝用户的数据行为
用户数量:987994
商品数量:4162024
用户数量:987994
商品类目数量:9439
所有行为数量:100150807
2.上传数据
- 上传数据(将数据上传到hdfs)
新建文件夹data
mkdir data
将数据上传到xshell中的data文件夹

在hdfs上建立文件夹zq/data
hdfs dfs -mkdir /zq
hdfs dfs -mkdir /zq/data
将数据上传到hdfs
hdfs dfs -copyFromLocal /data/UserBehavior.csv /zq/data
数据预处理
进入spark-shell
spark-shell
1.读取数据
读取HDFS上数据
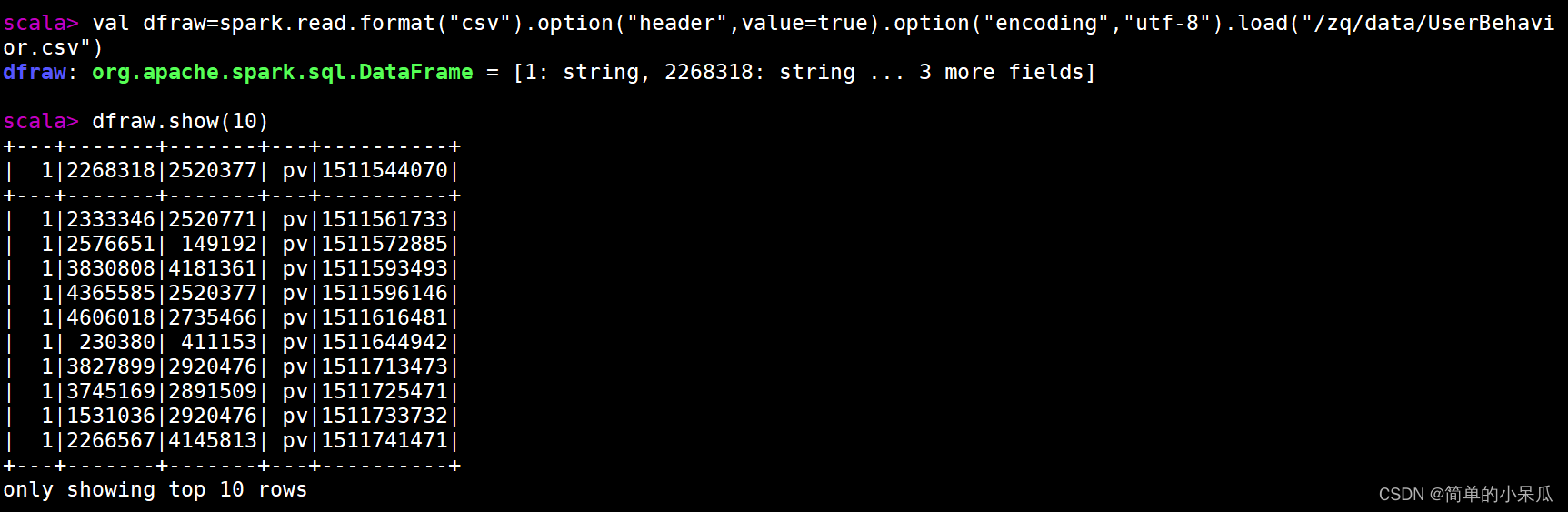
//读取HDFS上数据
val dfraw=spark.read.format("csv").option("header",value=true).option("encoding","utf-8").load("/zq/data/UserBehavior.csv")
读取本地数据
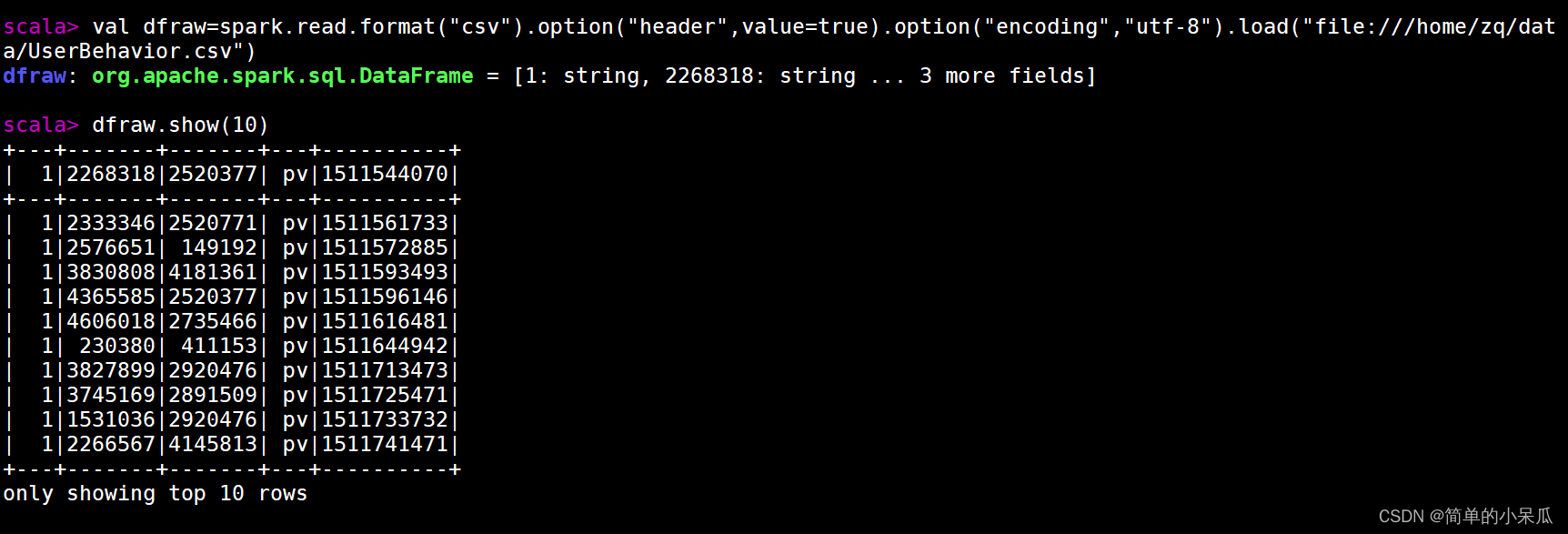
//读取本地数据
val dfraw=spark.read.format("csv").option("header",value=true).option("encoding","utf-8").load("file:///home/zq/data/UserBehavior.csv")
2.数据预处理
2.1 给数据集加上表头
给数据集加上表头
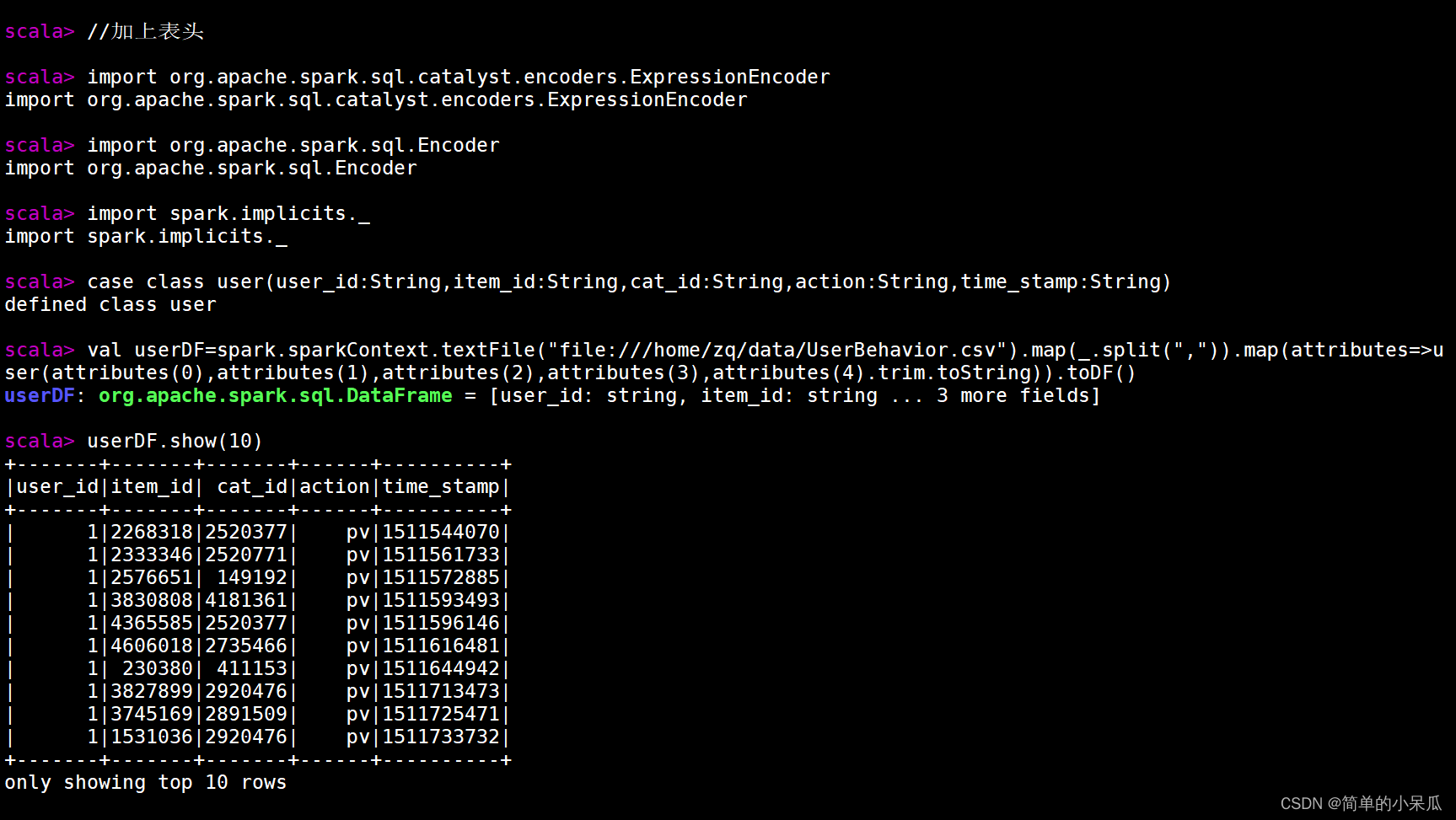
//加上表头
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import spark.implicits._
case class user(user_id:String,item_id:String,cat_id:String,action:String,time_stamp:String)
val userDF=spark.sparkContext.textFile("file:///home/zq/data/UserBehavior.csv").map(_.split(",")).map(attributes=>user(attributes(0),attributes(1),attributes(2),attributes(3),attributes(4).trim.toString)).toDF()
2.2 时间转换
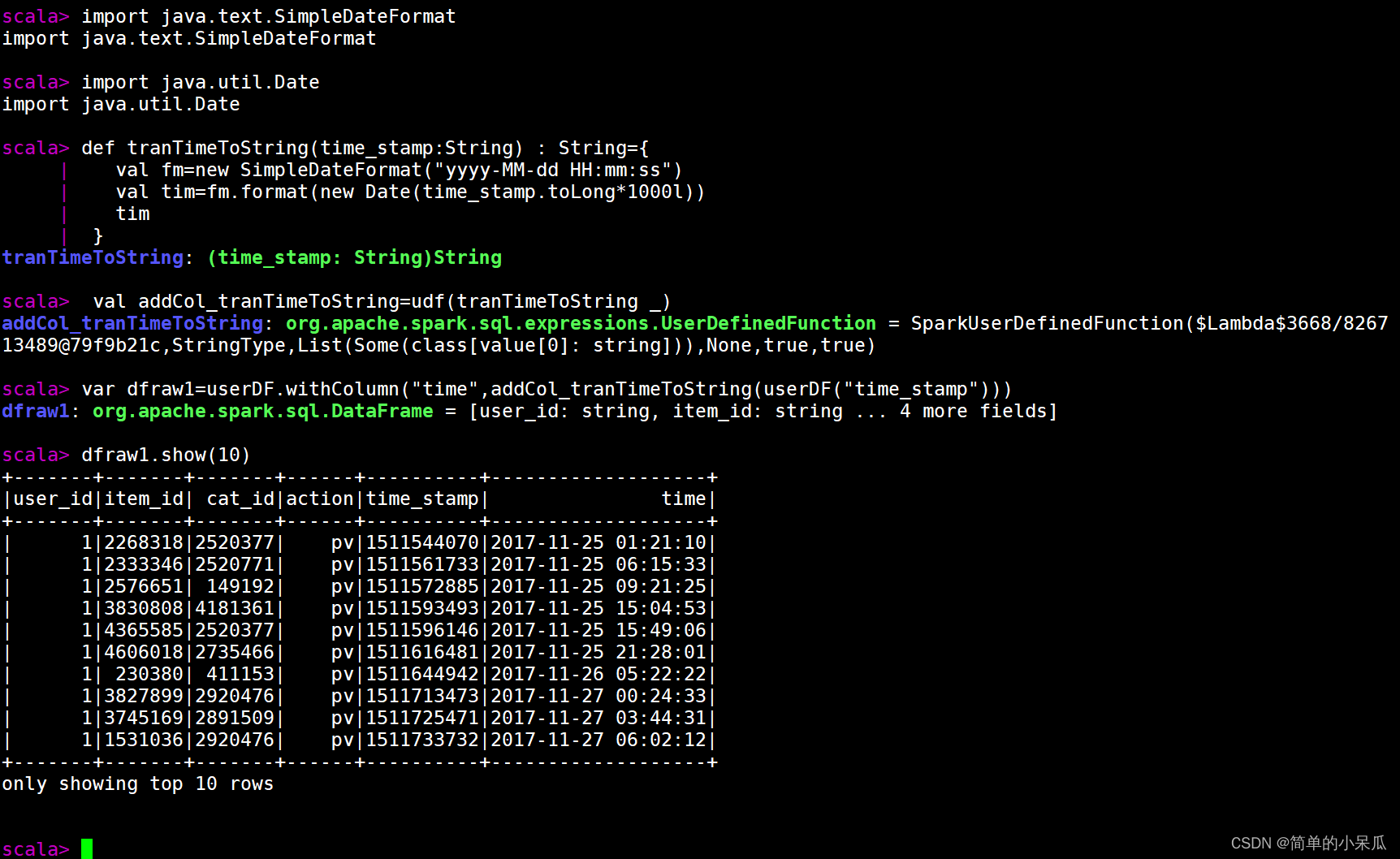
将时间戳转换成正常的时间,并且将提取出的日期加到dataframe中
//时间戳转换成时间
import java.text.SimpleDateFormat
import java.util.Date
def tranTimeToString(time_stamp:String) : String={
val fm=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val tim=fm.format(new Date(time_stamp.toLong*1000l))
tim
}
val addCol_tranTimeToString=udf(tranTimeToString _)
var dfraw1=userDF.withColumn("time",addCol_tranTimeToString(userDF("time_stamp")))
提取出日期和小时数,并将其加到dataframe中
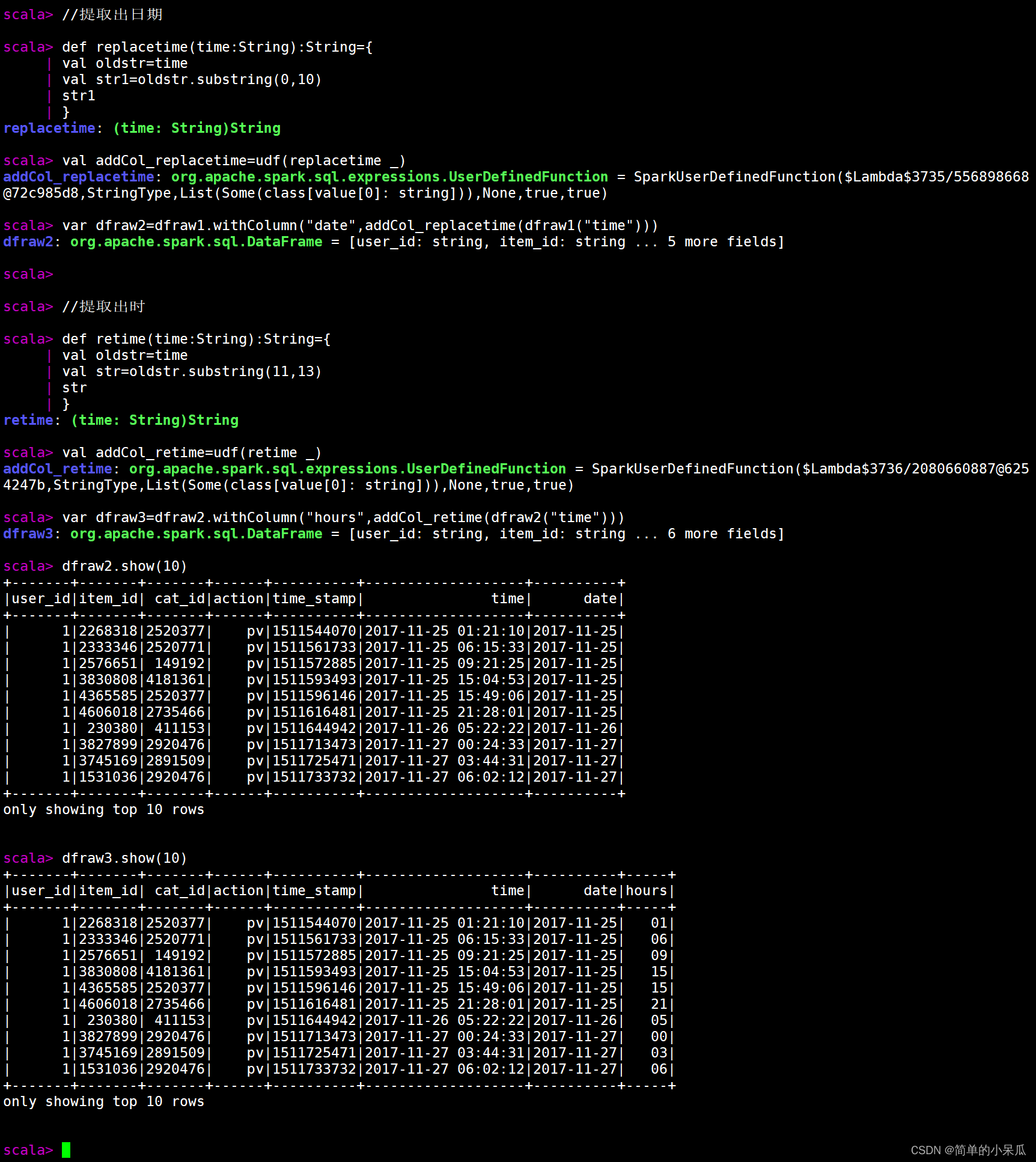
//提取出日期
def replacetime(time:String):String={
val oldstr=time
val str1=oldstr.substring(0,10)
str1
}
val addCol_replacetime=udf(replacetime _)
var dfraw2=dfraw1.withColumn("date",addCol_replacetime(dfraw1("time")))
//提取出时
def retime(time:String):String={
val oldstr=time
val str=oldstr.substring(11,13)
str
}
val addCol_retime=udf(retime _)
var dfraw3=dfraw2.withColumn("hours",addCol_retime(dfraw2("time")))
2.3 查看缺失值
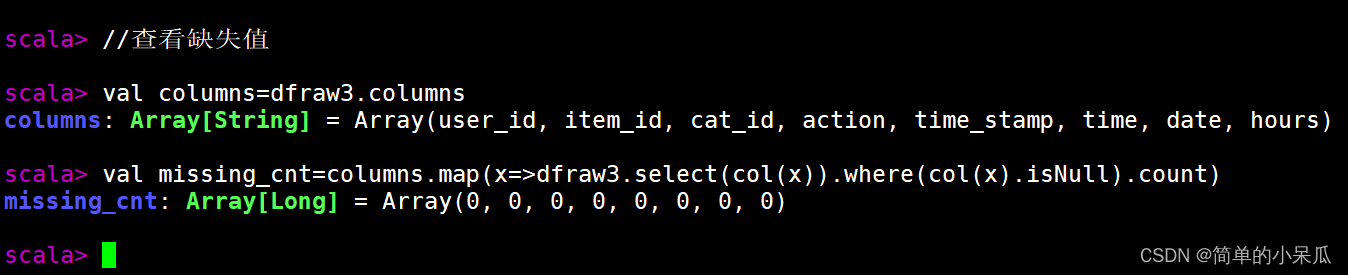
查看是否含有缺失值
//查看缺失值
val columns=dfraw3.columns
val missing_cnt=columns.map(x=>dfraw3.select(col(x)).where(col(x).isNull).count)
2.4 去重
去重
//去重
dfraw3.count()
val df=dfraw3.select("user_id","item_id","cat_id","action","time_stamp","time","date","hours").dropDuplicates()
df.count()

2.5 筛选出符合的数据集
查看数据集中包含的日期
//查看数据集中包含的日期
val df1=df.select("date").distinct().collect()

筛选出2017-11-25~2017-12-03的数据
//筛选出2017-11-25~2017-12-03的数据
val df1=df.filter((df("date")>"2017-11-24") and (df("date") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









