






一、摘要
原始深度图像中普遍存在的噪声和歧义。为了解决,提出了一种深度校准和融合 (DCF) 框架: 1) 一种学习策略,用于校准原始深度图中的潜在偏差,以提高SOD性能;2) 一个简单而有效的交叉参考模块,用于融合RGB和深度模态的特征。
二、解决的问题
1) 深度图通常在对象边界处非常嘈杂,这可能会受到深度传感器和场景配置 (例如遮挡,反射和观看距离的限制;2) 即使具有正确的深度,前景对象在深度图中通常与周围的背景仅略有不同。与使用RGB图像作为唯一输入相比,这严重限制了合并深度图的潜在性能增益
提出了一种深度校准和融合 (DCF) 框架。DCF生成深度值的最佳校准,从而直接促进显着物体检测。方法包含以下主要贡献: 开发了两步校准和融合管道: 第一步涉及校准深度图像并校正原始深度图中的潜在偏差;第二步引入了有效的交叉引用模块 (CRM),以融合来自RGB和校准深度流的特征表示。
三、整体框架结构
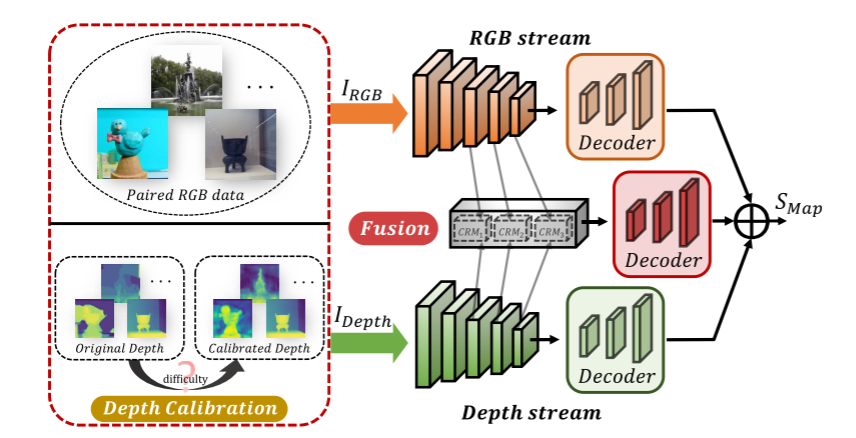
DCF框架。基于两流特征提取网络,它包含两个核心组件: 深度校准和融合策略。
一种深度校准 (DC) 策略,以校正由不可靠的原始深度图引起的潜在噪声,并获得经校准的深度Idepth (或Depthcal)。校准的深度可以比原始深度更好地显示场景布局并识别前景区域。
给定已校准的rgb-d配对数据,将RGB图像IRGB和已校准的深度Idepth馈送到两流特征提取网络中,以生成分层特征。对于每个流,采用编码器-解码器网作为主干。随后是融合策略: 交叉参考模块 (crm) 旨在将RGB特征和深度特征中的有价值提示集成到跨模态融合特征中; 这导致了三个解码分支,分别处理RGB,深度和融合的层次特征。对这些特征进行单独处理,并对相应的输出进行求和,以获得最终的显着性图SMap。
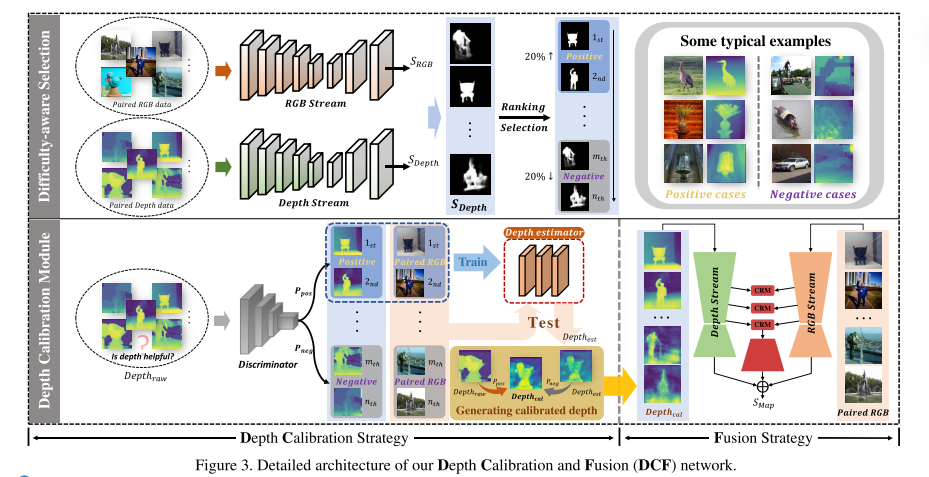
训练数据库中最典型的好的和坏的样本。然后,这些样本用于训练判别器/分类器,以预测深度图的质量,从而反映深度图的可靠性。首先在显着性地面真相的监督下,分别对具有相同体系结构的RGB数据和深度数据作为输入进行了两个基线模型的预训。设计了一种选择方案,以基于两个基线模型预测的显着性来测量深度图是否能够提供可靠的信息。具体来说,根据RGB流和深度流生成的显著性结果,首先计算两个流的预测显著性和地面真实显著性之间的交集 (IoU)度量,分别表示为IoUdepth、IoURGB。然后,将所有训练样本的IoUdepth分数从大到小依次排序。基于排名顺序,所有训练样本中排名前20%的样本将被视为典型的正集Pset(即,深度图的质量是可接受的),而底部20% 将被视为典型的负集Nset (深度图的质量很差,不可接受)。此外,当IoUdepth> IoURGB时,这些样本也将被视为正样本,这表明原始深度数据提供了比RGB输入更丰富的全局线索来识别前景区域。在图3的右上角示出了积极情况和消极情况的一些典型示例。
深度校准模块DC基于所选的代表性正样本和负样本,训练了基于ResNet-18 的二进制鉴别器/分类器,以评估深度图的可靠性。训练有素的鉴别器能够预测可靠性得分Ppos,分别表明深度图的概率为正或负。Ppos越高,原始深度图的质量越好。此外,建立了一个深度估计器,使用RGB图像和来自正集 (即 {IRGB,Depthraw} ∈ Pset) 的高质量深度数据对进行训练,以减轻由不准确的原始深度数据引起的固有噪声。深度校准模块中,将原始深度图替换为原始深度图与估计深度之间的加权求和,并且权重由判别器预测的可靠性概率Ppos确定。
Depthcal = Depthraw * ppos Depthest * (1 − ppos),(1) 其中depest和Depthraw分别表示来自深度估计器和原始深度图的估计深度。Depthcal提供了比Depthraw更可靠的3D布局信息。就低对比度深度数据而言 (如在第2行和第5行中所见),与原始深度相比,我们的深度可以更好地体现完整的场景结构。至于具有良好质量的原始深度图 (如在第4行中所见),与Depthraw相比,估计的深度最远具有次优的性能。但是,由于鉴别器预测的可靠性概率ppo对于高质量的Depthraw将很高,因此我们的框架仍将能够获得高质量的校准深度深度。

图4。深度校准的内部检查: 输入深度图Depthraw,中间估计深度图depest和校准深度图Depthcal的示例。绿色和黄色圆圈分别表示判别器产生的正概率和负概率。
特征融合:在深度校准过程之后,将校准的深度图深度与RGB图像一起馈送到两流特征提取网络以生成分层特征

在深度校准过程之后,将校准的深度图深度与RGB图像一起馈送到两流特征提取网络以生成分层特征。保留了最后一个并以高分辨率删除前两个卷积块,以平衡计算成本。从RGB通道中提取的特征包含丰富的语义信息和纹理信息; 同时,从深度通道中提取的特征包含更具区分性的场景布局提示,与RGB特征互补。为了整合跨模式信息,融合策略称为交叉参考模块 (CRM),在图5中进行了设计和说明。提出的CRM旨在挖掘和组合最有区别的通道 (即,特征检测器) 在深度和RGB特征之间,并生成更多信息特征。更具体地说,给定分别由RGB流和深度流的第i个卷积块产生的两个输入特征FRGB i和FDepth i,我们首先采用全局平均池化 (GAP) 来获得RGB和深度视图中的全局统计信息。然后,将两个特征向量分别馈送到全连接层 (FC) 和softmax激活函数 δ(·) 中,以获得通道注意向量AttRGB i和AttDepth i,分别反映RGB特征和深度特征的重要性。然后将注意力向量以逐通道乘法的方式应用于输入特征。这样,CRM将明确地专注于重要功能,并抑制不必要的功能以进行场景理解。此过程可以定义为:
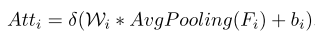
其中Wi和bi表示第i个特征的FC层的参数,而AvgPooling(·) 表示全局平均池化操作。然后,生成通道增强特征f ˙ i = Atti ffi,其中,×表示按通道乘法。
此外,注意力向量AttRGB i和AttDepth i通过最大函数聚合,以保留来自RGB流和深度流的有用特征通道,然后将其馈送到归一化操作N(·) 以将输出归一化到从0到1的范围。因此,我们获得了交叉引用的通道注意向量AttCR i。此过程可以定义为:

基于融合通道注意向量AttCR i,通过将f ˙ i RGB和f ˙ i深度与AttCR i增强特征相加,可以获得增强特征f ~ RGB i和f ~ 深度i。来自RGB分支和深度分支的增强特征被进一步串联并馈送到1 × 1卷积层,以生成交叉模态融合特征Fi。该过程可以描述为:
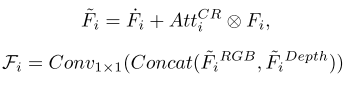
此外,利用三重态损耗来增强所获得的跨模态融合特征Fi,以鼓励融合特征更靠近前景,同时扩大前景特征与背景特征之间的距离。我们使用Fi作为锚特征。与显着性区域相对应的特征设置为正,背景区域的特征设置为负,如:
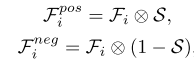
其中S表示地面-真相显著图。然后,三重态损失三重态可以计算为:
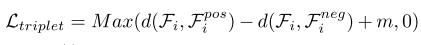
其中d(·) 表示欧几里得距离; m表示边距参数,并在 [60] 之后设置为1.0。在提出的CRM之后,我们可以获得跨模态融合特征 {Fi}5 i = 3,它与从RGB流 {FRGB i} 5 i = 3和深度流 {FDepth i} 5 i = 3中提取的原始特征一起,进一步馈送到由S监督的三个单独的解码器,如图2所示。最后,来自三个解码器的预测被求和以生成最终的显着性映射SMap。
所提出方法的优化目标Ltotal可以描述为:
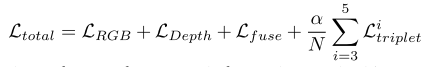
其中LRGB,LDepth和Lfuse表示每个解码器的预测与地面真值显着性之间的二进制交叉熵损失。N = 3表示涉及三重态损失的卷积块的数量。本文根据经验将超参数 α 设为0.2。
四、结论
提出了一种深度校准和融合 (DCF) 框架,用于精确的rgb-d SOD。首先,设计了深度校准策略来校正不可靠原始深度中的潜在噪声。对于所提出的框架和最新的rgb-d显着性模型,已证明校准的深度可以有效地提高模型性能。此外,提出了一种交叉参考模块,以有效地集成来自RGB和深度特征的互补提示。















 2369
2369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









