






复现过程(win11)
代码地址:[botaoye/OSTrack: ECCV 2022] Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework (github.com)
第一步:
1.创建并激活环境
2.执行bash install.sh
windows下注意:直接使用bash会出现'sh' 不是内部或外部命令,也不是可运行的程序或批处理文件。
解决办法:conda install m2-base
第二步:配置环境
1.虚拟环境进入ostrack目录
2.执行命令:
python tracking/create_default_local_file.py --workspace_dir . --data_dir ./data --save_dir ./output
解释:
--workspace_dir .: 指定工作空间目录为当前目录(.)。--data_dir ./data: 指定数据目录为当前目录下的data文件夹。--save_dir ./output: 指定保存目录为当前目录下的output文件夹。
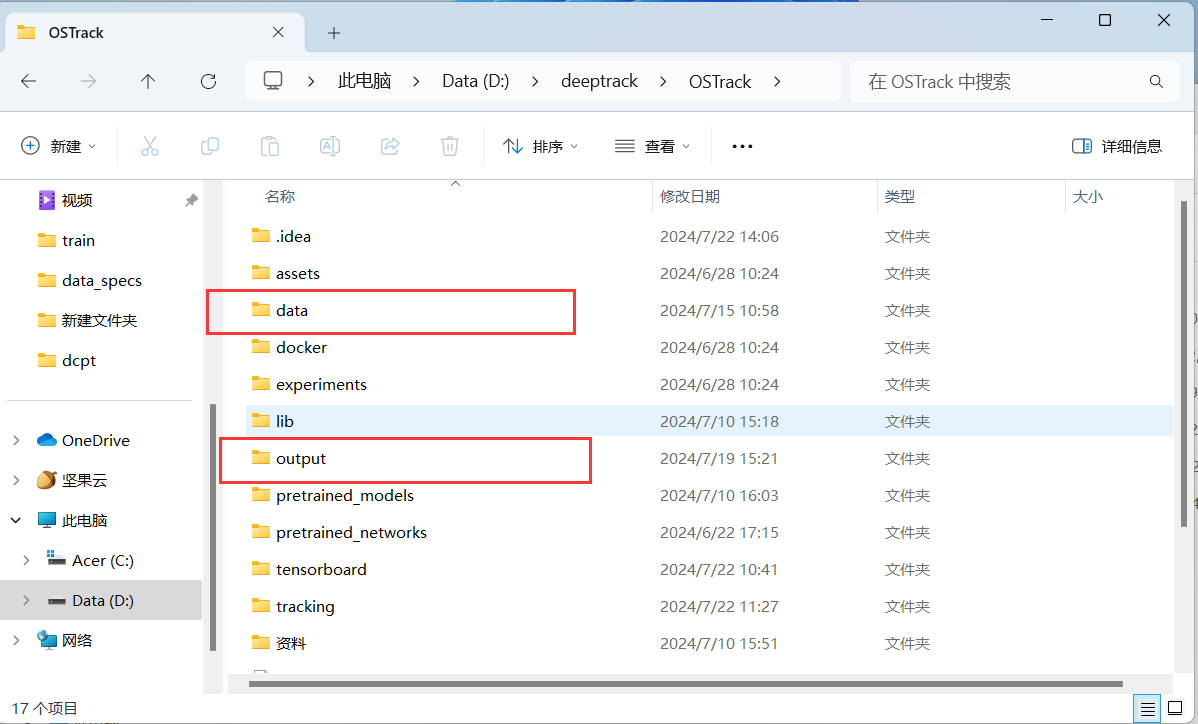
3.执行命令后,按运行结果local.py新建文件夹如图所示,并将模型放入
第三步:实现demo(与DCPT相同)
1.如图配置并运行video_demo.py

运行成功:
第四步:运行测试(otb100)(与DCPT相同)
1.修改tracking/test.py 如图

遇到错误1:
raise Exception('Could not read file {}'.format(path)) Exception: Could not read file /data/otb/BlurCar1/groundtruth_rect.txt
错误原因1:
groundtruth_rect.txt格式与读取格式不对应
解决方法1:
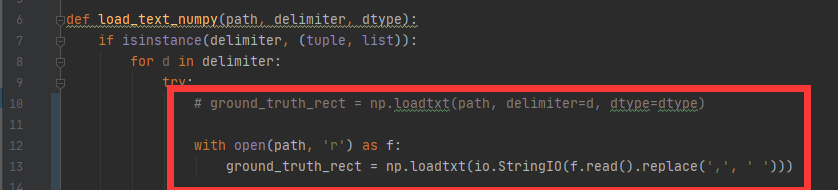
修改lib/test/utils/load_text.py 如下图:
遇到错误2:
Exception: Could not read file /data/otb/Human4/groundtruth_rect.txt
错误原因2:
代码数据集文件名与实际文件名不符合
解决方法2:
修改实际文件夹名字或者修改lib/test/evaluation/otbdataset.py 如下图:

同样Jogging 、Skating2也如此操作
运行成功:
2.运行tracking/analysis_results.py(这个代码的作用还没搞懂,不清楚是否与tracking/test.py生成的结果有关系)
出现错误ImportError: cannot import name 'common_texification' from 'matplotlib.backends.backend_pgf' (D:\Software\anaconda3\envs\Pytorch_py39\lib\site-packages\matplotlib\backends\backend_pgf.py)
错误原因:matplotlib版本不兼容问题Common_texification removed from matplotlib 3.8.0
解决办法:pip install matplotlib==3.7
运行结果如图:

第五步:测试FLOPs和速度(与DCPT相同)
1.运行命令行python tracking/profile_model.py 没问题
2.直接运行tracking/profile_model.py
出现问题:FileNotFoundError: [Errno 2] No such file or directory: 'experiments/DCPT/DCPT_Gate.yaml'
解决如图:

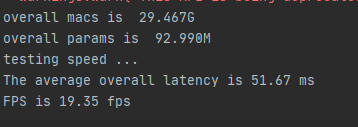
运行结果:
第六步:训练(只用got10k中GOT-10k_Train_split_01数据)
1.修改:experiments/ostrack/vitb_256_mae_ce_32x4_ep300.yaml文件
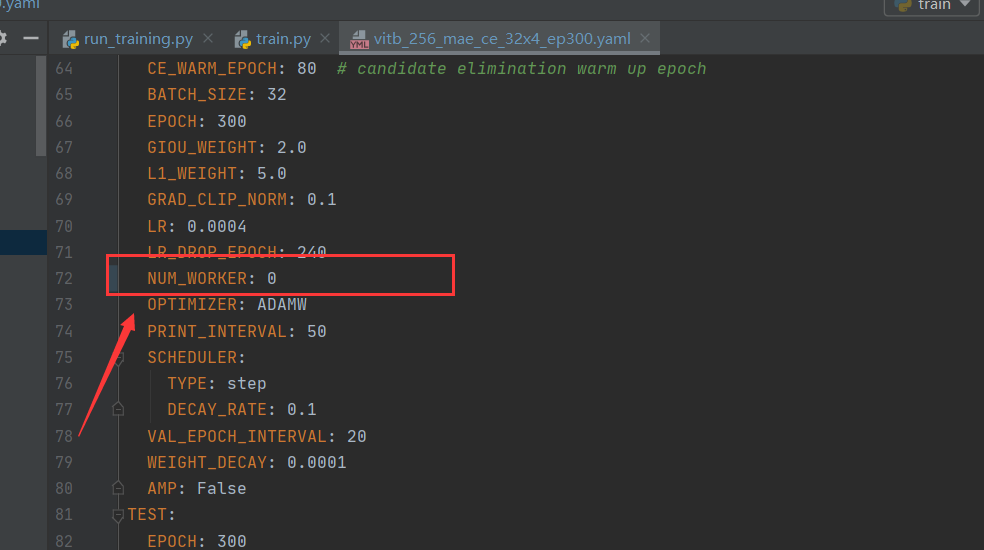
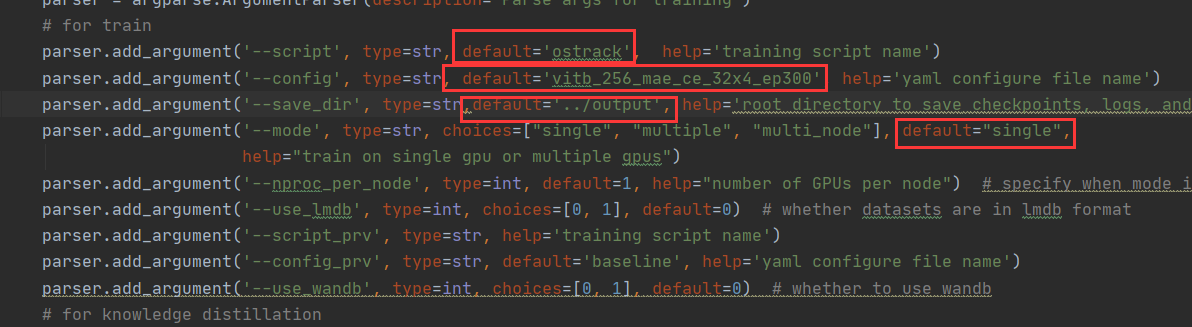
2.修改tracking/train.py如图

3.got10k数据集放置如下所示
4.运行tracking/train.py或者lib/train/run_training
出现问题1:
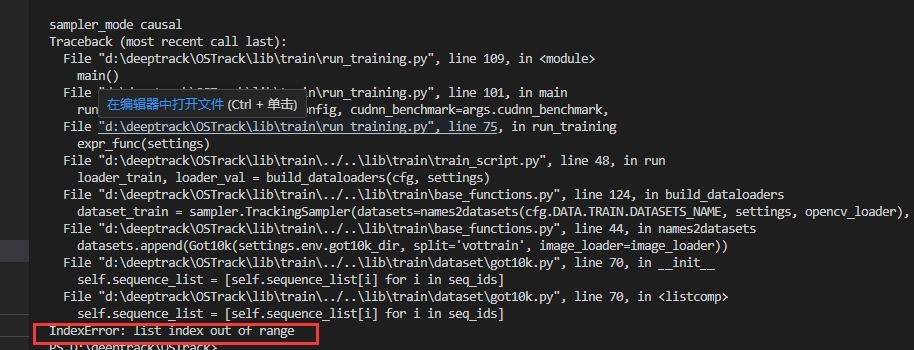
debug找错误:(如图位置打断点开始调试)
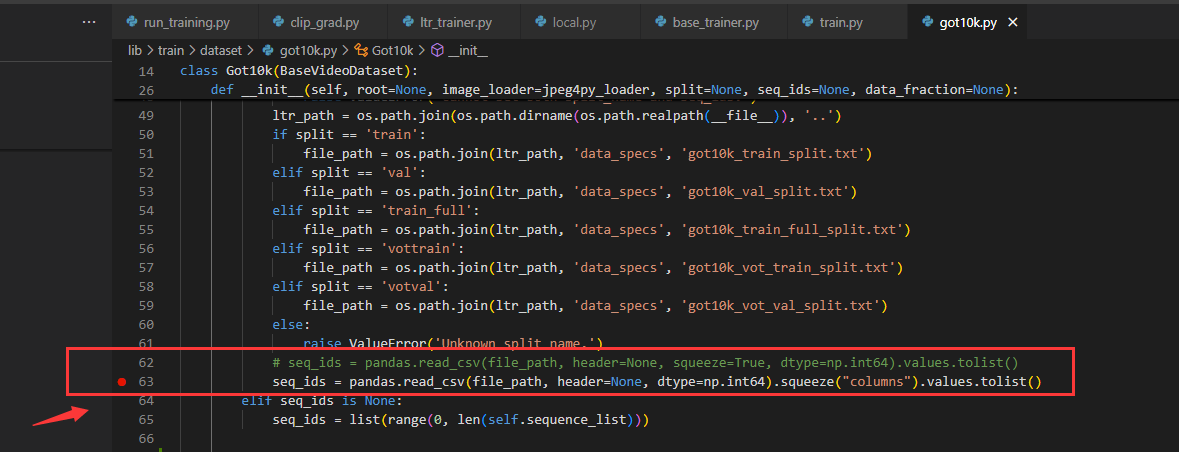
单步调试得到如图所示:
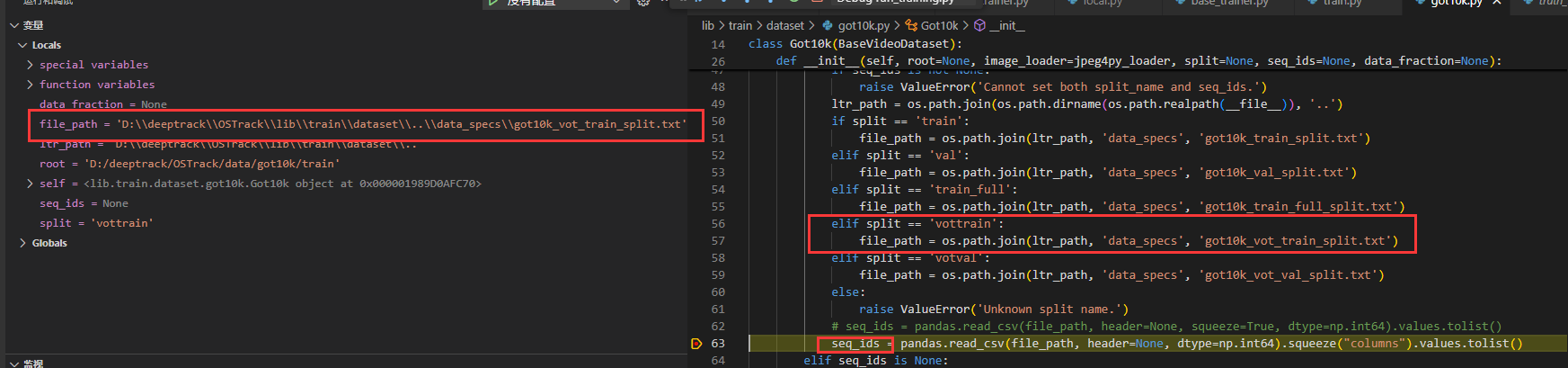
点击左边红框进入txt文件查看。(当时上午没看出啥问题,下午想到了。self.sequence_list相当于是由seq_ids决定的)
写一段python代码将如下图的txt文件中的数字从小到大重新排序,验证想法。
排序的python代码如下:
# 读取文件内容
with open('got10k_train_full_split.txt', 'r') as file:
lines = file.readlines()
# 将每行的数字转换为整数,并排序
numbers = [int(line.strip()) for line in lines]
numbers.sort()
# 将排序后的数字写入新的文件
with open('sorted_numbers.txt', 'w') as file:
for number in numbers:
file.write(f'{number}\n')
排序结果如图所示:
由此得思路正确。
运行代码,还是同样的错误;添加如图的两行代码查看具体的索引值。
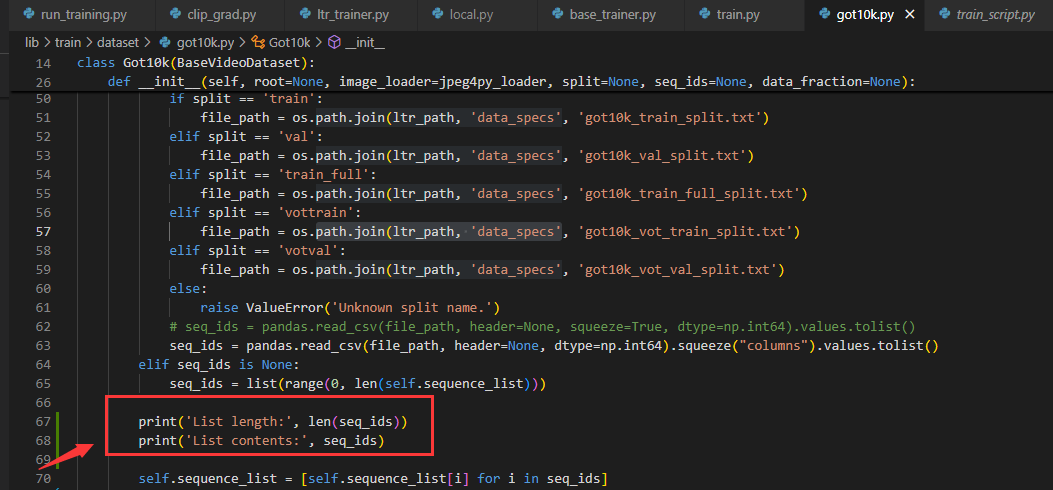
再次运行,查看错误如下图所示:
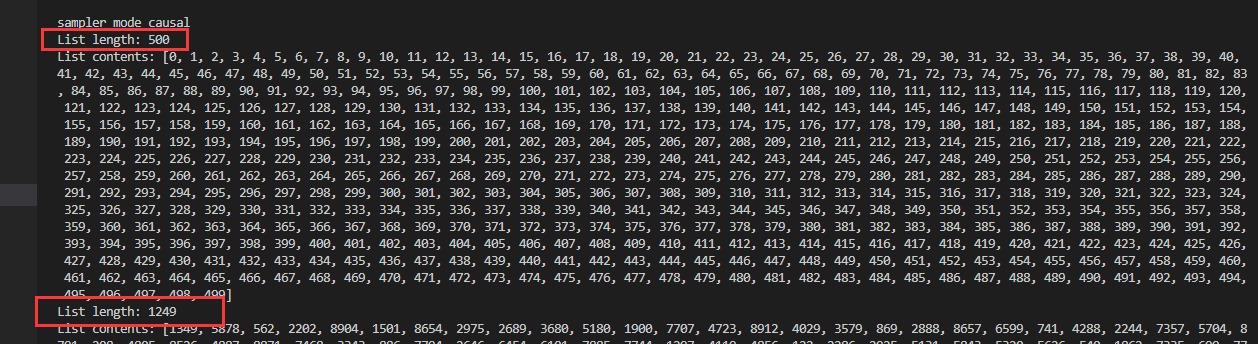
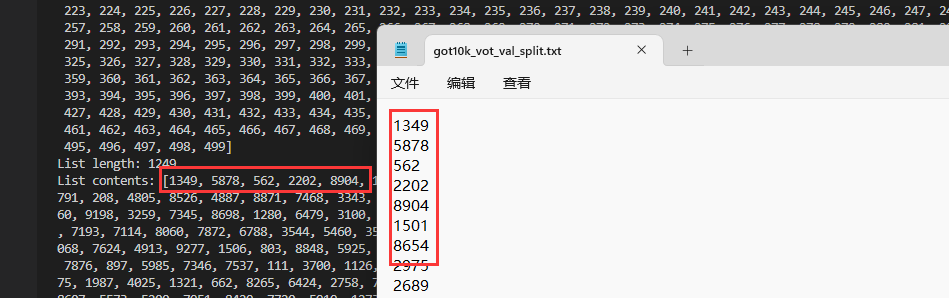
可以验证思路基本正确,上面修改got10k_vot_train_split.txt后已经变为我们所需的索引值,下面那个1249推测是验证集的索引值,打开相应文件查看如下图,确实如此,因此将其做对应修改。
修改后运行代码,未出现IndexError: list index out of range,成功解决错误。
解决方法(任选其一):
(1)将下图两个文件内数字修改成自己所需的数据集序列部分。
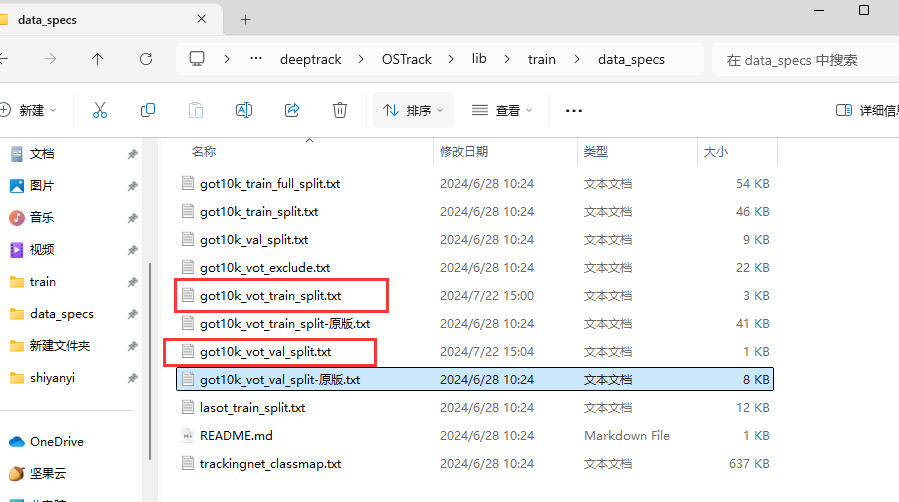
(2)
将"D:\deeptrack\OSTrack\lib\train\dataset\got10k.py"中的该行代码
self.sequence_list = [self.sequence_list[i] for i in seq_ids]注释。
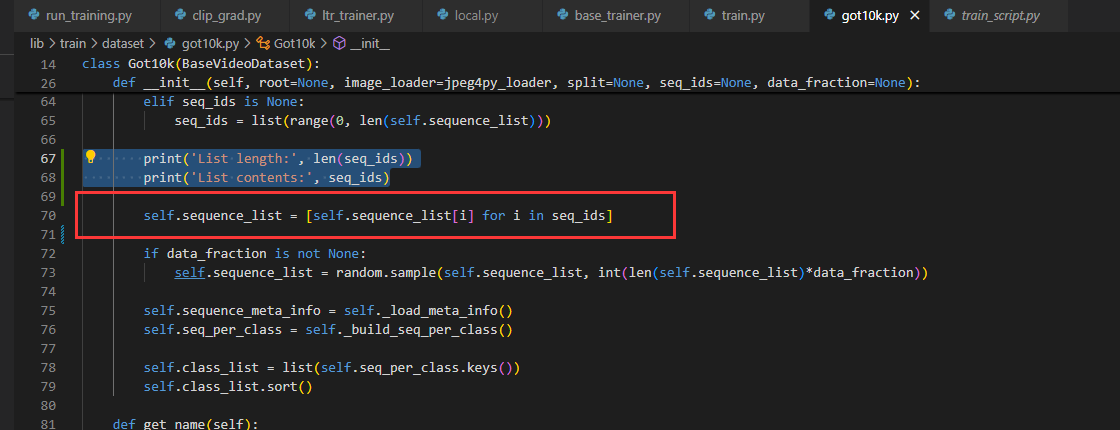
出现问题2:
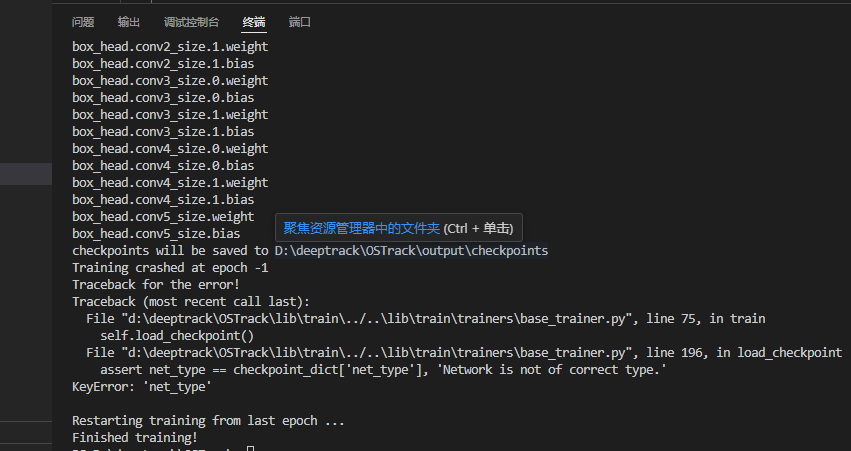
解决办法:
(1)将该行代码注释
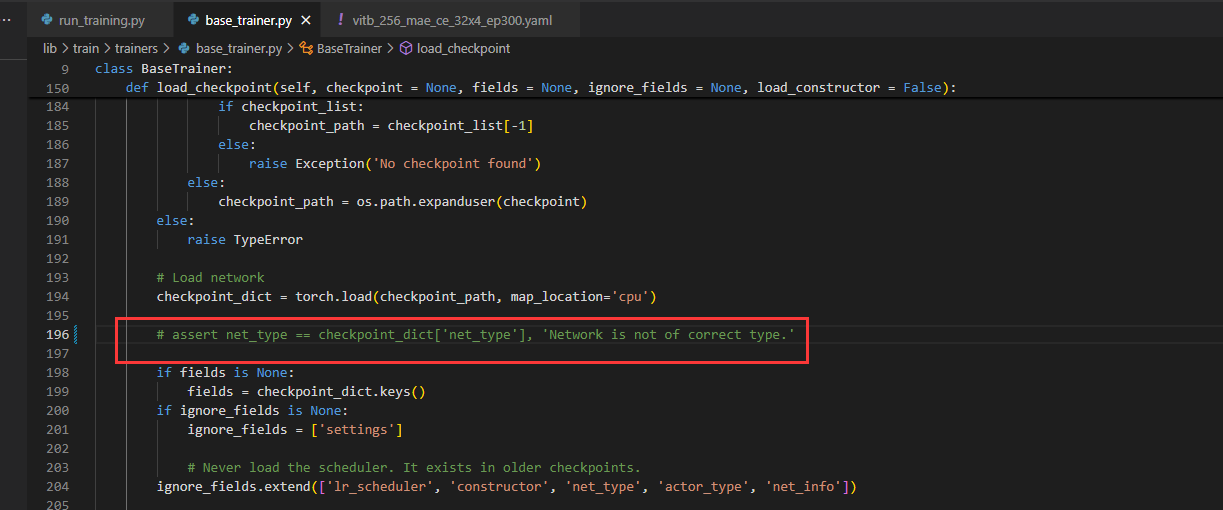
(2)将作者的模型删掉
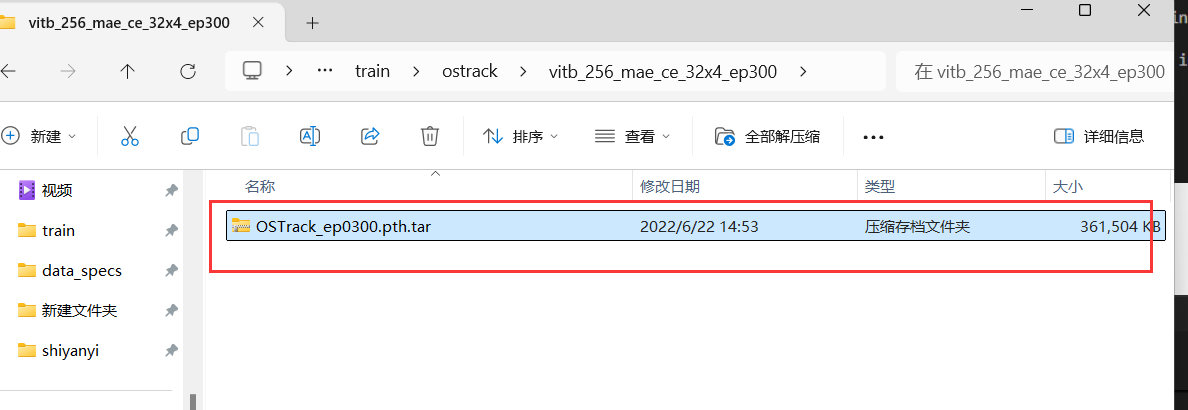
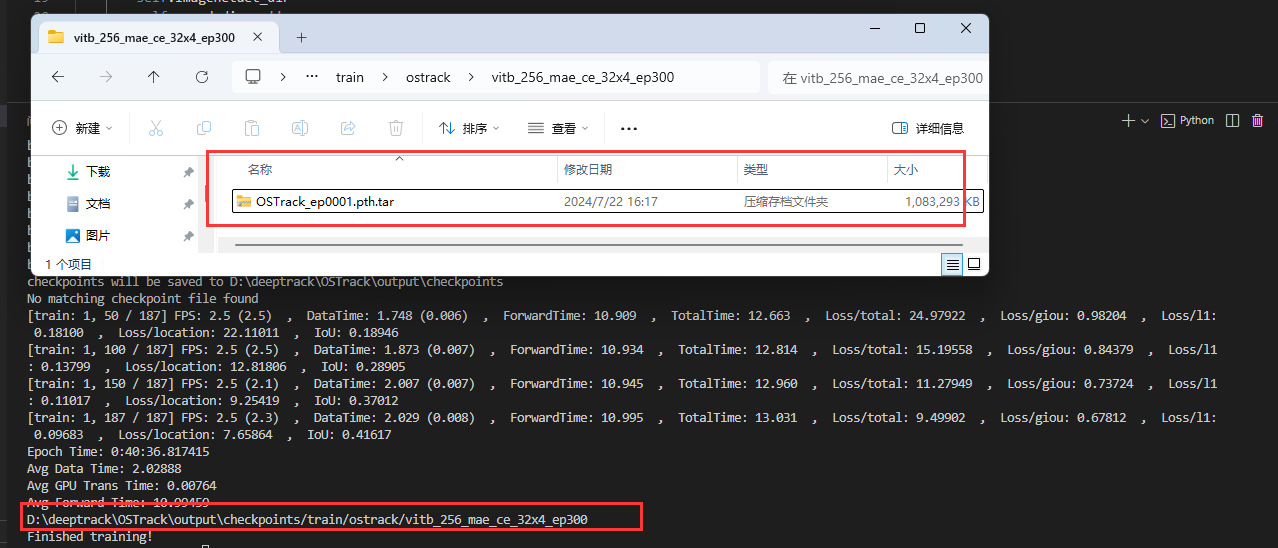
最后成功运行,如下图所示(只训练了一轮来验证是否成功训练):
参考资料:















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









