简介:爬取字段如
'电影名称',
'电影类型',
'电影封面',
'上映地区',
'上映时间',
'电影评分',
'参演人员',
'评论头像地址',
'用户名称',
'推荐指数',
'评论时间',
'评论标题',
'有用数',
'没用数',
'回应数',
'评论内容'
1、运行结果
1.1 数据截图
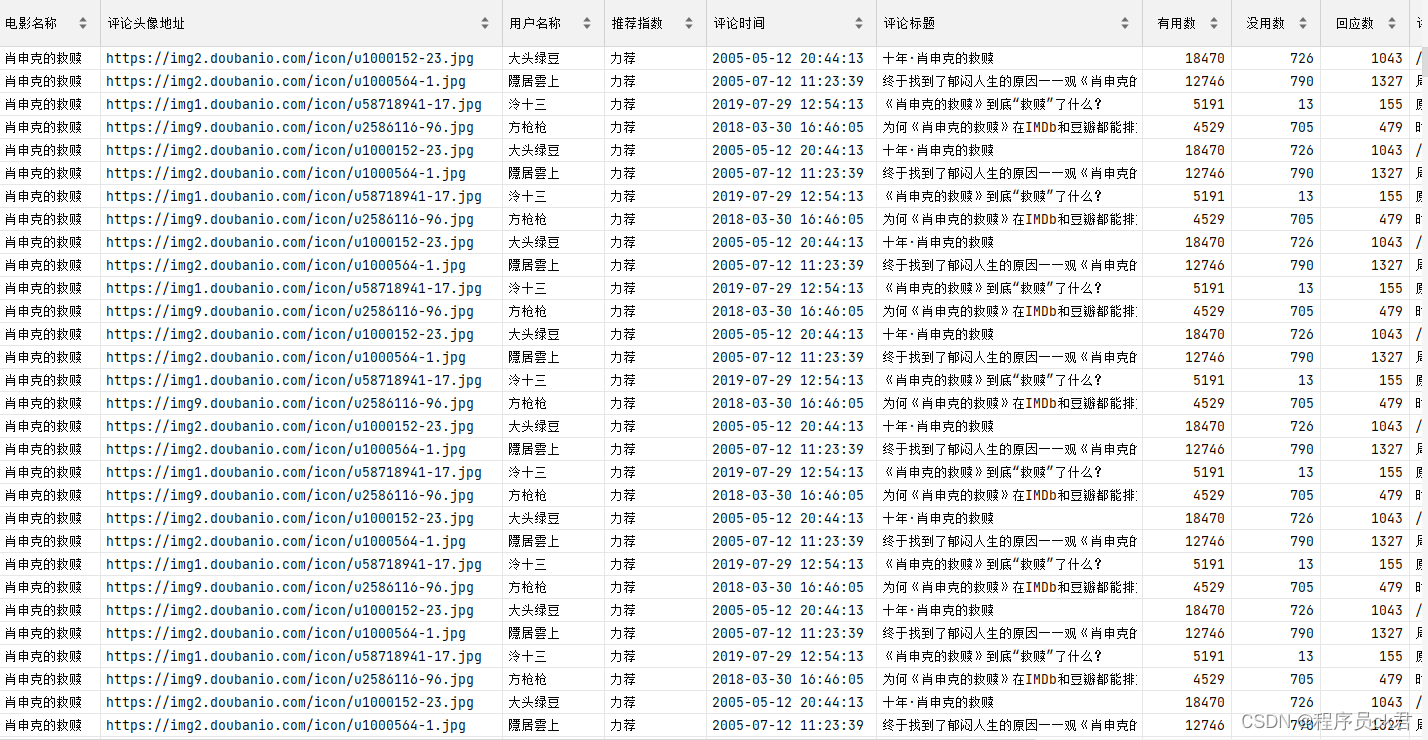
1.2 运行结果图

2、代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/11/28 0028 15:50
# @Author : 程序员ck君
# @File : hyy.py
# @Software: PyCharm
'''
爬取豆瓣电影
'''
## 加载json模块
import time
import requests
from lxml import etree
import csv
if __name__ == "__main__":
date = time.strftime('%Y_%m_%d_%H_%M_%S', time.localtime())
with open(f'{date}豆瓣影评_plus.csv', 'w', encoding='utf8', newline='') as filename:
csvwriter = csv.DictWriter(filename, fieldnames=[
'电影名称',
'电影类型',
'电影封面',
'上映地区',
'上映时间',
'电影评分',
'参演人员',
'评论头像地址',
'用户名称',
'推荐指数',
'评论时间',
'评论标题',
'有用数',
'没用数',
'回应数',
'评论内容'
])
csvwriter.writeheader()
start = 0 #
count = 10
# 占比数量 10
# https://movie.douban.com/j/chart/top_list_count?type=28&interval_id=100%3A90
# U-A 伪装
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
# 请求地址 url_num 是数量 // ulr_data 是电影类型
url_num = "https://movie.douban.com/j/chart/top_list_count"
url_data = "https://movie.douban.com/j/chart/top_list"
# interval_id list
interval_id_list = ["100:90", "90:80", "80:70", "70:60", "60:50", "50:40",
"40:30", "30:20", "20:10", "10:0"]
type_dict = {
"剧情": 11,
"喜剧": 24,
"动作": 5,
"爱情": 13,
"科幻": 17,
"动画": 25,
"悬疑": 10,
"惊悚": 19,
"恐怖": 20,
"纪录片": 1,
"短片": 23,
"情色": 6,
"音乐": 14,
"舞蹈": 7,
"家庭": 28,
"儿童": 8,
"传记": 2,
"历史": 4,
"战争": 22,
"犯罪": 3,
"西部": 27,
"奇幻": 16,
"冒险": 15,
"灾难": 12,
"武侠": 29,
"古装": 30,
"运动": 18,
"黑色电影": 31
}
# 爬取数据
for dy_key in type_dict.keys():
print(f"---------------------正在爬取 ** {dy_key} **-----------------")
# interval_id 数量循环
for interval_id_count in interval_id_list:
print(f" ---------------爬取 ** {interval_id_count}** -------")
# interval_id 数量 携带参数
params_num = {
"type": type_dict[dy_key],
"interval_id": interval_id_count
}
# 响应每一个interval_id 的数量
time.sleep(1) # 休眠1秒
json_num = requests.get(url_num, headers=headers, params=params_num).json()
start_num = json_num["total"] # 数量
# 参数
for data_count in range(0, start_num, 20): # TODO 爬取电影评论页数,可控 --- 1
params_data = {
"type": type_dict[dy_key],
"interval_id": interval_id_count,
"action": "",
"start": data_count,
"limit": 20,
}
# 响应数据
time.sleep(1) # 休眠1秒
json_data = requests.get(url_data, headers=headers, params=params_data).json()
for key in json_data:
list = []
list.append(key["title"]) # 电影名称
list.append(key['cover_url']) # 电影封面
list.append(key['regions'][0]) # 上映地区
list.append(key['release_date']) # 上映时间
list.append(key['score']) # 电影评分
# 参演人员
data_temp_list = key['actors']
data_temp = ""
for i in range(0, len(data_temp_list)):
data_temp += data_temp_list[i] + " "
list.append(data_temp) # 参演人员
data_to_url = key["url"] # 详情页面
for to_url in range(0, 1200, 20): # TODO 爬取电影评论页数,可控 --- 2
try:
print(f' -----------爬取{list[0]} 评论++++第 {to_url} ++页----------')
params_data_to = {
start: to_url
}
list_1 = []
getData = requests.get(data_to_url, headers=headers, params=params_data_to).text
time.sleep(1) # 休眠1秒
tree = etree.HTML(getData)
li_List = tree.xpath('//*[@id="content"]/div/div[1]/div[1]/div')
for li in range(0, len(li_List)):
list_1 = []
try:
# 评论头像地址
data_img = li_List[li].xpath(f'//div[{li + 1}]/div/header/a[1]/img/@src')[0]
list_1.append(data_img)
# 用户名称
data_1 = li_List[li].xpath(f'//div[{li + 1}]/div/header/a[2]/text()')[0]
list_1.append(data_1)
# 推荐指数
data_2 = li_List[li].xpath(f'//div[{li + 1}]/div/header/span[1]/@title')[0]
list_1.append(data_2)
# 评论时间
data_3 = li_List[li].xpath(f'//div[{li + 1}]/div/header/span[2]/text()')[0]
list_1.append(data_3)
# 标题
data_4 = li_List[li].xpath(f'//div[{li + 1}]/div/div/h2/a/text()')[0]
list_1.append(data_4)
# 有用数
data_5 = int(li_List[li].xpath(f'//div[{li + 1}]/div/div/div[3]/a[1]/span/text()')[0])
list_1.append(data_5)
# 没用数
data_6 = int(li_List[li].xpath(f'//div[{li + 1}]/div/div/div[3]/a[2]/span/text()')[0])
list_1.append(data_6)
# 回应数
data_71 = li_List[li].xpath(f'//div[{li + 1}]/div/div/div[3]/a[3]/text()')[0] + ""
data_7 = data_71.split("回")[0]
list_1.append(data_7)
# 评论内容
data_81 = li_List[li].xpath(f'//div[{li + 1}]/div/div/div[1]/div/text()')
data_82 = ""
for data_81_i in range(0, len(data_81)):
data_82 += data_81[data_81_i]
data_8 = (data_82.replace("\n", '')).replace(" ", '')
list_1.append(data_8)
# 数据持久护化
dict = {
'电影名称': list[0],
'电影类型': dy_key,
'电影封面': list[1],
'上映地区': list[2],
'上映时间': list[3],
'电影评分': list[4],
'参演人员': list[5],
'评论头像地址': list_1[0],
'用户名称': list_1[1],
'推荐指数': list_1[2],
'评论时间': list_1[3],
'评论标题': list_1[4],
'有用数': list_1[5],
'没用数': list_1[6],
'回应数': list_1[7],
'评论内容': list_1[8]
}
csvwriter.writerow(dict)
except:
pass
except:
pass
print('-------------------------------程序结束----------------------------------------------')






















 5615
5615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









