



简介:通过将存储于MySQL中的数据提取出来,调用机器学习中的某个算法训练出模型并保存,再使用Java跨语言调用训练好的模型,然后可视化。训练流程如图1.1中所示。主要涉及技术及工具有Sprint Boot2 + Vue2 + Echarts + Anaconda + IDEA + Noetpad++等;需要准备:
1、环境准备。 Java + Maven + MySQL + nvm + Anaconda
2、数据准备。 该项目中使用地震数据。
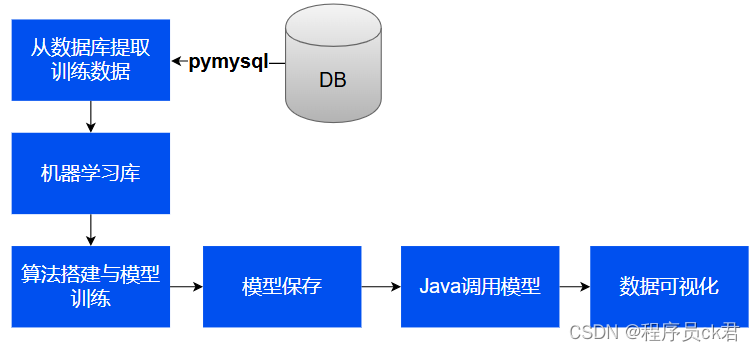
图1.1
1、模型训练
1.1 数据获取及导入MySQL
git clone git@gitee.com:luoyanUFO/my-sql-data.git
1.2 启动Anaconda (安装省略)
在桌面新建任意一个文件夹,点击进入,输入cmd.如图1.2、1.3、1.4所示,然后输入命令(如果没有下载先下载jupyter notebook),一段时间后自动跳转浏览器,如果没有自动跳转复制url在浏览器中打开。
注意:CTRL + enter 运行代码(光标要停在要运行的那个框中); shift + enter 新建一个运行框
jupyter notebook
图 1.2

图 1.3

图 1.4
1.3 安装pymysql
如果两个命令都安装不成功,再去网上找一下其他方法。如果不行可以去官网下载对应的轮子,然后导入到本地。过程省略。
# 安装, 请勿重复运行这一栏
# conda install pymysql # 先用这个,不行然后注释用下一个
# !pip install pymysql
# pip install --user -i https://pypi.tuna.tsinghua.edu.cn/simple sklearn2pmml # 安装sklearn2pmml, 如果后面导入出错再安装
1.4 提取MySQL中的数据
'''
随机森林预测
-------- 通过经纬度训练模型-------------------
'''
# 导入所需包
import pymysql
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
from sklearn2pmml import PMMLPipeline, sklearn2pmml
#连接数据库
url = '192.168.6.166' # 连接地址
user = 'root' # 用户名
pws = '123456' # 密码
db = 'rwly' # 数据库名称
conn=pymysql.connect(host = url # 连接名称,默认127.0.0.1
,user = user # 用户名
,passwd = pws # 密码
,port = 3306 # 端口,默认为3306
,db = db # 数据库名称
,charset='utf8' # 字符编码
)
cur = conn.cursor() # 生成游标对象
sql="SELECT `longitude`,`dim`,`km`,`ml` FROM ads_serism_all;" # SQL语句-- 注意查询表
cur.execute(sql) # 执行SQL语句
data = cur.fetchall() # 通过fetchall方法获得数据
# for i in data[:21]: # 打印输出前2条数据
# print (i)
df = pd.DataFrame(data, columns=['经度', '维度', '震深', '震级'])
print("-----------------------------------查询数据展示------------------------------------------------------------\n")
print(df)
# print(classification_report(data, target_names=target_names))
cur.close() # 关闭游标
conn.close() # 关闭连接
运行结果如图1.5。

图1.5
1.5 训练模型
1.5.1 震级模型
'''
随机森林预测
-----------------------------------随机森林预测 -- 震级模型-----------------------------------------------
'''
# 特征提取:选取与薪资相关的特征
X = df[['经度', '维度']] # 用身高和年龄来预测得分情况
y = df['震级']
#
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 随机森林模型建立
rf = RandomForestRegressor(n_estimators=100, random_state=123)
#
# 模型训练
rf.fit(X_train, y_train)
# 模型评估
y_pred = rf.predict(X_test)
print("------------------------震级模型评估-----------------------------------\n")
# 平均绝对误差
mae = mean_absolute_error(y_test, y_pred)
print('震级模型评估',y_pred)
print("--------------------------震级平均绝对误差(MAE)---------------------------------\n")
print('震级平均绝对误差(MAE):', mae)
# 导出模型到 ml.pmml 文件
sklearn2pmml(rf, "ml.pmml", with_repr = True)
1.5.2 震深模型
'''
随机森林预测
-----------------------------------随机森林预测 -- 震深模型-----------------------------------------------
'''
#
# 特征提取:选取与薪资相关的特征
X = df[['经度', '维度']] # 用身高和年龄来预测得分情况
y = df['震深']
#
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 随机森林模型建立
rf2 = RandomForestRegressor(n_estimators=100, random_state=123)
#
# 模型训练
rf2.fit(X_train, y_train)
# 模型评估
y_pred = rf2.predict(X_test)
print("------------------------震深模型评估-----------------------------------\n")
# 平均绝对误差
mae = mean_absolute_error(y_test, y_pred)
print('震深模型评估',y_pred)
print("--------------------------震深平均绝对误差(MAE)---------------------------------\n")
print('震深平均绝对误差(MAE):', mae)
# 导出模型到 km.pmml 文件
sklearn2pmml(rf2, "km.pmml", with_repr = True)
1.6 模型预览
模型保存在新建的那个文件夹中,如图1.6所示;使用idea打开,可以修改。
![]()
图1.6
2、调用模型
创建 spring boot 工程省略 。。。
2.1 调入jar包
<!-- pmml -->
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.4.1</version>
</dependency>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator-extension</artifactId>
<version>1.4.1</version>
</dependency>
2.2 模型位置
将模型存放到static目录下,如图1.7所示
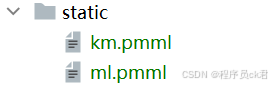
图 1.7
2.3 调用方法
在util目录下编写方法
package com.itly.rwly.utils;
import org.dmg.pmml.FieldName;
import org.dmg.pmml.PMML;
import org.jpmml.evaluator.*;
import org.jpmml.model.PMMLUtil;
import org.xml.sax.SAXException;
import javax.xml.bind.JAXBException;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.util.*;
/**
* Created with IntelliJ IDEA.
*
* @Author: 程序员CK君
* @Version: 1.0
* @Date: 2024-03-17-20:53
* @Description: 模型调用工具类
*/
@SuppressWarnings({"all"})
public class UserDefinedModel {
private Evaluator modelEvaluator;
/**
* 通过传入 PMML 文件路径来生成机器学习模型
*
* @param pmmlFileName pmml 文件路径
*/
public UserDefinedModel(String pmmlFileName) {
PMML pmml = null;
try {
if (pmmlFileName != null) {
InputStream is = new FileInputStream(pmmlFileName);
pmml = PMMLUtil.unmarshal(is);
try {
is.close();
} catch (IOException e) {
System.out.println("InputStream close error!");
}
ModelEvaluatorFactory modelEvaluatorFactory = ModelEvaluatorFactory.newInstance();
this.modelEvaluator = (Evaluator) modelEvaluatorFactory.newModelEvaluator(pmml);
modelEvaluator.verify();
System.out.println("加载模型成功!");
}
} catch (SAXException e) {
e.printStackTrace();
} catch (JAXBException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
// 获取模型需要的特征名称
public List<String> getFeatureNames() {
List<String> featureNames = new ArrayList<String>();
List<InputField> inputFields = modelEvaluator.getInputFields();
for (InputField inputField : inputFields) {
featureNames.add(inputField.getName().toString());
}
return featureNames;
}
// 获取目标字段名称
public String getTargetName() {
return modelEvaluator.getTargetFields().get(0).getName().toString();
}
//
public String predict(String a, String b) {
Map<String, String> data = new HashMap<>();
data.put("经度", a);
data.put("维度", b);
List<InputField> inputFields = modelEvaluator.getInputFields();
// 过模型的原始特征,参数获取,作为模型输入
Map<FieldName, FieldValue> arguments = new LinkedHashMap<FieldName, FieldValue>();
for (InputField inputField : inputFields) {
FieldName inputFieldName = inputField.getName();
Object rawValue = data.get(inputFieldName.getValue());
FieldValue inputFieldValue = inputField.prepare(rawValue);
arguments.put(inputFieldName, inputFieldValue);
}
Map<FieldName, ?> results = modelEvaluator.evaluate(arguments);
List<TargetField> targetFields = modelEvaluator.getTargetFields();
TargetField targetField = targetFields.get(0);
FieldName targetFieldName = targetField.getName();
Object targetFieldValue = results.get(targetFieldName);
System.out.println("target: " + targetFieldName.getValue() + " 预测结果: " + targetFieldValue);
// int primitiveValue = -1;
// if (targetFieldValue instanceof Computable) {
// Computable computable = (Computable) targetFieldValue;
// primitiveValue = (Integer)computable.getResult();
// }
// System.out.println(a + " " + b + ":" + primitiveValue);
return targetFieldValue + "";
}
}
2.4 实现调用
在controller目录下编写一个类,如下代码,
package com.itly.rwly.controller;
import com.itly.rwly.pojo.Code;
import com.itly.rwly.pojo.RandomForestParam;
import com.itly.rwly.pojo.Result;
import com.itly.rwly.utils.UserDefinedModel;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
/**
* Created with IntelliJ IDEA.
*
* @Author: 程序员CK君
* @Version: 1.0
* @Date: 2024-03-17-22:17
* @Description: 随机森林预测 --根据经纬度预测地级 和 震深
*/
@Controller
@RequestMapping("/rfs")
@SuppressWarnings("all")
public class RandomForestController {
@PostMapping("/data")
@ResponseBody
public Result getData3(@RequestBody RandomForestParam param) {
// 震级模型存放目录
UserDefinedModel clf = new UserDefinedModel("src/main/resources/static/ml.pmml");
String ml = clf.predict(param.getLongitude(), param.getDim());
// 震深模型存放目录
UserDefinedModel clf2 = new UserDefinedModel("src/main/resources/static/km.pmml");
String km = clf2.predict(param.getLongitude(), param.getDim());
// 加入数据
String data = ml + "-" + km;
return new Result(data != null ? Code.GET_OK : Code.GET_ERR, data);
}
}
2.5 输入参数验证
使用Postman验证,如图1.8所示.。。。可视化省略
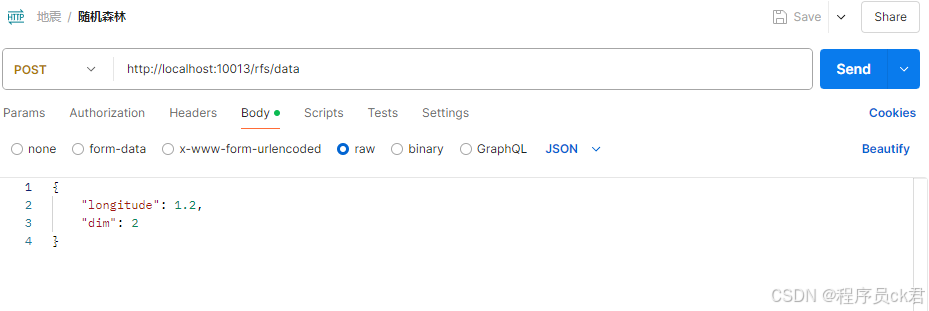
图1.8

















 4457
4457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









