






摘要:
本文记录了针对无人机实时视频流中人车目标检测、跟踪与计数任务进行优化的全过程。面对初期基于YOLO的方案在推理延迟、小目标漏检、计数不准及相机移动干扰等问题,本文探索并实践了多种优化策略,包括引入基于Transformer的RF-DETR模型、视频预处理、目标跟踪算法对比与调优(ByteTrack)、相机运动补偿探索及数据增强等,最终结合异步处理架构实现了接近实时的推理效果,并分享了过程中的关键挑战与经验总结。

一、 引言与初期挑战
在无人机视觉应用中,实时准确地检测、跟踪并计数地面目标(如行人、车辆)具有重要意义。本项目初期采用基于 YOLOv11n 的目标检测模型进行基础的检测任务,使用 VisDrone-DET 数据集训练。虽然初步展现了较好的目标提取能力,但在尝试基于此进行实时跟踪与计数时,遇到了几大挑战:
-
计数导致的严重卡顿: 最初采用的基于YOLO检测结果的区域计数方法,其对边界目标的逐帧NMS(非极大值抑制)计算成为巨大瓶颈,导致处理速度远低于实时要求(目标30Hz)。
-
推理延迟与掉帧: 即使不考虑计数,基础检测推理也存在一定的延迟。
-
识别不全: 特别是对于密集或细小的目标存在遗漏。
后续的优化工作主要围绕解决这些核心问题展开,重点是改进跟踪与计数流程以突破性能瓶颈。
二、 优化探索:应对延迟与小目标漏检 (初步探索)
2.1 视频处理与多线程
-
初步尝试 (
ffmpeg): 考虑使用ffmpeg对视频进行抽帧或降低分辨率/码率,但判断这可能牺牲检测精度,并非最优方向。 -
多线程加载: 实现多线程加载视频帧。这在一定程度上缓解了基础推理的延迟,但无法解决计数瓶颈,且小目标和密集目标识别不全的问题依旧存在。
2.2 SAHI 技术探索 (小目标检测)
-
研究引入: 针对小目标漏检问题,研究了CVPR论文提出的SAHI(切片辅助超推理)技术。

-
适用性分析与结论: 分析了SAHI的原理与计算量后,通过实测发现其计算开销对于实时视频流来说过高,会导致严重卡顿。判断SAHI不适合此实时任务,但其思路对静态图像或低帧率场景有价值。
2.3 视频压缩策略
-
方向确认: 既然算法层面的优化是重点,决定先通过视频压缩为后续更复杂的算法争取处理时间。
-
实践: 使用
ffmpeg结合多线程推理,对输入视频进行降低分辨率(至720p)、降低帧率(至20Hz)、降低数据速率(至2000kbps以下)的处理。 -
效果: 处理后的视频流基本满足了实时输入的要求,为后续引入更优的跟踪计数算法奠定了基础。
三、 优化核心:引入RF-DETR与ByteTrack实现实时跟踪计数
3.1 突破计数瓶颈:选择RF-DETR
-
问题根源: 深刻认识到基于传统检测+NMS后处理的计数方法是性能瓶颈。
-
新模型引入: 调研并引入了基于Transformer的视觉算法 [RF-DETR](RF-DETR Object Detection Model: What is, How to Use)。该模型通过全局自注意力机制和匈牙利匹配策略实现端到端的目标检测,避免了耗时的NMS后处理,理论上更适合需要精确计数的场景。
-
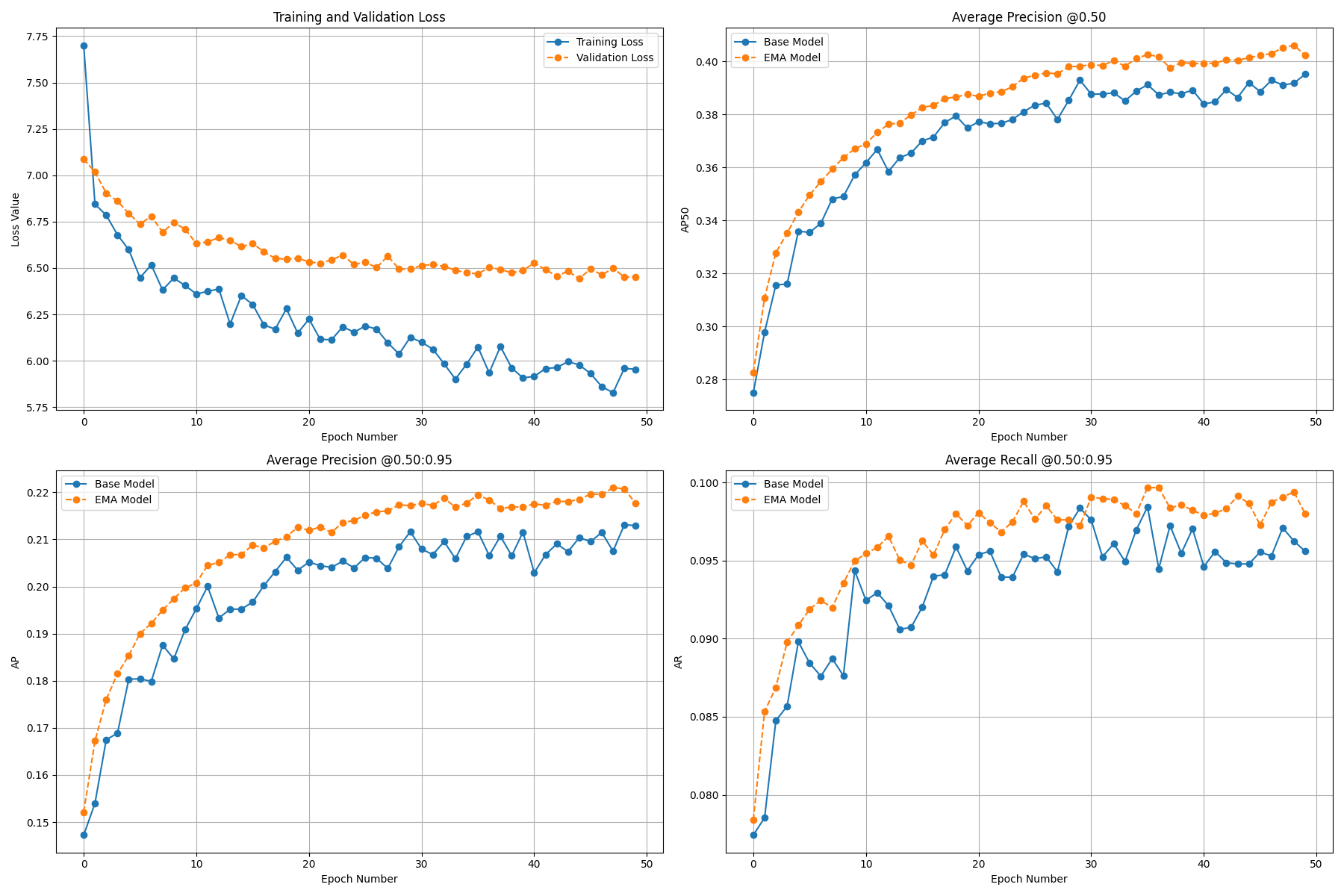
模型评估:
对RF-DETR模型进行了微调训练,结果显示模型稳定收敛,并在精度(AP)和召回率(AR)指标上表现良好,证明了其潜力。
3.2 跟踪算法选型与实施
-
需求: 需要一个高效的跟踪器来处理RF-DETR的检测输出,并分配唯一ID以实现准确计数。
-
算法对比: 再次评估了BOT-SORT和
ByteTrack。考虑到RF-DETR已解决部分检测问题且计算开销相对可控,结合无人机场景特点(轻量化需求、运动干扰),最终选择ByteTrack作为跟踪器。 -
简化实现 (
supervision库): 为了快速高效地实现复杂的跟踪逻辑和可视化,引入了supervision这个优秀的Python计算机视觉库。它提供了便捷的接口,可以用很少的代码实现诸如ByteTrack跟踪器的集成、检测框与轨迹的可视化绘制、区域计数等功能,极大地简化了开发流程。(尽管在中文标签显示上遇到一些小问题,需要额外处理,但其整体优势显著)。 -
效果达成: 将RF-DETR的检测结果输入到通过
supervision实现的ByteTrack跟踪器中。在处理后的视频(720p, 20Hz)上测试,实现了仅比原始视频延迟几秒的近实时跟踪与计数效果。
3.3 跟踪鲁棒性提升:处理重复计数
-
问题: 目标在跟踪过程中仍可能因遮挡、形变等原因丢失ID后被重新识别,导致重复计数。
-
方案对比与选择: 对比了增加Re-ID(计算开销大)和严格化跟踪器参数(可能牺牲召回率)两种方案后,选择严格化
ByteTrack参数。 -
参数调优:
详细分析并根据实验确定了一组合适的
ByteTrack参数(track_activation_threshold=0.5,lost_track_buffer=120,minimum_matching_threshold=0.95,minimum_consecutive_frames=2,frame_rate=20),在保证召回率不过度牺牲的前提下,提升跟踪的准确性和鲁棒性。tracker = sv.ByteTrack( track_activation_threshold=0.5, # 提高激活阈值 lost_track_buffer=120, # 缩短丢失缓冲时间(3秒,假设20fps) minimum_matching_threshold=0.95, # 降低匹配阈值 minimum_consecutive_frames=2, # 增加连续帧要求 frame_rate=20 # 确保与实际帧率一致 )
四、 应对挑战:相机运动补偿探索与数据增强
4.1 相机运动补偿 (CMC) 探索
-
问题观察: 发现在相机移动(非目标自身移动)时,
ByteTrack的跟踪效果下降,分析认为与minimum_consecutive_frames参数及检测器在目标形变/模糊时的召回率下降有关。 -
尝试CMC:
探索性地研究并实现了一种将相机运动补偿(通过计算相邻帧间仿射变换矩阵)修正到
ByteTrack卡尔曼滤波状态的方法。class CMCByteTrack(ByteTrack): def __init__(self, track_thresh: float = 0.5, match_thresh: float = 0.8, frame_rate: int = 30): super().__init__(track_thresh=track_thresh, match_thresh=match_thresh, frame_rate=frame_rate) self.prev_frame: Optional[np.ndarray] = None # 存储前一帧图像 self.affine_matrix: Optional[np.ndarray] = None # 仿射变换矩阵 def _compute_affine_matrix(self, current_frame: np.ndarray) -> Optional[np.ndarray]: """ 计算相邻帧之间的仿射变换矩阵(使用SIFT+RANSAC) """ if self.prev_frame is None: return None # 特征检测与匹配 sift = cv2.SIFT_create() kp1, des1 = sift.detectAndCompute(cv2.cvtColor(self.prev_frame, cv2.COLOR_BGR2GRAY), None) kp2, des2 = sift.detectAndCompute(cv2.cvtColor(current_frame, cv2.COLOR_BGR2GRAY), None) # 使用FLANN匹配器 flann = cv2.FlannBasedMatcher(dict(algorithm=1, trees=5), dict(checks=50)) matches = flann.knnMatch(des1, des2, k=2) # 筛选优质匹配点 good_matches = [] for m, n in matches: if m.distance < 0.7 * n.distance: good_matches.append(m) # 至少需要3对匹配点计算仿射变换 if len(good_matches) < 3: return None src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2) dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2) # 使用RANSAC估计仿射矩阵 matrix, _ = cv2.estimateAffine2D(src_pts, dst_pts, method=cv2.RANSAC, ransacReprojThreshold=5.0) return matrix def _apply_cmc_to_tracks(self): """ 应用仿射变换到所有跟踪轨迹的卡尔曼滤波状态 """ if self.affine_matrix is None: return # 分解仿射矩阵参数 a, b, tx = self.affine_matrix[0, 0], self.affine_matrix[0, 1], self.affine_matrix[0, 2] c, d, ty = self.affine_matrix[1, 0], self.affine_matrix[1, 1], self.affine_matrix[1, 2] scale = np.sqrt(a * a + c * c) # 近似缩放因子 # 构造8x8扩展矩阵和8维平移向量 M_ext = np.array([ [a, b, 0, 0, 0, 0, 0, 0], [c, d, 0, 0, 0, 0, 0, 0], [0, 0, scale, 0, 0, 0, 0, 0], [0, 0, 0, scale, 0, 0, 0, 0], [0, 0, 0, 0, a, b, 0, 0], [0, 0, 0, 0, c, d, 0, 0], [0, 0, 0, 0, 0, 0, scale, 0], [0, 0, 0, 0, 0, 0, 0, scale] ]) T_ext = np.array([tx, ty, 0, 0, 0, 0, 0, 0]) # 修正每个跟踪轨迹的卡尔曼状态 for track in self.tracker.tracks: if track.is_activated: # 获取卡尔曼滤波的状态向量(8维) state = track.mean.reshape(8, 1) # 应用变换: x' = M_ext * x + T_ext corrected_state = M_ext @ state + T_ext.reshape(8, 1) track.mean = corrected_state.reshape(1, 8) def update(self, detections: List[Tuple[int, int, int, int, float, int]], frame: np.ndarray) -> List[Tuple[int, int, int, int, int]]: # 计算当前帧与前一帧的仿射变换 self.affine_matrix = self._compute_affine_matrix(frame) # 应用CMC修正跟踪状态 if self.affine_matrix is not None: self._apply_cmc_to_tracks() # 调用父类ByteTrack的update方法 tracks = super().update(detections, frame) # 存储当前帧供下一帧使用 self.prev_frame = frame.copy() return tracks当前状态: CMC代码实现后观察到一定改善,但未能根本解决问题,优先级暂时不高。判断更根本的解决方案在于提升检测模型本身的鲁棒性。
4.2 数据增强策略
-
根本解决方案: 认识到需要让检测模型(RF-DETR)在训练阶段就学习适应运动带来的图像变化。
-
实施:引入
Albumentations库,设计了强大的数据增强管道,在训练数据中重点模拟相机运动和视角变化可能导致的模糊、形变、遮挡等情况。# --- 1. 定义强大的数据增强管道 (借鉴 YOLO 策略) --- # 注意: Bbox 格式需要与你的数据集标注格式匹配 (例如 'pascal_voc', 'coco', 'yolo') # VisDrone 原始格式是左上角xy + 宽高wh,接近 'coco' 或 'pascal_voc' (需要确认具体加载方式) # 这里假设使用 'pascal_voc' (xmin, ymin, xmax, ymax),如果你的加载器用了 'coco' (xmin, ymin, w, h),请修改 format # label_fields=['labels'] 假设你的数据加载器返回的标注字典中,类别标签的 key 是 'labels',如果不同请修改 BBOX_FORMAT = 'coco' LABEL_FIELDS = ['labels'] # 定义训练时的数据增强 # 组合了颜色、几何、模糊、遮挡等增强 train_transforms = A.Compose([ # --- 颜色增强 --- A.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0.05, p=0.8), # --- 几何增强 (核心,模拟运动和视角变化) --- # 随机调整大小并安全裁剪,确保 BBox 不会完全丢失 (除非太小) # 输入图像大小应接近你的模型输入 resolution (448),这里设大一点允许裁剪 A.RandomSizedBBoxSafeCrop(width=640, height=640, erosion_rate=0.2, p=0.5), # 调整到模型输入尺寸 A.Resize(height=448, width=448, p=1.0), # 水平翻转 A.HorizontalFlip(p=0.5), # 仿射变换: 平移、缩放、旋转 (模拟相机和物体相对运动) # 注意: rotate_limit, shear_limit 可以根据需要调整范围 # border_mode=cv2.BORDER_CONSTANT 用于处理变换后产生的边界像素 A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.2, rotate_limit=15, border_mode=cv2.BORDER_CONSTANT, value=0, p=0.8), # value=0 用黑色填充 # 透视变换 (更强的视角变化模拟) A.Perspective(scale=(0.05, 0.1), keep_size=True, p=0.3), # --- 模拟运动模糊 --- A.MotionBlur(blur_limit=(3, 11), p=0.5), # blur_limit 控制模糊核大小范围 # --- 模拟遮挡 --- # Cutout/CoarseDropout: 随机挖掉一些区域 A.CoarseDropout(max_holes=8, max_height=40, max_width=40, min_holes=1, min_height=20, min_width=20, fill_value=0, p=0.5), # fill_value=0 用黑色填充 # --- 标准化 & 转 Tensor --- # 这里的 mean 和 std 通常使用 ImageNet 预训练模型的统计值 # 如果 RFDETR 有自己的特定值,请使用那些值 A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ToTensorV2(), # 将图像和标签转换为 PyTorch Tensor ], bbox_params=A.BboxParams(format=BBOX_FORMAT, label_fields=LABEL_FIELDS, min_visibility=0.1))目标: 通过增强训练,提升RF-DETR模型在动态场景下的检测鲁棒性,从而间接提升
ByteTrack的跟踪稳定性。已启动相关训练。
五、 集成与部署:实时推理框架
-
目标: 将优化后的模型(
RF-DETR + ByteTrack)集成到WebRTC框架中进行实时推流。 -
异步处理与实时性保障: 设计并实现了一个异步处理器 (
AsyncProcessor),通过设置输出队列最大长度为1 (maxsize=1) 来主动丢弃旧帧,优先保证输出最新帧及其计数信息,从而在处理波动时维持交互的实时性。
六、 结论与总结
通过引入RF-DETR模型解决NMS瓶颈,结合轻量高效的ByteTrack跟踪器(并利用supervision库简化实现),并通过视频预处理、跟踪器参数精调、探索相机运动补偿以及实施针对性的数据增强策略,我们成功将无人机视角下的人车检测与跟踪计数任务从初期面临严重卡顿和精度问题,优化至接近实时的水平。
关键优化点与学习:
-
模型选型是核心: RF-DETR的端到端特性是突破计数瓶颈的关键。
-
跟踪器选择与调优:
ByteTrack在轻量级和性能间取得良好平衡,精细调参至关重要。 -
supervision库提效: 该库极大简化了跟踪与可视化代码。 -
数据增强应对动态场景: 对于运动、遮挡等问题,数据增强是提升模型鲁棒性的根本途径之一。
-
系统设计保障实时性: 异步处理和队列管理是应对实时系统中处理波动的有效手段。
这个过程充分体现了算法优化是一个涉及模型、数据、系统架构多方面权衡与迭代的复杂工程。未来的工作将包括解决提升推理速度以及适配帧格式大小的问题,以及持续评估数据增强训练的效果。

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









