







1.早融合(Early fusion)
就是在特征上进行融合,进行不同特征的连接,输入到一个模型中进行训练。(先融合多层的特征,然后在融合后的特征上训练预测器,只有在完全融合之后,才进行检测。)这类方法也被称为skip connection,即采用concat、add操作。这一思路的代表是Inside-Outside Net (ION)和HyperNet.
经典的早融合方法:
(1)concat:系列特征融合,直接将连个特征进行连接。两个输入特征x和y的维数若为p和q,输出特征z的维数为p+q。
(2)add:并行策略,将这两个特征向量组合成复合向量,对于输入特征x和y,z=x+iy,其中i是虚数单位。
1.1 DCA(Dynamic Channel Attention)特征融合
博客来源:https://blog.csdn.net/snail_crawling/article/details/84568071
DCA最大化两个特征集中对应特征的相关关系,同时最大化不同类之间的差异。
DCA通过按顺序捕获多尺度编码器特征之间的通道和空间依赖关系来解决编码器特征和解码器特征之间的语义差距。
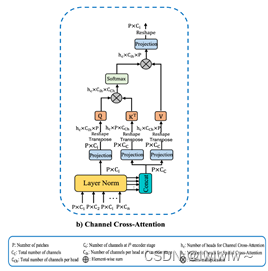
首先,通道交叉注意(CCA)通过利用多尺度编码器特征的跨通道token的交叉注意提取全局通道依赖关系。
然后,空间交叉注意(SCA)模块进行交叉注意操作,来捕获跨空间令牌的空间依赖性。
最后,将这些细粒度的编码器特征上采样并连接到相应的解码器部分,形成skip-connection方案。
1. 模型的特点
模型大致示意如下。DCA模块的结构不受编码器stage数量的影响,给定n+1个多尺度编码器stage,DCA将前n个stage的特征层作为输入,产生增强表示,并将它们连接到相应的n个解码器stage。
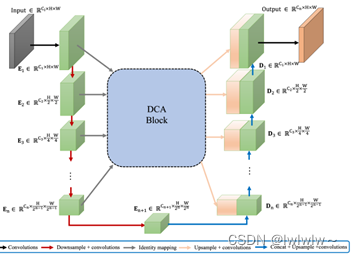
如下图所示,DCA可以分为两个主要阶段,三个步骤:
第一阶段由多尺度patch embedding模块组成,以获得编码器Token。
第二阶段,在这些编码器token上使用通道交叉注意(CCA)和空间交叉注意(SCA)模块来实现DCA,以捕获长距离依赖关系。
最后,使用层归一化和GeLU对这些token进行序列化和上采样,将它们连接到解码器对应部分。
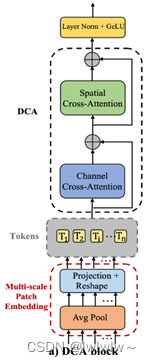
通道交叉注意力(CCA)
1.2 Inside-Outside Net(ION)
来源:https://blog.csdn.net/qq_36926037/article/details/111572980
1.2.1模型介绍
1.2.1.1主要贡献
本文采用的技术方法(空间RNNs【1,2,3】 ,跳层连接 )在其他文献中有先例,但它们良好的组合对检测器的准确性有意想不到的积极影响。本文贡献如下:
(1) 介绍了利用上下文和多尺度跳跃池化进行目标检测的ION架构。
(2) 在PASCAL VOC和COCO数据集上取得了最先进的成果
(3) 进行了大量的实验来评估选择:如合并的层数、使用分割损失、归一化特征振幅、不同的RNN架构,和其他变化。
(4) 分析了ION的性能,发现了全面改进的精度,特别是对小型物体。
1.2.1.2架构inside-outside net(ION)
两个特色:
- Outside Net
所谓 Outside 是指 ROI 区域之外,也就是目标周围的 上下文(Contextual)信息。 作者通过添加了两个 RNN 层(修改后的 IRNN)实现上下文特征提取。 上下文信息 对于目标遮挡有比较好的适应。
- Inside Net(常用)
所谓 Inside 是指在 ROI 区域之内,通过连接不同 Scale 下的 Feature Map,实现多尺度特征融合。这里采用的是 Skip-Pooling,从 conv3-4-5-context 分别提取特征,后面会讲到。 多尺度特征 能够提升对小目标的检测精度。
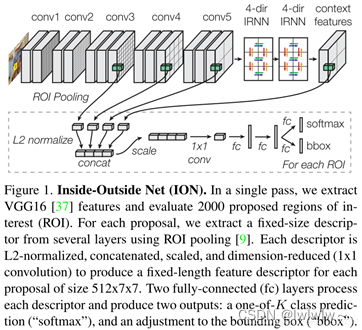
这是一个在ROI内部和外部都改进描述符的检测器。
①单一深度卷积网络处理图像,来自卷积神经网络每一层的特征图存储在内存中。
②在网络的顶部一个2倍堆叠的4方向IRNN计算描述图像全局和局部的上下文特征(上下文特征具有与“conv5”相同的维度)。
③数千个建议区域(ROI ,可能包含目标),对于每个ROI从几个层(“conv3”、“conv4”、“conv5”和“上下文特征”)提取一个固定长度的特征描述符,描述符被l2标准化、连接、重新缩放和降维(1x1卷积)以产生固定长度的特征描述符——512x7x7。
④两个全连接(FC)层处理每个描述符并产生两个输出 -k类预测(“softmax”)和调整建议区域的边界框(“bbox”)。
IRNN工作原理:
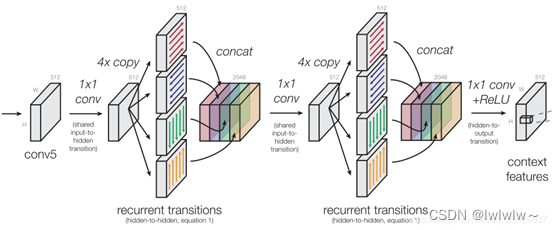
ION网络的每个循环层有四个向四个方向移动的独立的IRNN。 **为了高效实现IRNN,将内部IRNN的计算划分为4个独立逻辑层(如图,分别运行一个方向的IRNN),从这个角度看输入到隐藏的转换相当于一个1x1卷积,它可以在不同的方向上共享。**偏差可以以同样的方式共享,并合并到1x1 conv层。IRNN层现在只需要在每一步应用循环矩阵和非线性。
IRNN的输出是通过在每个空间位置连接四个方向的隐藏状态来计算的。
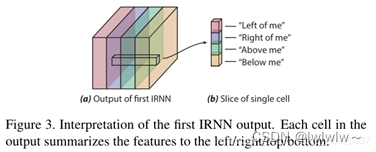
解释:
- 在第一个4方向的IRNN(从两个IRNN中)之后,得到一个特征图,它概括了图像中每一个位置附近的目标。如图所示第一个IRNN创建了每个单元格的左/右/顶/底的特征摘要。
- 随后的1x1卷积将这些信息混合在一起作为降维。
- 第二个4方向IRNN之后,输出的每个单元依赖于输入的每个单元。通过这种方式,我们的上下文特征既是全局的,也是局部的。特征因空间位置的不同而不同,每个单元格都是相对于特定空间位置的图像的全局摘要。
1.3 FSSD
1.3.1 FSSD模型架构
FSSD是SSD的改进版,算是SSD+FPN思想的结合
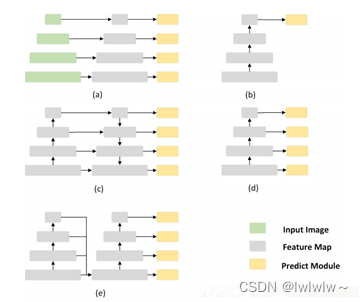
这张图在FPN里面也有一张类似的,
1. (a) image pyramid
2. (b) rcnn系列,只在最后一层feature预测
3. (c) FPN,语义信息一层传递回去,而且有很多相加的计算
4. (d) SSD,在各个level的feature上直接预测,每个level之间没联系
5. (e) 本文的做法,把各个level的feature concat,然后从fusion feature上生成feature pyramid
2.晚(后)融合
指的是在预测分数上进行融合,做法就是训练多个模型,每个模型都会有一个预测分数,我们对所有模型的结果进行融合,得到最后的预测结果。(通过结合不同层的检测结果改进检测性能,尚未完成最终融合之前,在部分融合的层上就开始检测,会有多层的检测,最终将多个检测结果进行融合)。
这一类研究思路的代表有两种:
(1)feature不融合:多尺度的feture分别进行预测,然后对预测结果进行综合,如Single Shot MultiBox Detector(SSD),Multi-scale CNN(MS-CNN).
(2)feature进行金字塔融合,融合后进行预测,如Feature Pyramid Network(FPN)等
2.1 SSD(Single Shot MultiBox Detector)
来源1::http://blog.csdn.net/u010167269/article/details/52563573
来源2:https://blog.csdn.net/qq_41368247/article/details/88027340
论文代码:GitHub - weiliu89/caffe at ssd
代码讲解来源:https://blog.csdn.net/IanYue/article/details/126544187
2.1.1SSD模型讲解
SSD(Single Shot MultiBox Detector)主要贡献:
1.提出了新的物体检测方法:SSD,比原先最快的 YOLO: You Only Look Once 方法,还要快,还要精确。保证速度的同时,其结果的 mAP 可与使用 region proposals 技术的方法(如 Faster R-CNN)相媲美。
2.SSD 方法的核心就是 predict object(物体),以及其 归属类别的 score(得分);同时,在 feature map 上使用小的卷积核,去 predict 一系列 bounding boxes 的 box offsets。
3.本文中为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。
4.本文的这些改进设计,能够在当输入分辨率较低的图像时,保证检测的精度。同时,这个整体 end-to-end 的设计,训练也变得简单。在检测速度、检测精度之间取得较好的 trade-off。
5.本文提出的模型(model)在不同的数据集上,如 PASCAL VOC、MS COCO、ILSVRC, 都进行了测试。在检测时间(timing)、检测精度(accuracy)上,均与目前物体检测领域 state-of-art 的检测方法进行了比较。
SSD模型:
SSD 是基于一个前向传播 CNN 网络,产生一系列 固定大小(fixed-size) 的 bounding boxes,以及每一个 box 中包含物体实例的可能性,即 score。之后,进行一个 非极大值抑制(Non-maximum suppression) 得到最终的 predictions。
SSD 模型的最开始部分,本文称作 base network,是用于图像分类的标准架构。在 base network 之后,本文添加了额外辅助的网络结构:
Multi-scale feature maps for detection
在基础网络结构后,添加了额外的卷积层,这些卷积层的大小是逐层递减的,可以在多尺度下进行 predictions。
Convolutional predictors for detection
每一个添加的特征层(或者在基础网络结构中的特征层),可以使用一系列 convolutional filters,去产生一系列固定大小的 predictions,具体见 Fig.2。对于一个大小为 ,具有 通道的特征层,使用的 convolutional filters 就是 的 kernels。产生的 predictions,那么就是归属类别的一个得分,要么就是相对于 default box coordinate 的 shape offsets。
在每一个 的特征图位置上,使用上面的 的 kernel,会产生一个输出值。bounding box offset 值是输出的 default box 与此时 feature map location 之间的相对距离(YOLO 架构则是用一个全连接层来代替这里的卷积层)。
Default boxes and aspect ratios
每一个 box 相对于与其对应的 feature map cell 的位置是固定的。 在每一个 feature map cell 中,我们要 predict 得到的 box 与 default box 之间的 offsets,以及每一个 box 中包含物体的 score(每一个类别概率都要计算出)。
因此,对于一个位置上的 个boxes 中的每一个 box,我们需要计算出 个类,每一个类的 score,还有这个 box 相对于 它的默认 box 的 4 个偏移值(offsets)。于是,在 feature map 中的每一个 feature map cell 上,就需要有 个 filters。对于一张 大小的 feature map,即会产生 个输出结果。
这里的 default box 很类似于 Faster R-CNN 中的 Anchor boxes,关于这里的 Anchor boxes,详细的参见原论文。但是又不同于 Faster R-CNN 中的,本文中的 Anchor boxes 用在了不同分辨率的 feature maps 上。

注:SSD目标检测算法对小目标的预测不是很好,有一类解决方法是融合低层特征和高层特征来解决,例如DensNet模型、DSSD模型、FSSD模型。
2.1.2代码讲解
2.1.2.1模型架构
class SSD300(nn.Module):
input_size = 300
def __init__(self):
super(SSD300, self).__init__()
# model
self.base = self.VGG16()
self.norm4 = L2Norm(512, 20) # 38
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1, dilation=1)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1, dilation=1)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1, dilation=1)
self.conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
self.conv8_1 = nn.Conv2d(1024, 256, kernel_size=1)
self.conv8_2 = nn.Conv2d(256, 512, kernel_size=3, padding=1, stride=2)
self.conv9_1 = nn.Conv2d(512, 128, kernel_size=1)
self.conv9_2 = nn.Conv2d(128, 256, kernel_size=3, padding=1, stride=2)
self.conv10_1 = nn.Conv2d(256, 128, kernel_size=1)
self.conv10_2 = nn.Conv2d(128, 256, kernel_size=3)
self.conv11_1 = nn.Conv2d(256, 128, kernel_size=1)
self.conv11_2 = nn.Conv2d(128, 256, kernel_size=3)
# multibox layer(第二章节会讲)
self.multibox = MultiBoxLayer()
def forward(self, x):
hs = []
h = self.base(x)
hs.append(self.norm4(h)) # conv4_3
h = F.max_pool2d(h, kernel_size=2, stride=2, ceil_mode=True)
h = F.relu(self.conv5_1(h))
h = F.relu(self.conv5_2(h))
h = F.relu(self.conv5_3(h))
h = F.max_pool2d(h, kernel_size=3, padding=1, stride=1, ceil_mode=True)
h = F.relu(self.conv6(h))
h = F.relu(self.conv7(h))
hs.append(h) # conv7
h = F.relu(self.conv8_1(h))
h = F.relu(self.conv8_2(h))
hs.append(h) # conv8_2
h = F.relu(self.conv9_1(h))
h = F.relu(self.conv9_2(h))
hs.append(h) # conv9_2
h = F.relu(self.conv10_1(h))
h = F.relu(self.conv10_2(h))
hs.append(h) # conv10_2
h = F.relu(self.conv11_1(h))
h = F.relu(self.conv11_2(h))
hs.append(h) # conv11_2
loc_preds, conf_preds = self.multibox(hs)
return loc_preds, conf_preds
2.1.2.2MultiBoxLayer代码
class MultiBoxLayer(nn.Module):
num_classes = 21
num_anchors = [4,6,6,6,4,4]
in_planes = [512,1024,512,256,256,256]
def __init__(self):
super(MultiBoxLayer, self).__init__()
self.loc_layers = nn.ModuleList()
self.conf_layers = nn.ModuleList()
for i in range(len(self.in_planes)):
self.loc_layers.append(nn.Conv2d(self.in_planes[i], self.num_anchors[i]*4, kernel_size=3, padding=1))
self.conf_layers.append(nn.Conv2d(self.in_planes[i], self.num_anchors[i]*21, kernel_size=3, padding=1))
2.1.2.3Default box代码
'''Compute default box sizes with scale and aspect transform.'''
scale = 300.
steps = [s / scale for s in (8, 16, 32, 64, 100, 300)]
sizes = [s / scale for s in (30, 60, 111, 162, 213, 264, 315)]
aspect_ratios = ((2,), (2,3), (2,3), (2,3), (2,), (2,))
feature_map_sizes = (38, 19, 10, 5, 3, 1)
# 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
num_layers = len(feature_map_sizes)
boxes = []
for i in range(num_layers):
fmsize = feature_map_sizes[i] # feature map size
for h,w in itertools.product(range(fmsize), repeat=2):
# for each point in feature map
cx = (w + 0.5)*steps[i]
cy = (h + 0.5)*steps[i]
s = sizes[i]
boxes.append((cx, cy, s, s))
s = math.sqrt(sizes[i] * sizes[i+1])
boxes.append((cx, cy, s, s))
s = sizes[i]
for ar in aspect_ratios[i]:
boxes.append((cx, cy, s * math.sqrt(ar), s / math.sqrt(ar)))
boxes.append((cx, cy, s / math.sqrt(ar), s * math.sqrt(ar)))
self.default_boxes = torch.Tensor(boxes)
2.2 MFF-SSD模型
原文链接:https://blog.csdn.net/oijdkd/article/details/120322394
由于SSD网络生成的预测框质量较低,导致小尺度目标或被遮挡的目标定位失败,影响检测效果,所以针对SSD算法在检测小目标存在检测视野范围小、检测图像长宽比单一、检测精度较低、实时性较差等问题,提出了一种基于SSD多尺度特征融合的模型(MFF-SSD)。
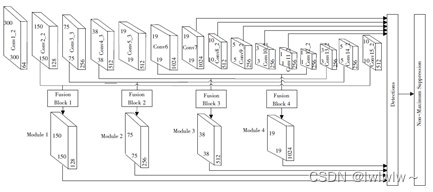
图2 MFF-SSD网络结构
1.MFF-SSD模型
在原SSD网络结构的基础上对SSD的后4层进行反卷积,得到4个反卷积模块(conv12_2,conv13_2,conv14_2以及conv15_2),利用高层网络和低层网络的优势,将高层网络和低层网络进行多尺度融合,然后将特征融合模块与SSD网络的7~11层同时输入到检测模块进行检测。共提取大小分别是(150,150)、(75,75)、(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1)的8个特征图. 该模型实现了来自不同卷积层、不同尺度、不同特征的多元信息的分类检测与位置回归。
2.融合模块
MFF-SSD模型一有4个融合模块,它们采用的都是跳跃连接的方式,以融合模块1为例进行说明。
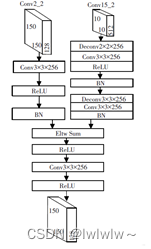
首先将高层特征图conv15_2进行上采样,使用卷积核为2 × 2 2\times 22×2,通道数为256进行反卷积,接着使用3 × 3 3\times 33×3的卷积核进行卷积,再经过激活函数ReLu输出到BN层,采用L2正则化对数据进行批量归一化,再输入到卷积和为3 × 3 3\times 33×3,通道数为256再进行一次反卷积,接着再经过卷积核大小为3 × 3 3\times 33×3的卷积,最后经过BN层输出。低层特征图conv2_2首先经过一次卷积核大小为3 × 3 3\times 33×3的卷积,再输入到ReLu,最后经BN层归一化输出。将高层特征图和低层特征图的输出进行求和操作(Eltw Sum),然后输入到ReLu层,最后再经过一次卷积和ReLu后就实现了融合。
2.3 Multi-scale CNN(MS-CNN)
代码:GitHub - zhaoweicai/mscnn: Caffe implementation of our multi-scale object detection framework
来源:https://blog.csdn.net/ture_dream/article/details/52750565
2.3.1几点创新和技巧
(1)针对多尺度问题:
类似于FCNT跟踪方法,该文章也是观察到了卷积网络不同层得到的特征特点的不同,对不同层的特征采用不同的利用方式。比如conv-3的低网络层,有更小的感受野,可以进行小目标的检测;而高层如conv-5,对于大目标的检测更加准确。对于不同的输出层设计不同尺度的目标检测器,完成多尺度下的检测问题。
注: 在卷积神经网络中,感受野的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点 在原始图像上映射的区域大小。点击打开链接
(2)针对速度问题:
使用特征的上采样代替输入图像的上采样步骤。设计一个去卷积层,来增加特征图的分辨率,使得小目标依然可以被检测出来。这里使用了特征图的deconvolutional layer(去卷积层)来代替input图像的上采样,可以大大减少内存占用,提高速度。
作者说:去卷积层一直用于分隔和边缘检测,我们第一次用它加速和提高检测率。
文章的网络结构类似RCNN,分为proposal提取和目标检测,两个部分独立进行。
2.3.2架构简介
proposal子网络和目标检测子网络结构图分别如下:
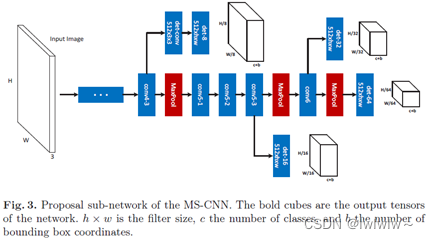
中间有色部分可以看成CNN trunk(cnn 主干线),一些层延伸了分支,分支由单检测层构成,通过分支的proposal判断为最终proposal。
技巧一:Conv4-3上面有一个缓冲卷积层,因为这一次更靠近主干线的底层(接近输入图),更影响梯度导致学习过程不稳定,缓冲卷积层能防止检测分支的梯度直接反向传播回主干线层。

2.4Feature Pyramid Network(FPN)
来源:目标检测算法FPN(Feature Pyramid Networks)简介-CSDN博客
代码讲解:https://zhuanlan.zhihu.com/p/35854548
2.4.1算法介绍
特征金字塔网络(Feature Pyramid Network)简称FPN,类似TDM(Top-Down Modulation)方法,FPN是一种自顶向下的特征融合方法,但是FPN是一种多尺度的目标检测算法,即不只有一个特征预测层。虽然有些算法也采用多尺度特征融合来进行目标检测,但是它们往往只利用融合后得到的一种尺度的特征,这种做法虽然可以将顶层特征的语义信息和底层特征细节信息,但是在特征反卷积等过程中会造成一些偏差,只利用融合后得到的特征进行预测会对检测精度造成不良影响。FPN方法从上述问题出发,可以在多个不同尺度的融合特征上进行预测,实现检测精度的最大化。
FPN使用不同分辨率的特征图感知不同大小的物体,并通过连续上采样和跨层融合机制使输出特征兼具底层视觉信息和高层语义信息。低层次的特征图语义不够丰富,不能直接用于分类,而深层的特征更值得信赖。将侧向连接与自上而下的连接组合起来,就可以得到不同分辨率的特征图,而它们都包含了原来最深层特征图的语义信息。
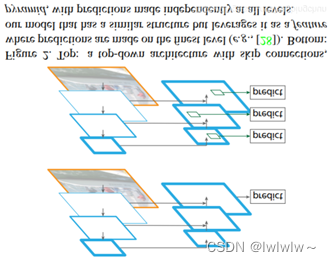
FPN特征金字塔的思想来源于传统算法中的多尺度识别,具体操作是将原始图像放缩到不同尺度大小的状态,缩小的图像应用于图像全局特征,放大的图像应用于细节特征。深度学习网络越深层次的特征图,拥有越多的全局和抽象特征。在图像分类任务中,这种深层次的特征保持了良好的平移不变性,不论分类物体图像在哪个位置,深层次的全局特征,依然可以获得信息。但是在图像识别领域中,图像分类中的平移不变性就不成立了,不光要识别出物体的分类还要识别出物体的位置,所以如何结合浅层和深层的信息是一个重要的问题。FPN通过横向连接段,纵向相加的方式,解决浅层和深层结合问题。总体结构采用自上而下的信息结构,如下图所示:在图中每一个正方形代表一个特征图,从小到大的正方形表示从深到浅的特征图。在新生成的特征图中,最浅层次拥有上面所有层次信息的特征。深层的特征语义信息比较少,但是目标位置准确;浅层的特征语义信息比较丰富,但是目标位置比较粗略。图中Top部分是一个带有skip connection的网络结构,在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。图中Bottom部分,是一个网络结构和上面的类似,区别在于预测是在每一层中独立进行的。
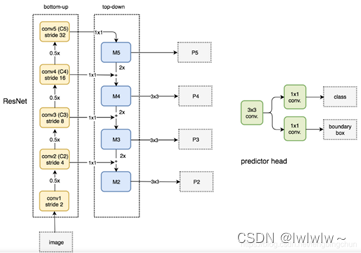
如下图所示为FPN连接结构,采用1*1的卷积层和2倍的上采样的结构。上采样(upsampling)是卷积的反向过程,又被称为反卷积网络。
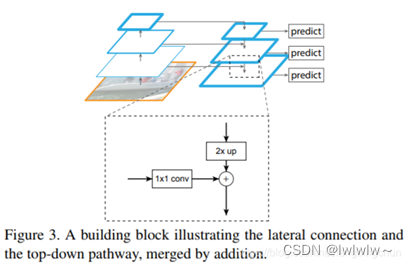
卷积操作使得特征图尺寸不断缩小或者不变(1*1卷积),而反卷积操作会使得特征图尺寸不断增大。这里使用反卷积操作是为了深层次的特征图,通过放大到和浅层的特征图一样的尺寸后,可以进行元素级别(element-wise)的相加。设计1*1卷积的结构是为了对于原有的特征图,进行的尺寸的不变的空间变换,使得结构上更加鲁棒。FPN作者的主网络采用ResNet。
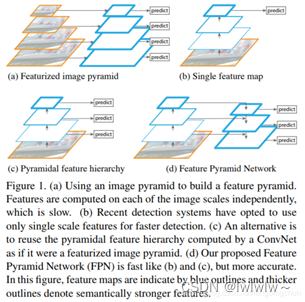
下图中展示了FPN论文中提到的4种提取特征的形式:蓝色框代表feature maps,蓝色线越粗,代表其语义信息越强。
2.4.2代码部分
1.怎么做的上采样?
高层特征怎么上采样和下一层的特征融合的,代码里面可以看到:
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)C5是 resnet最顶层的输出,它会先通过一个1*1的卷积层,同时把通道数转为256,得到FPN 的最上面的一层 P5。
KL.UpSampling2D(size=(2, 2),name="fpn_p5upsampled")(P5)Keras 的 API 说明告诉我们:
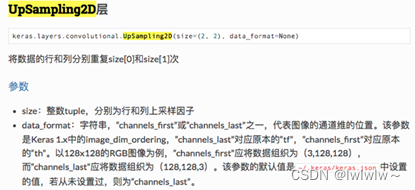
也就是说,这里的实现使用的是最简单的上采样,没有使用线性插值,没有使用反卷积,而是直接复制。
2、 怎么做的横向连接?
P4 = KL.Add(name="fpn_p4add") ([KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5), KL.Conv2D(256,(1, 1), name='fpn_c4p4')(C4)])这里可以很明显的看到,P4就是上采样之后的 P5加上1*1 卷积之后的 C4,这里的横向连接实际上就是像素加法,先把 P5和C4转换到一样的尺寸,再直接进行相加。
注意这里对从 resnet抽取的特征图做的是 1*1 的卷积:
1x1的卷积我认为有三个作用:使bottom-up对应层降维至256;缓冲作用,防止梯度直接影响bottom-up主干网络,更稳定;组合特征。
3、 FPN自上而下的网络结构代码怎么实现?
#先从 resnet 抽取四个不同阶段的特征图 C2-C5。
_, C2, C3, C4, C5 =resnet_graph(input_image, config.BACKBONE,stage5=True, train_bn=config.TRAIN_BN)# Top-down Layers构建自上而下的网络结构
#从 C5开始处理,先卷积来转换特征图尺寸
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)#上采样之后的P5和卷积之后的 C4像素相加得到 P4,后续的过程就类似了
P4 = KL.Add(name="fpn_p4add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5), KL.Conv2D(256, (1, 1),name='fpn_c4p4')(C4)])P3 = KL.Add(name="fpn_p3add")([ KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4), KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])P2 = KL.Add(name="fpn_p2add")([ KL.UpSampling2D(size=(2, 2),name="fpn_p3upsampled")(P3), KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])# P2-P5最后又做了一次3*3的卷积,作用是消除上采样带来的混叠效应
# Attach 3x3 conv to all P layers to get the final feature maps.P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)P3 = KL.Conv2D(256, (3, 3), padding="SAME",name="fpn_p3")(P3)P4 = KL.Conv2D(256, (3, 3), padding="SAME",name="fpn_p4")(P4)P5 = KL.Conv2D(256, (3, 3), padding="SAME",name="fpn_p5")(P5)# P6 is used for the 5th anchor scale in RPN. Generated by# subsampling from P5 with stride of 2.P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2,name="fpn_p6")(P5)#注意 P6是用在 RPN 目标区域提取网络里面的,而不是用在 FPN 网络
# Note that P6 is used in RPN, but not in the classifier heads.rpn_feature_maps = [P2, P3, P4, P5, P6] #最后得到了5个融合了不同层级特征的特征图列表;
注意 P6是用在 RPN 目标区域提取网络里面的,而不是用在 FPN 网络;
另外这里 P2-P5最后又做了一次3*3的卷积,作用是消除上采样带来的混叠效应。
4、 上面得到的5个融合了不同层级的特征图怎么使用?
可以看到,这里只使用2-5四个特征图:
for i, level in enumerate(range(2, 6)):#先找出需要在第 level 层计算ROI
ix = tf.where(tf.equal(roi_level, level)) level_boxes = tf.gather_nd(boxes, ix) # Box indicies for crop_and_resize. box_indices = tf.cast(ix[:, 0], tf.int32) # Keep track of which box is mapped to which level box_to_level.append(ix) # Stop gradient propogation to ROI proposals level_boxes = tf.stop_gradient(level_boxes) box_indices = tf.stop_gradient(box_indices) # Crop and Resize # From Mask R-CNN paper: "We sample four regular locations, so # that we can evaluate either max or average pooling. In fact, # interpolating only a single value at each bin center (without # pooling) is nearly as effective." # # Here we use the simplified approach of a single value per bin, # which is how it's done in tf.crop_and_resize() # Result: [batch * num_boxes, pool_height, pool_width, channels]#使用 tf.image.crop_and_resize 进行 ROI pooling
pooled.append(tf.image.crop_and_resize( feature_maps[i], level_boxes, box_indices, self.pool_shape, method="bilinear"))对每个 box,都提取其中每一层特征图上该box对应的特征,然后组成一个大的特征列表pooled。
5、 金字塔结构中所有层级共享分类层是怎么回事?
先看代码:
# ROI Pooling# Shape: [batch, num_boxes, pool_height, pool_width, channels]#得到经过 ROI pooling 之后的特征列表
x = PyramidROIAlign([pool_size, pool_size], name="roi_align_classifier")([rois, image_meta] + feature_maps)#将上面得到的特征列表送入 2 个1024通道数的卷积层以及 2 个 rulu 激活层
# Two 1024 FC layers (implemented with Conv2D for consistency)x = KL.TimeDistributed(KL.Conv2D(1024, (pool_size, pool_size), padding="valid"), name="mrcnn_class_conv1")(x)x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)x = KL.Activation('relu')(x)x = KL.TimeDistributed(KL.Conv2D(1024, (1, 1)), name="mrcnn_class_conv2")(x)x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)x = KL.Activation('relu')(x)shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2), name="pool_squeeze")(x)#分类层
# Classifier headmrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes), name='mrcnn_class_logits')(shared)mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"), name="mrcnn_class")(mrcnn_class_logits)# BBOX的位置偏移回归层
# BBox head# [batch, boxes, num_classes * (dy, dx, log(dh), log(dw))]x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'), name='mrcnn_bbox_fc')(shared)# Reshape to [batch, boxes, num_classes, (dy, dx, log(dh), log(dw))]s = K.int_shape(x)mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)这里的PyramidROIAlign得到的 x就是上面一步得到的从每个层的特征图上提取出来的特征列表,这里对这个特征列表先接两个1024通道数的卷积层,再分别送入分类层和回归层得到最终的结果。
也就是说,每个 ROI 都在P2-P5中的某一层得到了一个特征,然后送入同一个分类和回归网络得到最终结果。
FPN中每一层的heads 参数都是共享的,作者认为共享参数的效果也不错就说明FPN中所有层的语义都相似。
2.5YOLOv3
论文下载:https://pjreddie.com/media/files/papers/YOLOv3.pdf
论文代码: GitHub - pjreddie/darknet: Convolutional Neural Networks
原文链接:https://blog.csdn.net/Gentleman_Qin/article/details/84350496
2.5.1基本思想
YOLO系算法的思想都是,首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图(比如13*13),然后将输入图像划分网格成13*13个单元格,接着如果Ground Truth中某个目标的中心坐标落在哪个单元格中,那么就由该单元格来预测该目标,每个单元格都会预测固定数量的边界框(v1中是2个,v2中是5个,v3中是3个),这几个边界框中只有和Ground Truth的IOU最大的边界框才会被选定用来预测该目标。
预测得到的输出特征图有两个维度是提取到的特征,其中一个维度是平面,比如13*13,还有一个维度是深度,比如B*(5+C)(v1中是(B*5+C)),其中B表示每个单元格预测的边界框的数量,C表示边界框的对应的类别数(对于VOC数据集是20),5表示4个坐标信息和1个边界框置信得分(Objectness Score)。
YOLO v3的模型比之前复杂不少,在速度和精度上的提升也非常明显(如图1-1),同时可以通过改变模型的结构来权衡速度与精度:
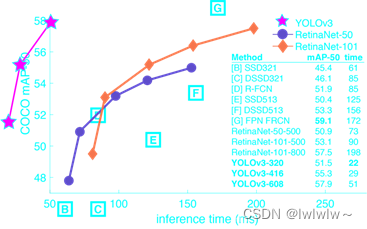
图 YOLOv3 和其他算法的性能对比
2.5.2代码实现步骤:
来源:https://blog.csdn.net/kay_beauty/article/details/107011636
1.运行./VOCdevkit/VOC2007/test.py
前提:在annotations中放入训练集的xml文件
作用:生成imagesets下的训练集,测试集,验证集等txt文件(里面包含的是xml的名称,不含后缀名)
2.运行voc_annotation.py
作用:生成包含训练集,测试集,验证集等的txt文件(里面包含路径和名称,4个坐标值,1个类别)
作用:用kmeans聚类算法生成包含9对w,h的文件:model_data/yolo_anchors.txt
另外:同时修改同一路径下的类别文件:voc_classes.txt
4.运行train.py
作用:用kmeans聚类算法生成包含9对w,h的文件:model_data/yolo_anchors.txt
另外:同时修改同一路径下的类别文件:voc_classes.txt
前提:将测试图片放到某文件夹下
作用:生成打框后的文件./img_save,以及打框坐标文件./map_txt/
2.5.3具体代码实现
代码实现地址:Yolov3代码实现_import config.yolov3_config_voc as cfg-CSDN博客
具体为:
3.注意力引导特征融合
1.Attentional Feature Fusion 注意力特征融合
(属于注意力引导的特征融合)
在AFF中,不同的特征首先分别经过一个卷积神经网络进行特征提取,然后通过一个注意力图(attention map)来加权融合这些特征。注意力图是由一个自注意力机制(self-attention mechanism)计算得到的,它可以捕捉到不同特征之间的依赖关系,并根据这些关系对特征进行加权融合。
具体来说,对于输入图像,首先通过多个卷积层分别提取出不同的特征,例如颜色、纹理和边缘等。然后,这些特征分别经过自注意力机制计算得到各自的注意力图。接下来,将不同特征的注意力图进行融合,得到一个全局注意力图。最后,将全局注意力图应用于原始特征上,通过加权融合得到最终的特征表示。
代码地址:GitHub - YimianDai/open-aff: code and trained models for "Attentional Feature Fusion"
知乎原文地址:https://zhuanlan.zhihu.com/p/424031096
提出解决方法:
注意特征融合模块(AFF),适用于大多数常见场景,包括由short and long skip connections以及在Inception层内引起的特征融合。
迭代注意特征融合模块(IAFF),将初始特征融合与另一个注意力模块交替集成。
引入多尺度通道注意力模块(MSCAM),通过尺度不同的两个分支来提取通道注意力。
实现方法:
- Multi-scale Channel Attention Module (
MS-CAM)
MS-CAM 主要是延续 SENet 的想法,再于 CNN 上结合 Local / Global 的特征,并在空间上用 Attention 来 融合多尺度信息 。
MS-CAM 有 2 个较大的不同:
1. 通过逐点卷积(1x1卷积)来关注通道的尺度问题,而不是大小不同的卷积核,使用点卷积,为了让 MS-CAM 尽可能的轻量化。
2. 不是在主干网中,而是在通道注意力模块中局部本地和全局特征上下文特征。
结构图:

上图为 MS-CAM 的结构图,X 为输入特征,X' 为融合后的特征,右边两个分支分别表示全局特征的通道注意力和局部特征的通道注意力
实现代码如下:
class MS_CAM(nn.Module):
'''
单特征进行通道注意力加权,作用类似SE模块
'''
def __init__(self, channels=64, r=4):
super(MS_CAM, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
xl = self.local_att(x)
xlg = xl + xg
return x * wei
2.Attentional Feature Fusion(AFF)
给定两个特征 X, Y 进行特征融合( Y 代表感受野更大的特征)。
对输入的两个特征 X , Y 先做初始特征融合,再将得到的初始特征经过 MS-CAM 模块,经过 sigmod 激活函数,输出值为 0~1 之间,作者希望对 X 、Y 做加权平均,就用 1 减去这组 Fusion weight ,可以作到 Soft selection ,通过训练,让网络确定各自的权重。
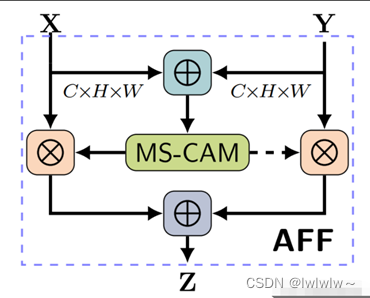
实现代码如下:
class AFF(nn.Module):
'''
多特征融合 AFF
'''
def __init__(self, channels=64, r=4):
super(AFF, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xo = x * wei + residual * (1 - wei)
return xo
3.iterative Attentional Feature Fusion ( iAFF )
在注意力特征融合模块中,X , Y 初始特征的融合仅是简单对应元素相加,然后作为注意力模块的输入会对最终融合权重产生影响。作者认为如果想要对输入的特征图有完整的感知,只有将初始特征融合也采用注意力融合的机制,一种直观的方法是使用另一个 attention 模块来融合输入的特征。
公式跟 AFF 的计算一样,仅仅是多加一层attention。
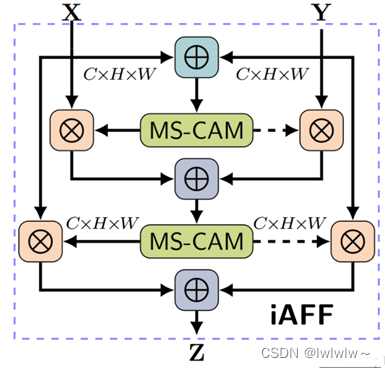
实现代码如下:
class iAFF(nn.Module):
'''
多特征融合 iAFF
'''
def __init__(self, channels=64, r=4):
super(iAFF, self).__init__()
inter_channels = int(channels // r)
# 局部注意力
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 全局注意力
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次局部注意力
self.local_att2 = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
# 第二次全局注意力
self.global_att2 = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x, residual):
xa = x + residual
xl = self.local_att(xa)
xg = self.global_att(xa)
xlg = xl + xg
wei = self.sigmoid(xlg)
xi = x * wei + residual * (1 - wei)
xl2 = self.local_att2(xi)
xg2 = self.global_att(xi)
xlg2 = xl2 + xg2
wei2 = self.sigmoid(xlg2)
xo = x * wei2 + residual * (1 - wei2)
return xo

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









