









本文是SSD的改进版,算是SSD+FPN思想的结合,FSSD: Feature Fusion Single Shot Multibox Detector
Motivation
我在上一篇SSD解读中也介绍了SSD的缺点,SSD虽然是从不同level的feature进行预测,ConvNets提取的特征随着level的增加语义越来越强,但是SSD却把它们当成一样的level,之前在上面去预测,不能充分地利用局部的细节特征和全局的语义特征。然而之前也说过定位和识别是矛盾,我们需要把细节特征(定位)和全局语义(识别)结合起来,所以本文就想着把浅层的细节特征和高层的语义特征结合起来(FPN也是这样的,但本文不和FPN完全一样,下面会介绍)
Approach
Feature Fusion

这张图在FPN里面也有一张类似的,
1. (a) image pyramid
2. (b) rcnn系列,只在最后一层feature预测
3. (c) FPN,语义信息一层传递回去,而且有很多相加的计算
4. (d) SSD,在各个level的feature上直接预测,每个level之间没联系
5. (e) 本文的做法,把各个level的feature concat,然后从fusion feature上生成feature pyramid
Architecture

- base model和SSD基本一致,只是在把Conv6_2的步长从2调到了1,这样conv7_2和Conv6_2一样也是10*10,因为论文中说他们认为小于10的feature 能够合并的信息量太少了(他们本来也merge了conv3 3,但是后面实验证明没什么用就去掉了)
- 把Conv4_3 FC7 Conv7_2这三层用1x1降维到256(和fpn一样),然后FC7 Conv7_2双线性插值到和Conv4_3一样大小的38x38,然后cat起来(是否加bn后面也有对比)成fusion feature,论文中也试了加起来效果会差点
- 如何从fusion feature生成feature pyramid也有多种方案

In (a), we only detect objects on the feature maps after the fusion feature map. In (b), the fusion feature map takes part in the object detection. 我猜测论文这句写反了
(a)是把fusion feature也用与预测了,(b)是不用fusion feature,(c)是把b中的简单的conv和relu换成了一个bottleneck效果更差了

Experiments
看到bn的作用,以及conv3_3并没有什么用,cat比sum好一些,但是我感觉实验不是十分完备,第2行和第3行只有conv3_3这个变量,没有它反而提高了,但是第5行初始化模型不一样加了Conv3_3也是最高,很蛋疼。而且最后一行的相加,是不是还得有一个没Conv3的cat,还有从vgg初始化开始。作者这是给自己挖一个坑,需要组合很多变量一一测试结果。

特别注意: GPU不同,刚开始我还以为它加了计算怎么速度还快了
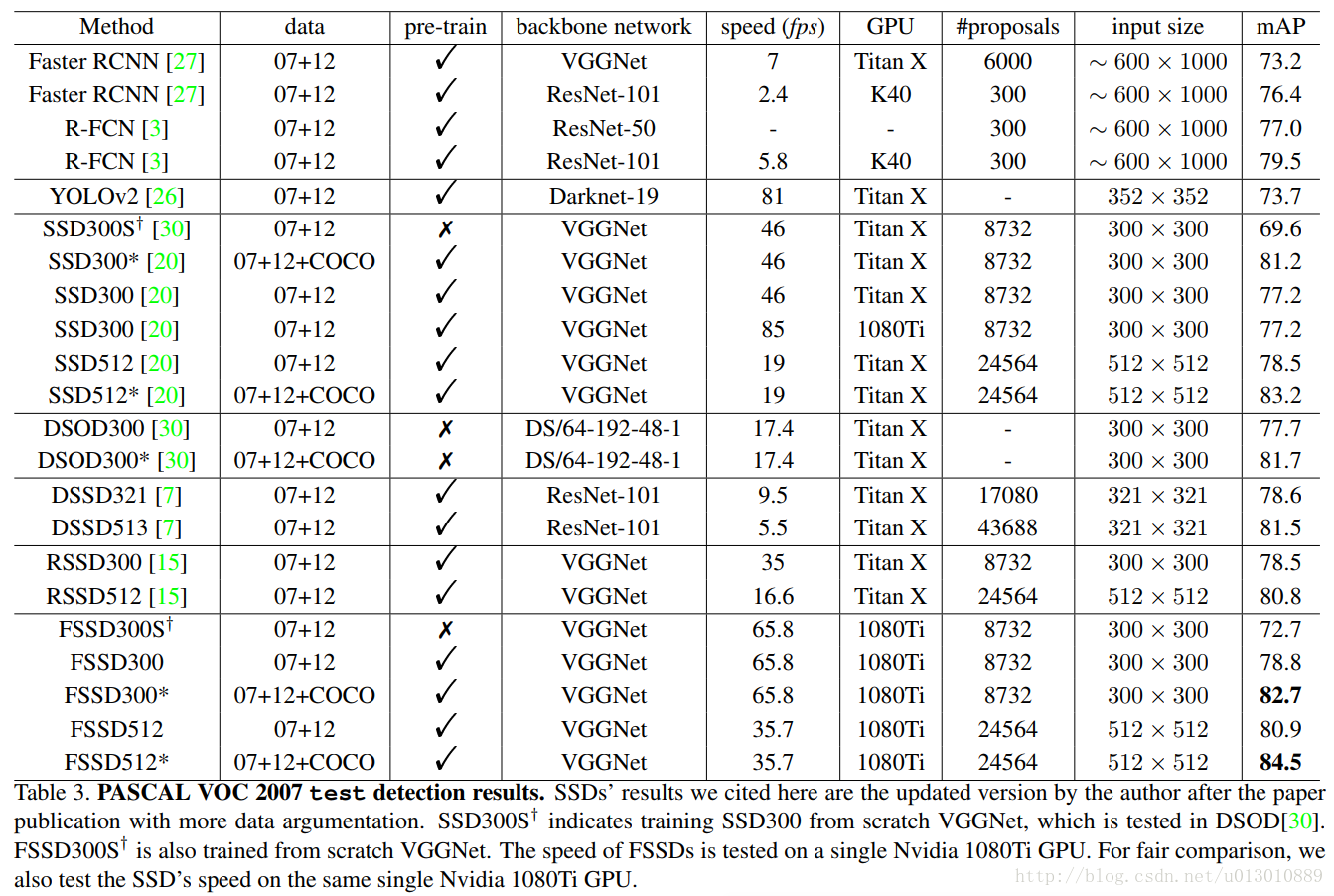
这里是用1080 Ti测试SSD和FSSD,然后反推到FSSD在Titan X的速度

Qualitative
第1列SSD会重复检测一个物体的多个part,第2列SSD会把多个物体合并成一个物体。第3-6列SSD漏了很多小物体,而FSSD都能减少这3类错误。
















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









