







在之前的文章Docker下拉取zookeeper镜像中我们已经成功地拉取了3.5.9版本的zookeeper官方镜像,下面将通过使用官方Storm镜像搭配使用官方zookeeper镜像来体验Storm的使用。
Storm是一个分布式实时计算系统,它可以处理大量的实时数据流。Storm提供了高效的并发处理能力,可以在多台机器上并行执行任务,同时具备容错和恢复能力。通过Storm,用户可以实时处理和分析数据,进行复杂的计算和实时决策。Storm的设计思想是将数据分为流(stream)和批(batch)两种模式,流模式用于实时计算,批模式则用于历史数据分析。Storm已经被广泛应用于各种场景,包括实时分析、实时计算、在线机器学习等。
拉取Storm镜像
我们拉取Storm的官方Docker镜像,在命令窗口中运行如下的命令:
docker pull storm:2.5.0注意这里拉取的是2.5.0版本的storm
等待Docker镜像拉取完毕。

创建容器
下面将使用docker-compose搭建一个由1个zookeeper节点带1个storm-nimbus结点和2个storm-supervisors结点以及1个storm-ui节点的集群:
version: '2'
services:
zookeeper:
image: zookeeper:3.5.9
container_name: zookeeper
restart: always
networks:
- storm-net
nimbus:
image: storm:2.5.0
container_name: nimbus
command: storm nimbus
depends_on:
- zookeeper
restart: always
ports:
- 6627:6627
networks:
- storm-net
supervisor-1:
image: storm:2.5.0
container_name: supervisor-1
command: storm supervisor
depends_on:
- nimbus
- zookeeper
restart: always
networks:
- storm-net
supervisor-2:
image: storm:2.5.0
container_name: supervisor-2
command: storm supervisor
depends_on:
- nimbus
- zookeeper
restart: always
networks:
- storm-net
ui:
image: storm:2.5.0
container_name: ui
command: storm ui
depends_on:
- nimbus
restart: always
ports:
- 8980:8080
networks:
- storm-net
networks:
storm-net:
driver: bridge注意:这里的zookeeper的容器名必须是zookeeper,否则storm连接不上zookeeper!(在后续的内容中我会给出解决办法)
通过Docker Desktop或者使用命令查看容器情况:
docker ps -a
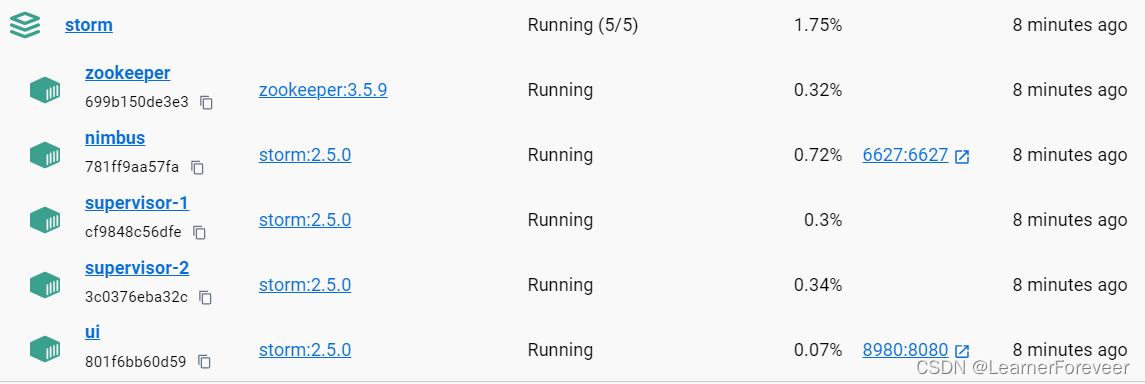
创建成功!
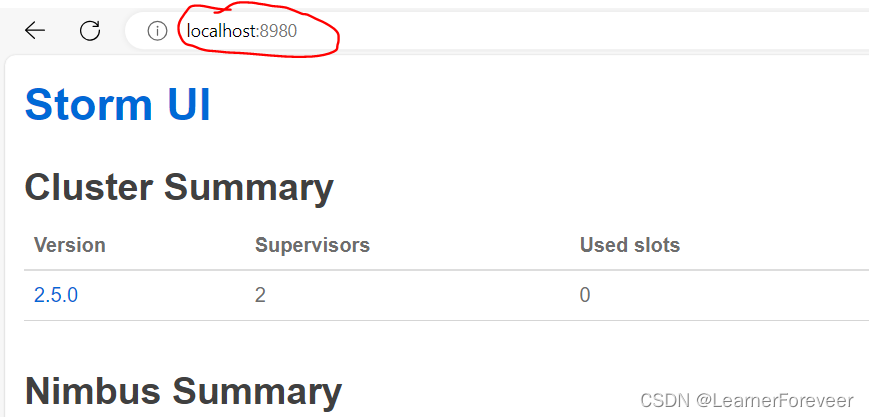
查看Storm UI
在上一步中,我们成功创建了Storm UI节点,那么Storm UI是什么呢?
Storm UI是一个Web界面,用于监控和管理Storm集群。它提供了实时的拓扑(Topology)状态信息、组件(Component)的统计数据,以及错误日志和警报信息的展示。Storm UI可视化地显示拓扑的结构和运行情况,包括拓扑的任务分配、各个组件的执行状况和数据流的流向等。通过Storm UI,用户可以方便地监控和调试拓扑,查看任务的健康状况和性能指标,并且能够及时发现和解决问题,从而提高Storm集群的稳定性和效率。
在浏览器网址栏中输入localhost:8980即可打开Storm UI界面。
创建Topology
从这里开始我们就正式开始对Storm的功能进行体验了,那么什么是Topology呢?
Topology是Storm中的核心概念,它代表了一个实时数据处理任务的拓扑结构。Topology是由多个Spout和Bolt组成的有向无环图,Spout用于从数据源获取数据并发送给Bolt,而Bolt则负责对接收到的数据进行处理和转换。Topology还定义了数据在Spout和Bolt之间的流动路径和处理逻辑,可以进行数据过滤、聚合、计算和存储等操作。拓扑的执行是分布式的,Storm会自动将拓扑的不同组件分配到集群中的各个工作节点上并进行并发执行,从而实现高效的实时数据处理。通过配置和管理Topology,用户可以灵活地构建和调整数据处理流程,以满足实时数据处理的需求。
下面我将通过“单词输出”的案例来演示Storm的基础功能。案例基于Maven和Java进行开发,这部分我就不详细说了,请自行了解。
Maven请导入依赖:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.2.0</version>
</dependency>注意这里是2.2.0而不是2.5.0,因为2.5.0似乎有bug?
创建spout,bolt和topology三个包:
创建Spout类
创建一个Spout类从上游数据源头“源源不断”地获取数据并传输给下游的bolt进行处理。这里我设计一个spout用于随机产生文本数据:
package spout;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.Map;
import java.util.Random;
public class TextGenerateSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private static final String[] sentences = {
"The quick brown fox jumps over the lazy dog.",
"Life is like a box of chocolates, you never know what you're gonna get.",
"To be or not to be, that is the question.",
"All's well that ends well.",
"Actions speak louder than words.",
"Beauty is in the eye of the beholder.",
"Curiosity killed the cat.",
"Don't count your chickens before they hatch.",
"Easy come, easy go.",
"Fortune favors the bold."
};
public static Random rd = new Random();
public static String randomPickSentence() { // 从句子数组中随机选择一个句子的静态方法
return sentences[rd.nextInt(sentences.length)];
}
@Override
public void open(Map<String, Object> map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector; // 在打开spout时,将输出collector保存到成员变量中
}
@Override
public void nextTuple() {
this.collector.emit(new Values(randomPickSentence())); // 发射一个随机选择的句子到下游组件
try {
Thread.sleep(100); // 暂停100毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence")); // 声明发射的tuple包含一个名为"sentence"的字段
}
}
创建bolt类
在这里我们创建标点去除器、单词切分器以及结果输出器以流程化处理从spout来的数据流:
Bolt是Apache Storm中的一个核心组件,用于在数据流处理拓扑中执行实际的数据处理和转换操作。类似于计算图中的节点,Bolt接收来自Spout或其他Bolt的数据流,并对其进行处理、过滤、聚合或转换等操作,然后将处理后的结果发送到下一个Bolt或输出到外部系统。Bolt通常是并行执行的,可以在集群中的多个工作节点上同时运行,以实现高吞吐量和低延迟的数据处理。每个Bolt都是通过编写自定义的数据处理逻辑来实现特定的业务需求。
PunctuationRemovalBolt
这个bolt用来将上游传入语句中的标点符号去除。
package bolt;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class PunctuationRemovalBolt extends BaseBasicBolt {
public static String removePunctuation(String sentence) {
// 使用正则表达式去除句子中的标点符号
return sentence.replaceAll("[^a-zA-Z\\s]", "");
}
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String sentence = tuple.getStringByField("sentence"); // 从输入元组中获取名为"sentence"的字段
basicOutputCollector.emit(new Values(removePunctuation(sentence))); // 发射处理后的句子到下游组件
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("clean_sentence")); // 声明发射的tuple包含一个名为"clean_sentence"的字段
}
}
WordSplitBolt
这个bolt用来对句子进行切割并逐个单词向下游提交。
package bolt;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
public class WordSplitBolt extends BaseBasicBolt {
public static String[] splitWords(String sentence) {
// 使用空格分割句子获取单词数组
return sentence.split(" ");
}
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String sentence = tuple.getStringByField("clean_sentence"); // 从输入元组中获取名为"clean_sentence"的字段
String[] words = splitWords(sentence); // 切分单词
for (String word : words) {
basicOutputCollector.emit(new Values(word)); // 发射每个单词到下游组件
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word")); // 声明发射的tuple包含一个名为"word"的字段
}
}
WordPrintBolt
这个bolt用来接收上游传入的单词并输出到控制台中。
package bolt;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
public class WordPrintBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String word = tuple.getStringByField("word"); // 从输入元组中获取名为"word"的字段
System.out.println(word); // 打印单词到控制台
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
// 不会发射任何字段,因此不需要声明
}
}
创建Topology类
Topology用来对我们之前写的Spout和Bolt进行组装,构建处理流程的有向无环图。
Topology类是Apache Storm中的一个重要概念,代表着数据流处理拓扑的结构和配置信息。它是由多个Spout和Bolt组成的有向无环图,描述了数据的流动方式和处理逻辑。Topology类提供了一种描述数据流处理流程的方式,可以定义Spout和Bolt之间的连接关系、数据流的流向以及并行度等参数。通过Topology类,我们可以配置拓扑的并发度、任务分配策略、数据流的分组方式等,以便根据具体需求来优化数据处理的性能和可靠性。另外,Topology类还提供了启动和管理拓扑的方法,可以将数据流处理作业提交到Storm集群中执行,实现高效的实时数据处理。
下面我们来实现这个Topology:
package topology;
import bolt.PunctuationRemovalBolt;
import bolt.WordPrintBolt;
import bolt.WordSplitBolt;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import spout.TextGenerateSpout;
public class WordPrintTopology {
public static void main(String[] args) throws Exception {
// 创建拓扑构建器对象
TopologyBuilder topologyBuilder = new TopologyBuilder();
// 设置spout和bolt,并指定并行度为2
topologyBuilder.setSpout("text_generate_spout", new TextGenerateSpout(), 2);
topologyBuilder.setBolt("punctuation_removal_bolt", new PunctuationRemovalBolt(), 2).shuffleGrouping("text_generate_spout");
topologyBuilder.setBolt("word_split_bolt", new WordSplitBolt(), 2).shuffleGrouping("punctuation_removal_bolt");
topologyBuilder.setBolt("word_print_bolt", new WordPrintBolt(), 2).shuffleGrouping("word_split_bolt");
// 创建配置对象
Config config = new Config();
config.setDebug(true); // 设置调试模式
if (args != null && args.length > 0) {
// 集群模式运行
config.setNumWorkers(2); // 设置工作进程数量为2
StormSubmitter.submitTopology(args[0], config, topologyBuilder.createTopology()); // 提交拓扑到集群
} else {
// 本地模式运行
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-print-topology", config, topologyBuilder.createTopology()); // 在本地运行拓扑
}
}
}
运行Topology
运行Topology的方式分为本地模式和集群模式。
在本地模式下运行Topology指的是在开发环境中以单机模式运行Storm拓扑。在本地模式下,拓扑会在本地的一个进程中运行,适用于开发和调试拓扑的阶段。本地模式下,无需搭建Storm集群,可以更快地进行代码的迭代和调试。拓扑以单线程的方式执行,并发度由开发者根据需求进行配置。在本地模式下运行Topology通常用于快速验证逻辑、进行单元测试和调优。
而在集群模式下运行Topology是将拓扑提交到Storm集群中进行分布式运行。在集群模式下,拓扑会在多个Worker进程中执行,各个Worker会分布在集群的不同节点上。集群模式下,可以根据实际需求来配置拓扑的并行度,让拓扑在多个节点上并行处理数据,提高处理能力和容错性。通过集群模式,可以实现更高的实时数据处理吞吐量和更强的扩展性。集群模式下运行Topology需要先将代码打包成jar文件,然后提交给Storm集群进行执行。
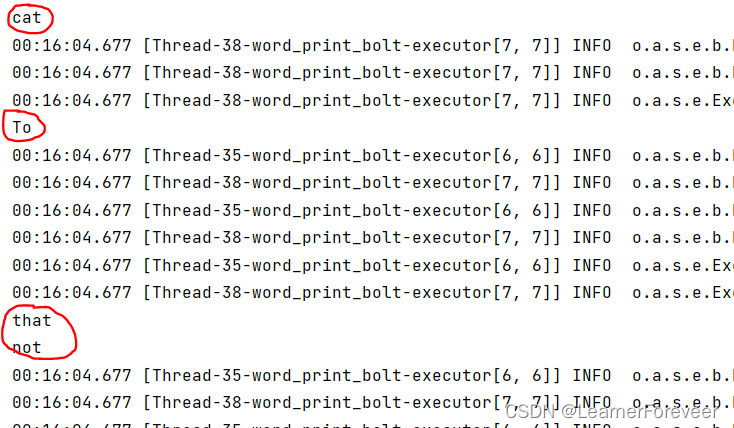
本地模式
本地模式十分简单,只需要在IDEA上本地运行后就可以在控制台中看到输出了:
集群模式
与本地模式运行不同,集群模式运行需要将项目进行打包,并发布到集群中。
首先需要修改项目依赖:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.2.0</version>
<scope>provided</scope>
</dependency>可以看到我们不需要将storm-core打包到项目jar包中,这是因为在Storm集群中已经安装了Storm的运行环境,包括storm-core。当我们将Storm拓扑提交到集群时,Storm集群会自动负责加载和使用storm-core,因此无需将其打包到拓扑项目中。
将jar包复制到nimbus容器中:
docker cp <本机文件> <容器名>:<容器路径>通过上面的命令能够将本地的文件上传到容器中。

将topology提交到集群上并运行:
storm jar <你的jar包> <Topology类的引用位置> <topology的名称>之后topology开始运行,但是需要注意的是这里似乎无法获得println输出的内容。
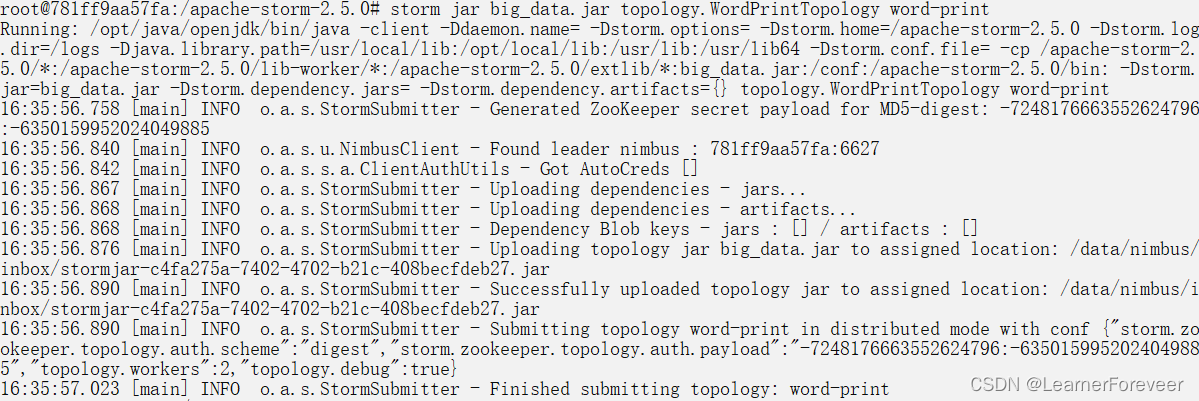
刷新之后可以在UI页面中可以看到我们提交的topology:
之后还可以通过命令kill掉当前正在运行的topology:
storm kill <topology名称或id>
之后我们可以在Storm的worker日志中看到输出的内容:
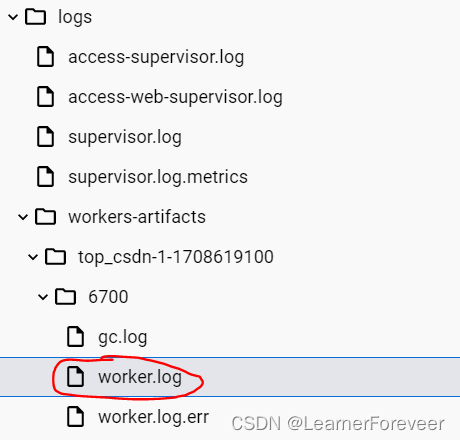
将此文件下载到本地来查看文件中的内容,如果是Docker Desktop的话可以直接右键下载,如果不是的话通过下面的命令下载:
docker cp <容器名称或id>:<容器中的文件位置> <保存的本地位置>
在这个文件中可以找到输出的内容:

至此,Docker下的Storm结束。
上一篇:Docker下的Kafka
下一篇:Docker下的Flink















 4065
4065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









