







目录
摘要
本周阅读的论文题目是《LSTA: Long Short-Term Attention for Egocentric Action Recognition》(《LSTA:用于自我中心动作识别的长短期注意力机制》)。以自我为中心的活动识别是视频分析中最具挑战性的任务之一,它需要精细地区分小物体及其操作。虽然一些方法基于强大的监督和注意力机制,但它们有些需要消耗大量标注,还有些没有考虑时空模式。在本文中,提出了一种新的循环单元长短期注意力(LSTA),设计了循环注意力和输出池化两个新特性,在跟踪视频序列时关注相关空间部分的特征,能够解决了当输入序列中的判别信息可以空间定位时LSTM的不足。还通过在跨模态融合的双流架构中部署LSTA,通过使用另一种模态来新颖地控制一个模态的偏差参数,大大提升了动作识别的识别性能。
Abstract
This week's paper is titled "LSTA: Long Short-Term Attention for Egocentric Action Recognition." Self-centered activity recognition is one of the most challenging tasks in video analysis, requiring a fine distinction between small objects and their actions. While some methods are based on powerful supervision and attention mechanisms, some of them require a lot of annotation, and some do not take into account spatiotemporal patterns. In this paper, a new recurrent unit Long and Short-Term Attention (LSTA) is proposed, and two new features of cyclic attention and output pooling are designed, which can pay attention to the features of the relevant spatial part when tracking the video sequence, which can solve the shortcomings of LSTM when the discriminant information in the input sequence can be spatially located. In addition, by deploying LSTA in a dual-stream architecture with cross-modal fusion, the deviation parameters of one modality are novelly controlled by using another modality, which greatly improves the recognition performance of action recognition.
1 引言
注意力机制能够引导网络关注与特定识别任务相关的感兴趣区域,以减少了网络搜索空间,避免了从无关图像区域计算特征,从而提高了泛化能力。并且注意力机制已成功应用于自主体动作识别,超越了非注意力替代方案的性能。然而,对将注意力追踪到时空自主体动作识别数据中的尝试仍然非常少。因此,当前模型可能在自主体动作视频中丢失对注意力区域的适当平滑追踪。此外,大多数当前模型基于具有强监督的独立预训练,需要复杂的标注操作。
为了解决这些局限性,本文研究了视频CNN-RNN如何学习关注感兴趣区域以更好地区分动作类别这一更普遍的问题,分析了LSTM在此方面的不足,并推导出长短期注意力机制(LSTA),这是一种新的循环神经网络单元,它通过内置空间注意力和改进的输出门控来增强LSTM。内置的空间注意力使LSTA能够关注感兴趣的特征区域,而改进的输出门控则限制它展示内部记忆的浓缩视图。并且最后结果表明改进循环单元的输出门控是有效的,因为它不仅影响整体预测,还控制递归,负责在序列中平滑且专注地跟踪潜在记忆状态。
LSTA方法利用预先训练用于对象识别的CNN和另一个预先训练的动作识别CNN中编码的先验信息,以自上而下的方式生成空间注意力图。LSTA还使用对运动流的注意力,然后是外观流和运动流的跨模态融合,从而使得两个流在层中更早地交互,以促进它们之间的信息流动。
2 长短期注意力机制(LSTA)
LSTA 通过两个新设计的组件(循环注意力和输出池化)扩展了 LSTM,如下图所示:
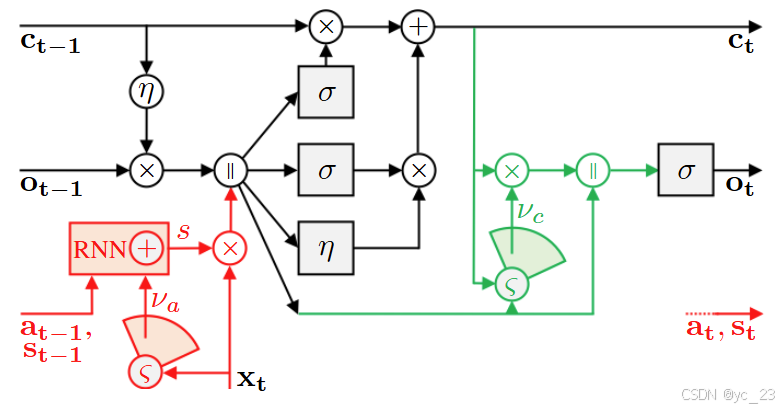
其中,圆圈表示点或连接操作,方块是带有非线性符号的线性/卷积参数节点,加粗的变量表示循环变量:
- 核心操作是一个池化操作
,它从一组中选择一个专门的映射池,用于实现循环注意力跟踪(红色部分)和输出池化门控(绿色部分);
- 循环注意力跟踪:在特征
上进行的池化操作
,该映射通过具有记忆
和输出门
的传统RNN单元,其输出状态
被添加到输入
,然后将图
是用于更新记忆状态
的注意力过滤特征,使用传统的LSTM递归(黑色部分);
- 输出池化门控:使用更新后的记忆状态的一个过滤视图,即
,而不是
,使用
LSTA模型从自视角视频中识别动作以卷积版本的形式实例化如下,分为为注意力池化(1-4)和输出池化(5-8)。
其中:
- 循环变量
形状为
,
形状为
;
- 可训练参数
都是
个卷积核,
形状为
,
形状为
;
分别代表空间位置、特征平面和类别得分空间;
是sigmoid和tanh激活函数;
是卷积,
是逐点乘法;
为池化模型。
下面将分别对注意力池化和输出池化进行学习:
2.1 注意力池化
对于给定一个卷积特征张量 的矩阵视图
,其中
索引
个空间位置之一,
索引
个特征平面之一,动作识别的目标就是抑制与识别任务无关的激活
。也就是说,需要寻求一个形状为
的
,使得参数
可以通过调整使得
成为识别的判别特征。对于以自我为中心的动作识别,这些特征可以来自物体、手或表示操作期间物体-手交互的隐含模式。
的设计基于这样一个假设:对于动作识别任务,存在有限数量的与动作相关的模式类别。然而,每个类别本身在执行过程中和执行之间可以实例化具有高度可变性的模式。因此,就需要
根据当前输入
从类别特定的映射池中进行选择,如果选择器和映射池都是可学习的且自洽的,并且使用更少的可调参数来实现,会大大提高模型的识别性能。
选择器具有参数 ,将图像特征
映射到类别得分空间
,则从该空间中返回得分最高的类别
,选择器形式为
其中 是降维操作,
是用于将
与类别
评分的参数。
如果选择 与降维操作
等变,则有
,就可以使用
作为与
关联的类别特定映射的池,其中
表示
的正交降维,例如如果
是在一个维度上执行最大池化,则
是在其他维度上执行最大池化。也就是说,池化模型由三元组
并且通过特征张量 实现
,当
使用 作为空间平均池化和
作为线性映射。
所以 是一个可微的空间映射,即可以将
作为
的可训练注意力模型,这与用于判别定位的类激活映射有关。然而,又和使用强监督直接训练选择器不同,模型利用视频级注释来隐式学习视频分类的注意力机制。
为了在 LSTA 中增强注意力,引入一个新的状态张量 ,其形状为
,其更新规则是标准的 LSTM:
(公式3)
其输入为:
- 从池化
(公式1)计算的创新
;
- 从
(公式2)计算得到门控
。
再使用隐藏状态 作为残差来计算注意力张量
,然后进行softmax校准:
(公式4)
代码如下:
# 注意力状态解包
a_t_1 = state_att[0]
s_t_1 = state_att[1]
# 公式2
# 注意力循环
# 输入门
i_s = F.sigmoid(self.conv_i_s(s_t_1) + self.conv_i_cam(cam))
# 遗忘门
f_s = F.sigmoid(self.conv_f_s(s_t_1) + self.conv_f_cam(cam))
# 输出门
o_s = F.sigmoid(self.conv_o_s(s_t_1) + self.conv_o_cam(cam))
# 候选注意力特征
a_tilde = F.tanh(self.conv_a_s(s_t_1) + self.conv_a_cam(cam))
# 公式3
# 更新注意力特征
a = (f_s * a_t_1) + (i_s * a_tilde)
# 公式4
# 更新注意力状态
s = o_s * F.tanh(a)
# 注意力特征与CAM结合
u = s + cam # hidden state + cam
# 注意力特征归一化
u = F.softmax(u.view(u.size(0), -1), 1)
u = u.view(u.size(0), 1, 7, 7)
# 应用注意力机制到输入特征
x_att = x * u.expand_as(x)
# 更新状态
state_att = [a, s]2.2 输出池化
如果用输入 代替
分析标准的LSTM公式
得到:
那么,就会很明显地看出输出门控 对
的影响与注意力
对
的影响相同,所以在
(公式5)
中,门控和创新的计算都是基于 ,通过基于这种类比增强了LSTA的输出门控能力,从而增强其记忆跟踪的忘记-更新行为。
通过引入输出门控更新中的注意力池化,而不是通过标准的LSTM公式计算 ,用
替换
,以获得更新公式,即标准门控的
和输出池化:
(公式7)
(公式8)
这样选择不同于注意力池化的更新公式是因为希望保留输出门控的递归性质,即通过将 右连接来获得
形状的张量进行卷积和tanh逐点操作。由于新的记忆状态
在此阶段已经可用,它已经整合了
,就可以用它来左连接而不是原始的注意力池化输入张量。
如果引入第二个注意力池化神经元来定位 的实际判别性记忆组件,即通过
,可以产生一个过滤版本
。由于
通过设计集成了过去记忆更新的信息,因此定位当前激活几乎是必需的。因此,与特征张量
相反,记忆激活可能在空间上没有很好地定位。因此,在输出池化中使用与注意力池化的一个略微不同的版本,移除
以获得一个满秩的
形状的注意力张量
。
为了进一步增强主动记忆定位,使用 来控制注意力池化的偏差项,即
(公式7)
其中,应用一个缩减 ,然后通过具有可学习参数
的线性回归来获得实例特定的偏差
用于激活映射,
是与
相关的缩减。
代码如下:
# 输入状态解包
c_t_1 = F.tanh(state_inp[0])
o_t_1 = state_inp[1]
# 公式5
# LSTM输入门
i_x = F.sigmoid(self.conv_i_c(o_t_1 * c_t_1) + self.conv_i_x(x_att) + x_flow_i)
# LSTM遗忘门
f_x = F.sigmoid(self.conv_f_c(o_t_1 * c_t_1) + self.conv_f_x(x_att) + x_flow_f)
# LSTM候选细胞状态
c_tilde = F.tanh(self.conv_c_c(o_t_1 * c_t_1) + self.conv_c_x(x_att) + x_flow_c)
# 公式6
# 更新细胞状态
c = (f_x * state_inp[0]) + (i_x * c_tilde)
# 公式7、8
# 细胞状态池化和平展
c_vec = self.avgpool(c).view(c.size(0), -1)
# 分类器输出
c_logits = self.c_classifier(c_vec) + self.coupling_fc(self.avgpool(x_att).view(x_att.size(0), -1))
# 分类器输出排序
c_probs, c_idxs = c_logits.sort(1, True)
# 获取最高概率的类别索引
c_class_idx = c_idxs[:, 0]
# 生成类激活图
c_cam = self.c_classifier.weight[c_class_idx].unsqueeze(2).unsqueeze(2) * c
# LSTM输出门
o_x = F.sigmoid(self.conv_o_x(o_t_1 * c_t_1) + self.conv_o_c(c_cam))
# 更新状态
state_inp = [c, o_x]
在两流架构中的跨模态融合也采用了类似的想法。并且这种与 的进一步耦合在LSTA递归中提升了记忆蒸馏,从而显著提高了其跟踪能力。
3 双流架构
与大多数动作识别的深度学习方法类似,LSTA同样遵循双流架构:一条流用于从RGB帧中编码外观信息,另一条流用于从光流堆栈中编码运动信息。划分双流代码如下:
def gen_split_twoStream(root_dir, test_id, stackSize):
trainDatasetX = []
trainDatasetY = []
trainDatasetF = []
testDatasetX = []
testDatasetY = []
testDatasetF = []
trainLabels = []
testLabels = []
trainNumFrames = []
testNumFrames = []
class_names = []
for dir_id in range(4):
dirX = os.path.join(root_dir, 'flow_x/S' + str(dir_id+1))
dirY = os.path.join(root_dir, 'flow_y/S' + str(dir_id+1))
dirF = os.path.join(root_dir, 'frames/S' + str(dir_id+1))
class_id = 0
for target in sorted(os.listdir(dirX)):
if target not in class_names:
class_names.append(target)
dirX1 = os.path.join(dirX, target)
dirY1 = os.path.join(dirY, target)
dirF1 = os.path.join(dirF, target)
for inst in sorted(os.listdir(dirX1)):
inst_dirX = os.path.join(dirX1, inst)
inst_dirY = os.path.join(dirY1, inst)
inst_dirF = os.path.join(dirF1, inst)
numFrames = len(glob.glob1(inst_dirX, '*.jpg'))
if numFrames >= stackSize:
if dir_id+1 == test_id:
testDatasetX.append(inst_dirX)
testDatasetY.append(inst_dirY)
testDatasetF.append(inst_dirF)
testLabels.append(class_id)
testNumFrames.append(numFrames)
else:
trainDatasetX.append(inst_dirX)
trainDatasetY.append(inst_dirY)
trainDatasetF.append(inst_dirF)
trainLabels.append(class_id)
trainNumFrames.append(numFrames)
class_id += 1
return trainDatasetX, trainDatasetY, trainDatasetF, testDatasetX, testDatasetY, testDatasetF, trainLabels, testLabels, trainNumFrames, testNumFrames, class_names通过双流架构结合LSTA模块进行自中心动作识别:
- 外观流注意力
- 使用预训练的ResNet-34中block conv5_3的最后一个卷积层的输出作为LSTA模块的输入,LSTA 记忆深度为512,所有门使用
的核大小;
- LSTA生成用于加权输入特征的注意力图;
- 使用内部状态(
- 两阶段训练:第一阶段训练分类器和LSTA模块;第二阶段训练最终块(conv5_x)中的卷积层和ResNet-34的FC层,以及第一阶段训练的层。
- 使用预训练的ResNet-34中block conv5_3的最后一个卷积层的输出作为LSTA模块的输入,LSTA 记忆深度为512,所有门使用
- 动态流注意力
- 使用在光流堆栈上训练的ResNet-34 CNN网络进行显式运动编码;
- 首先,使用5帧的光流堆栈在动作动词(拿、放、倒、开等)上训练网络,平均了预训练网络的输入卷积层的权重,并将其复制10次以初始化输入层;
- 然后,使用动作预训练的ResNet-34 FC权重作为注意力池化在conv5_3光流特征上的参数初始化,再取视频中时间中心处的五帧对应的光流,使用这个注意力图来加权分类特征。
- 跨模态融合
- 与大多数简单对双流的输出进行后期融合不同,LSTA使用的跨模态融合策略用于网络的前层,以促进两种模态之间信息的流动;
- 每个流都用于控制其他流的偏差:在外观流上执行跨模态融合,将运动流CNN的conv5_3中的流特征应用于LSTA层的门控;在运动流上执行跨模态融合,则将RGB流CNN的conv5_3中的特征序列进行3 卷积,形成一个总结特征,通过在运动流中添加一个512个记忆单元的ConvLSTM单元作为嵌入层,并使用RGB总结特征来控制ConvLSTM门的偏差,从而在神经网络深处形成信息流;
- 然后,对两个单独流输出进行后期平均融合,以获得类别得分。
总结
本文中提出了一种用于第一人称动作识别的方法LSTA,LSTA通过注意力池化、输出池化这两个核心特性扩展了 LSTM。通过注意力池化在空间上过滤输入序列;通过输出池化在每个迭代中揭示记忆的浓缩视图,这两个扩展方法更好帮助LSTA判别特征,从而进行空间定位。并且通过一个具有新颖跨模态融合的双流流CNN-LSTA架构展示了其在自中心动作识别中的实际益处,取得了良好的识别性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









