







目录
2 Graph Convolutional Network(GCN)
摘要
本周阅读的论文题目是《Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition》(《基于骨骼动作识别的时空图卷积网络》)。本文中提出了一种动态骨骼新模型ST-GCN,它通过图卷积网络自动从数据中学习空间和时间模式,适用于不同关节数量和连接情况的数据集,克服了传统的骨骼建模依赖于手工制作的部件或遍历规则方法的局限性。ST-GCN引入分区策略,通过建立多个反应不同运动状态的邻接矩阵,不仅导致更强的表达能力,还增强了泛化能力。此外,ST-GCN可以捕获动态骨架序列中的运动信息,这是对RGB模态的补充。ST-GCN基于骨架模型和基于框架模型的结合进一步提高了动作识别的性能。
Abstract
The paper I read this week is titled "Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition." In this paper, a new dynamic skeletal model, ST-GCN, is proposed, which automatically learns spatial and temporal patterns from data through graph convolutional networks, and is suitable for datasets with different number of joints and connections, overcoming the limitations of traditional skeletal modeling that relies on hand-made parts or traversal rule methods. ST-GCN introduces a partitioning strategy, which not only leads to stronger expression ability, but also enhances generalization ability by establishing multiple adjacency matrices that reflect different motion states. In addition, ST-GCN can capture motion information in dynamic skeleton sequences, which is complementary to RGB modalities. The combination of ST-GCN's skeleton-based model and frame-based model further improves the performance of action recognition.
1 引言
动态骨骼形态可以用人类关节位置的时间序列来表示,以2D或3D坐标的形式。然后,通过分析人类的运动模式,可以识别人类的行为。早期使用骨骼进行动作识别的方法简单地利用单个时间步的关节坐标形成特征向量,并对其进行时间分析,这些方法的能力是有限的,因为它们没有明确地利用关节之间的空间关系,这是理解人类行为的关键。现有的方法大多依赖于手工制作的部件或规则来分析空间模式。因此,针对特定应用设计的模型很难推广到其他应用。
从而,本文设想通过神经网络解决自动问题,为了超越这些限制,我们需要一种新的方法,能够自动捕获嵌入关节空间配置中的模式以及它们的时间动态。然而,骨架是图形形式的,而不是2D或3D网格,这使得使用卷积网络等经过验证的模型变得困难。然而图神经网络能够解决卷积对象非图像问题。图卷积神经网络(GCN)是一种将卷积神经网络(CNN)推广到任意结构图的方法,但需要固定的图作为输入。
由此,本文中提出了一种通过扩展图神经网络到时空图模型,即时空图卷积网络(ST-GCN)来设计用于动作识别的骨架序列的通用表示。如下图所示,为ST-GCN的骨骼序列空间时间图,蓝色点表示身体关节;身体关节之间的体内边(淡蓝色线条)是基于人体中的自然连接定义的;帧间边(淡绿色线条)连接连续帧中相同的关节;关节坐标用作ST-GCN的输入:
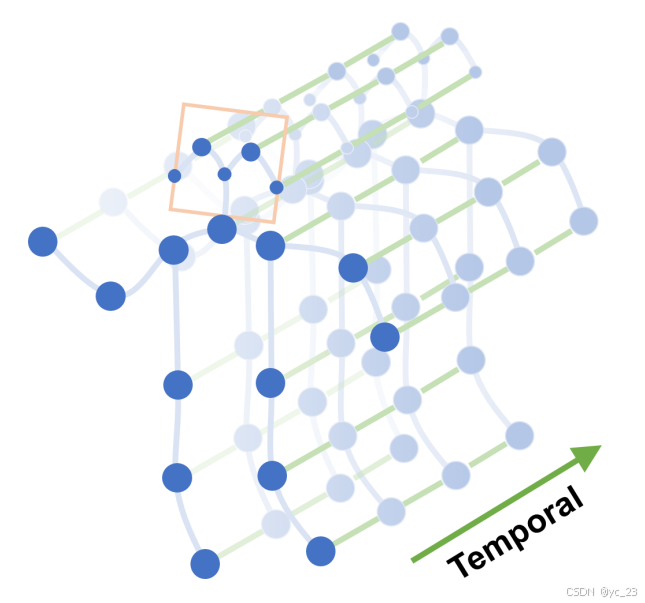
ST-GCN基于一系列骨骼图序列构建,其中每个节点对应人体的一个关节。存在两种类型的边,即符合关节自然连接性的空间边和连接连续时间步中相同关节的时间边。在此基础上构建了多层时空图卷积,允许信息在空间和时间维度上集成。
ST-GCN的层次性质消除了手工指定部分分配或遍历规则的需求。这不仅带来了更强的表达能力以及更高的性能,而且也使得它很容易推广到不同的上下文中。在通用的GCN公式基础上,本文还研究了受图像模型启发的新的设计图卷积核的策略。
2 Graph Convolutional Network(GCN)
图卷积网络(Graph Convolutional Network,GCN)是一类专门用于处理图数据的神经网络模型,它将图的拓扑结构与节点特征结合起来,通过图卷积操作来提取节点之间的关系和特征信息。
2.1 图
图的结构一般来说是十分不规则的,可以认为是无限维的一种数据,所以它没有平移不变性。而传统的CNN、RNN是针对有限的,有平移不变性的,然而,每一个节点的周围结构可能都是独一无二的,这种结构的数据,就让传统的CNN、RNN瞬间失效。
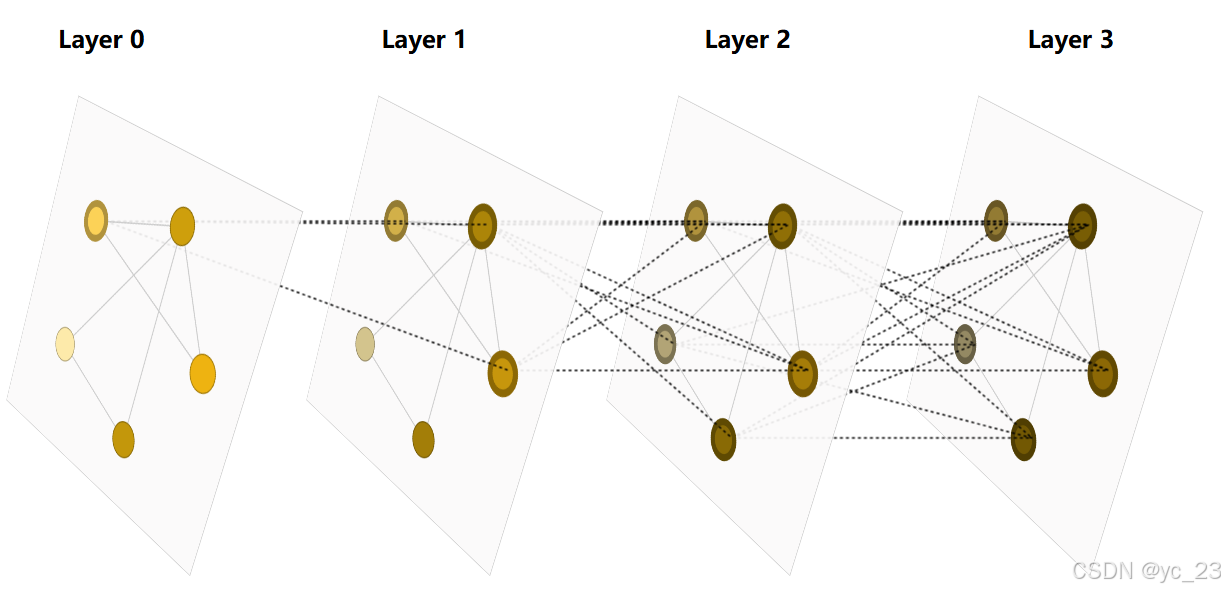
如下图,图通过网络层从周围的节点积累信息,可以看出层数越深,图的感受野也就越大:
图是一种强大的数据结构,用于表示实体(节点)及其之间的关系(边):
- 节点:表示图中的实体,通常用(
) 表示,节点的集合为 (
);
- 边(Edge):表示节点之间的关系,通常用(
)表示,边的集合为(
),边可以是有向的或无向的;
- 邻接矩阵:图的数学表示之一,用(
)表示,(
)表示节点(
) 和(
) 之间有边,反之为 0(对于加权图,值为权重);
- 特征矩阵:通常用(
)表示,描述每个节点的特征信息,维度为(
),其中(
)是节点数,(
)是特征维度。
2.2 GCN
下图为具有一阶滤波器的多层GCN:
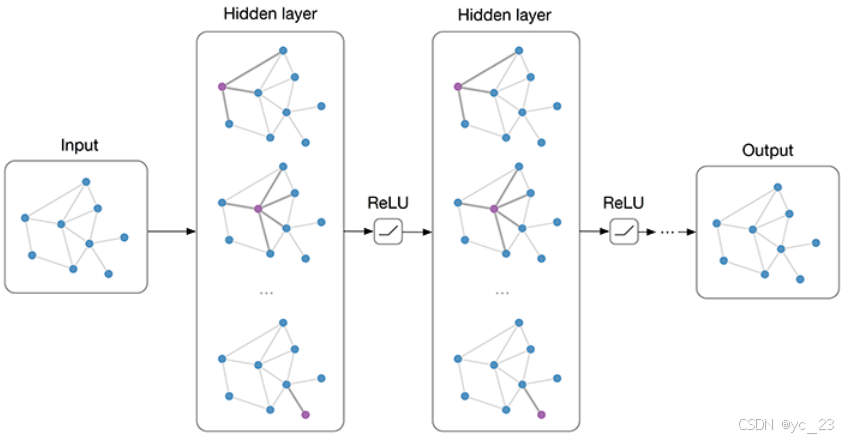
可以看出,与CNN类似,GCN大致为输入层、图卷积层和输出层。
GCN的输入是图数据,包括邻接矩阵(表示节点之间的连接关系)和节点特征矩阵(表示每个节点的特征向量)。
GCN包含多个图卷积层,每一层都对节点特征进行卷积操作。在图卷积层中,每个节点的特征向量与其邻居节点的特征向量进行聚合和组合,包括:
- 聚合邻居特征:通过邻接矩阵将每个节点的邻居节点特征进行聚合,可以使用矩阵乘法实现,即将邻接矩阵与节点特征矩阵相乘;
- 特征变换和更新:对聚合得到的邻居特征进行线性变换,通常使用全连接层(如线性变换)来处理。然后,应用非线性激活函数(如ReLU)对特征进行激活,以增加模型的非线性能力;
- 聚合结果更新:将特征变换后的结果与节点自身的特征进行融合,可以使用加法或连接操作。
这样,每个节点都能够利用自身特征和邻居节点特征的信息。
然后,最后一个图卷积层的输出可以被用于节点分类、图分类或其他图相关任务。对于节点分类问题,通常在输出层使用 softmax 函数将每个节点的特征向量映射为类别概率分布。
图卷积的核心公式是:
其中:
:第
层的节点特征矩阵(输入层(
),即原始特征矩阵);
:加了自环的邻接矩阵,即(
),其中
是单位矩阵;
:
);
:第
:激活函数(例如ReLU)。
则有:
实现了对邻接矩阵的标准化,防止度数不同的节点对结果的影响过大;
表示线性变换,提取特征;
公式代码推理如下:
有邻接矩阵和度矩阵
:
A = np.mat('0,1,1,1,0,0;1,0,1,0,0,0;1,1,0,0,1,1;1,0,0,0,0,0;0,0,1,0,0,1;0,0,1,0,1,0')
print(A)
'''输出如下
[[0 1 1 1 0 0]
[1 0 1 0 0 0]
[1 1 0 0 1 1]
[1 0 0 0 0 0]
[0 0 1 0 0 1]
[0 0 1 0 1 0]]'''
D = np.mat('3,0,0,0,0,0;0,2,0,0,0,0;0,0,4,0,0,0;0,0,0,1,0,0;0,0,0,0,2,0;0,0,0,0,0,2')
print(D)
'''输出如下
[[3 0 0 0 0 0]
[0 2 0 0 0 0]
[0 0 4 0 0 0]
[0 0 0 1 0 0]
[0 0 0 0 2 0]
[0 0 0 0 0 2]]'''根据,可以使用函数numpy.eye(n)得到
和
:
A_tilde = A+np.eye(6)
print(A_tilde)
'''输出如下
[[1. 1. 1. 1. 0. 0.]
[1. 1. 1. 0. 0. 0.]
[1. 1. 1. 0. 1. 1.]
[1. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 1.]
[0. 0. 1. 0. 1. 1.]]'''
D_tilde = D + np.eye(6)
print(D_tilde)
'''输出如下
[[4. 0. 0. 0. 0. 0.]
[0. 3. 0. 0. 0. 0.]
[0. 0. 5. 0. 0. 0.]
[0. 0. 0. 2. 0. 0.]
[0. 0. 0. 0. 3. 0.]
[0. 0. 0. 0. 0. 3.]]'''使用fractional_matrix_power(),计算 :
D_tilde_half_neg = fractional_matrix_power(D_tilde, -0.5)
print(D_tilde_half_neg)
'''输出如下
[[0.5 0. 0. 0. 0. 0. ]
[0. 0.57735027 0. 0. 0. 0. ]
[0. 0. 0.4472136 0. 0. 0. ]
[0. 0. 0. 0.70710678 0. 0. ]
[0. 0. 0. 0. 0.57735027 0. ]
[0. 0. 0. 0. 0. 0.57735027]]'''使用@操作符计算矩阵乘法 :
A_sym = D_tilde_half_neg @ A_tilde @ D_tilde_half_neg # 保证了特征值的归一化 最大特征值始终为1
print(A_sym)
'''输出如下
[[0.25 0.28867513 0.2236068 0.35355339 0. 0. ]
[0.28867513 0.33333333 0.25819889 0. 0. 0. ]
[0.2236068 0.25819889 0.2 0. 0.25819889 0.25819889]
[0.35355339 0. 0. 0.5 0. 0. ]
[0. 0. 0.25819889 0. 0.33333333 0.33333333]
[0. 0. 0.25819889 0. 0.33333333 0.33333333]]'''
V, D = np.linalg.eig(A_sym) # 特征值和特征向量
print(V)
'''输出如下
[ 1.00000000e+00 7.62045627e-01 4.53488936e-01 -1.72151079e-01 -9.33834846e-02 -1.95905871e-33]'''然后乘上 对特征进行归一化处理。
3 ST-GCN
ST-GCN遵循GCN的空间视角流派,通过在空间域上构建CNN滤波器,将每个滤波器的应用限制在每个节点的1个邻居节点。
并且,ST-GCN与之前的基于手工特征的方法和基于深度学习的方法不同,ST-GCN可以通过利用图卷积的局部性和时间动态隐式地学习部分信息。通过消除手动分配部分的需求,该模型更容易设计且更有潜力学习更好的动作表示。
ST-GCN的网络结构如下图所示:

- 数据来源:从运动捕获设备或从视频中的姿势估计算法获得;
- 输入:图形节点上的关节坐标向量,通常数据是一系列的帧,每个帧都会有一组关节坐标,这可以被认为是对基于图像的CNN的模拟,将对输入数据进行多层时空图形卷积运算,并在图形上生成更高级别的要素地图;
- 输出:然后,标准SoftMax分类器将其分类到相应的操作类别;
- 训练方式:整个模型采用端到端的反向传播方式进行训练。
输入数据维度为(N,C,T,V,M):
- N代表视频的数量,通常一个 batch 有 256 个视频;
- C代表关节的特征,通常一个关节包含x、y、acc 等 3 个特征(如果是三维骨骼就是 4 个),x、y为节点关节的位置坐标,acc为置信度;
- T 代表关键帧的数量,一般一个视频有 150 帧;
- V 代表关节的数量,通常一个人标注 18 个关节;
- M代表一帧中的人数,一般选择平均置信度最高的 2 个人。
输入数据(N,C,T,V,M)在输入至ST-GCN网络之前需要进行归一化操作,该归一化是在时间维度上进行的,具体来说,就是归一化某节点在所有T个关键帧的特征值。其具体实现代码如下:
N, C, T, V, M = x.size()
x = x.permute(0, 4, 3, 1, 2).contiguous()
x = x.view(N * M, V * C, T)
x = self.data_bn(x)
x = x.view(N, M, V, C, T)
x = x.permute(0, 1, 3, 4, 2).contiguous()
x = x.view(N * M, C, T, V)3.1 骨架图构建
骨骼序列通常用每帧中每个关节的 2D 或 3D 坐标来表示。本文中利用时空图来形成骨骼序列的层次表示,在具有 个关节和
帧的骨骼序列上构建了一个无向时空图
,该图具有体内和帧间连接。
在此图中,节点集 包含了骨骼序列中的所有关节。作为 ST-GCN 的输入,节点
上的特征向量由坐标向量和第
个关节在帧
上的估计置信度组成。
分两步构建骨架序列上的时空图:
- 根据人体结构的连通性,将一个框架内的关节用边连接起来;
- 将每个关节连接到连续帧中的同一关节。
因此,此设置中的连接是自然定义的,不需要人工来手动配置。这还使网络体系结构能够处理具有不同连接数或连接性的数据集。
边集 由两个子集组成:
- 第一个子集描述了每个帧内的骨架连接,表示为
,其中
是自然连接的人体关节集合;
- 第二个子集包含帧间边,连接连续帧中的相同关节,如
。
因此,对于一个特定关节 ,
中的所有边将表示其随时间变化的轨迹。
3.2 空间图卷积神经网络
对于时间 的单个帧中,将有
个关节节点
,以及骨骼边
:
它们都可以被视为2D网络,卷积运算的输出特侦图也是2D网络。步长设置为1,选择合适的padding,输出特征映射可以具有与输入特征映射相同的大小。
给定一个核大小为 的卷积算子,以及一个具有
个通道的输入特征图
。在空间位置
的单个通道的输出值可以表示为:
其中:
- 采样函数
:
枚举了位置x的邻居节点;在图像卷积的情况下,它也可以表示为
;
- 权重函数
:
提供
维实空间中的权重向量,用于计算具有
无关,因此权重到处都是共享的。
图像域上的标准卷积操作可以看作是将一个大小为 的矩阵(即卷积核)沿着图像平面上的每个像素点进行移动,并分别与该像素点周围的一小块区域做内积运算。
然后,通过将上述公式扩展到输入特征图驻留在空间图 上的情况来定义图上的卷积运算。也就是说:特征图
中的特征映射在图形的每个节点上都有一个向量。
由此,重新定义采样函数 和权重函数
:
- 采样函数
的邻居集
,其中
为
到
,采样函数
可表示为
;
- 权重函数
维的张量来实现,将节点
划分为固定数量的
个子集,其中每个子集都有一个数字标签,从而得到一个映射
,将邻域中的节点映射到它的子集标签,由此权重标签
可以通过索引一个
维张量或
来实现。
然后,重写图卷积公式为:
其中,为了平衡不同子集对输出的贡献,归一化项 等于相应子集的基数。
在时空图中,考虑每个节点不仅具有空间位置信息,还具有时间信息。因此,需要重新定义邻域 ,以包括时间上相邻的节点,即连接连续帧上的相同关节:
其中:
- 每个节点的领域
个单位的所有节点;
- 时间内核大小
控制时间上要包含在邻域图中的范围。
为了在时空图上完成卷积运算,还需要修改标签映射,以适应带时间维度的邻域。由于时间轴是有序的,对于以
为中间位置的空间时间邻域,直接修改标签映射
为:
其中:
是在一个单帧
上节点
的邻接点
的标签映射;
为当前样本节点
在时空图中所处的时间帧数;
是节点
则是当前节点的邻域范围,保证时间距离在
就是将时间距离转换为标签数值,用于在时间维度上对标签进行编码。
3.3 分区策略
考虑到动作识别的特点,ST-GCN引入分区策略,通过建立多个反应不同运动状态(如静止,离心运动和向心运动)的邻接矩阵。下图(a)为输入骨骼序列的示意图,红色节点为本次卷积计算的中心节点,红色虚线内蓝色节点为其采样的相邻节点:
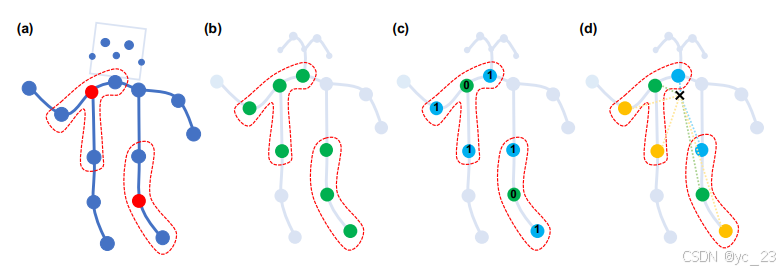
本文中提到了三种不同的分区策略:
- 如图(b),单标签分区策略:邻域中的所有节点具有相同的标签(绿色),即把节点的邻域节点(包括自身)全划为一个子集,有
,但是缺点是邻域节点与同一个权重进行内积,无法计算局部微分属性;
A = np.zeros((1, self.num_node, self.num_node))
A[0] = normalize_adjacency
self.A = A- 如图(c),距离分区策略:两个子集是根节点本身(距离为 0,绿色)和其他相邻点(距离为 1,蓝色),即中心节点为一类,相邻节点(不包括自身)为另一类,有
,
;
A = np.zeros((len(valid_hop), self.num_node, self.num_node))
for i, hop in enumerate(valid_hop):
A[i][self.hop_dis == hop] = normalize_adjacency[self.hop_dis == hop]
self.A = A- 如图(d),空间结构分区策略,也是本文真正采用的方法,这么分配更能表征人体关键点的向心运动与离心运动:节点根据其与骨骼重力中心(黑色十字)的距离相对于根节点(绿色)进行标记;向心节点距离较短(蓝色),而离心节点距离较长(黄色)于根节点,即按照关节点的向心离心关系定义,
表示节点
A = []
for hop in valid_hop:
a_root = np.zeros((self.num_node, self.num_node))
a_close = np.zeros((self.num_node, self.num_node))
a_further = np.zeros((self.num_node, self.num_node))
for i in range(self.num_node):
for j in range(self.num_node):
if self.hop_dis[j, i] == hop:
if self.hop_dis[j, self.center] == self.hop_dis[
i, self.center]:
a_root[j, i] = normalize_adjacency[j, i]
elif self.hop_dis[j, self.
center] > self.hop_dis[i, self.
center]:
a_close[j, i] = normalize_adjacency[j, i]
else:
a_further[j, i] = normalize_adjacency[j, i]
if hop == 0:
A.append(a_root)
else:
A.append(a_root + a_close)
A.append(a_further)
A = np.stack(A)
self.A = A在动作的过程中,一个关节可能会在身体的多个部位出现。而且,在不同部位的动力学建模中,这些关节外观的重要性是不同的。所以,ST-GCN在时空图卷积的每一层上都加上一个可学习的掩码 ,以提高 ST-GCN 的识别性能。该掩码将根据
中每个时空图边的学习重要性权重缩放节点特征对其相邻节点的贡献。
3.4 实现 ST-GCN
根据第2章的GCN核心公式,单帧内关节的体内连接由表示自连接的邻接矩阵 和单位矩阵
表示。
采用单标签分区策略,则公式表示为:
其中:
;
- 权值矩阵
由多个输出通道的权值向量叠加形成。
采用多个子集的分区策略,即距离分区和空间结构分区,由于此时邻接矩阵被分解为几个矩阵,其中 ,有
,
,则有:
其中, ,为了避免
空行,设置
。
同时也可以伴随一个可学习权值矩阵,初始化为全1矩阵,分别用
和
代替上式的
和
,
为两个矩阵之间的元素乘积。
# 初始化Edge重要性加权的参数
if edge_importance_weighting:
self.edge_importance = nn.ParameterList([
nn.Parameter(torch.ones(self.A.size()))
for i in self.st_gcn_networks
])
else:
self.edge_importance = [1] * len(self.st_gcn_networks)代码中采用为:
def _normalize_digraph(self, A): #矩阵归一化,即每个矩阵值÷对应列的节点数
Dl = np.sum(A, 0) # 按列求和,每个节点相连的个数
num_node = A.shape[0] #假设 A.shape的值是 (3, 3),而 A.shape[0] 的值就是 3,表示矩阵 A 有 3 行。
Dn = np.zeros((num_node, num_node))
for i in range(num_node):
if Dl[i] > 0:
Dn[i, i] = Dl[i] ** (-1) # 给对角线赋值,值为当前节点连接节点数的倒数
AD = np.dot(A, Dn) # 修改邻接矩阵。A*Dn
return AD3.5 ST-GCN 网络结构

由上图网络结构可以看出,ST-GCN单元,交替的使用GCN和TCN,对时间和空间维度进行变换:
# N*M(256*2)/C(3)/T(150)/V(18)
Input:[512, 3, 150, 18]
ST-GCN-1:[512, 64, 150, 18]
ST-GCN-2:[512, 64, 150, 18]
ST-GCN-3:[512, 64, 150, 18]
ST-GCN-4:[512, 64, 150, 18]
ST-GCN-5:[512, 128, 75, 18]
ST-GCN-6:[512, 128, 75, 18]
ST-GCN-7:[512, 128, 75, 18]
ST-GCN-8:[512, 256, 38, 18]
ST-GCN-9:[512, 256, 38, 18]ST-GCN 模型由9层时空图卷积算子(ST-GCN单元)组成。前三层有64个输出通道,接着三层有128个输出通道,最后三层有256个输出通道,这些层有9个时间内核大小。
GCN具体实现代码如下:
self.conv = nn.Conv2d(
in_channels,
out_channels * kernel_size,
kernel_size=(t_kernel_size, 1),
padding=(t_padding, 0),
stride=(t_stride, 1),
dilation=(t_dilation, 1),
bias=bias)
def forward(self, x, A):
assert A.size(0) == self.kernel_size
x = self.conv(x)
n, kc, t, v = x.size()
x = x.view(n, self.kernel_size, kc//self.kernel_size, t, v)
x = torch.einsum('nkctv,kvw->nctw', (x, A))
return x.contiguous(), A学习时间中关节变化的局部特征,TCN的定义如下:
padding = ((kernel_size[0] - 1) // 2, 0)
self.tcn = nn.Sequential(
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(
out_channels,
out_channels,
(kernel_size[0], 1),
(stride, 1),
padding,
),
nn.BatchNorm2d(out_channels),
nn.Dropout(dropout, inplace=True),
)然后通过不断堆叠ST-GCN从图结构输入中持续提取高级的语义特征,具体如下:
self.st_gcn_networks = nn.ModuleList((
st_gcn(in_channels, 64, kernel_size, 1, residual=False, **kwargs0),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 64, kernel_size, 1, **kwargs),
st_gcn(64, 128, kernel_size, 2, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 128, kernel_size, 1, **kwargs),
st_gcn(128, 256, kernel_size, 2, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
st_gcn(256, 256, kernel_size, 1, **kwargs),
))
# 初始化Edge重要性加权的参数
if edge_importance_weighting:
self.edge_importance = nn.ParameterList([
nn.Parameter(torch.ones(self.A.size()))
for i in self.st_gcn_networks
])
else:
self.edge_importance = [1] * len(self.st_gcn_networks)
# ST-GCN与可学习的权重矩阵不断重复与堆叠
for gcn, importance in zip(self.st_gcn_networks, self.edge_importance):
x, _ = gcn(x, self.A * importance)之后,和一般的分类任务类似,引入了全局平均池化以及全卷积层输出预测分支,如下:
# 全局池化
x = F.avg_pool2d(x, x.size()[2:])
x = x.view(N, M, -1, 1, 1).mean(dim=1)
# 预测
x = self.fcn(x)
x = x.view(x.size(0), -1)总结
本文提出了一种基于骨架的动作识别新模型,即时空图卷积网络ST-GCN。ST-GCN在骨架序列上构建了一组时空图卷积,具备能够从时空维度提取特征的能力,其在GCN中的表现就是能够同时聚合时空维度的信息。此外,ST-GCN可以捕捉动态骨架序列中的运动信息,并且骨架模型和基于帧的模型的结合进一步提高了动作识别的性能。ST-GCN模型的灵活性也为未来的工作开辟了许多可能的方向,例如如何将场景、物体和交互等上下文信息纳入ST-GCN等。

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









