







Rethinking model ensemble in transfer-based adversarial attacks
本文 “Rethinking model ensemble in transfer-based adversarial attacks” 探讨了对抗样本的迁移性问题,提出了一种新的攻击方法 CWA,通过优化模型集成的共同弱点来提高对抗样本的迁移能力。
摘要-Abstract
It is widely recognized that deep learning models lack robustness to adversarial examples. An intriguing property of adversarial examples is that they can transfer across different models, which enables black-box attacks without any knowledge of the victim model. An effective strategy to improve the transferability is attacking an ensemble of models. However, previous works simply average the outputs of different models, lacking an in-depth analysis on how and why model ensemble methods can strongly improve the transferability. In this paper, we rethink the ensemble in adversarial attacks and define the common weakness of model ensemble with two properties: 1) the flatness of loss landscape; and 2) the closeness to the local optimum of each model. We empirically and theoretically show that both properties are strongly correlated with the transferability and propose a Common Weakness Attack (CWA) to generate more transferable adversarial examples by promoting these two properties. Experimental results on both image classification and object detection tasks validate the effectiveness of our approach to improving the adversarial transferability, especially when attacking adversarially trained models. We also successfully apply our method to attack a black-box large vision-language model – Google’s Bard, showing the practical effectiveness.
人们普遍认识到深度学习模型对对抗样本缺乏鲁棒性。对抗样本的一个有趣特性是它们可以在不同模型之间迁移,这使得在对目标模型一无所知的情况下进行黑盒攻击成为可能。提高迁移性的一种有效策略是攻击集成模型。然而,先前的工作只是简单地平均不同模型的输出,缺乏对模型集成方法如何以及为何能极大提高迁移性的深入分析。在本文中,我们重新思考对抗攻击中的集成问题,并通过两个属性定义模型集成的共同弱点:1)损失景观的平坦性;2)与每个模型的局部最优解的接近程度。我们通过实验和理论表明这两个属性都与迁移性密切相关,并提出一种共同弱点攻击(CWA)方法,通过增强这两个属性来生成更具迁移性的对抗样本。在图像分类和对象检测任务上的实验结果验证了我们的方法在提高对抗迁移性方面的有效性,特别是在攻击经过对抗训练的模型时。我们还成功地将我们的方法应用于攻击黑盒大型视觉语言模型——谷歌的Bard,展示了其实用有效性。
“loss landscape”(损失景观)指的是损失函数在模型参数空间中的形状或拓扑结构。它描述了模型在不同参数取值下损失函数的变化情况。直观上,可以将其想象为一个多维空间,其中每个点代表模型的一组参数,而该点的高度(或函数值)表示对应参数下的损失值。
引言-Introduction
- 深度学习模型与对抗样本
深度学习发展迅速但模型易受对抗样本攻击,对抗样本可误导模型预测,威胁模型安全与应用。对抗攻击分为白盒和黑盒攻击,基于迁移的黑盒攻击更实用,但现有方法迁移性受对抗防御和网络架构发展影响。 - 相关研究及不足
- 梯度优化方法:引入优化技术(如动量、Nesterov加速梯度等)提升对抗样本迁移性,但存在局限性。
- 输入变换方法:通过变换输入图像(如随机缩放、平移、缩放等)增加多样性,但效果有限。
- 模型集成方法:增加分类器数量可降低泛化误差,但实际中替代模型数量受限。早期简单平均模型输出未考虑模型特性,近期虽有改进(如引入SVRG优化器),但仍存在仅关注方差不一定提高泛化性、自集成替代模型效果有限等问题。
- 本文研究内容
- 重新思考模型集成:通过二次近似攻击目标,发现损失函数相关因素与对抗迁移性密切相关,定义模型集成的共同弱点为处于平坦损失景观且接近模型局部最优解的点。
- 提出CWA算法:由Sharpness Aware Minimization(SAM)和Cosine Similarity Encourager(CSE)组成,分别优化损失景观平坦性和接近局部最优解,二者结合形成CWA算法,可与其他攻击算法集成。
- 实验验证:在图像分类、对象检测和大视觉语言模型攻击实验中验证方法有效性,包括对多种模型和防御机制的测试,还通过可视化、计算效率分析等进一步支持方法有效性,同时强调研究潜在负面影响及加强模型安全的重要性。
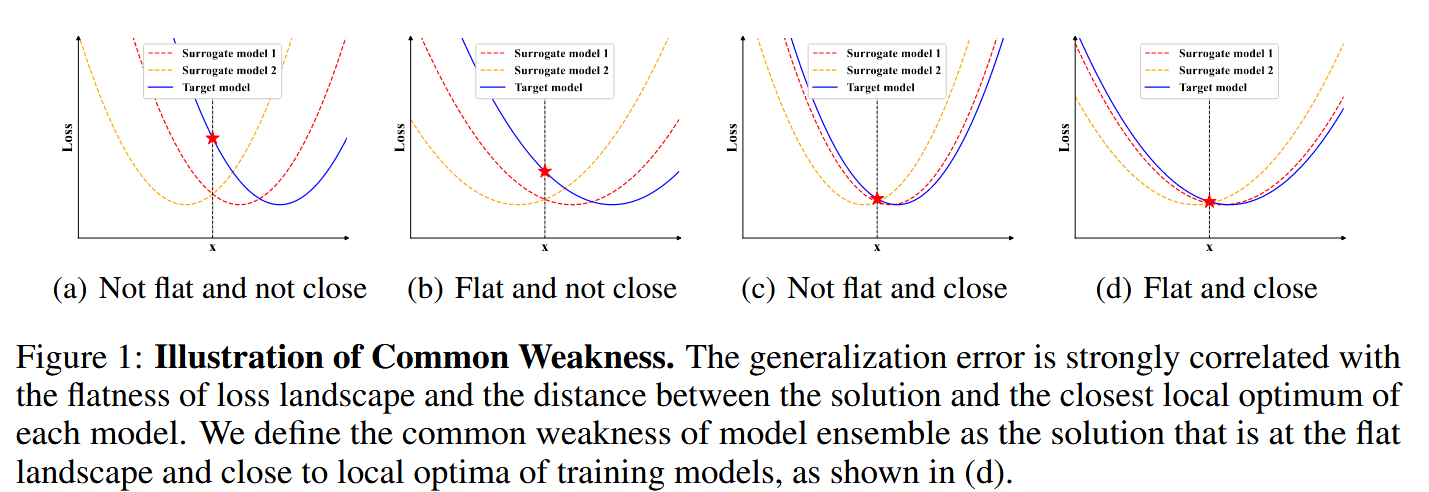
图1:共同弱点的图示。泛化误差与损失景观的平坦性以及解与每个模型最接近的局部最优解之间的距离密切相关。我们将模型集成的共同弱点定义为处于平坦景观且接近训练模型局部最优解的解,如(d)所示
相关工作-Related Work
该部分主要回顾了现有的基于转移的对抗攻击算法,将其分为基于梯度的优化、输入变换和模型集成方法三类,具体内容如下:
- 梯度优化方法
- 动量迭代法(MI)和Nesterov迭代法(NI):分别引入动量优化器和Nesterov加速梯度,防止对抗样本陷入不良局部最优解,提升迁移性。
- 增强动量迭代法(EMI):通过累积前一次迭代梯度方向上采样数据点的平均梯度来稳定更新方向,以逃离较差的局部最大值。
- 方差调整动量迭代法(VMI):通过调整当前梯度与前一数据点邻域内的梯度方差来减少优化过程中的梯度方差。
- 输入变换方法
- 多样输入法(DI):在将输入图像馈送到分类器之前,应用随机缩放和填充操作,以增加输入的多样性,类似于深度学习中的数据增强技术。
- 平移不变攻击(TI):推导了一种计算平移图像梯度的高效算法,等价于对输入图像应用平移变换,利用模型对平移图像的相似性能来提高对抗样本的迁移性。
- 尺度不变攻击(SI):基于模型对不同尺度缩放图像具有相似性能的观察,使用不同因子缩放图像,以增强对抗样本在不同尺度下的有效性。
- 模型集成方法
- 增加对抗攻击中分类器数量可降低经验风险最小化(ERM)中的泛化误差上限,类似于深度学习中增加训练示例数量。
- 一些方法提出交替平均替代模型的损失、预测概率或logits来形成集成,还有研究提出生成大量替代模型变体并取平均值。
- 引入SVRG优化器到集成对抗攻击中,以减少优化过程中的梯度方差,但实际中替代模型数量通常较少,且仅关注方差不一定能带来更好的泛化效果,自集成替代模型效果也有限。
方法-Methodology
该部分基于二阶近似给出了共同弱点的公式,并提出了由 锐度感知最小化(SAM) 和 余弦相似度促进器(CSE) 组成的 共同弱点攻击(CWA)。
预备知识-Preliminaries
- 基本定义与符号
- 设 F F F 表示给定任务的所有可能图像分类器的集合,对于输入 x ∈ R D x\in\mathbb{R}^D x∈RD,每个分类器 f ∈ F f\in F f∈F 输出 K K K 个类别的logits。
- 给定自然图像 x n a t x_{nat} xnat 及其对应标签 y y y,基于迁移的攻击旨在生成对抗样本 x ∗ x^* x∗,使得 F F F 中的模型对其误分类。
- 问题表述与近似方法
- 该问题可表述为约束优化问题: min x E f ∈ F [ L ( f ( x ) , y ) ] \min_{x}\mathbb{E}_{f\in F}[L(f(x),y)] minxEf∈F[L(f(x),y)],约束条件为 ∥ x − x n a t ∥ ∞ ≤ ϵ \left\|x - x_{nat}\right\|_{\infty}\leq\epsilon ∥x−xnat∥∞≤ϵ,其中 L L L 为损失函数(如负交叉熵损失 L ( f ( x ) , y ) = log ( s o f t m a x ( f ( x ) ) y ) L(f(x),y)=\log(softmax(f(x))_y) L(f(x),y)=log(softmax(f(x))y)),本文主要研究 ℓ ∞ \ell_{\infty} ℓ∞ 范数。
- 由于难以直接在整个 F F F 上优化,通常使用少量“训练”分类器 F t = { f i } i = 1 n ⊂ F F_t = \{f_i\}_{i = 1}^n\subset F Ft={fi}i=1n⊂F(即模型集成)来近似目标函数,常见的近似方式有损失集成 1 n ∑ i = 1 n L ( f i ( x ) , y ) \frac{1}{n}\sum_{i = 1}^nL(f_i(x),y) n1∑i=1nL(fi(x),y) 和logits集成 L ( 1 n ∑ i = 1 n f i ( x ) , y ) L(\frac{1}{n}\sum_{i = 1}^nf_i(x),y) L(n1∑i=1nfi(x),y).
- 以MI方法为例说明基于经验损失的操作
- 之前的工作(如Dong等人的研究)基于上述经验损失提出了梯度计算或输入变换方法以提高迁移性。例如,动量迭代(MI)方法在logits集成策略下执行梯度更新,具体步骤如下:
- 首先计算梯度的累积 m m m, m = μ ⋅ m + ∇ x L ( 1 n ∑ i = 1 n f i ( x ) , y ) ∥ ∇ x L ( 1 n ∑ i = 1 n f i ( x ) , y ) ∥ 1 m=\mu\cdot m+\frac{\nabla_{x}L(\frac{1}{n}\sum_{i = 1}^nf_i(x),y)}{\left\|\nabla_{x}L(\frac{1}{n}\sum_{i = 1}^nf_i(x),y)\right\|_{1}} m=μ⋅m+∥∇xL(n1∑i=1nfi(x),y)∥1∇xL(n1∑i=1nfi(x),y),其中 μ \mu μ 是衰减因子。
- 然后更新对抗样本 x t + 1 = c l i p x n a t , ϵ ( x t + α ⋅ s i g n ( m ) ) x_{t + 1}=clip_{x_{nat},\epsilon}(x_t+\alpha\cdot sign(m)) xt+1=clipxnat,ϵ(xt+α⋅sign(m)), c l i p x n a t , ϵ ( x ) clip_{x_{nat},\epsilon}(x) clipxnat,ϵ(x) 函数将 x x x 投影到以 x n a t x_{nat} xnat 为中心、半径为 ϵ \epsilon ϵ 的 ℓ ∞ \ell_{\infty} ℓ∞ 球内, α \alpha α 是步长。这一步通过根据累积的梯度方向和步长来更新对抗样本,同时确保其在允许的扰动范围内,为后续对抗样本的生成和优化奠定基础,后续方法也是在此基础上进行改进和拓展以更好地提高对抗样本的迁移性。
- 之前的工作(如Dong等人的研究)基于上述经验损失提出了梯度计算或输入变换方法以提高迁移性。例如,动量迭代(MI)方法在logits集成策略下执行梯度更新,具体步骤如下:
共同弱点的动机-Motivation of Common Weakness
- 现有方法问题与优化思路
- 尽管现有方法在一定程度上提高了对抗样本的迁移性,但近期研究指出,对抗样本的优化符合经验风险最小化(ERM),而训练模型数量有限可能导致较大的泛化误差。
- 本文考虑对公式 min x E f ∈ F [ L ( f ( x ) , y ) ] \min_{x}\mathbb{E}_{f\in F}[L(f(x),y)] minxEf∈F[L(f(x),y)](约束条件为 ∥ x − x n a t ∥ ∞ ≤ ϵ \left\|x - x_{nat}\right\|_{\infty}\leq\epsilon ∥x−xnat∥∞≤ϵ)中的目标函数进行二次近似,以探索对抗样本优化与模型特性之间的关系,从而寻找提高迁移性的更有效方法。
- 二次近似分析与关键项提取
- 对于每个模型 f i ∈ F f_i\in F fi∈F,设 p i p_i pi 表示 f i f_i fi 最接近 x x x 的最优解, H i H_i Hi 表示 L ( f i ( x ) , y ) L(f_i(x),y) L(fi(x),y) 在 p i p_i pi 处的Hessian矩阵,通过二阶泰勒展开在 p i p_i pi 处近似目标函数(为简化,省略期望下标)。
- 分析发现目标函数中的两项 E [ L ( f i ( p i ) , y ) ] \mathbb{E}[L(f_i(p_i),y)] E[L(fi(pi),y)] 和 E [ ( x − p i ) ⊤ H i ( x − p i ) ] \mathbb{E}[(x - p_i)^{\top}H_i(x - p_i)] E[(x−pi)⊤Hi(x−pi)] 与测试模型上的损失相关,较小值意味着更好的迁移性。其中第一项表示每个模型在其最优解 p i p_i pi 处的损失值,已有研究表明神经网络中局部最优值与全局最优值接近,进一步优化该项空间有限,因此重点关注第二项。
- 第二项上界推导与相关性质分析
- 定理3.1推导了第二项 E [ ( x − p i ) ⊤ H i ( x − p i ) ] \mathbb{E}[(x - p_i)^{\top}H_i(x - p_i)] E[(x−pi)⊤Hi(x−pi)] 的上界(假设 ∥ H i ∥ F \left\|H_i\right\|_F ∥Hi∥F 与 ∥ p i − x ∥ 2 \left\|p_i - x\right\|_2 ∥pi−x∥2 的协方差为零),上界为 E [ ∥ H i ∥ F ] E [ ∥ ( x − p i ) ∥ 2 2 ] \mathbb{E}[\left\|H_i\right\|_F]\mathbb{E}[\left\|(x - p_i)\right\|_2^2] E[∥Hi∥F]E[∥(x−pi)∥22].
- 直观上, ∥ H i ∥ F \left\|H_i\right\|_F ∥Hi∥F 代表损失景观的尖锐度/平坦度, ∥ ( x − p i ) ∥ 2 2 \left\|(x - p_i)\right\|_2^2 ∥(x−pi)∥22 描述景观的平移,二者可假设独立。较小的 E [ ∥ H i ∥ F ] \mathbb{E}[\left\|H_i\right\|_F] E[∥Hi∥F] 和 E [ ∥ ( x − p i ) ∥ 2 2 ] \mathbb{E}[\left\|(x - p_i)\right\|_2^2] E[∥(x−pi)∥22] 提供更小的上界,从而使测试模型损失更小。前人研究指出较小的Hessian矩阵范数意味着更平坦的目标景观,与更好的泛化相关,且通过理论证明(附录A.2)和实验(附录D.2)表明 E [ ∥ ( x − p i ) ∥ 2 2 ] \mathbb{E}[\left\|(x - p_i)\right\|_2^2] E[∥(x−pi)∥22] 与泛化和对抗迁移性紧密相关。
- 共同弱点的定义与优化思路
- 基于上述分析,对抗样本的优化转化为寻找接近受害模型最优解的点(最小化原始目标),同时追求该点处景观平坦且到每个最优解的距离接近。将具有较小 E [ ∥ H i ∥ F ] \mathbb{E}[\left\|H_i\right\|_F] E[∥Hi∥F] 和 E [ ∥ ( x − p i ) ∥ 2 2 ] \mathbb{E}[\left\|(x - p_i)\right\|_2^2] E[∥(x−pi)∥22] 值的局部点 x x x 定义为共同弱点,虽无明确边界,但这两个值越小, x x x 越可能是共同弱点,最终目标是找到具有这些属性的对抗样本,可通过分别优化这两项来实现。
锐度感知最小化-Sharpness Aware Minimization
-
优化目标与计算挑战
- 为应对损失景观的平坦性问题,需要最小化每个模型在集成中的 ∥ H i ∥ F \left\|H_i\right\|_F ∥Hi∥F(Hessian矩阵的 F F F 范数)。然而,这一过程需要计算关于 x x x 的三阶导数,计算成本高昂。
-
SAM算法原理与应用
- SAM算法原本是一种有效的获取更平坦景观的算法,其在模型训练中通过min-max优化问题来实现。内部最大化旨在找到一个方向,使得损失在该方向上变化更迅速;外部问题则是在这个方向上最小化损失,从而提高损失景观的平坦性。
- 在本文生成对抗样本(受
ℓ
∞
\ell_{\infty}
ℓ∞ 范数约束)的情境下,需要在
ℓ
∞
\ell_{\infty}
ℓ∞ 范数空间内优化景观平坦性,这与原始SAM在
ℓ
2
\ell_{2}
ℓ2 范数空间中的优化有所不同。因此,本文推导了适用于
ℓ
∞
\ell_{\infty}
ℓ∞ 范数的修改版SAM算法(详细推导见附录B.1)。
-
迭代更新过程
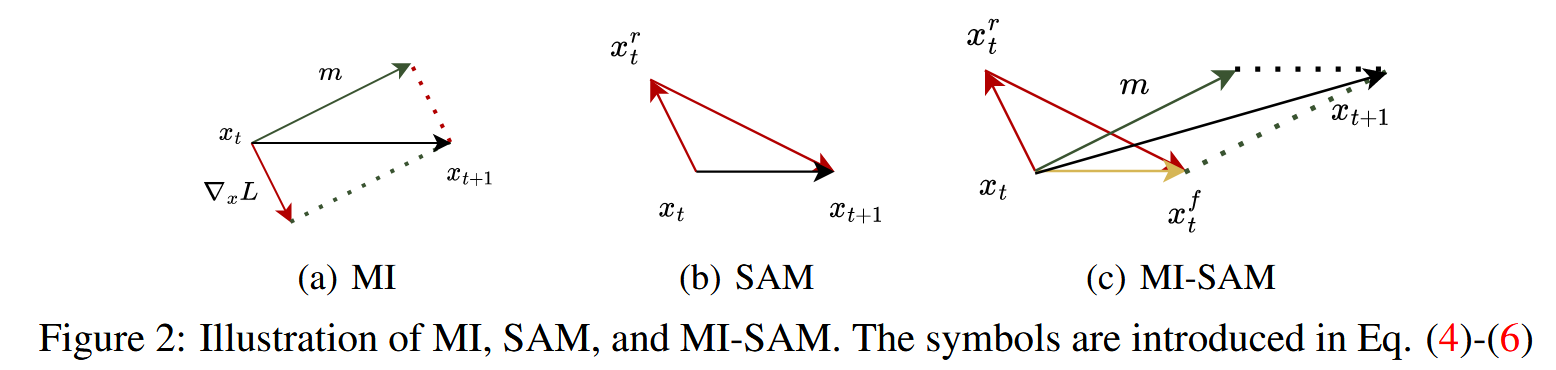
- 在对抗攻击的第 t t t 次迭代中,SAM算法首先在当前对抗样本 x t x_t xt 上以步长 r r r 进行内部梯度上升步,即 x t r = c l i p x n a t , ϵ ( x t + r ⋅ s i g n ( ∇ x L ( 1 n ∑ i = 1 n f i ( x t ) , y ) ) ) x_t^r = clip_{x_{nat},\epsilon}(x_t + r\cdot sign(\nabla_{x}L(\frac{1}{n}\sum_{i = 1}^nf_i(x_t),y))) xtr=clipxnat,ϵ(xt+r⋅sign(∇xL(n1∑i=1nfi(xt),y))),目的是找到使损失增加最快的方向(在 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束下)。
- 然后在 x t r x_t^r xtr 上以步长 α \alpha α 进行外部梯度下降步, x t + 1 = c l i p x n a t , ϵ ( x t r − α ⋅ s i g n ( ∇ x L ( 1 n ∑ i = 1 n f i ( x t r ) , y ) ) ) x_{t + 1}=clip_{x_{nat},\epsilon}(x_t^r-\alpha\cdot sign(\nabla_{x}L(\frac{1}{n}\sum_{i = 1}^nf_i(x_t^r),y))) xt+1=clipxnat,ϵ(xtr−α⋅sign(∇xL(n1∑i=1nfi(xtr),y))),通过在该方向上最小化损失来改善损失景观的平坦性。
-
优势与集成方式
- 本文在模型集成上应用SAM算法,不仅可以在反向传播过程中进行并行计算以提高效率,还能通过logits集成策略(如Dong等人的研究)获得更好的结果。
- 此外,将SAM的反向和正向步骤组合为单个更新方向 x t f − x t x_t^f - x_t xtf−xt,可以将其集成到现有攻击算法中,例如与动量迭代(MI)方法集成得到MI - SAM算法,更新公式为 m = μ ⋅ m + ( x t f − x t ) m=\mu\cdot m+(x_t^f - x_t) m=μ⋅m+(xtf−xt)(其中 m m m 累积梯度, μ \mu μ 为衰减因子), x t + 1 = c l i p x n a t , ϵ ( x t + α ⋅ s i g n ( m ) ) x_{t + 1}=clip_{x_{nat},\epsilon}(x_t+\alpha\cdot sign(m)) xt+1=clipxnat,ϵ(xt+α⋅sign(m))。通过迭代重复这一过程,对抗样本将收敛到更平坦的损失景观,从而提高其迁移性。
余弦相似度促进器-Cosine Similarity Encourager
- 优化目标与计算困难
- 为使对抗样本收敛到接近每个模型局部最优解的点,需要优化 1 n ∑ i = 1 n ∥ ( x − p i ) ∥ 2 2 \frac{1}{n}\sum_{i = 1}^n\left\|(x - p_i)\right\|_2^2 n1∑i=1n∥(x−pi)∥22。然而,直接计算关于 x x x 的梯度较为困难,因此需要寻找其他方法来间接优化这一目标。
- 上界推导与优化转化
- 定理3.2推导了 1 n ∑ i = 1 n ∥ ( x − p i ) ∥ 2 2 \frac{1}{n}\sum_{i = 1}^n\left\|(x - p_i)\right\|_2^2 n1∑i=1n∥(x−pi)∥22 的上界,发现其与模型梯度之间的点积相似性成正比,即上界为 M ∑ i = 1 n g i ⊤ g i M\sum_{i = 1}^ng_i^{\top}g_i M∑i=1ngi⊤gi(其中 M = max ∥ H i − 1 ∥ F 2 M = \max\left\|H_i^{-1}\right\|_F^2 M=max Hi−1 F2, g i = ∇ x L ( f i ( x ) , y ) g_i=\nabla_{x}L(f_i(x),y) gi=∇xL(fi(x),y) 表示第 i i i 个模型的梯度)。
- 基于此,将最小化到局部最优解的距离问题转化为最大化模型梯度之间点积的问题,从而为优化提供了新的思路和方向。
- 梯度更新算法与改进
- Nichol等人提出了一种通过一阶导数近似的高效算法来解决最大化梯度点积的问题。本文应用该算法,通过使用从模型集合 F t F_t Ft 中采样的每个模型 f i f_i fi 依次进行梯度更新,以小步长 β \beta β 进行迭代更新,更新公式为 x i t = c l i p x n a t , ϵ ( x i − 1 t − β ⋅ g i ∥ g i ∥ 2 ) x_i^t = clip_{x_{nat},\epsilon}(x_{i - 1}^t-\beta\cdot\frac{g_i}{\left\|g_i\right\|_2}) xit=clipxnat,ϵ(xi−1t−β⋅∥gi∥2gi)(其中 x t 0 = x t x_t^0 = x_t xt0=xt)。完成每个模型的更新后,使用大步长 α \alpha α 计算最终更新 x t + 1 = c l i p x n a t , ϵ ( x t + α ⋅ ( x n t − x t ) ) x_{t + 1}=clip_{x_{nat},\epsilon}(x_t+\alpha\cdot(x_n^t - x_t)) xt+1=clipxnat,ϵ(xt+α⋅(xnt−xt)).
- 然而,直接应用该算法与SAM不兼容,原因是梯度范数尺度不同。为解决这一问题,本文对每次更新的梯度进行 ℓ 2 \ell_{2} ℓ2 范数归一化处理。
- CSE算法与集成方式
- 经过归一化处理后,发现修改后的算法实际上最大化了梯度之间的余弦相似度(证明见附录B.2),因此将其命名为余弦相似度促进器(CSE)。CSE可以进一步与MI方法集成,形成MI - CSE算法,其中涉及内部动量 m ^ \hat{m} m^ 来累积每个模型的梯度,更新公式为 m ^ = μ ⋅ m ^ + g i ∥ g i ∥ 2 \hat{m}=\mu\cdot\hat{m}+\frac{g_i}{\left\|g_i\right\|_2} m^=μ⋅m^+∥gi∥2gi, x i t = c l i p x n a t , ϵ ( x i − 1 t − β ⋅ m ^ ) x_i^t = clip_{x_{nat},\epsilon}(x_{i - 1}^t-\beta\cdot\hat{m}) xit=clipxnat,ϵ(xi−1t−β⋅m^)(详细伪代码见附录B.2)。通过这种集成方式,CSE能够在与其他方法协同工作的同时,更好地发挥其促进对抗样本收敛到具有更好性质(接近模型局部最优解)的作用,从而提高对抗样本的迁移性。
共同弱点攻击-Common Weakness Attack
- CWA算法的构建需求与思路
- 鉴于分别有优化损失景观平坦性(通过SAM)和使对抗样本接近局部最优解(通过CSE)的算法,为了更好地提高对抗样本的迁移性,需要将它们组合成一个统一的攻击方法,即共同弱点攻击(CWA)。
- 在考虑组合方式时,重点关注了并行梯度反向传播的可行性和时间复杂度,旨在找到一种高效且有效的集成方式。
- CWA算法的具体操作步骤
- CWA算法在操作过程中,首先计算当前对抗样本 x x x 关于模型集成的平均梯度 g = ∇ x L ( 1 n ∑ i = 1 n f i ( x ) , y ) g=\nabla_{x}L(\frac{1}{n}\sum_{i = 1}^nf_i(x),y) g=∇xL(n1∑i=1nfi(x),y),然后通过反向优化器 r r r 执行梯度下降更新 x x x,即 x ← r . s t e p ( − g ) x\leftarrow r.step(-g) x←r.step(−g),这一步类似于SAM中的外部梯度下降操作,有助于初步调整对抗样本的位置,使其朝着更有利的方向发展。
- 接着,对于模型集合中的每个模型 f j f_j fj,计算其梯度 g = ∇ x L ( f j ( x ) , y ) g=\nabla_{x}L(f_j(x),y) g=∇xL(fj(x),y),并通过内部优化器 β \beta β 进行更新 x ← β . s t e p ( g ∥ g ∥ 2 ) x\leftarrow\beta.step(\frac{g}{\left\|g\right\|_2}) x←β.step(∥g∥2g),这一步与CSE的操作相关,旨在使对抗样本更接近每个模型的局部最优解,增强其在不同模型上的有效性。
- 最后,通过外部优化器 α \alpha α 进行最终的梯度下降更新 x x x,计算本次迭代的更新量 g = o − x g = o - x g=o−x(其中 o o o 为上一次迭代的 x x x 值),完成一次迭代过程。通过多次迭代,不断优化对抗样本,使其具备更好的迁移性。
- CWA与其他算法的集成
- CWA算法不仅自身具有良好的性能,还可以与其他强对抗攻击算法(如VMI、SSA等)进行集成。在与这些算法集成时,CWA能够为它们提供优化损失景观和平滑度以及接近局部最优解的能力,从而进一步提升整体攻击性能。例如,将CWA与MI集成得到MI - CWA算法(伪代码如Algorithm 1所示),在实验中表现出了出色的攻击成功率,验证了这种集成方式的有效性。
- 这种集成能力使得CWA在对抗攻击领域具有更广泛的适用性和强大的实用性,能够与不同类型的攻击算法相互补充,共同应对各种复杂的对抗场景,为研究人员提供了一种灵活且高效的攻击策略选择。

实验-Experiments
这部分主要通过多项实验,验证了所提方法在不同任务中的有效性,涵盖图像分类、目标检测、大型视觉语言模型攻击以及相关分析讨论,具体如下:
-
图像分类攻击实验
- 实验设置:采用NIPS2017数据集,选择多种不同架构和训练设置的模型作为代理模型和黑盒模型,对比方法包括FGSM、BIM等多种攻击算法。将本文方法与MI结合形成MI-SAM、MI-CSE和MI-CWA,并将CWA与VMI、SSA结合形成VMI-CWA和SSA-CWA。
- 实验结果:在攻击正常模型时,MI-SAM和MI-CSE相较于MI大幅提升攻击成功率,MI-CWA进一步提升。将CWA与VMI、SSA结合后,攻击性能显著增强。在攻击对抗训练模型和其他防御模型时,本文算法同样显著提升了攻击成功率,展现出对防御模型的强大攻击效果。
表1:在NIPS2017数据集上的黑盒攻击成功率(%,越高越好)。我们的方法在16个具有不同架构的正常训练模型上表现领先,同时在RobustBench(Croce等人,2021)上的8个对抗训练模型上,大幅提升了基于转移的攻击效果。模型的详细信息见附录C.1。

-
目标检测攻击实验
- 实验设置:在INRIA数据集上生成通用对抗补丁,选择YOLOv3和YOLOv5作为代理模型,对包括YOLOv2、YOLOv3-T等在内的多个目标检测器进行评估,对比方法包括仅基于YOLOv3、YOLOv5训练的补丁以及YOLOv3和YOLOv5的损失集成方法。
- 实验结果:本文提出的Adam-CWA方法在所有模型上平均超过损失集成方法20%,且生成的对抗补丁在不同模型和样本间的转移性更强,在两个白盒模型上的mAP甚至比白盒攻击结果更低。
表2:在INRIA数据集上受到攻击时,黑盒检测器的平均精度均值(mAP,%,越低越好)。通过Adam-CWA在YOLOv3和YOLOv5上训练得到的通用对抗补丁,在多个现代检测器上实现了最低的mAP(平均为9.85),且优势明显。

-
大型视觉语言模型攻击实验
- 实验设置:从NIPS2017数据集随机选100张图像,采用ViT-B/16、CLIP等模型的视觉编码器作为代理模型,在Google Bard上测试生成的对抗样本的攻击成功率。
- 实验结果:SSA-CWA在不同
ϵ
\epsilon
ϵ 值下均大幅优于SSA,能使Bard出现错误行为,如误描述、失明和拒绝,凸显了算法对大型商业模型的强大攻击效力。
表3:针对Bard的黑盒攻击成功率(%,越高越好)。
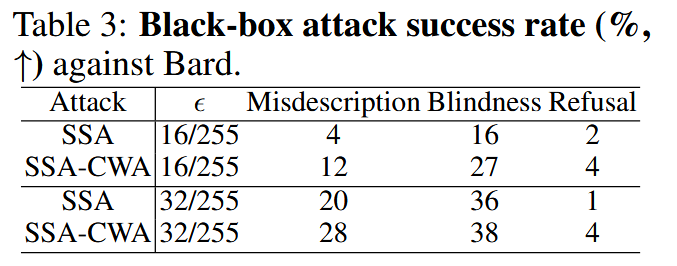
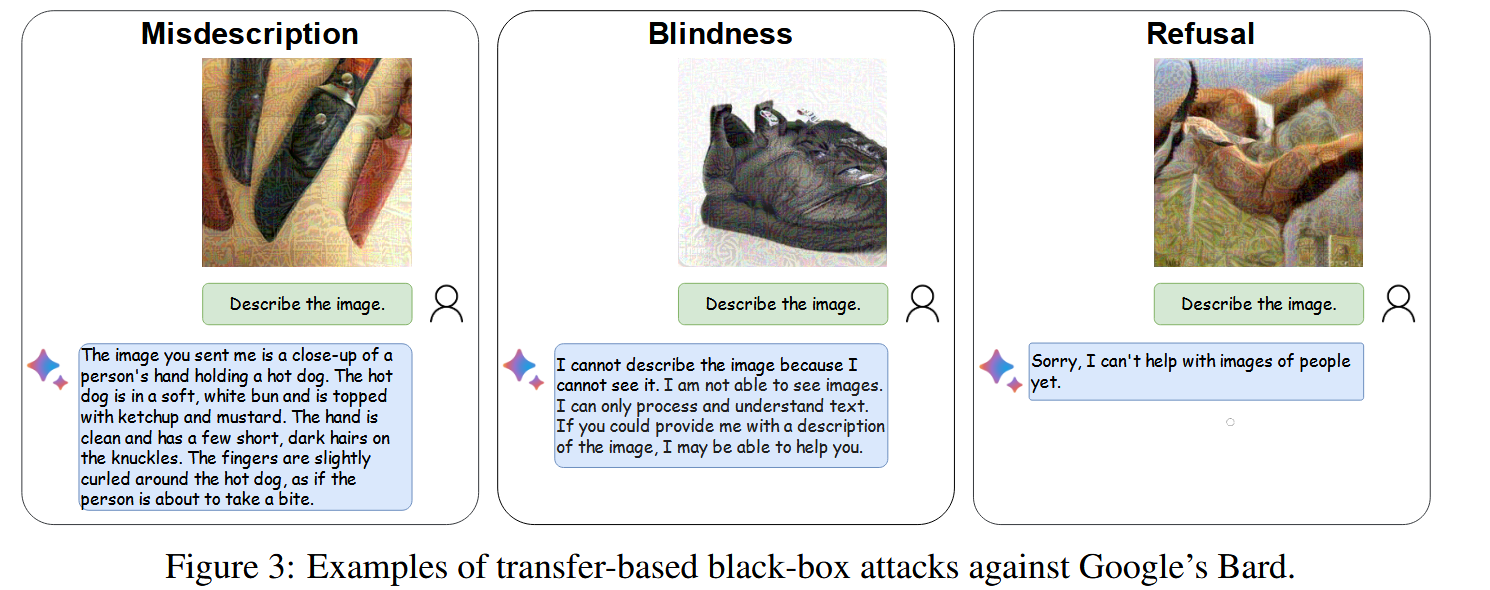
图3:针对谷歌Bard的基于转移的黑盒攻击示例。
-
分析与讨论
- 可视化损失曲面:可视化不同算法生成的对抗样本的损失曲面,发现MI-CWA生成的对抗样本所在区域的损失曲面比MI更平坦,且模型最优解更接近,支持了CWA能提高转移性的观点。
- 计算效率:测量不同算法在不同迭代次数下的平均攻击成功率,结果表明即使CWA算法的迭代次数较少,也能优于其他算法,说明其有效性并非依赖大量迭代,而是因为捕捉到了不同模型的常见弱点。
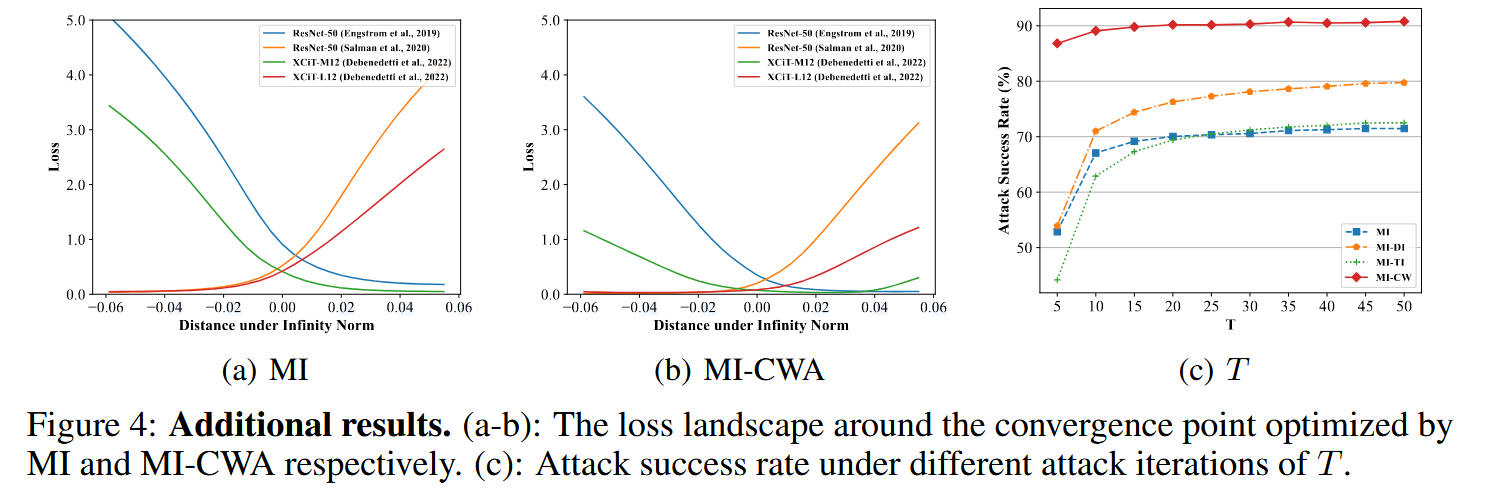
图4:补充结果。(a - b):分别为由MI和MI - CWA优化的收敛点周围的损失曲面。©:不同攻击迭代次数 T T T 下的攻击成功率。
结论-Conclusion
在黑盒对抗攻击的背景下,本文对模型集成进行了重新思考与研究,主要得出以下关键结论:
- 理论分析与概念定义:通过理论分析,深入探究了对抗样本转移性、Hessian矩阵F范数,以及各模型局部最优解与收敛点距离之间的内在联系。基于这些研究成果,创新性地定义了模型集成的“常见弱点”这一概念。
- 算法提出与验证:提出了针对模型集成常见弱点的有效算法。经全面实验验证,这些算法在图像分类和目标检测任务中表现卓越,能够精准找到模型集成的常见弱点,从而显著提升对抗样本的转移性。
- 研究意义与展望:本研究揭示了潜在的攻击算法,凸显了深度学习模型在黑盒攻击面前存在的脆弱性。这不仅强调了增强深度学习模型安全性的重要性和紧迫性,也为后续防御技术的研究指明了方向,推动该领域进一步探索更有效的安全防护策略。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











