







Adversarial Example Soups: Improving Transferability and Stealthiness for Free
本文 “Adversarial Example Soups: Improving Transferability and Stealthiness for Free” 提出 “对抗样本汤” AES,通过平均丢弃的对抗样本(包括最优样本)提升攻击可迁移性和隐蔽性。AES 包含用于超参数调整的 AES-tune 和用于稳定性测试的 AES-rand,在 10 种最先进的攻击方法及组合、10 种不同防御目标模型上进行实验,结果表明 AES 可将攻击成功率提高多达 13%,同时通过减少扰动方差提升了攻击隐蔽性。此外,还探讨了 AES 在集成攻击、现实场景中的应用及局限性,并指出未来可在理论分析、针对性防御设计和跨数据域扩展等方向开展研究。
摘要-Abstract
Abstract—Transferable adversarial examples cause practical security risks since they can mislead a target model without knowing its internal knowledge. A conventional recipe for maximizing transferability is to keep only the optimal adversarial example from all those obtained in the optimization pipeline. In this paper, for the first time, we revisit this convention and demonstrate that those discarded, sub-optimal adversarial examples can be reused to boost transferability. Specifically, we propose “Adversarial Example Soups” (AES), with AES-tune for averaging discarded adversarial examples in hyperparameter tuning and AES-rand for stability testing. In addition, our AES is inspired by “model soups”, which averages weights of multiple fine-tuned models for improved accuracy without increasing inference time. Extensive experiments validate the global effectiveness of our AES, boosting 10 state-of-the-art transfer attacks and their combinations by up to 13% against 10 diverse (defensive) target models. We also show the possibility of generalizing AES to other types, e.g., directly averaging multiple in-the-wild adversarial examples that yield comparable success. A promising byproduct of AES is the improved stealthiness of adversarial examples since the perturbation variances are naturally reduced.
可迁移对抗样本会带来实际的安全风险,因为它们可以在不了解目标模型内部知识的情况下误导目标模型。传统的最大化可迁移性的方法是从优化过程中获得的所有对抗样本中仅保留最优对抗样本。在本文中,我们首次重新审视了这一传统做法,并证明了那些被丢弃的次优对抗样本可以被重新利用,以提高可迁移性。具体来说,我们提出了 “对抗样本汤” AES,其中 AES-tune 用于在超参数调整中平均被丢弃的对抗样本,AES-rand 用于稳定性测试。此外,我们的 AES 受到 “模型汤” 的启发,“模型汤” 通过平均多个微调模型的权重来提高准确率,且不会增加推理时间。大量实验验证了我们的 AES 的整体有效性,在针对10种不同的(防御性)目标模型的攻击中,AES 可将10种最先进的迁移攻击及其组合的成功率提高多达 13%。我们还展示了将 AES 推广到其他类型的可能性,例如,直接平均多个效果相近的实际对抗样本。AES 的一个有前景的副产品是,由于扰动方差自然减小,对抗样本的隐蔽性得到了提高。
引言-Introduction
这部分内容主要介绍了研究背景、提出的方法及主要贡献,具体如下:
- 研究背景:深度神经网络(DNNs)在多个领域取得成功,但容易受到对抗样本的攻击。可迁移对抗样本能在黑盒安全敏感应用中造成严重威胁,目前生成可迁移对抗样本的方法通常是基于梯度的优化问题,现有研究在超参数调整和稳定性测试时,遵循传统优化方法,仅保留最终的最优对抗样本,而丢弃其余样本,这种做法消耗大量计算资源和时间。
- 提出的方法:本文提出 “对抗样本汤”(AES),通过简单平均多个包括最优样本在内的丢弃对抗样本,重新利用这些样本。其中 AES-tune 用于在超参数调整中重用丢弃的样本,AES-rand 用于稳定性测试。AES 受 “模型汤” 启发,在 “模型汤” 中,通过平均多个不同超参数配置微调模型的权重,可提高模型精度且不增加推理时间。在对抗样本场景下,优化对抗扰动类似于优化模型权重,多个对抗样本也可能位于同一误差盆地。
- 主要贡献:首次重新审视优化对抗样本可转移性的传统方法,利用被丢弃的对抗样本免费提升可转移性;提出 AES 方法,并证明其在改进10种最先进的可转移攻击及其组合对10种不同防御目标模型的攻击效果方面的全局有效性;证明 AES 能提高攻击的隐蔽性,并讨论了其他潜在类型的 AES,如通过平均任意攻击生成的、成功率相近的多个实际对抗样本提升可迁移性。
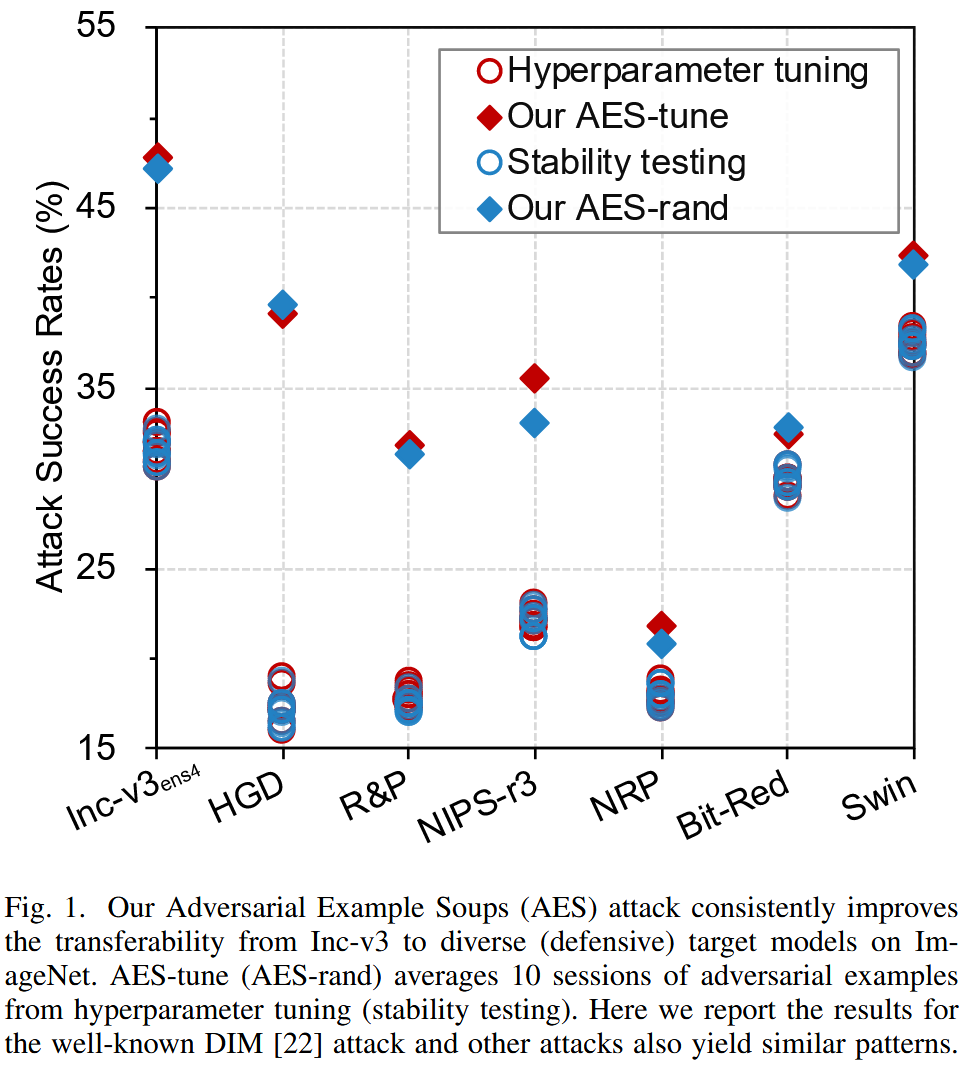
图1. 我们的对抗样本汤(AES)攻击持续提升了从 Inception-v3(Inc-v3)模型到 ImageNet 上多种(防御性)目标模型的对抗样本转移性。AES-tune(AES-rand)对超参数调整(稳定性测试)中10次实验生成的对抗样本进行平均。此处我们报告了著名的 DIM 攻击的结果,其他攻击也呈现出类似的模式。
相关工作-Related Work
这部分内容主要介绍了对抗攻击和对抗防御两个方面的相关工作,具体如下:
- 对抗攻击:为增强对抗样本的可迁移性,已开发出多种方法,可分为六类:
- 梯度稳定攻击:从梯度优化的角度改进对抗攻击,增强攻击过程的收敛效果,典型方法包括在攻击过程中引入动量、Nesterov加速梯度、方差调整和惩罚梯度范数等。
- 输入变换攻击:从数据增强的角度缓解对抗攻击的过拟合问题,进而提高对抗样本的可迁移性,典型方法聚焦于多样化输入、尺度不变性、图像混合和频域变换等。
- 特征破坏攻击:通过操纵主导分类的特征来增强攻击过程,典型方法有特征破坏攻击、特征重要性感知攻击和基于神经元归因的攻击等。
- 模型修改攻击:通过调整代理模型来优化基于迁移的攻击,典型方法包括构建幽灵网络、训练鲁棒性低的代理模型或使代理模型更具贝叶斯特性。
- 生成建模攻击:通过训练生成模型来生成可迁移的对抗样本,典型方法包括生成对抗扰动(GAP)、跨域可转移扰动(CDTP)和注意力多样性攻击(ADA)等。
- 模型集成攻击:借鉴神经网络训练方法,通常结合多个代理模型的输出来显著增强对抗样本的可迁移性,典型方法有随机方差减少集成攻击(SVRE)、自适应集成攻击(AdaEA)和共同弱点攻击(CWA)等。
- 对抗防御:为减轻对抗攻击的威胁,研究人员提出了许多防御方法。其中,对抗训练(AT)方法应用广泛,它通过迭代将对抗样本纳入训练数据,但存在训练成本高的问题,且现有研究普遍认为其对黑盒攻击并非必要。因此,人们探索了更多针对黑盒攻击的高效防御方法,如Tramèr等人采用AT,但仅生成一次性(可转移)对抗样本用于训练;其他防御方法则依赖于输入预处理,如Liao等人利用高级表示引导去噪器(HGD)消除输入图像中的对抗扰动;Xie等人对对抗样本进行随机缩放和填充(R&P)以降低其有效性;Cohen等人提出随机平滑(RS)方法,以获得具有可证明对抗鲁棒性的ImageNet分类器;Naseer等人利用神经表示净化器(NRP)模型净化对抗样本;Xu等人设计了位缩减(Bit-Red)和空间平滑作为对抗对抗样本的防御手段。在本研究中,作者使用上述最先进的防御方法对不同的目标模型评估 AES 的效果。
对抗样本汤-Adversarial Example Soups (AES)
该部分主要介绍了对抗样本汤(AES)的相关理论基础、设计动机、技术细节等内容,具体如下:
-
预备知识:生成对抗样本可转化为约束最大化问题,直接求解复杂。Goodfellow等人提出快速梯度符号法(FGSM),Alexey等人将其扩展为迭代版本I-FGSM,二者是后续迭代攻击方法的基础。现有攻击方法基于此,从不同角度优化,而 AES 关注最终输出。
-
AES的动机:AES 的关键假设是优化过程中得到的多个对抗样本位于同一误差盆地。通过对模型内部特征、损失值和攻击成功率的探索性实验,发现不同对抗样本在这些指标上结果相近,验证了该假设,这与“模型汤”中多个微调模型常处于同一误差盆地的情况一致。
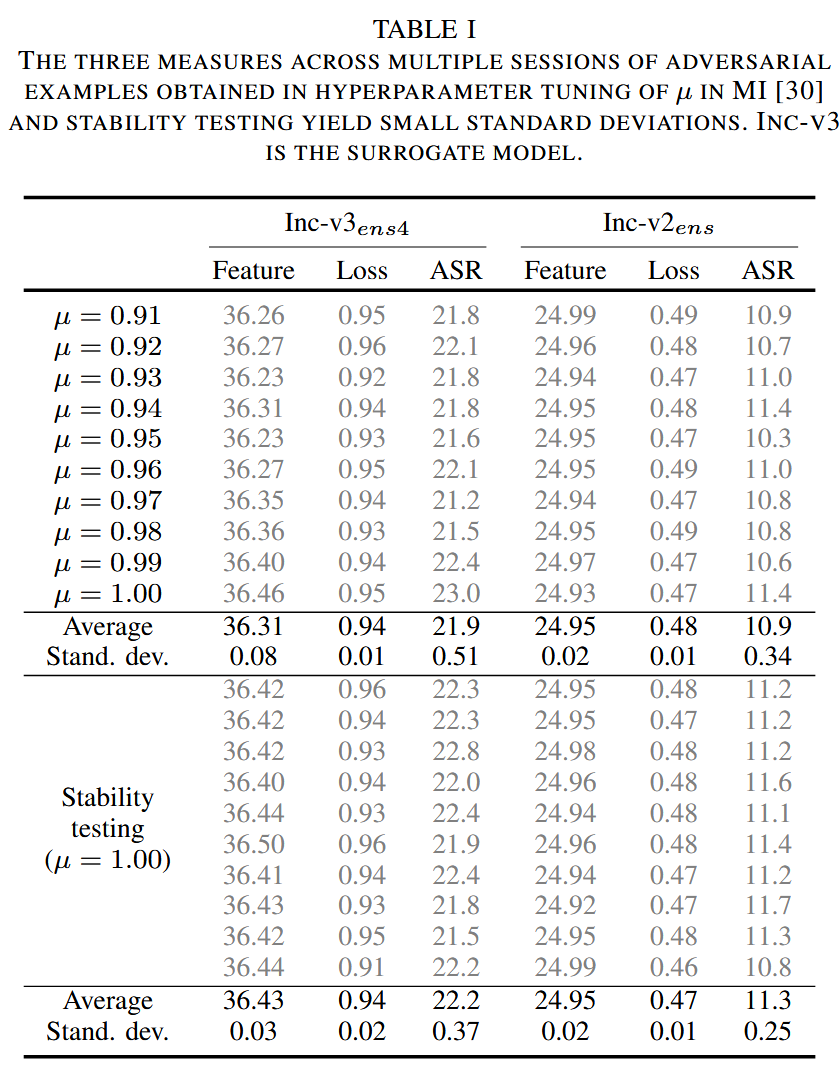
表1. 在对 MI 里的 μ μ μ 进行超参数调整以及稳定性测试时所获得的多个会话的对抗样本的三种度量方法产生较小的标准差。Inception-v3(Inc-v3)是代理模型。
-
AES的技术细节
-
整体思路:AES 对超参数调整或稳定性测试中不同配置或重复实验生成的对抗样本进行平均。设 x i a d v x_{i}^{adv} xiadv 是在超参数设置 h i h_{i} hi 下生成的对抗样本, x a d v = ∑ i = 1 m w i x i a d v x^{adv}=\sum_{i = 1}^{m}w_{i}x_{i}^{adv} xadv=∑i=1mwixiadv( ∑ i = 1 m w i = 1 \sum_{i = 1}^{m}w_{i}=1 ∑i=1mwi=1),探索了均匀、加权和贪婪三种平均策略,主实验采用简单方便的均匀策略。
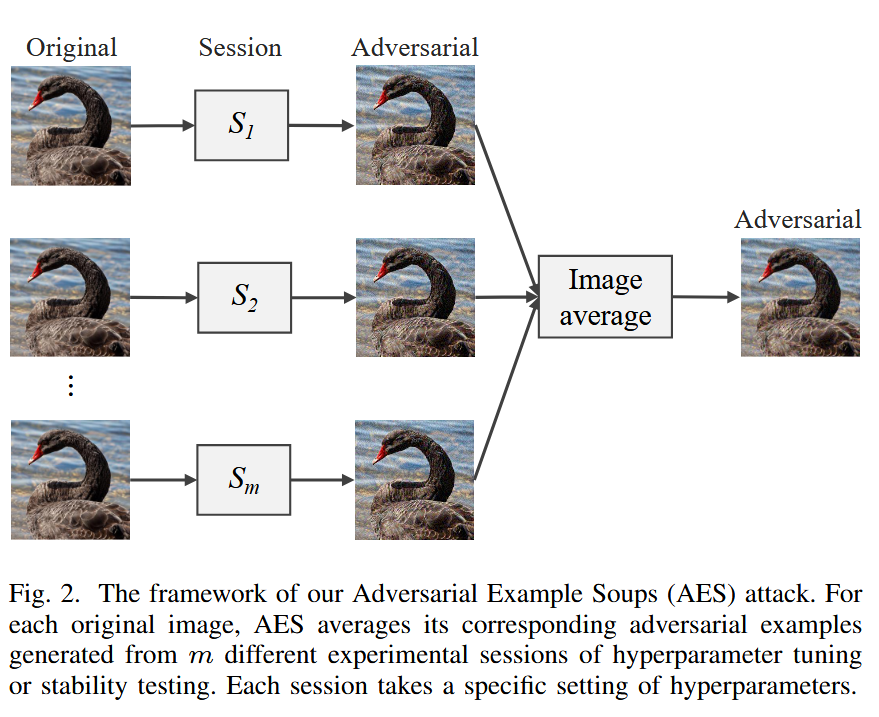
图2. 我们的对抗样本汤(AES)攻击框架。对于每一张原始图像,AES 对从超参数调整或稳定性测试的 m m m 个不同实验会话中生成的相应对抗样本进行平均。每个会话采用特定的超参数设置。
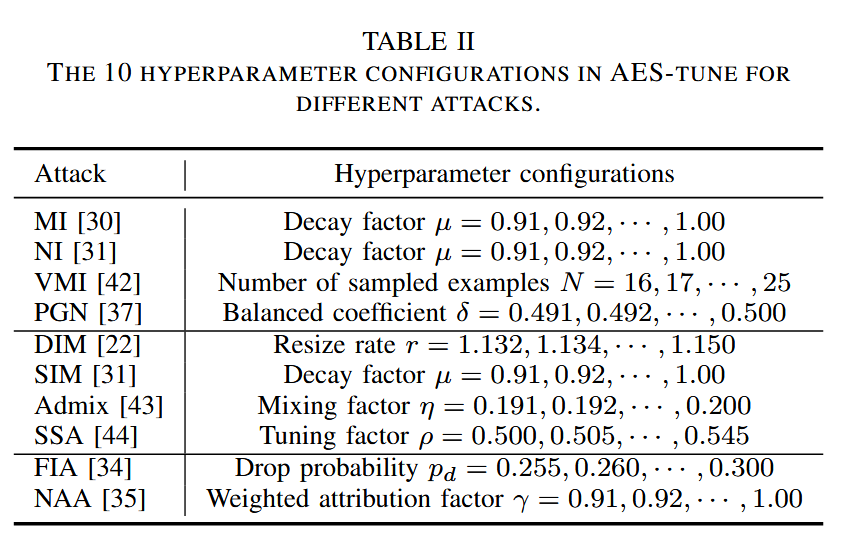
表2. AES-tune 中针对不同攻击的10种超参数配置。
-
AES-tune:在超参数调整时,从预定义范围选择超参数值生成对抗样本,用 AES-tune 平均多个超参数调整会话中的对抗样本,以选择最优攻击迁移性的超参数。
-
AES-rand:在稳定性测试中,为确保新攻击的转移性对优化对抗样本时的潜在随机性不敏感,用 AES-rand 平均多个稳定性测试会话中的对抗样本,随机性来源包括GPU计算、库变化及攻击特定超参数等。
-
其他形式:除 AES-tune 和 AES-rand 外,还可能有其他形式的 AES,如平均已有的实际对抗样本可进一步提升迁移性。
-
实验-Experiments
该部分主要通过一系列实验,验证了对抗样本汤(AES)的有效性,具体内容如下:
-
实验设置
- 数据集和模型:从 ImageNet 验证集中随机选取1000张正确分类的图像。代理模型采用 Inception-v3(Inc-v3)、Inception-v4(Inc-v4)、Inception-Resnet-v2(IncRes-v2)和 Resnet-v2-152(Res-152)。目标模型包括具有不同防御机制或来自不同家族的模型,如对抗训练模型、采用知名防御方法的模型以及 Swin Transformer。
- 基线攻击:选择多种代表性的可转移攻击作为基线,包括梯度稳定攻击(如MI、NI等)、输入变换攻击(如DIM、SIM等)和特征破坏攻击(如 FIA、NAA)。
- 攻击设置:设置最大扰动幅度 ε = 16 \varepsilon = 16 ε=16,迭代次数 T = 10 T = 10 T=10,步长 α = 1.6 \alpha = 1.6 α=1.6,并采用各基线攻击的默认超参数设置。AES 的会话数 m = 10 m = 10 m=10,不同攻击形成 AES-tune 的详细超参数设置在表II中列出。
-
AES提高可迁移性:评估 AES 对梯度稳定、输入变换和特征破坏三类攻击可迁移性的提升效果,考虑单代理模型和代理模型集成两种设置。结果表明,AES 在两种设置下均提高了10种攻击在10个目标模型上的可转移性,集成代理设置下梯度稳定攻击的 AES-tune 提升幅度最高达13.3%。同时发现,AES 对 Swin Transformer 模型的提升相对较小,且 AES-tune 的性能略优于 AES-rand。此外,梯度稳定攻击在单模型设置下的提升最小,可能是因为其超参数调整产生的结果多样性最少。
表3. 有无我们的AES时,梯度稳定攻击的成功率(%)对比。
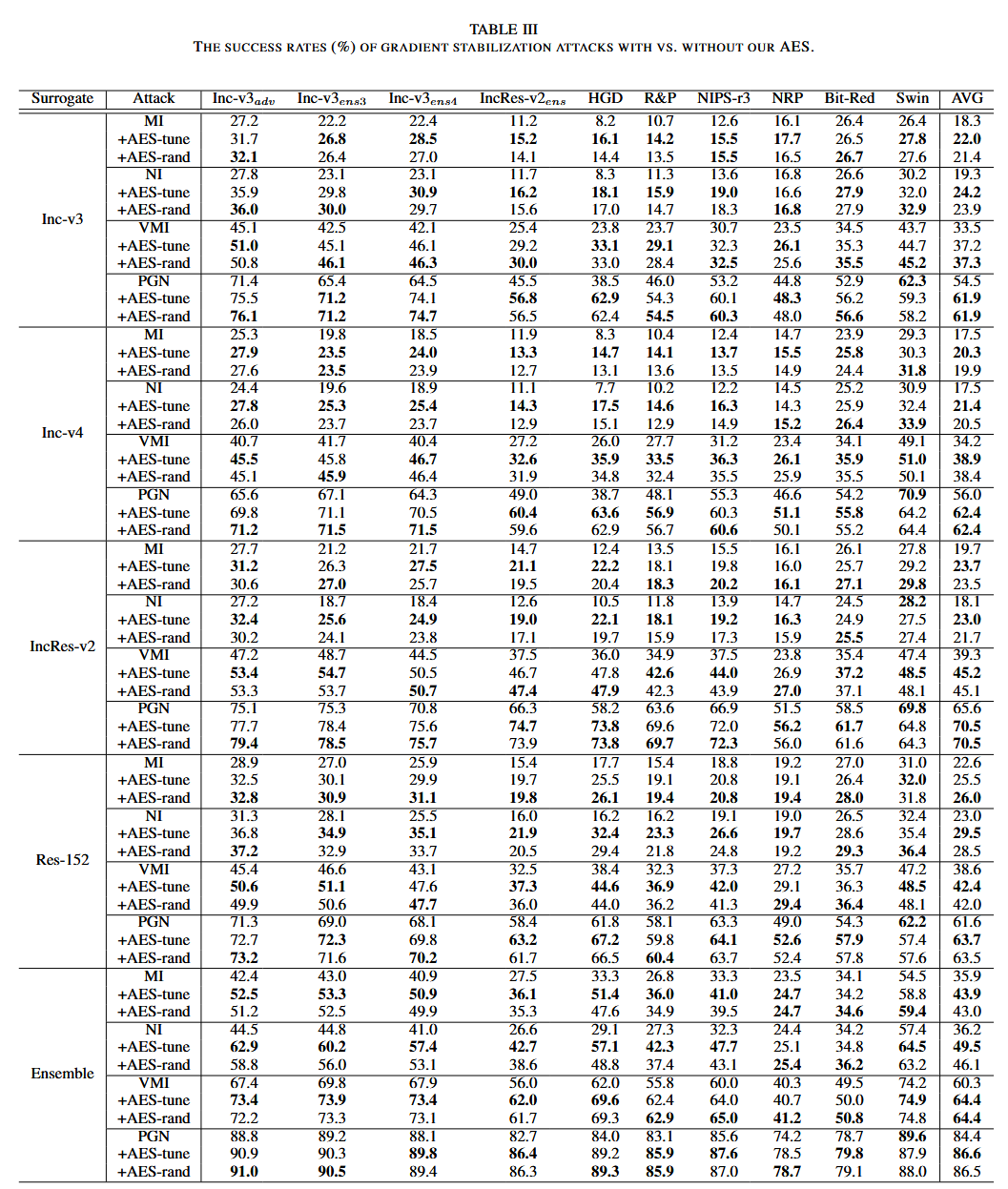
表4. 有无我们的AES时,输入变换攻击的成功率(%)对比。
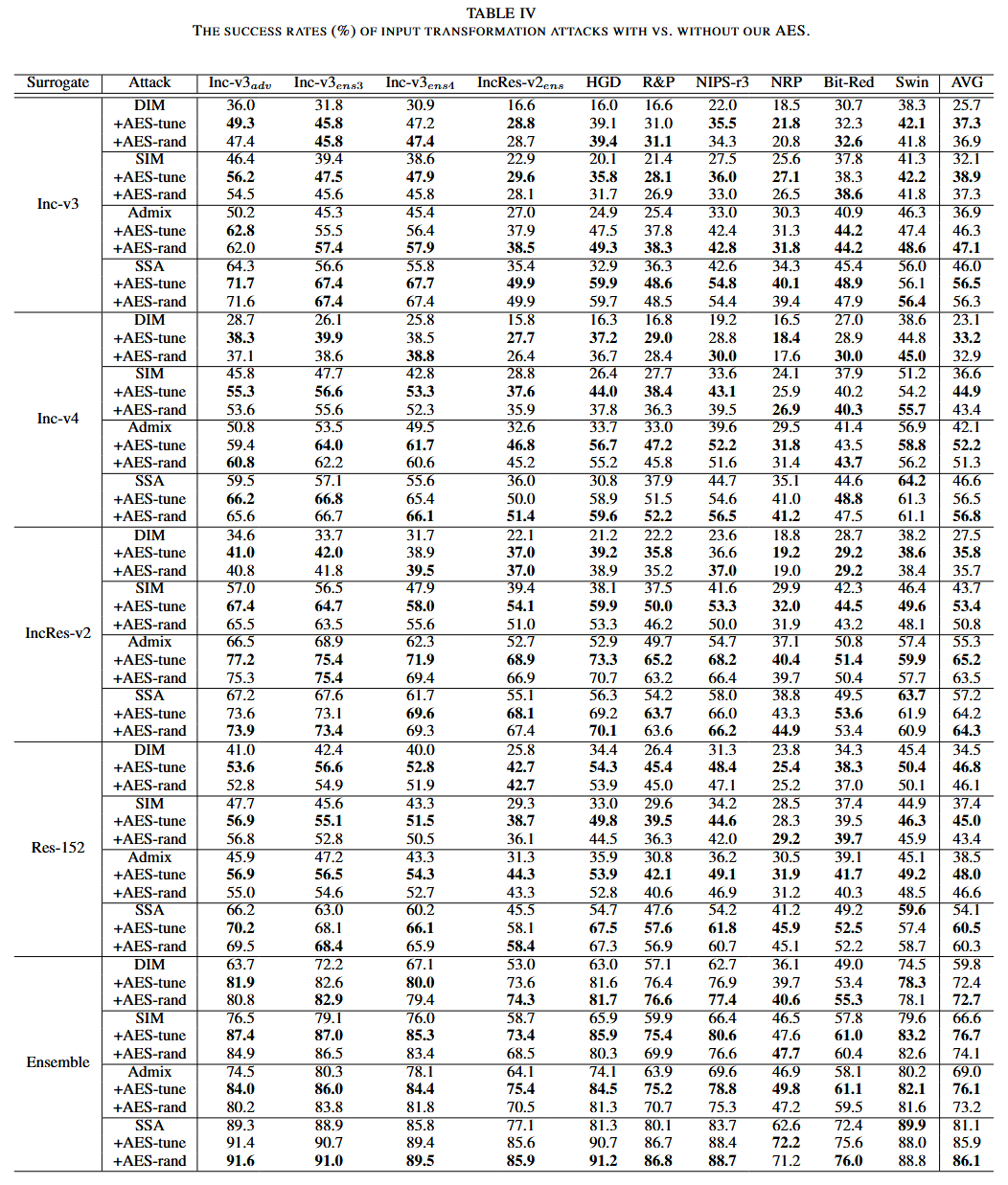
表5. 有无我们的AES时,特征破坏攻击的成功率(%)对比。
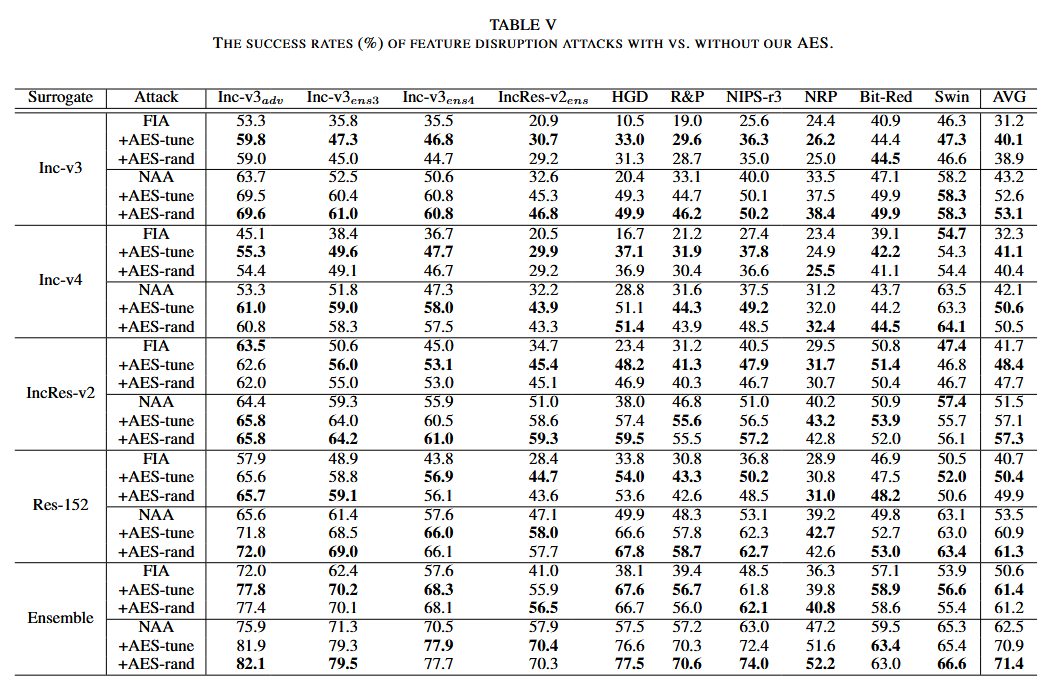
表6. 不同攻击成功率的多样性。梯度稳定攻击的多样性最低,以最低的标准差为代表。此处使用的是基于 Inception-v3(Inc-v3)的 AES-rand。
-
AES提高隐蔽性:AES 对对抗样本求平均,可能减少不稳定的像素扰动,从而提高攻击的隐蔽性。通过峰值信噪比(PSNR)、结构相似性指数测量(SSIM)、学习感知图像块相似性(LPIPS)和弗雷歇初始距离(FID)四种指标评估 AES 生成的对抗图像的视觉质量。结果显示,AES-tune 和 AES-rand 在所有指标上均显著优于基线攻击,表明AES能同时提高可转移性和隐蔽性。
表7. 以Inc-v3为代理模型时,有无我们的AES的不同攻击的隐蔽性对比。
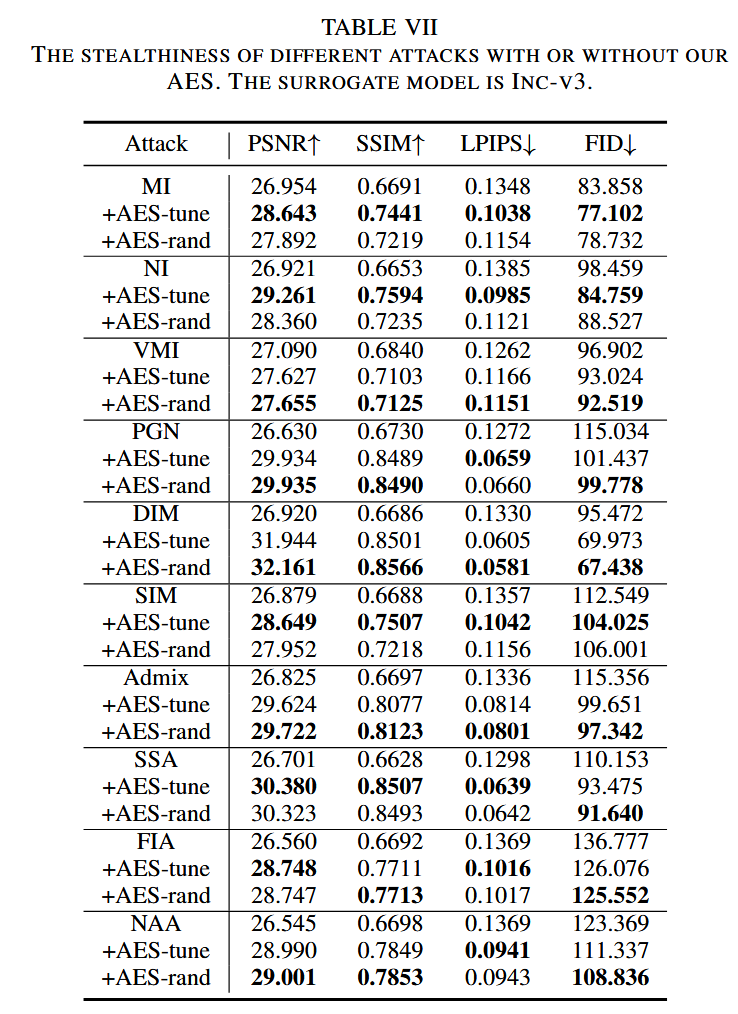

图3. 不同超参数下,由频谱空间攻击(SSA)生成的对抗图像与我们的对抗样本汤(AES)生成的对抗图像的可视化对比。AES生成的图像质量更高。 -
消融研究
- 会话数
m
m
m:以DIM为基线攻击,在 Inc-v3 上生成对抗样本,研究会话数
m
m
m 对AES性能的影响。结果表明,随着
m
m
m 增加,AES-tune 和 AES-rand 的可迁移性逐渐增加,
m
>
10
m > 10
m>10 后趋于饱和。综合考虑可迁移性和计算成本,主实验中设置
m
=
10
m = 10
m=10。
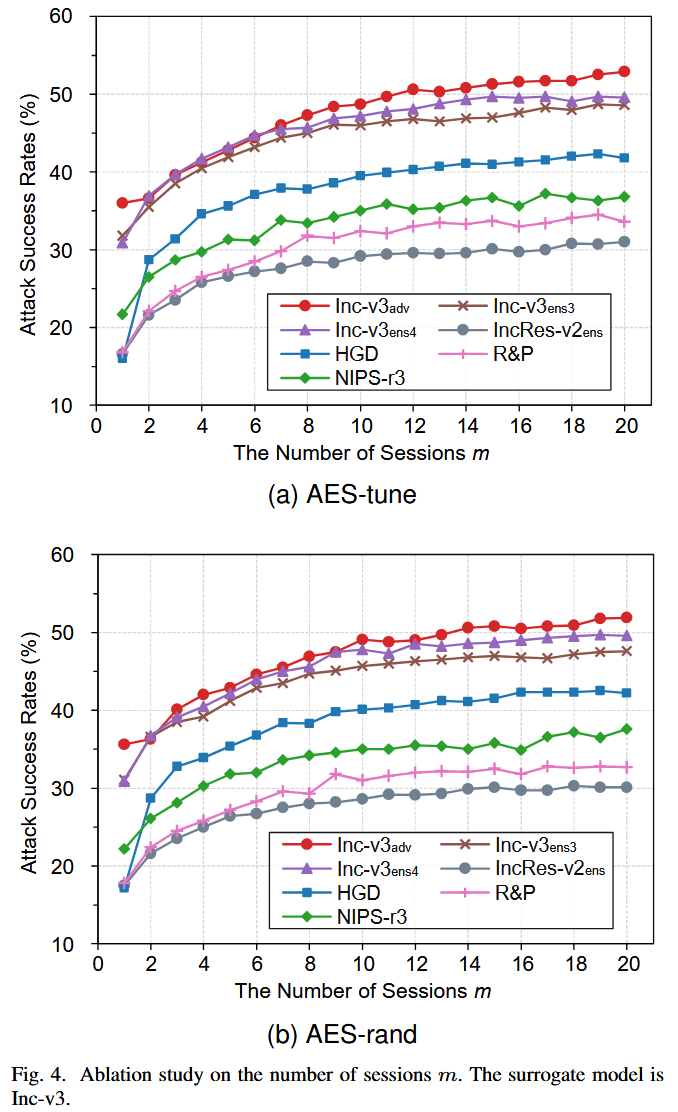
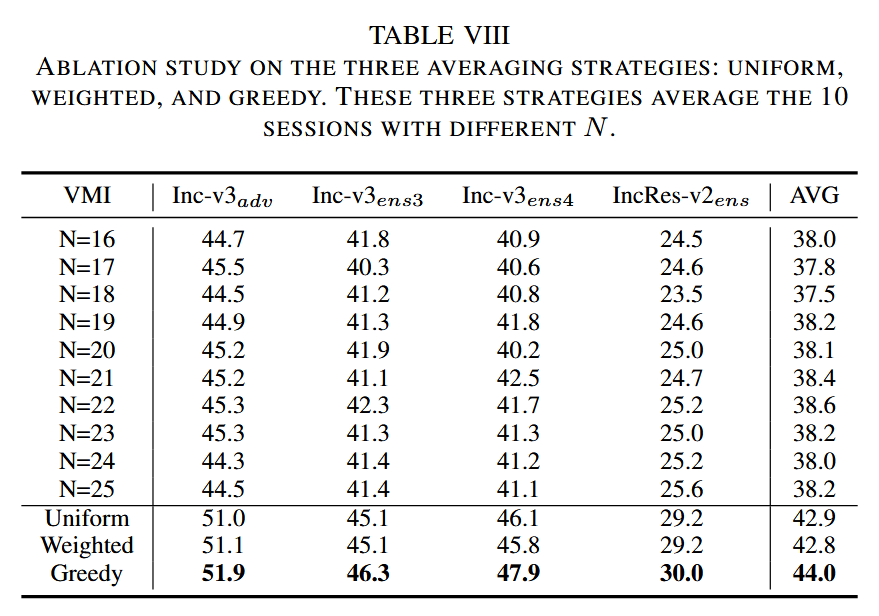
图4. 关于会话数量 m m m 的消融研究。代理模型为Inception-v3(Inc-v3)。 - 平均策略:考虑均匀、加权和贪婪三种平均策略,以 VMI 攻击为例进行实验。结果表明,三种策略均显著提高了可转移性,贪婪策略效果略好,但均匀策略因无需加权分配和样本选择,更为简单高效,因此主实验主要采用均匀策略。
表8. 关于均匀、加权和贪婪这三种平均策略的消融研究。这三种策略对具有不同 N N N 值的10次实验结果进行平均。
- 会话数
m
m
m:以DIM为基线攻击,在 Inc-v3 上生成对抗样本,研究会话数
m
m
m 对AES性能的影响。结果表明,随着
m
m
m 增加,AES-tune 和 AES-rand 的可迁移性逐渐增加,
m
>
10
m > 10
m>10 后趋于饱和。综合考虑可迁移性和计算成本,主实验中设置
m
=
10
m = 10
m=10。
进一步分析与讨论-Further Analysis And Discussion
该部分对AES进行了深入剖析,涵盖有效性解释、在集成攻击和现实场景中的应用,以及对其局限性和更广泛应用的探讨。具体内容如下:
-
解释AES的有效性
- 基于损失平坦度:借鉴模型训练中平均不同超参数配置模型参数可找到更平坦局部最小值以提升泛化性的思路,研究计算了 MI、DIM 和 FIA 三种攻击的损失平坦度。结果显示,AES-tune 和 AES-rand 比基线攻击实现了更平坦的局部最大值,这解释了 AES 具有更好可转移性的原因。
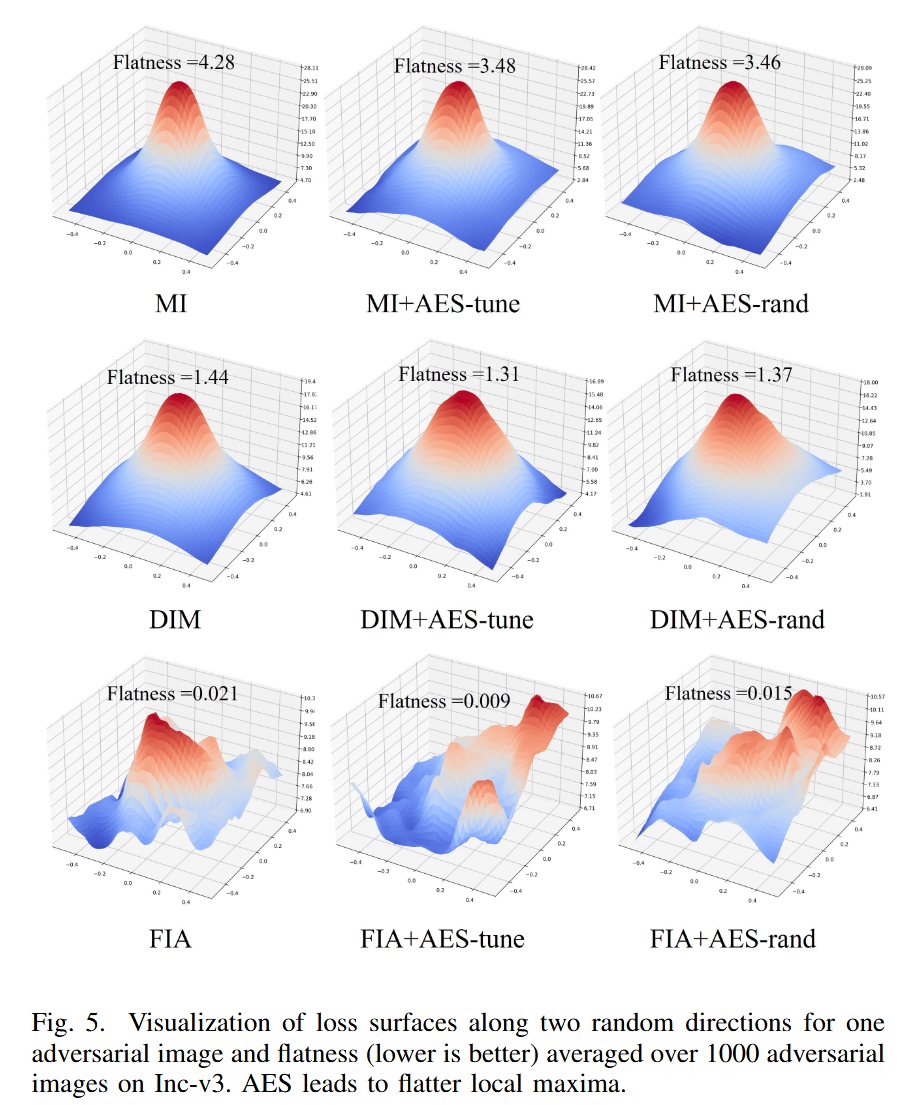
图5. 在 Inc-v3 模型上,沿两个随机方向对一张对抗图像的损失曲面进行可视化,以及对1000张对抗图像的平坦度(越低越好)进行平均。AES 能得到更平坦的局部最大值。 - 基于模型注意力:通过可视化 Res-50 分类器对干净图像和对抗图像的 CAM 注意力图发现,AES 应用后,注意力更集中于中心物体区域,扰动关键语义并消除不稳定扰动,这既解释了 AES 可迁移性提升的原因,也说明了其攻击隐蔽性提高的原因。

图6. 由 Admix 在不同超参数下生成的对抗图像与 AES 生成的对抗图像的 CAM 注意力对比。AES 扰动关键语义区域,这种扰动能够在不同模型间迁移,并且它消除了背景中不必要的扰动。
- 基于损失平坦度:借鉴模型训练中平均不同超参数配置模型参数可找到更平坦局部最小值以提升泛化性的思路,研究计算了 MI、DIM 和 FIA 三种攻击的损失平坦度。结果显示,AES-tune 和 AES-rand 比基线攻击实现了更平坦的局部最大值,这解释了 AES 具有更好可转移性的原因。
-
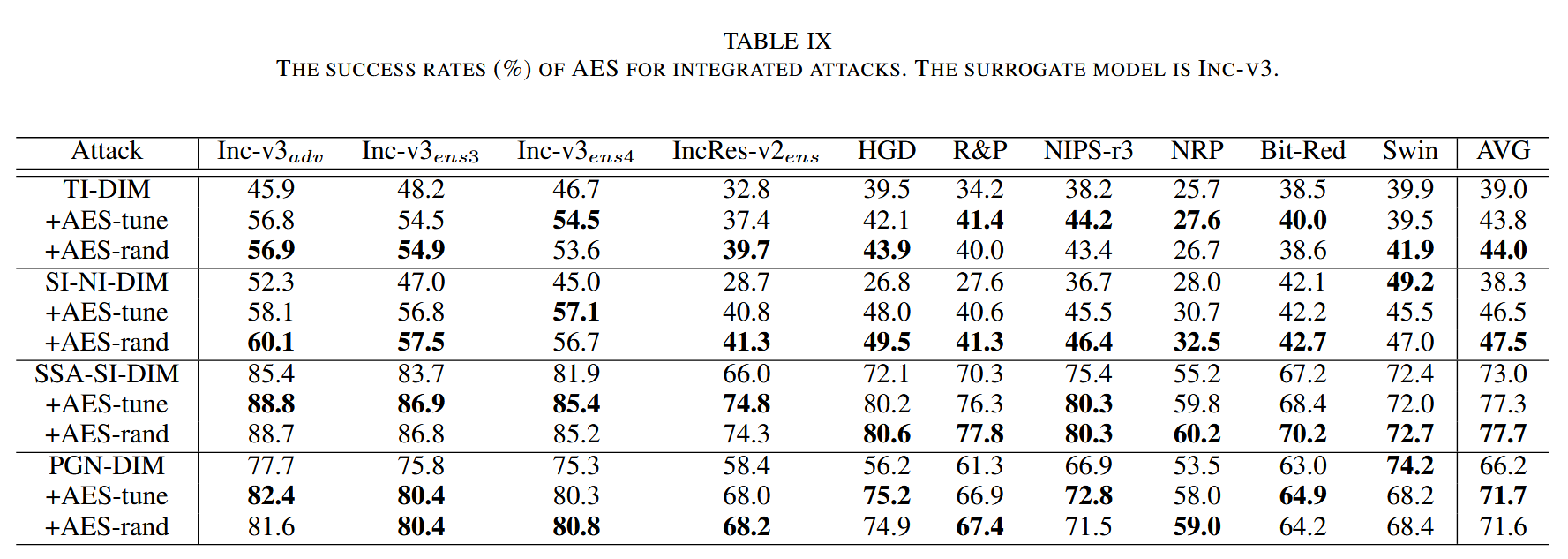
AES用于集成攻击:在实际中,不同类别可转移攻击可集成以提升可转移性。研究在涉及梯度稳定和输入变换两类攻击的集成场景中评估 AES。对于 AES-tune,只调整一种基本攻击的超参数,其余固定;AES-rand 则多次重复优化。结果表明,AES在所有情况下都实现了最高的平均可转移性。
表9. 以Inc - v3为代理模型时,AES在集成攻击中的成功率(%)。
-
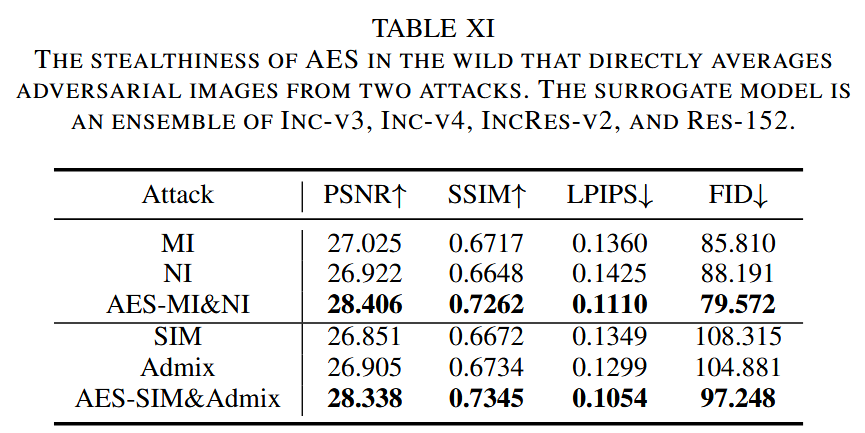
现实场景中的AES:除了攻击优化中的 AES,还存在其他类型的 AES。在现实世界中,可利用公开的攻击源代码和随处可见的对抗图像,直接平均不同攻击产生的对抗样本。实验选取在目标模型上可转移性相似的对抗样本进行平均,结果显示,针对 MI 和 NI 或 SIM 和 Admix 这两对攻击的 AES,能持续提升可转移性和隐蔽性。
表10. 在实际场景中,直接对来自两种攻击的对抗图像进行平均的AES的成功率(%)。代理模型是Inception-v3、Inception-v4、Inception-Resnet-v2和Resnet-v2-152的集成。
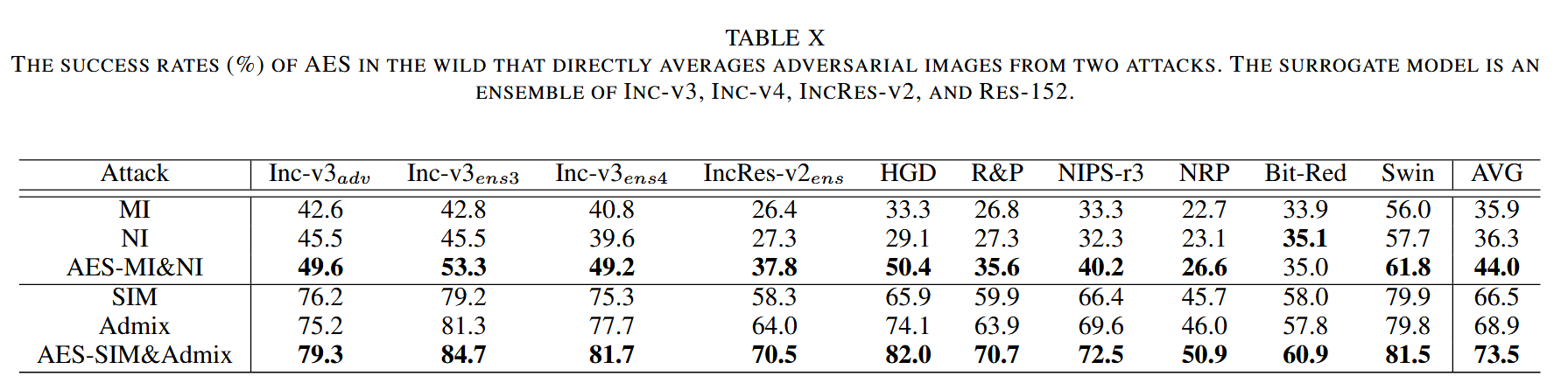
表11. 在实际场景中,直接对来自两种攻击的对抗图像进行平均的AES的隐蔽性。代理模型是 Inception-v3、Inception-v4、Inception-Resnet-v2 和 Resnet-v2-152 的集成。
-
局限性和更广泛的应用
- 局限性:AES与大多数现有对抗可转移性研究一样,缺乏理论分析,未来需进行更深入的理论研究。同时,目前缺少针对AES的特定防御措施,设计专门的防御是未来研究方向之一。
- 更广泛的应用:AES可被视为现有攻击的通用后处理操作,可与其他防御方法结合以获得更好的性能,尽管这可能会增加时间和内存成本。此外,AES范式可扩展到文本和语音等其他数据领域,但文本的离散性可能给确保AES关键假设(多个对抗样本位于同一误差盆地)带来挑战 。
结论-Conclusion
这部分内容主要是对全文研究的核心成果、贡献以及未来研究方向的展望进行总结,具体内容如下:
- 重新审视传统方法:重新审视了优化对抗样本可迁移性的常见做法,指出传统方法在优化过程中直接丢弃对抗样本的问题。以往在超参数调整和稳定性测试时,仅保留最优对抗样本,而忽视了其他样本的价值。
- 提出AES方法及成果:提出“对抗样本汤”(AES)方法,通过重用丢弃的对抗样本来提升可迁移性和隐蔽性。在针对10种最先进的迁移攻击及其组合,以及10种不同的(防御性)目标模型的大量实验中,验证了 AES 的全局有效性。AES 能够将攻击成功率提高多达13%,同时,由于其平均操作自然地降低了扰动方差,使得对抗样本的隐蔽性也得到了提升。
- 讨论AES的其他类型:除了在攻击优化过程中使用 AES(如 AES-tune 和 AES-rand),还探讨了其他类型的 AES。例如,通过平均多个实际场景中效果相近的对抗样本,同样可以提升其可迁移性和隐蔽性,这为AES的应用提供了更广阔的思路。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











