







Boosting the Transferability of Adversarial Samples via Attention
本文 “Boosting the Transferability of Adversarial Samples via Attention” 提出了一种注意力引导的转移攻击(ATA)策略,通过计算模型对提取特征的注意力来规范对抗样本的搜索方向,从而提高对抗样本在不同模型间的可转移性。实验表明,ATA在攻击未防御和防御模型时表现优异,显著提升了BIM的攻击成功率,且生成的对抗样本扰动难以察觉。此外,ATA与其他转移攻击算法兼容,能进一步提高攻击成功率,为评估深度模型的安全性提供了更有效的手段,在黑盒攻击场景下优势明显,对相关研究和模型安全性评估具有重要推动作用。
摘要-Abstract
The widespread deployment of deep models necessitates the assessment of model vulnerability in practice, especially for safety- and security-sensitive domains such as autonomous driving and medical diagnosis. Transfer-based attacks against image classifiers thus elicit mounting interest, where attackers are required to craft adversarial images based on local proxy models without the feedback information from remote target ones. However, under such a challenging but practical setup, the synthesized adversarial samples often achieve limited success due to overfitting to the local model employed. In this work, we propose a novel mechanism to alleviate the overfitting issue. It computes model attention over extracted features to regularize the search of adversarial examples, which prioritizes the corruption of critical features that are likely to be adopted by diverse architectures. Consequently, it can promote the transferability of resultant adversarial instances. Extensive experiments on ImageNet classifiers confirm the effectiveness of our strategy and its superiority to state-of-the-art benchmarks in both white-box and black-box settings.
深度模型的广泛部署使得在实践中评估模型漏洞变得十分必要,特别是在自动驾驶和医疗诊断等对安全性和保密性要求较高的领域。因此,针对图像分类器的基于转移的攻击引起了越来越多的关注,攻击者需要基于本地代理模型制作对抗性图像,而没有来自远程目标模型的反馈信息。然而,在这种具有挑战性但实用的设置下,合成的对抗样本往往由于过度拟合所使用的本地模型而成功率有限。在这项工作中,我们提出了一种新颖的机制来缓解过拟合问题。它通过计算提取特征上的模型注意力来规范对抗样本的搜索,优先破坏不同架构可能采用的关键特征。 因此,它可以提高生成的对抗样本的可转移性。在ImageNet分类器上进行的大量实验证实了我们策略的有效性,以及它在白盒和黑盒设置下相对于最先进基准的优越性。
引言-Introduction
- 研究背景
深度神经网络(DNNs)在诸多领域广泛应用,但易受对抗样本攻击,在自动驾驶、医疗诊断等安全敏感领域,其可靠性备受关注,促使对模型漏洞评估的研究兴起。 - 威胁模型和攻击方式
- 威胁模型:分为白盒和黑盒。白盒中攻击者知晓受害者模型架构与参数;黑盒里攻击者仅能查询目标模型获取输入输出信息。
- 攻击方式:对应威胁模型有白盒攻击(利用模型梯度信息构造恶意实例)和黑盒攻击(又分查询式与迁移式,查询式需大量查询,迁移式用本地模型生成样本攻击远程目标模型)。
- 迁移式黑盒攻击的现状与问题
迁移式黑盒攻击因实际中多只有查询访问权限而受重视,但现有方法合成的对抗样本常过拟合本地模型,虽能高成功率攻击本地模型,对目标模型效果却不佳。 - 本文的发现和贡献
- 发现:不同模型决策前虽特征提取器有差异,但关键特征多有重叠,如识别猫图像时多关注面部特征。
- 贡献:提出注意力引导的迁移攻击(ATA)策略,用模型注意力正则化搜索欺骗噪声,缓解过拟合,提升对抗样本迁移性;实验表明 ATA 对多种高性能图像分类器及防御模型有效,在白盒和黑盒场景优于现有基准;ATA 与其他迁移式攻击兼容,可集成提升性能。

图1:三个具有代表性的模型(VGG 16、ResNet V2以及Inception V3)针对猫的预测所生成的注意力热图。可视化图像是采用[30]中的技术生成的,详见第4.2节。颜色越红的区域对模型决策来说重要性越高。
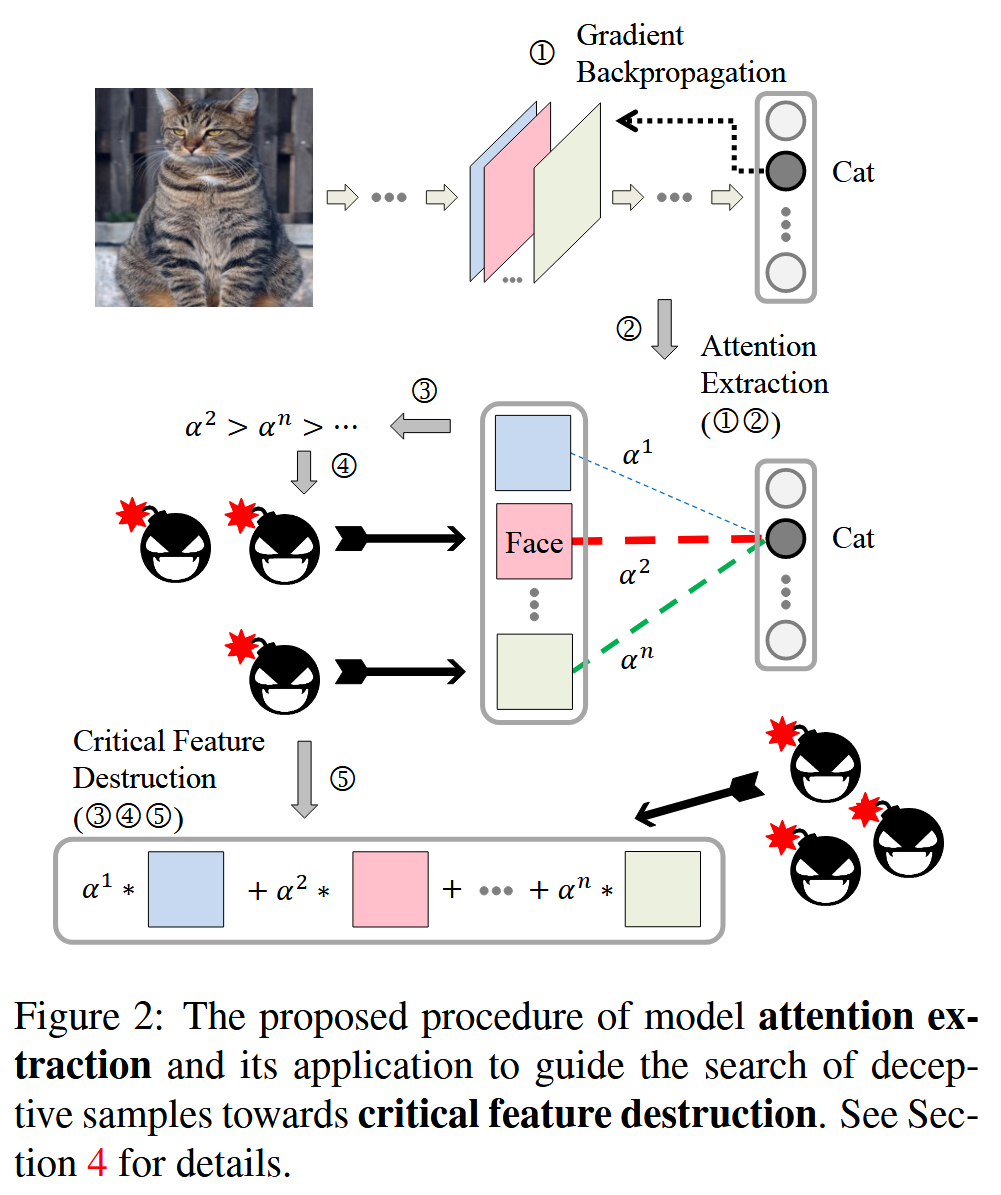
图2:所提出的模型注意力提取流程及其在引导欺骗性样本搜索以破坏关键特征方面的应用。
相关工作-Related Work
该部分主要介绍了相关工作,涵盖攻击模型、提升对抗样本迁移性的方法以及增强深度模型鲁棒性的防御方法,具体内容如下:
- 攻击模型分类
- 提升对抗样本迁移性的方法:包括基于集成的机制和基于正则化的方法,如 TAP 通过在模型训练损失函数中注入正则项引导对抗操作搜索;本文则利用不同模型在正确预测时的注意力相似性来提升迁移性。
- 增强深度模型鲁棒性的防御方法:现有防御方法如输入预处理、防御蒸馏、特征挤压等效果不佳,对抗训练是较有效的方法,本文采用对抗训练模型研究策略性能。
预备知识-Preliminaries
该部分主要介绍了深度神经网络(DNN)图像分类器的相关数学表示、对抗样本需满足的条件以及生成对抗样本的优化问题,具体内容如下:
- DNN 图像分类器的表示:将 DNN 图像分类器表示为函数 f ( x ) f(x) f(x),其由神经元层分层组合而成。对于给定图像 x x x,它输出一个概率向量 f ( x ) f(x) f(x),其中 f ( x ) [ i ] f(x)[i] f(x)[i] 表示 x x x 属于第 i i i 类的概率。同时,用 A k ( x ) = f k ( x ) A_{k}(x)=f_{k}(x) Ak(x)=fk(x) 表示 x x x 在第 k k k 层的隐藏表示,它由多个特征图组成。
- 对抗样本的条件:对于具有真实标签 t t t 的干净图像 x x x,其对抗样本 x ′ x' x′ 需满足两个条件。一是 a r g m a x f ( x ′ ) ≠ t argmax f(x')\neq t argmaxf(x′)=t,即通过恶意样本 x ′ x' x′ 误导目标模型做出错误预测;二是 ∥ x ′ − x ∥ p ≤ ϵ \left\|x' - x\right\|_{p}\leq\epsilon ∥x′−x∥p≤ϵ,确保对原始图像 x x x 的诱导失真在人类难以察觉的范围内,本文采用 l ∞ l_{\infty} l∞ 范数,且该方法也适用于其他范数选择。
- 生成对抗样本的优化问题:用 l ( f ( x ) , t ) l(f(x),t) l(f(x),t) 表示指导模型 f f f 训练的损失函数,攻击者将其作为攻击目标的替代,将生成对抗图像 x ′ x' x′ 表述为一个优化问题,即最大化 l ( f ( x ′ ) , t ) l(f(x'),t) l(f(x′),t),同时满足 ∥ x ′ − x ∥ p ≤ ϵ \left\|x' - x\right\|_{p}\leq\epsilon ∥x′−x∥p≤ϵ 的约束条件。
方法-Method
注意力提取-Attention Extraction
该部分主要阐述了在基于迁移的攻击背景下,如何提取模型注意力以指导对抗样本的生成,具体内容如下:
- 攻击中间特征的重要性:基于迁移的攻击者可通过攻击 DNN 图像分类器中的隐藏特征检测器获益。与传统依赖手工设计特征的方法不同,深度学习分类器能自动提取判别性特征,可分为特征提取模块和 softmax 分类器。由于不同架构的模型在同一任务中可能共享许多特征描述符,所以若对抗噪声能污染中间特征,就更易在不同模型间迁移。
- 关注关键特征的必要性:然而在有限扰动预算下污染中间特征可能过拟合特定模型,因为存在源模型独有的特征滤波器。因此,需让欺骗噪声聚焦于破坏模型预测的关键特征。尽管不同模型获取最终决策的特征证据可能不同,但关键特征常被不同架构共享,如识别猫图像时不同模型多关注面部相关特征。
- 模型注意力的近似计算:将整个特征图视为基础特征检测器,通过空间池化梯度近似计算特征图 A k c A_{k}^{c} Akc(第 k k k 层的第 c c c 个特征图)对类别 t t t 的重要性,公式为 α k c [ t ] = 1 Z ∑ m ∑ n ∂ f ( x ) [ t ] ∂ A k c [ m , n ] \alpha_{k}^{c}[t]=\frac{1}{Z}\sum_{m}\sum_{n}\frac{\partial f(x)[t]}{\partial A_{k}^{c}[m,n]} αkc[t]=Z1∑m∑n∂Akc[m,n]∂f(x)[t],其中 Z Z Z 是归一化常数使 α k c [ i ] ∈ [ − 1 , 1 ] \alpha_{k}^{c}[i]\in[-1,1] αkc[i]∈[−1,1], α k [ t ] \alpha_{k}[t] αk[t] 即为模型对第 k k k 层提取的各类特征关于类别 t t t 的注意力权重。
注意力可视化-Attention Visualization
该部分核心内容是基于已推导出的注意力权重对各类模型的注意力图进行可视化,具体如下:
- 可视化方法:首先,利用对应的模型注意力权重 α k c [ t ] \alpha_{k}^{c}[t] αkc[t] 对不同的特征图进行缩放操作。接着,针对同一层内的所有特征图执行按通道求和的运算。完成求和后,运用 ReLU 函数进一步处理,从而得到针对标签预测 t t t 的注意力图 H k t H_{k}^{t} Hkt,其计算公式为 H k t = R e L U ( ∑ c α k c [ t ] ⋅ A k c ) H_{k}^{t}=ReLU(\sum_{c}\alpha_{k}^{c}[t]\cdot A_{k}^{c}) Hkt=ReLU(∑cαkc[t]⋅Akc)。在此过程中,ReLU 操作的作用是去除注意力图中的负像素,因为负像素可能代表来自其他类别的特征,而保留对感兴趣类别有积极影响的支持性特征,以便更好地聚焦于关键特征。
- 分辨率处理:由于不同层和模型的特征图大小存在差异,为了便于比较,最终会采用双线性插值的方法将注意力图调整到与输入图像相同的分辨率。
- 验证假设:通过对同一猫图像在不同 ImageNet 分类器上的应用,展示了这些分类器关于猫预测的注意力热图(如图 1 所示)。结果表明,所有正确分类该猫图像的模型在注意力分布上呈现出相似性,有力地证实了不同模型在做出正确预测时展现出相似注意力这一假设,为后续利用模型注意力引导对抗样本搜索提供了直观的依据和支持。
关键特征破坏-Critical Feature Destruction
该部分重点讲述了在获得模型注意力后,如何构建新的攻击目标函数来实现对关键特征的破坏,从而提高对抗样本的有效性,具体内容如下:
- 攻击目标函数的构建:在得到模型注意力后,期望对抗样本既能误导目标模型的最终决策,又能破坏关键的中间特征。为此,将这两个目标结合,构建了一个新的替代攻击目标函数 J ( x , x ′ , t , f ) J(x,x',t,f) J(x,x′,t,f),其表达式为 J ( x , x ′ , t , f ) = l ( f ( x ′ ) , t ) + λ ∑ k ∥ H k t ( x ′ ) − H k t ( x ) ∥ 2 J(x,x',t,f)=l(f(x'),t)+\lambda\sum_{k}\left\|H_{k}^{t}(x') - H_{k}^{t}(x)\right\|^{2} J(x,x′,t,f)=l(f(x′),t)+λ∑k∥Hkt(x′)−Hkt(x)∥2.
- 函数各项含义:在这个函数中, l ( f ( x ′ ) , t ) l(f(x'),t) l(f(x′),t) 是传统的训练损失(如交叉熵损失),最大化它可实现误导目标模型的目标;而 λ ∑ k ∥ H k t ( x ′ ) − H k t ( x ) ∥ 2 \lambda\sum_{k}\left\|H_{k}^{t}(x') - H_{k}^{t}(x)\right\|^{2} λ∑k∥Hkt(x′)−Hkt(x)∥2 这一项用于衡量原始特征输出的注意力加权组合与被破坏后的组合之间的距离。通过这种方式,使得对抗样本在更新时更倾向于对具有较大注意力权重的特征进行较大改变,从而实现破坏关键特征的目标。其中, λ \lambda λ 是一个可调节的权重,用于控制第二项的正则化效果,平衡两个目标在攻击过程中的作用。
优化算法-Optimization Algorithm
该部分主要介绍了在提出新的攻击目标函数后,如何将制造可迁移对抗样本转化为一个优化问题,并采用合适的优化算法来求解,具体内容如下:
- 优化问题的构建:将新的攻击目标函数 J ( x , x ′ , t , f ) J(x,x',t,f) J(x,x′,t,f) 代入到原始的对抗样本生成的优化问题中,得到新的优化问题为:在满足 ∥ x ′ − x ∥ p ≤ ϵ \left\|x' - x\right\|_{p}\leq\epsilon ∥x′−x∥p≤ϵ 的约束条件下,最大化 J ( x , x ′ , t , f ) J(x,x',t,f) J(x,x′,t,f),其中 J ( x , x ′ , t , f ) = l ( f ( x ′ ) , t ) + λ ∑ k ∥ H k t ( x ′ ) − H k t ( x ) ∥ 2 J(x,x',t,f)=l(f(x'),t)+\lambda\sum_{k}\left\|H_{k}^{t}(x') - H_{k}^{t}(x)\right\|_{2} J(x,x′,t,f)=l(f(x′),t)+λ∑k∥Hkt(x′)−Hkt(x)∥2.
- 优化算法的选择:为了求解这个优化问题,可以采用不同的骨干优化算法。在本文中,为了进行公平比较,选择的优化策略与白盒基准(BIM)相同,BIM 是 FGSM 的迭代改进版本。具体来说,BIM 在每次迭代中以较小的步长 ϵ ′ \epsilon' ϵ′ 扩展 FGSM,其迭代公式为 x k + 1 ′ = c l i p x , ϵ { x k ′ + ϵ ′ s i g n ( ∂ l ( f ( x k ′ ) , t ) ∂ x ) } x_{k + 1}' = clip_{x,\epsilon}\{x_{k}'+\epsilon'sign(\frac{\partial l(f(x_{k}'),t)}{\partial x})\} xk+1′=clipx,ϵ{xk′+ϵ′sign(∂x∂l(f(xk′),t))},其中 x 0 ′ = x x_{0}' = x x0′=x, c l i p x , ϵ x ′ clip_{x,\epsilon}{x'} clipx,ϵx′ 操作对生成的图像 x ′ x' x′ 进行逐像素裁剪,确保 x ′ x' x′ 始终在原始图像 x x x 的 l ∞ l_{\infty} l∞ ϵ \epsilon ϵ-邻域内。
- 算法总结:算法 1 详细总结了制造可迁移对抗样本的过程,其主要特点是在 BIM 的优化过程中引入了基于注意力的正则化项,通过这种方式来引导对抗样本的生成,提高其在不同模型间的迁移性。

实验-Experiments
实验设置-Experimental Setup
该部分主要介绍了实验设置的相关内容,包括数据集、目标模型、基线、评估指标和参数设定等方面,具体如下:
- 数据集:开发数据集采用 ILSVRC 2012 验证数据集用于超参数微调,测试数据集则是 NeurIPS 2017 对抗竞赛发布的 ImageNet 兼容数据集,包含 1000 张不在原始 ImageNet 中的图像,以此评估攻击算法的泛化能力。
- 目标模型:既包括未防御的多种高性能架构模型,如 ResNet V2、Inception V3、Inception V4、Inception-ResNet V2 及其集成模型;也涵盖了采用对抗训练的防御模型,如对抗训练的 Inception V3、Inception-ResNet V2 以及结合不同数量模型欺骗样本的对抗训练模型。
- 基线:将攻击方法与三种基准技术对比,包括添加高斯噪声的 Random Noise 攻击,以及 FGSM、BIM、C&W、JSMA 等先进的白盒攻击方法,还有同样旨在提升对抗迁移性的 TAP 方法。
- 评估指标:通过目标模型的 top - 1 准确率来比较不同攻击方法的性能,准确率越低表示攻击性能越好。
- 参数设定:基于初步实验仅将源模型的最后卷积层纳入正则项;采用基准方法和 Foolbox 推荐的默认参数,随机噪声从均值为 0、方差为 1 的截断正态分布采样;固定扰动预算 ϵ \epsilon ϵ 为 16,在开发数据集上进行网格搜索确定算法最佳超参数,攻击迭代次数 K K K 设为 5。
攻击迁移性-Transferability of Attacks
该部分主要围绕对未防御模型和经过对抗训练的防御模型的攻击实验展开,详细分析了攻击性能及可迁移性,具体内容如下:
- 对未防御模型的攻击结果
- 首先,所有未防御模型在干净数据上具有较高准确率且对随机噪声有抗性,通常容量大的模型表现更好。
- 在白盒设置下,BIM 是表现最佳的攻击方法,而本文提出的算法 ATA 与 BIM 结果相当且显著优于其他对比方法。
- 在黑盒设置中,ATA 极大地提升了 BIM 的可迁移性。例如以 Inception V3 为源模型时,ATA 相比 BIM 在攻击成功率上平均提升了 40.4%,且除少数情况略逊于 TAP 外,大幅超越了其他基准方法。TAP 使用两个正则化项,而本文 ATA 仅用一个关注注意力加权内部特征距离的正则化项,却在多数情况下表现更优。
- 对防御模型的攻击结果
- 同样显著提升了 BIM 的可迁移性,如以 Inception V3 为源模型时,平均使 BIM 的攻击成功率提高 29.3%。
- ATA 除个别情况稍落后于 TAP 外,显著优于其他基准方法。
- 对抗样本的可视化展示:展示了用 ATA 生成的针对 Inception V3 的对抗图像,肉眼难以察觉对原始图像的扰动,证明了攻击的隐蔽性。
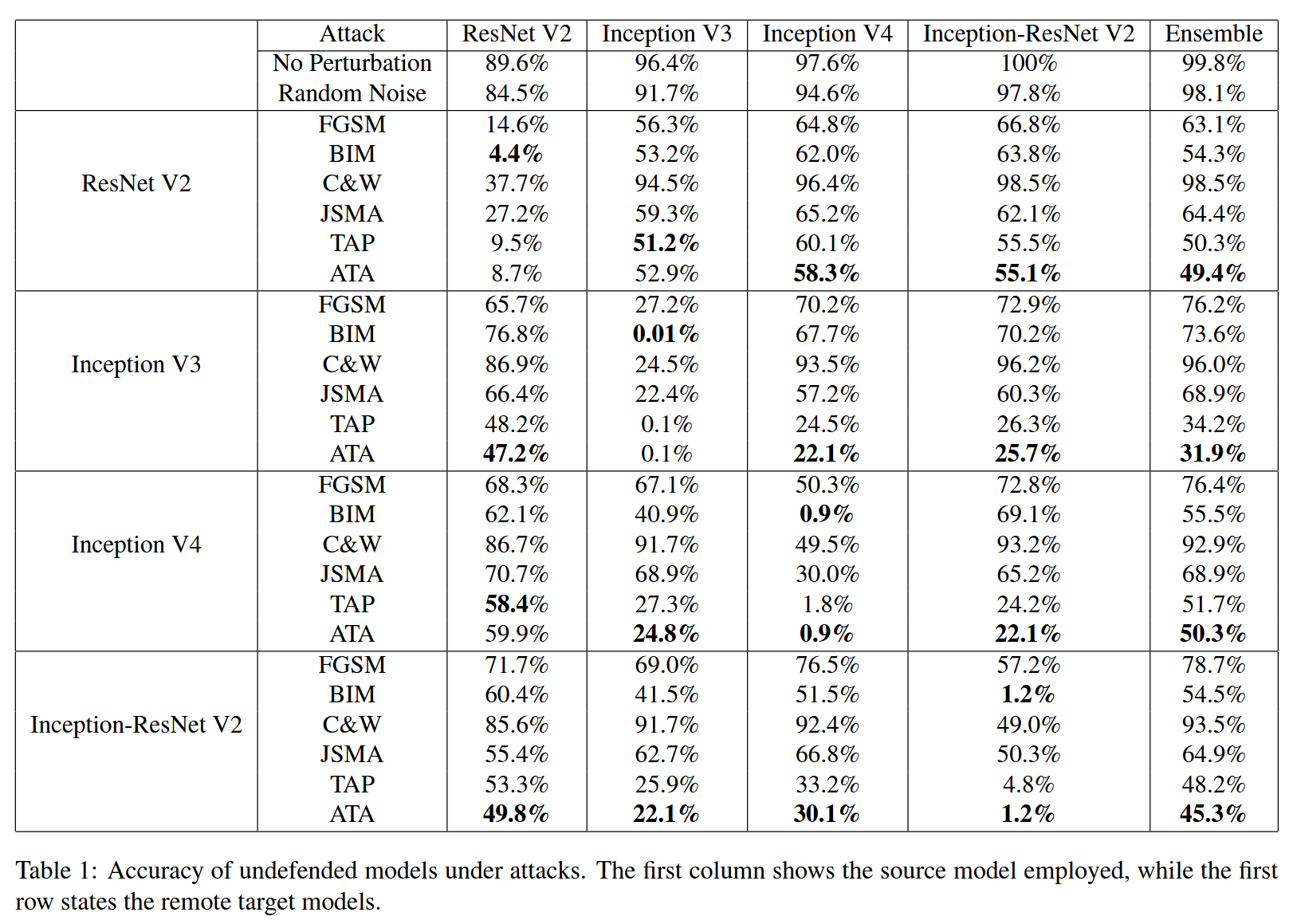
表 1:未防御模型在遭受攻击时的准确率。第一列显示所采用的源模型,而第一行说明远程目标模型。
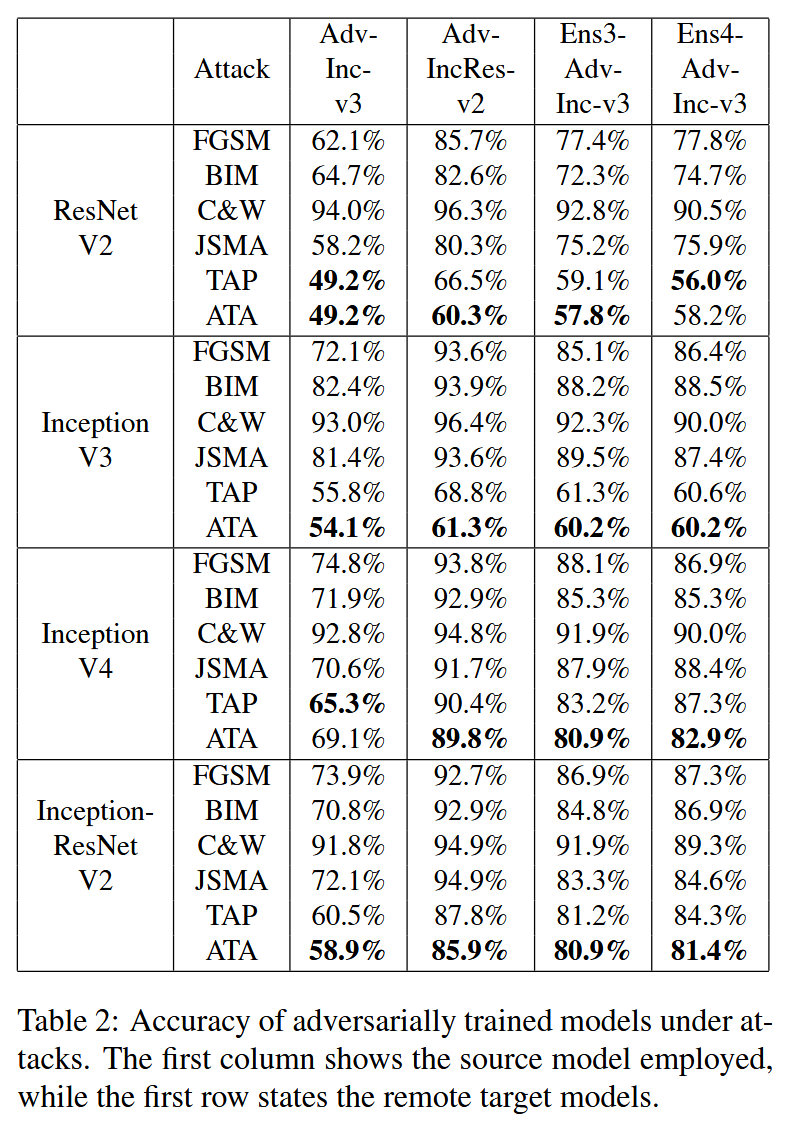
表 2:经过对抗训练的模型在遭受攻击时的准确率。第一列展示了所使用的源模型,而第一行说明了远程目标模型。

图 3:一张原始的源图像以及用所提出的注意力引导的迁移攻击(ATA)方法生成的相应对抗图像。目标模型是 Inception V3。尽管这种扰动人类难以察觉,但它能够成功欺骗高性能模型。
超参数对攻击成功率的影响-Effect of Hyper-parameters on Attack Success Rates
该部分重点探讨了正则化权重 λ \lambda λ 这一主要超参数对攻击成功率的影响,具体内容如下:
- 实验方法:在保持其他参数固定的情况下,改变正则化权重 λ \lambda λ 来合成对抗样本,并通过报告目标模型在这些恶意样本上的 top - 1 准确率来衡量攻击成功率。
- 实验结果与分析:以 Inception V3 作为源模型,对所有未防御和防御模型进行实验,将 λ \lambda λ 从 1 × 1 0 − 4 1\times10^{-4} 1×10−4 到 1 1 1 按对数尺度以步长 1 1 1 进行变化。结果发现,损失函数 J J J 中的两项之间存在权衡关系,因为在有限的扰动预算下,平衡两项的贡献对于缓解过拟合至关重要,不同的 λ \lambda λ 取值会导致攻击成功率产生相应变化。
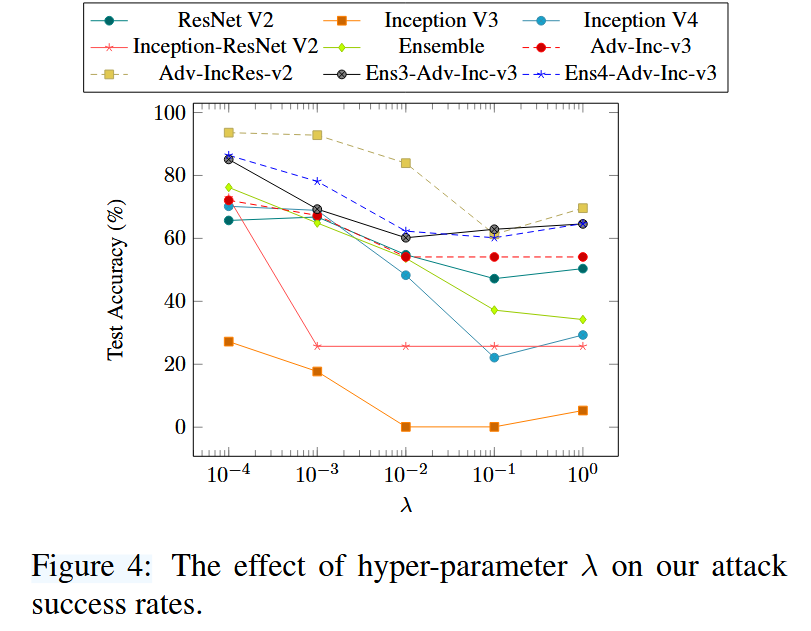
图 4:超参数λ对我们攻击成功率的影响。
提出策略的互补效应-Complementing Effect of the Proposed Strategy
该部分主要探讨了所提策略与其他基于迁移的黑盒攻击方法的兼容性及互补效果,具体内容如下:
- 兼容性验证:原则上,本文提出的策略与其他基于迁移的黑盒攻击方法兼容,为此选择了两种前沿的此类攻击方法进行验证,分别是基于集成的平移不变攻击(TI)和基于正则化的可迁移对抗扰动(TAP)。
- 实验设置与改进措施
- 对于 TI 与 ATA 的组合,仅修改算法 1 的更新规则,将其更新公式改为 x k + 1 ′ = c l i p x , ϵ { x k ′ + ϵ ′ s i g n ( W ∗ ∂ J ( x , x k ′ , t , f ) ∂ x ) } x_{k + 1}' = clip_{x,\epsilon}\{x_{k}'+\epsilon'sign(W * \frac{\partial J(x,x_{k}',t,f)}{\partial x})\} xk+1′=clipx,ϵ{xk′+ϵ′sign(W∗∂x∂J(x,xk′,t,f))},其中 W W W 是预定义的核, ∗ * ∗ 表示卷积操作。
- 对于 TAP 与 ATA 的组合,在攻击目标函数 J J J(公式(6))中添加 η ∥ S ∗ ( x ′ − x ) ∥ 1 \eta\left\|S * (x' - x)\right\|_{1} η∥S∗(x′−x)∥1 这一项,其中 S S S 是预定义的卷积滤波器,并且由于不存在梯度消失问题,为简化起见舍弃了 TAP 中的另一项。
- 实验结果:以 Inception V4 为源模型进行实验,在黑盒设置下,本文策略使 TAP 的平均攻击成功率提高了 6.8 % 6.8\% 6.8%,使 TI 的平均攻击成功率提高了 4.6 % 4.6\% 4.6%,在白盒设置下也能进一步提升它们的攻击成功率,从而证实了所提技术对现有方法的补充和提升作用。

表 3:结合所提出的注意力引导的迁移攻击(ATA)和兼容算法的模型在遭受攻击时的准确率。
结论-Conclusion
该主要总结了研究工作的核心内容与成果,具体如下:
- 提出了注意力引导的转移攻击(ATA)方法,用于在无目标模型反馈信息的情况下针对黑盒 DNN 合成对抗样本。
- 该策略利用源模型的注意力来规范对抗样本的搜索方向,重点破坏不同模型所依赖的关键特征,从而显著提高了对抗样本的可迁移性。
- 通过大量实验充分验证了 ATA 方法的有效性,且在白盒和黑盒场景下均优于现有的先进基准方法。
- 强调 ATA 攻击能够更有效地揭示深度模型的脆弱性,为评估模型防御提供了有力的基准,对推动该领域研究具有重要意义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











