







Boosting Adversarial Transferability by Block Shuffle and Rotation
本文 “Boosting Adversarial Transferability by Block Shuffle and Rotation” 提出一种名为块打乱和旋转(BSR)的新型基于输入变换的攻击方法,通过破坏图像内在关系扰乱注意力热图,优化对抗扰动,提升对抗样本在不同模型间的转移性,实验结果验证了该方法的有效性。
摘要-Abstract
Adversarial examples mislead deep neural networks with imperceptible perturbations and have brought significant threats to deep learning. An important aspect is their transferability, which refers to their ability to deceive other models, thus enabling attacks in the black-box setting. Though various methods have been proposed to boost transferability, the performance still falls short compared with white-box attacks. In this work, we observe that existing input transformation based attacks, one of the mainstream transfer-based attacks, result in different attention heatmaps on various models, which might limit the transferability. We also find that breaking the intrinsic relation of the image can disrupt the attention heatmap of the original image. Based on this finding, we propose a novel input transformation based attack called block shuffle and rotation (BSR). Specifically, BSR splits the input image into several blocks, then randomly shuffles and rotates these blocks to construct a set of new images for gradient calculation. Empirical evaluations on the ImageNet dataset demonstrate that BSR could achieve significantly be tter transferability than the existing input transformation based methods under single-model and ensemble-model settings. Combining BSR with the current input transformation method can further improve the transferability, which significantly outperforms the state-of-the-art methods.
对抗样本以难以察觉的扰动误导深度神经网络,给深度学习带来了重大威胁。一个重要方面是它们的迁移性,即欺骗其他模型的能力,从而能够在黑盒设置下进行攻击。尽管已经提出了各种方法来提高迁移性,但与白盒攻击相比,性能仍然不足。在这项工作中,我们观察到现有的基于输入变换的攻击(主流的基于迁移的攻击之一)在不同模型上会产生不同的注意力热图,这可能会限制迁移性。我们还发现打破图像的内在关系可以扰乱原始图像的注意力热图。基于这一发现,我们提出了一种名为块打乱和旋转(BSR)的新型基于输入变换的攻击。具体来说,BSR 将输入图像分割成几个块,然后随机打乱和旋转这些块,以构建一组用于梯度计算的新图像。 在 ImageNet 数据集上的实证评估表明,在单模型和集成模型设置下,BSR 可以比现有的基于输入变换的方法实现显著更好的迁移性。将 BSR 与当前的输入变换方法相结合可以进一步提高迁移性,显著优于最先进的方法。
引言-Introduction
- 深度神经网络的脆弱性:深度神经网络(DNNs)在图像分类、分割、对象检测、人脸识别等诸多任务中取得优异成果,但易受对抗样本攻击。对抗样本与合法样本相似,却能误导模型做出不合理预测,在安全敏感应用(如自动驾驶、人脸验证)中引发严重担忧。
- 对抗攻击分类及现状
- 白盒与黑盒攻击:对抗攻击分为白盒攻击(能获取目标模型架构和参数等全部信息)和黑盒攻击(仅能获取有限信息),黑盒攻击在现实应用中更具适用性。
- 攻击方法及迁移性问题:白盒攻击中,基于梯度的攻击是主要方法,如 FGSM、I - FGSM 等。虽然一些攻击方法在白盒攻击性能良好,但迁移性较差,限制了其在现实攻击中的效果。目前已有多种方法尝试提升对抗迁移性,如集成动量、攻击多个模型、变换图像、利用模型特征、修改前向或反向过程等,其中基于输入变换的方法在提升迁移性方面较为有效。
- 本文研究动机与贡献
- 动机:现有基于输入变换的攻击在不同模型上产生不同注意力热图,可能限制对抗迁移性。作者发现打破图像内在关系可扰乱注意力热图,进而探索如何生成在不同模型上具有一致注意力热图的对抗样本,以提升迁移性。
- 贡献
- 揭示打破图像内在关系可扰乱深度模型注意力热图。
- 提出块打乱和旋转(BSR)这一新型攻击方法,通过优化变换图像扰动消除注意力热图方差,提升迁移性,这是首个基于扰乱注意力热图来提高迁移性的输入变换攻击方法。
- 经 ImageNet 数据集实验验证,BSR在单模型和集成模型设置下,迁移性优于现有基于输入变换的方法,且与其他方法结合可进一步提升对抗迁移性。

图1. 使用 Grad - CAM 在 Inception - v3 模型上生成的原始图像、打乱图像以及在打乱图像上重新打乱后的注意力热图.
相关工作-Related Work
对抗攻击-Adversarial Attacks
- 对抗攻击的发现与分类
- 发现威胁:Szegedy等人首次发现对抗样本,其对深度神经网络(DNN)应用构成巨大威胁。
- 分类方式:对抗攻击主要分为白盒攻击和黑盒攻击两类。白盒攻击可获取目标模型的梯度、权重、架构等全部信息,基于梯度最大化损失函数的攻击是主要的白盒攻击方式。黑盒攻击对目标模型的访问有限,可进一步细分为基于分数的攻击、基于决策的攻击和基于迁移的攻击,其中基于迁移的攻击因攻击者采用代理模型生成的对抗样本来直接攻击目标模型,在现实世界中具有广泛应用前景而备受关注。
- 各类攻击方法简述
- 白盒攻击方法发展
- FGSM及其扩展:FGSM 通过在输入的梯度方向添加扰动来生成对抗样本,但攻击性能较差。I - FGSM 将 FGSM 扩展为迭代版本,虽提高了白盒攻击性能,但迁移性不佳。
- 动量引入提升迁移性:MI - FGSM 引入动量稳定优化过程并逃离局部最优,随后更多基于动量的先进攻击方法(如 NI - FGSM、VMI - FGSM、EMI - FGSM、PGN 等)被提出以进一步提高迁移性。
- 集成攻击:通过同时攻击多个模型来生成更具迁移性的对抗样本,如相关研究中的多种集成攻击方法。
- 特征空间扰乱攻击:部分工作通过扰乱特征空间来生成对抗样本,如某些特定研究中的方法。
- 基于输入变换的攻击方法
- 白盒攻击方法发展
对抗防御-Adversarial Defenses
- 对抗训练:随着对抗攻击受到越来越多的关注,研究人员致力于减轻其威胁。对抗训练是一种重要的防御手段,通过将对抗样本注入训练过程来增强模型的鲁棒性。例如,Tramer等人提出的集成对抗训练,利用在多个模型上生成的对抗扰动,对基于迁移的攻击具有显著的防御效果。
- 去噪滤波器:作为一种数据预处理方法,去噪滤波器旨在在将输入样本送入目标模型之前过滤掉对抗扰动。例如,Liao等人设计的基于U - Net的高级表示引导去噪器(HGD),以及Naseer等人使用自监督对抗训练机制训练的神经表示净化器(NRP),均能有效消除对抗扰动。
- 基于输入变换的防御:与基于输入变换的攻击相对应,研究人员也引入了多种基于输入变换的防御方法。这些方法在预测前对图像进行变换,以消除对抗扰动的影响。例如,随机调整大小和填充、使用位减少进行特征压缩、特征蒸馏等方法。
- 认证防御方法:与上述经验性防御方法不同,一些认证防御方法能够在给定半径内提供可证明的防御。例如,区间边界传播(IBP)、CROWN - IBP、随机平滑(RS)等方法,为模型提供了更具理论保证的防御能力。
注意力热图-Attention Heatmaps
- 深度模型解释的需求与方法:由于深度模型的内部机制对研究人员来说仍然难以捉摸,因此开发了多种技术来解释这些模型,其中注意力热图是一种广泛采用的方式。
- 注意力热图的示例方法:例如,Zhou等人采用全局平均池化来突出有判别力的对象部分;Selvaraju等人提出的Grad - CAM则利用梯度信息生成更准确的注意力热图。
- 本文对注意力热图的应用:在本研究中,作者采用注意力热图来研究如何提高对抗迁移性,通过分析不同输入变换方法生成的对抗样本在不同模型上的注意力热图一致性,探索提升对抗迁移性的方法,为后续提出基于块打乱和旋转(BSR)的攻击方法提供了研究基础和思路。
方法-Methodology
预备知识-Preliminaries
- 对抗样本生成的目标:给定一个具有参数 θ \theta θ 的受害模型 f f f 和一个带有真实标签 y y y 的干净图像 x x x,攻击者的目标是生成一个与原始图像 x x x 难以区分(即 ∥ x a d v − x ∥ p ≤ ϵ \left\|x^{a d v}-x\right\|_{p} ≤\epsilon xadv−x p≤ϵ,这里 ϵ \epsilon ϵ 是扰动预算, ∥ ⋅ ∥ p \|\cdot\|_{p} ∥⋅∥p 是 ℓ p \ell_{p} ℓp 范数距离,本文采用 ℓ ∞ \ell_{\infty} ℓ∞ 距离)的对抗样本 x a d v x^{a d v} xadv,但该对抗样本能欺骗受害模型,使 f ( x a d v ; θ ) ≠ f ( x ; θ ) = y f(x^{a d v} ; \theta) ≠f(x ; \theta)=y f(xadv;θ)=f(x;θ)=y。攻击者通常通过最大化目标函数来生成这样的对抗样本,目标函数可形式化为 x a d v = a r g m a x ∥ x a d v − x ∥ p ≤ ϵ J ( x a d v , y ; θ ) x^{a d v}=\underset{\left\| x^{a d v}-x\right\| _{p} \leq \epsilon}{argmax} J\left(x^{a d v}, y ; \theta\right) xadv=∥xadv−x∥p≤ϵargmaxJ(xadv,y;θ),其中 J ( . ) J(.) J(.) 是相应的损失函数(如交叉熵损失)。
- 常见攻击方法的原理
- FGSM:FGSM 通过在输入的梯度方向添加一个小扰动来更新良性样本,即 x a d v = x + ϵ ⋅ s i g n ( ∇ x J ( x , y ; θ ) ) x^{a d v}=x+\epsilon \cdot sign\left(\nabla_{x} J(x, y ; \theta)\right) xadv=x+ϵ⋅sign(∇xJ(x,y;θ)),它能高效生成对抗样本,但攻击性能较差。
- I - FGSM:I - FGSM 将 FGSM 扩展为迭代版本,通过迭代地添加小扰动来更新对抗样本,公式为 x t a d v = x t − 1 a d v + α ⋅ s i g n ( ∇ x t − 1 a d v J ( x t − 1 a d v , y ; θ ) ) x_{t}^{a d v}=x_{t - 1}^{a d v}+\alpha \cdot sign\left(\nabla_{x_{t - 1}^{a d v}} J\left(x_{t - 1}^{a d v}, y ; \theta\right)\right) xtadv=xt−1adv+α⋅sign(∇xt−1advJ(xt−1adv,y;θ))(其中 x 0 a d v = x x_{0}^{a d v}=x x0adv=x, α \alpha α 是步长),虽然提高了白盒攻击性能,但迁移性不佳。
- MI - FGSM:考虑到 I - FGSM 的迁移性问题,MI - FGSM 引入动量,通过公式 g t = μ ⋅ g t − 1 + ∇ x t − 1 a d v J ( x t − 1 a d v , y ; θ ) ∥ ∇ x t − 1 a d v J ( x t − 1 a d v , y ; θ ) ∥ 1 g_{t}=\mu \cdot g_{t - 1}+\frac{\nabla_{x_{t - 1}^{a d v}} J\left(x_{t - 1}^{a d v}, y ; \theta\right)}{\left\| \nabla_{x_{t - 1}^{a d v}} J\left(x_{t - 1}^{a d v}, y ; \theta\right)\right\| _{1}} gt=μ⋅gt−1+ ∇xt−1advJ(xt−1adv,y;θ) 1∇xt−1advJ(xt−1adv,y;θ) 和 x t a d v = x t − 1 a d v + α ⋅ s i g n ( g t ) x_{t}^{a d v}=x_{t - 1}^{a d v}+\alpha \cdot sign\left(g_{t}\right) xtadv=xt−1adv+α⋅sign(gt)( g 0 = 0 g_{0}=0 g0=0, μ \mu μ 是衰减因子)来生成更具迁移性的对抗样本。
- 基于输入变换的攻击集成方式:假设 T T T 是一个变换算子,现有基于输入变换的攻击通常集成到 MI - FGSM 中以提高对抗迁移性,即采用 ∇ x t − 1 a d v J ( T ( x t − 1 a d v ) , y ; θ ) \nabla_{x_{t - 1}^{a d v}} J(T(x_{t - 1}^{a d v}), y ; \theta) ∇xt−1advJ(T(xt−1adv),y;θ) 来计算梯度。这部分预备知识为后续理解本文提出的基于块打乱和旋转(BSR)的攻击方法奠定了理论基础,BSR 也是基于这些基本的攻击原理和优化思路,通过创新的输入变换方式来提升对抗迁移性。
动机-Motivation
- 基于特征共享的假设与迁移性影响:不同模型虽参数和架构各异,但在图像识别任务中其学习特征存在共享特性。由此假设针对这些显著特征的对抗扰动对迁移性影响更大,且已有研究发现扰乱注意力热图可增强迁移性,这支持了该假设。直观上,若对抗样本在不同模型上的注意力热图一致,预期能产生更好的对抗迁移性。
- 现有方法问题的发现与新问题提出:为探究此想法,作者评估了基于 GradCAM 的几种输入变换攻击生成的对抗样本在不同模型上的注意力热图一致性,发现白盒模型和目标黑盒模型上的注意力热图不同,导致对抗迁移性受限(如图2)。这促使作者提出新问题:如何生成在不同模型上具有一致注意力热图的对抗样本?
- 提升迁移性的思路探讨:为保持多模型注意力热图的一致性,直接方法是利用不同模型输入图像的梯度进行集成攻击,但实际获取多个模型困难,故本文探索在单模型上通过输入变换获取不同注意力热图的梯度,以此优化扰动,消除不同变换图像注意力热图的方差,增强一致性,进而提高对抗迁移性。此部分明确了研究的动机和方向,为后续提出 BSR 方法提供了理论依据和逻辑起点,即从解决现有方法中注意力热图不一致问题出发,探索新的攻击方法以提升对抗迁移性。

图2. 使用梯度加权类激活映射(Grad - CAM)由各种输入变换生成的对抗样本的注意力热图.
块打乱和旋转-Block Shuffle and Rotation
- 解决单模型注意力热图变化的问题:在仅有单源模型的情况下,为在计算梯度时获得多样的注意力热图,需对输入图像进行变换。本部分探讨如何通过变换图像扰乱单源模型的注意力热图,以提升对抗迁移性。
- 基于人类认知的图像变换思路
- 部分遮挡与注意力转移:注意力热图突出了对深度模型准确预测有贡献的重要特征。人类可基于部分视觉线索识别物体,这启发了通过图像变换使模型关注主物体特定区域,从而改变注意力热图。例如,部分遮挡物体可使模型聚焦于剩余部分,但直接遮挡会导致信息丢失,使梯度计算无意义,影响攻击效率和效果。
- 内在关系破坏与多样化热图:人类能根据物体内在关系重建部分遮挡的物体,基于此,作者尝试通过将图像分割成块并打乱来破坏内在关系,构建新图像。实验表明,变换后的图像注意力热图被扰乱,即使恢复原始图像的注意力热图,也与原始不同。这表明打破内在关系可获得更多样的注意力热图,有助于提升对抗迁移性。
- BSR算法实现
- 图像变换操作:提出新的输入变换 T ( x , n , τ ) T(x, n, \tau) T(x,n,τ),随机将图像分割成 n × n n×n n×n 个块,然后随机打乱这些块,并对每个块独立旋转 − τ ≤ β ≤ τ -\tau ≤\beta ≤\tau −τ≤β≤τ 度(超出边界部分去除并填充零)。
- 梯度计算与优化:通过变换 T ( x , n , τ ) T(x, n, \tau) T(x,n,τ) 可获得比不同模型更具多样性的注意力热图,为使不同模型的注意力热图更一致,采用该变换计算梯度。由于变换不能保证所有变换图像正确分类(如在Inc - v3上约86.8%能正确分类),为消除内在关系破坏引入的方差,计算 N N N 个变换图像的平均梯度 g ‾ = 1 N ∑ i = 0 N ∇ x a d v J ( T ( x a d v , n , τ ) , y ; θ ) \overline{g}=\frac{1}{N} \sum_{i = 0}^{N} \nabla_{x^{a d v}} J(\mathcal{T}(x^{a d v}, n, \tau), y ; \theta) g=N1∑i=0N∇xadvJ(T(xadv,n,τ),y;θ).
- 集成到MI - FGSM:将输入变换 T ( x , n , τ ) T(x, n, \tau) T(x,n,τ) 集成到MI - FGSM中,形成 BSR 算法(如算法1所示),在每次迭代中,生成多个变换图像,计算平均梯度,更新动量,进而更新对抗样本。这部分详细阐述了 BSR 方法的核心原理和实现过程,通过创新的图像变换方式和梯度计算策略,实现了在单模型上优化对抗扰动,提高对抗迁移性的目标。

BSR 与 RLFAT 的对比-BSR Vs. RLFAT
- 目标差异:BSR 旨在生成更具迁移性的对抗样本,以提升在不同模型间的攻击效果;而 RLFAT 的目标是通过最小化原始图像和块打乱图像的高级特征之间的距离,来增强对抗训练的泛化能力,二者的应用方向有所不同。
- 策略区别:BSR在图像变换策略上采用了更为复杂的操作,不仅对图像块进行打乱,还对每个块进行独立旋转,以此打破图像内在关系,获取更多样化的注意力热图;RLFAT 仅对图像块进行简单的打乱操作,其对图像的改变程度和方式与 BSR 不同。
- 用法不同:BSR 直接利用变换后的图像进行梯度计算,从而生成对抗样本,是一种直接作用于对抗样本生成过程的方法;RLFAT 则将图像变换视为对原始图像的一种正则化手段,处理方式和在攻击过程中的角色与 BSR 有本质区别。
- 创新性体现:鉴于上述在目标、策略和用法上的显著差异,BSR 作为一种全新的基于输入变换的攻击方法,在有效提升对抗迁移性方面具有独特的创新性,与 RLFAT 有着明显的区分,为对抗攻击领域提供了新的思路和方法。这部分通过详细对比 BSR 和 RLFAT,进一步明确了 BSR 方法的独特性和创新性,突出了其在提升对抗迁移性方面的优势和价值。
Experiments-实验
实验设置-Experiment Setup
- 数据集选择:实验选用 ImageNet 数据集的验证集,从中选取 1000 张属于 1000 个类别的图像作为评估数据,为后续测试提供了丰富多样的样本来源,以全面检验所提出的 BSR 方法及其他对比方法的有效性和性能表现。
- 模型选用
- 受害模型:采用四个流行的模型,即Inception - v3(Inc - v3)、Inception - v4(Inc - v4)、Inception - Resnet - v3(IncRes - v3)、Resnet - v2 - 101(Res - 101),以及三个集成对抗训练模型(Inc - v3 e n s 3 _{ens3} ens3、Inc - v3 e n s 4 _{ens4} ens4、IncRes - v2 e n s 2 _{ens2} ens2)作为受害模型,用于评估对抗样本在不同模型间的迁移性,从而全面衡量攻击方法的效果。
- 防御模型(用于后续评估):为进一步验证 BSR 的有效性,引入了多个先进的防御方法,包括HGD、R&P、NIPS - r31、BitRD、JPEG、FD、RS 和 NRP 等,这些防御模型将在后续实验中用于测试 BSR 方法生成的对抗样本对其的突破能力,以更全面地评估 BSR 的性能。
- 基线方法确定:选择五种有竞争力的基于输入变换的攻击方法(DIM、TIM、SIM、Admix、PAM)作为基线,将所有输入变换集成到 MI - FGSM 中进行公平比较。这些基线方法代表了当前在提升对抗迁移性方面的相关研究成果,通过与它们对比,可以清晰地展现BSR方法的优势和改进之处。
- 参数设置
- 通用参数:对于MI - FGSM,设置最大扰动 ϵ = 16 \epsilon = 16 ϵ=16,迭代次数 T = 10 T = 10 T=10,步长 α = ϵ / T \alpha=\epsilon / T α=ϵ/T,衰减因子 μ = 1 \mu = 1 μ=1,为后续攻击方法的实施提供了统一的基础参数设置。
- 各方法特定参数:DIM 采用 0.5 的变换概率;TIM 使用 7 × 7 7×7 7×7 的核大小;SIM 和 Admix 的复制数量为5,且 Admix 混合 3 张图像,强度为 0.2;PAM 的缩放数量为 4,增强路径数量为 3;BSR 将图像分割为 2 × 2 2×2 2×2 个块,最大旋转角度 τ = 2 4 ∘ \tau = 24^{\circ} τ=24∘,并计算 N = 20 N = 20 N=20 个变换图像的梯度。这些针对不同方法的特定参数设置,确保了每种方法在实验中的准确实现,以便进行公平有效的对比评估。此部分实验设置为整个实验过程奠定了基础,明确了实验所涉及的数据集、模型、基线方法以及各类参数,使得后续实验结果具有可比性和可靠性,能够有效验证 BSR 方法的性能和优势。
单模型评估-Evaluation on Single Model
- 实验过程:在该实验中,首先对多种基于输入变换的攻击方法(包括DIM、TIM、SIM、Admix、PAM 以及本文提出的 BSR)在单模型设置下的攻击性能进行评估。具体操作是在四个标准训练模型(Inception - v3、Inception - v4、Inception - Resnet - v3、Resnet - v2 - 101)上分别生成对抗样本,然后将这些对抗样本在七个模型(上述四个标准训练模型以及三个集成对抗训练模型)上进行测试,以获取攻击成功率,攻击成功率定义为受害模型在对抗样本上的错误分类率。
- 实验结果分析
- 各方法性能对比:实验结果表明,不同方法在不同模型上的表现各异。DIM 在标准训练模型上表现较好,而 TIM 在对抗训练模型上具有更好的迁移性;SIM 作为 Admix 的特殊情况,性能优于 DIM 和 TIM,Admix 在标准训练模型中表现最佳,PAM 在对抗训练模型上展现出较好的迁移性。
- BSR方法的优势:相比之下,本文提出的 BSR 方法在保持与其他方法可比的白盒攻击性能的同时,显著提升了迁移性。在标准训练模型上,BSR 平均攻击成功率达到93.8%,比 Admix 至少高出6.5%;在对抗训练模型上,BSR 平均攻击成功率为56.2%,比 PAM 高出11.0%。这充分证明了 BSR 在生成可迁移对抗样本方面的卓越性能,强调了通过保持不同模型注意力热图一致性来提高迁移性的重要性,也为后续研究提供了有力的参考依据,表明 BSR 在单模型评估中相对于现有方法具有明显的优势,为进一步的研究和应用奠定了基础。
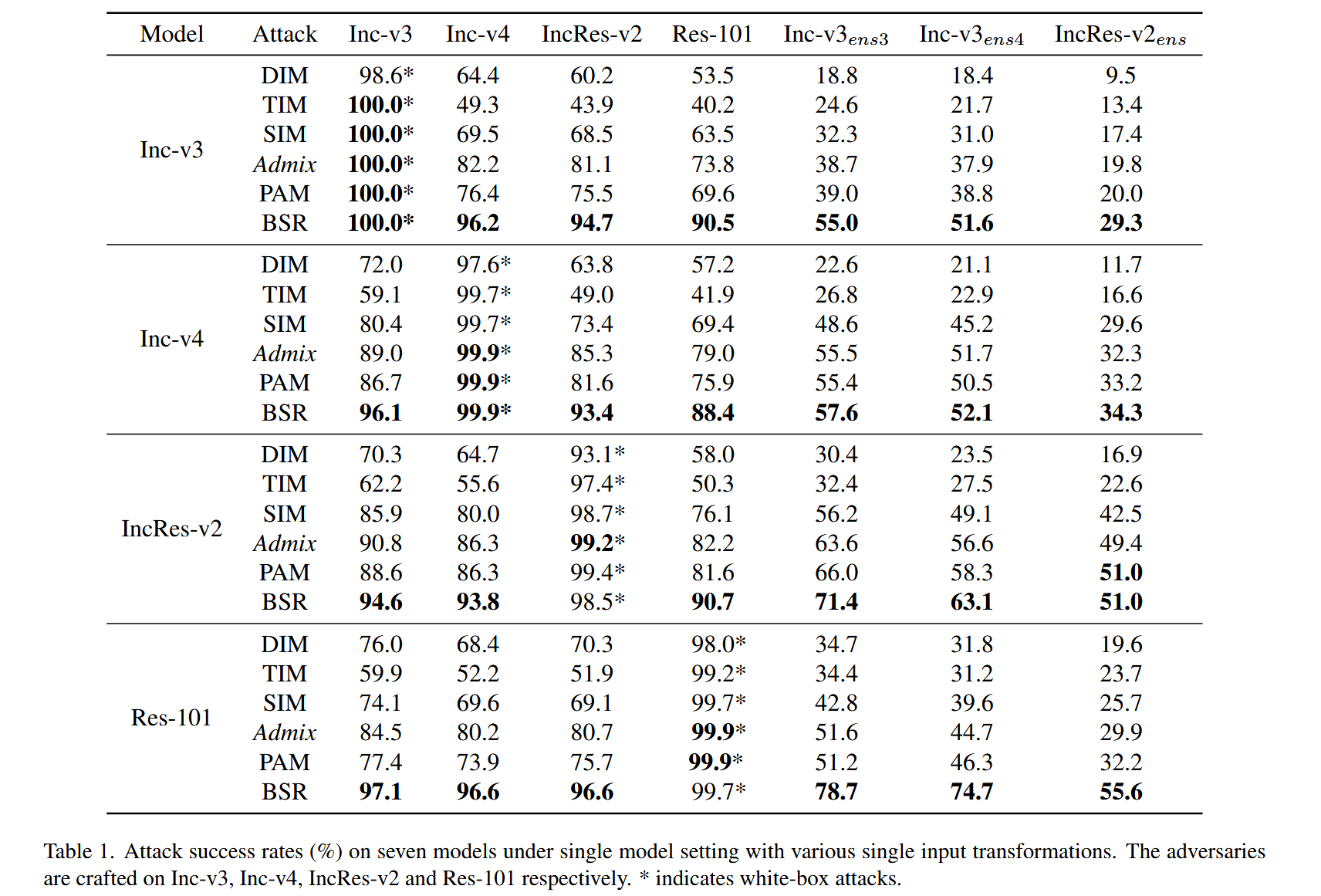
表1. 在单模型设置下,采用各种单一输入变换在七个模型上的攻击成功率(%)。对抗样本分别基于Inception - v3(Inc - v3)、Inception - v4(Inc - v4)、Inception - Resnet - v2(IncRes - v2)和Resnet - v2 - 101(Res - 101)生成。
∗
*
∗ 表示白盒攻击.
组合输入变换评估-Evaluation on Combined Input Transformation
- 实验目的与设置
- 目的:前人研究表明,优秀的基于输入变换的攻击方法不仅自身应具备良好的迁移性,还需与其他输入变换方法兼容,以生成更具迁移性的对抗样本。因此,本实验旨在评估BSR与其他输入变换方法组合后的性能表现。
- 设置:遵循 Admix 的评估设置,将 BSR 分别与 DIM、TIM、SIM、Admix 和 PAM 等输入变换方法进行组合,得到 BSR - DIM、BSR - TIM、BSR - SIM、BSR - Admix 和BSR - PAM 等组合方法。同时,还将 BSR 与多种输入变换相结合,如 BSR - TI - DIM(TI 表示 TIM 与 DIM 组合)和BSR - SI - TI - DIM(SI 表示 SIM 与 TI - DIM 组合),并与 Admix - TI - DIM 和 PAM - TI - DIM 进行对比。实验在Inc - v3上生成对抗样本,测试其在七个模型上的攻击成功率。
- 实验结果与分析
- BSR对迁移性的提升:实验结果显示,BSR 显著提高了与之组合的输入变换方法的迁移性。总体而言,BSR 能使攻击成功率提高16.7% - 52.0%。特别是在对抗训练模型上,组合后的攻击性能提升幅度为22.8% - 52.0%。例如,BSR - SIM 组合在某些模型上的攻击成功率提升了52.0%。
- 与其他组合方法对比:尽管 Admix - TI - DIM 在组合方法中表现较好,但 BSR - TI - DIM 的平均攻击成功率比 Admix - TI - DIM 高出2.6%。尤其当 BSR 与 SI - DI - TIM 组合时,进一步增强了迁移性,提升幅度在8.1% - 31.6%之间。如 BSR - SI - TI - DIM 在某些模型上的攻击成功率提升了31.6%。这充分体现了BSR的高效性以及与其他输入变换方法的高度兼容性,进一步证明了 BSR 在提升对抗迁移性方面的有效性,为对抗攻击领域中输入变换方法的组合应用提供了有力的参考依据,表明 BSR 在与其他方法组合时能够显著提升攻击效果,优于现有组合方法。
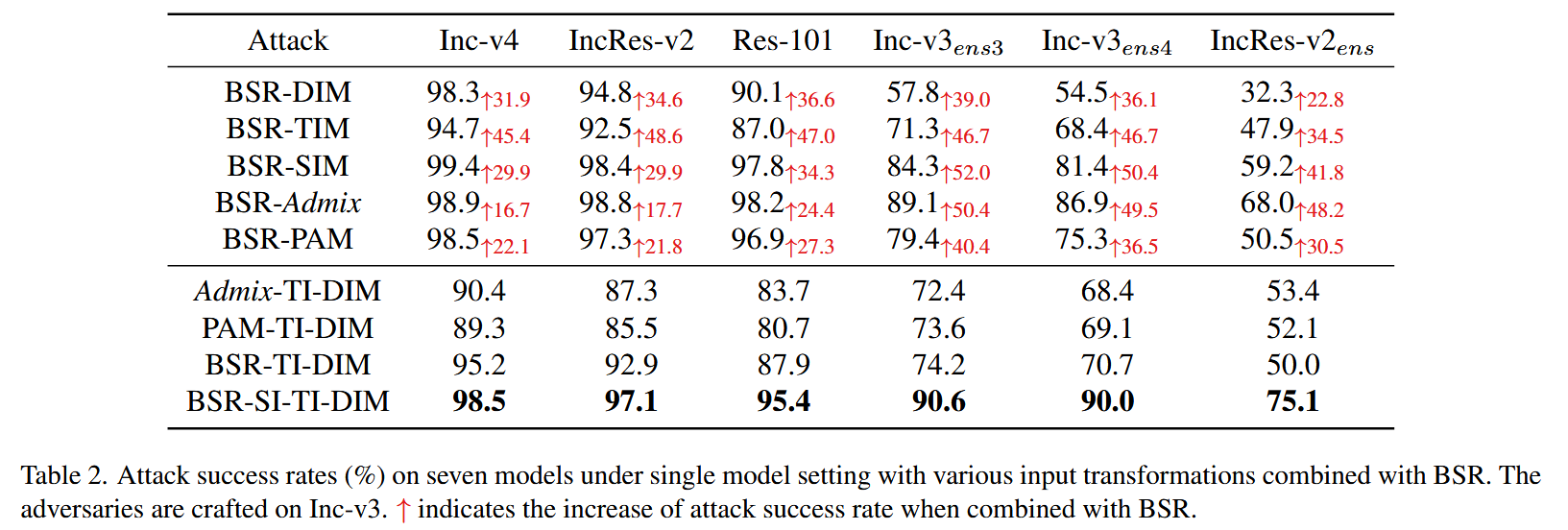
表2. 在单模型设置下,采用各种与块打乱和旋转(BSR)相结合的输入变换在七个模型上的攻击成功率(%)。对抗样本基于Inception - v3(Inc - v3)生成。↑ 表示与 BSR 结合时攻击成功率的提升情况.
集成模型评估-Evaluation on Ensemble Model
- 实验背景与设置
- 背景:Liu等人首次提出集成攻击,通过同时攻击多个模型来提高对抗迁移性。本实验旨在评估 BSR 与集成攻击的兼容性,进一步探究BSR在集成模型设置下的性能表现。
- 设置:按照 MI - FGSM 的设置,在四个标准训练模型(Inception - v3、Inception - v4、Inception - Resnet - v3、Resnet - v2 - 101)上生成对抗样本,然后将这些对抗样本在三个集成对抗训练模型(Inc - v3 e n s 3 _{ens3} ens3、Inc - v3 e n s 4 _{ens4} ens4、IncRes - v2 e n s 2 _{ens2} ens2)上进行测试。实验评估了单一输入变换方法以及 BSR 与现有输入变换方法组合后的攻击性能。
- 实验结果分析
- 各方法在集成模型下的表现:在集成模型设置下,PAM 在白盒攻击能力方面表现出色,在对抗训练模型上显著优于其他基线方法,领先幅度至少为0.7%。
- BSR的优势体现:然而,BSR 在这些对抗训练模型上始终优于 PAM,领先幅度为6.3% - 8.1%,并且与 Admix 的白盒攻击性能相当。例如,BSR 在某些对抗训练模型上的攻击成功率比 PAM 高出8.1%。特别地,BSR - SI - TI - DIM在对抗训练模型上的平均攻击成功率达到98.4%,比 PAM - TI - DIM 高出至少3.1%。这一卓越的攻击性能再次验证了 BSR 在提高对抗迁移性方面的显著效果,表明 BSR 在集成模型设置下具有强大的攻击能力,对安全关键应用构成巨大威胁,也为对抗攻击在集成模型场景下的研究提供了重要参考,突出了 BSR 在该场景中的优势和价值。
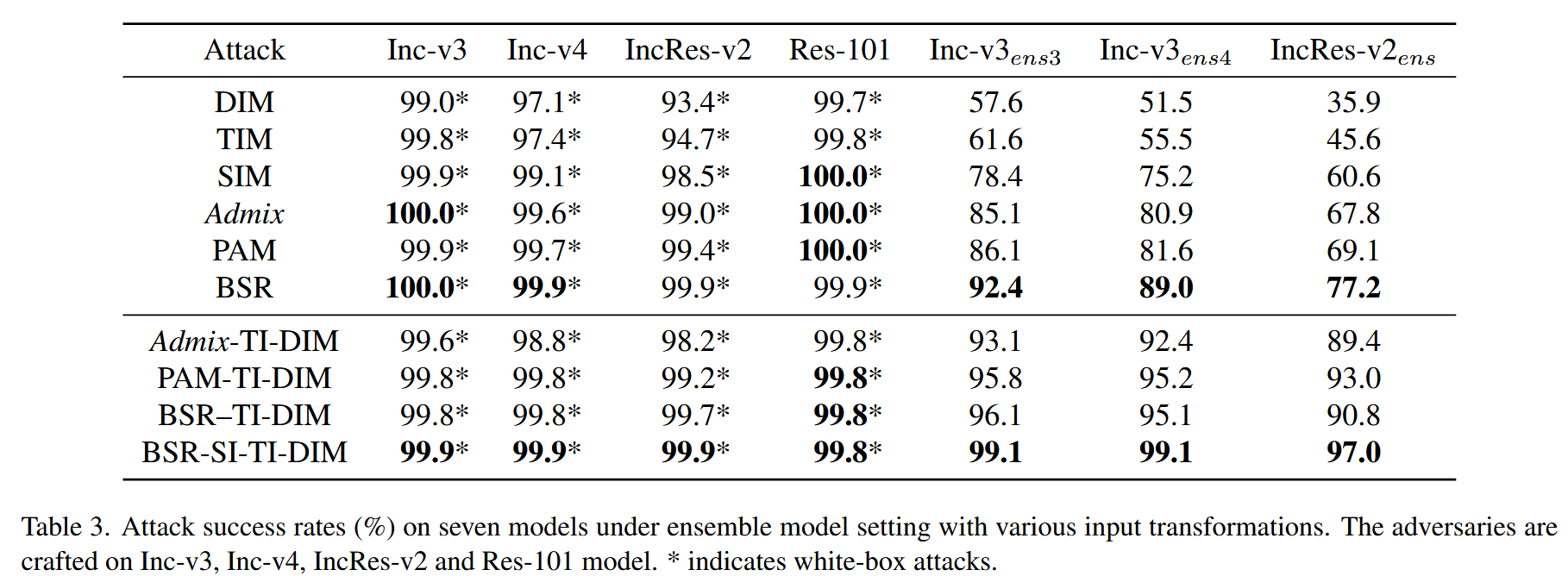
表3. 在集成模型设置下,采用各种输入变换在七个模型上的攻击成功率(%)。对抗样本基于Inception - v3(Inc - v3)、Inception - v4(Inc - v4)、Inception - Resnet - v2(IncRes - v2)以及Resnet - v2 - 101(Res - 101)模型生成。
∗
*
∗ 表示白盒攻击.
防御方法评估-Evaluation on Defense Method
- 实验目的与设置:
- 目的:为了全面评估 BSR 方法的有效性,本部分实验聚焦于探究BSR生成的对抗样本对现有先进防御模型的突破能力,以此来进一步衡量BSR在实际对抗场景中的性能表现。
- 设置:选取了多种先进的防御模型,包括 HGD、R&P、NIPS - r31、BitRD、JPEG、FD、RS 以及 NRP 等,将基于 BSR 方法生成的对抗样本应用于这些防御模型,通过对比不同输入变换方法生成的对抗样本在各防御模型上的攻击成功率,来考察BSR的防御突破能力。
- 实验结果与分析:
- 总体突破能力对比:实验结果显示,在面对这些防御模型时,BSR 生成的对抗样本相较于其他基于输入变换的攻击方法(如 DIM、TIM、SIM、Admix、PAM 等)具有更强的突破能力,其攻击成功率普遍更高,这体现出BSR在突破现有防御方面的优势。
- 各防御模型情况:例如在针对 HGD 防御模型时,BSR 的攻击成功率高于其他对比方法;对于 R&P、NIPS - r31 等其他防御模型,同样能看到 BSR 展现出更好的突破效果,能够更有效地绕过这些防御机制,让防御模型出现误判等情况。这表明 BSR 生成的对抗样本具有较强的隐蔽性和攻击性,即便面对当前较为先进的防御手段,依然能保持较好的攻击性能,进一步证实了 BSR 方法在提升对抗迁移性以及实际对抗应用中的有效性和强大竞争力,凸显了其在对抗攻击领域的重要价值。
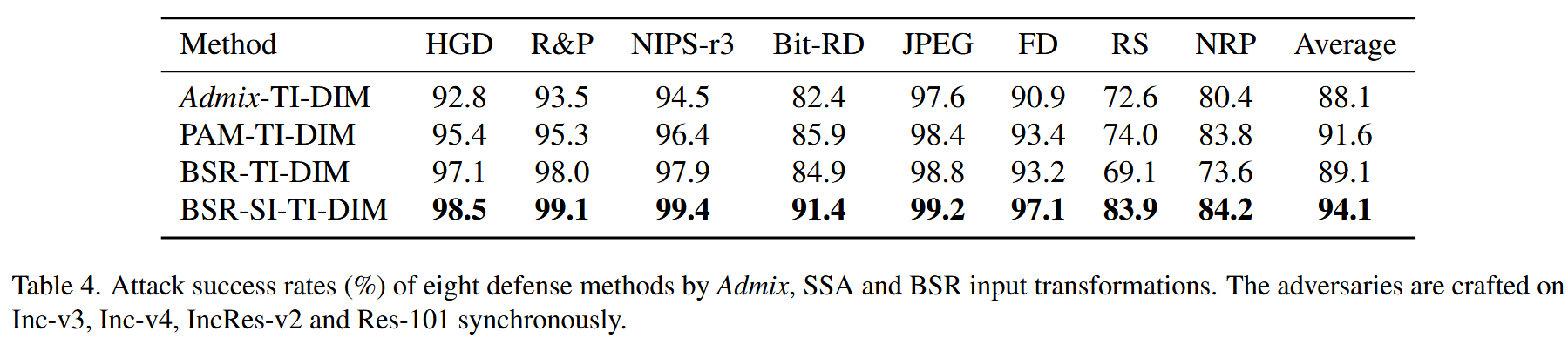
表4. 采用Admix、SSA和块打乱和旋转(BSR)输入变换的八种防御方法的攻击成功率(%)。对抗样本同步基于Inception - v3(Inc - v3)、Inception - v4(Inc - v4)、Inception - Resnet - v2(IncRes - v2)以及Resnet - v2 - 101(Res - 101)生成.
消融研究-Abalation Study
为了深入了解BSR性能提升的原因,通过在Inception-v3上生成对抗样本并在其他六个模型上进行评估,进行了消融和超参数研究,包括以下内容:
- 打乱和旋转的有效性
- 实验设置:将图像分割成若干块后,进行块打乱(BS)和块旋转(BR)操作,并与BSR进行对比,探究打乱和旋转对提升迁移性的有效性。
- 实验结果:BS 和 BR 比 MI-FGSM 具有更好的迁移性,证明了在具有不同注意力热图的输入图像上优化对抗扰动可消除热图间差异以提升迁移性。BSR 结合了 BS 和 BR,表现出最佳的迁移性,显示了其在生成可迁移对抗样本方面的合理性和高效性。
- 块数量n的影响
- 实验设置:研究不同块数量 n n n 对 BSR 性能的影响, n n n 取值从1开始变化,观察迁移性的变化趋势。
- 实验结果:当 n = 1 n = 1 n=1 时,BSR 仅旋转原始图像,无法干扰注意力热图,迁移性最差。当 n > 3 n>3 n>3 时,增加 n n n 会导致过多无法有效消除的差异,降低迁移性。因此,适当的干扰程度对提高迁移性很重要,实验中设置 n = 2 n = 2 n=2.
- 变换图像数量N的影响
- 实验设置:由于BSR在破坏内在关系时引入了差异,采用N个变换图像的平均梯度来消除这种差异,研究不同N值对攻击性能的影响。
- 实验结果:当 N = 5 N = 5 N=5 时,BSR 已经比 MI-FGSM 具有更好的迁移性,显示了其高效性。随着 N N N 增加,攻击性能进一步提高,当 N > 20 N>20 N>20 时趋于稳定。因此,实验中设置 N = 20 N = 20 N=20。
- 旋转角度范围T的影响
- 实验设置:图像块随机旋转角度范围为 − τ ≤ β ≤ τ -\tau \leq \beta \leq \tau −τ≤β≤τ,研究不同旋转角度对图像干扰程度及性能的影响,实验中角度从 τ = 6 ∘ \tau = 6^{\circ} τ=6∘ 到 τ = 18 0 ∘ \tau = 180^{\circ} τ=180∘ 变化。
- 实验结果:当 τ \tau τ 小于 2 4 ∘ 24^{\circ} 24∘ 时,增加T会对图像造成更多干扰,从而实现更好的迁移性。若继续增加 T T T,旋转会引入过多干扰,导致性能下降。因此,实验中设置 τ = 2 4 ∘ \tau = 24^{\circ} τ=24∘.
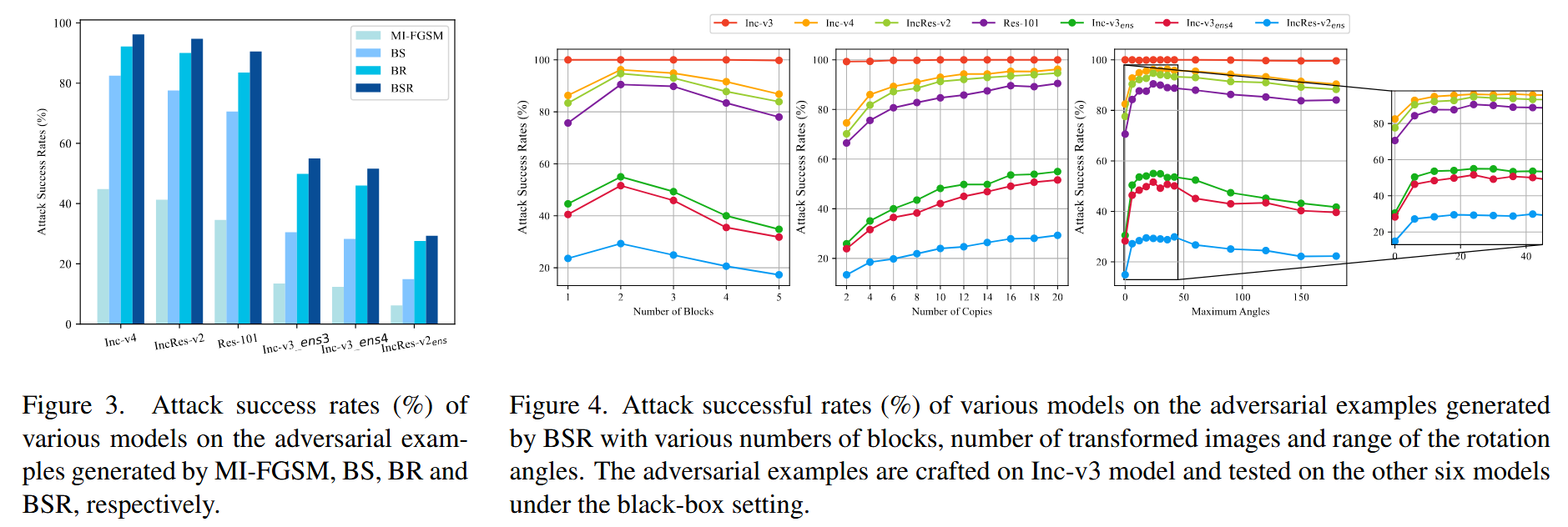
图3. 各种模型在分别由MI - FGSM、BS、BR和BSR生成的对抗样本上的攻击成功率(%).
图4. 不同模型在由具有不同块数量、变换图像数量和旋转角度范围的BSR生成的对抗样本上的攻击成功率(%)。对抗样本在Inception - v3模型上生成,并在黑盒设置下在其他六个模型上进行测试.
结论-Conclusion
直观上,对抗样本在不同模型上具有一致的注意力热图会有更好的迁移性,但现有基于输入变换的攻击常导致不同模型上注意力热图不一致,限制了迁移性。为此,本文提出了基于输入变换的攻击方法——块打乱和旋转(BSR),它通过在具有不同注意力热图的变换图像上优化扰动,消除了不同模型上注意力热图的差异。在ImageNet数据集上的实验表明,BSR 在各种攻击设置下比现有方法具有更好的迁移性,为通过生成在不同模型上具有更稳定注意力热图的对抗样本来提高迁移性提供了新思路。


















 1329
1329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











