







Improving Adversarial Transferability via Neuron Attribution-based Attacks
本文 “Improving Adversarial Transferability via Neuron Attribution-based Attacks” 提出神经元归因攻击(NAA)方法,通过更准确的神经元重要性估计进行特征级攻击,以提高对抗样本的可迁移性,实验证明该方法优于现有基准方法。
摘要-Abstract
Deep neural networks (DNNs) are known to be vulnerable to adversarial examples. It is thus imperative to devise effective attack algorithms to identify the deficiencies of DNNs beforehand in security-sensitive applications. To efficiently tackle the black-box setting where the target model’s particulars are unknown, feature-level transfer-based attacks propose to contaminate the intermediate feature outputs of local models, and then directly employ the crafted adversarial samples to attack the target model. Due to the transferability of features, feature-level attacks have shown promise in synthesizing more transferable adversarial samples. However, existing feature-level attacks generally employ inaccurate neuron importance estimations, which deteriorates their transferability. To overcome such pitfalls, in this paper, we propose the Neuron Attribution-based Attack (NAA), which conducts feature-level attacks with more accurate neuron importance estimations. Specifically, we first completely attribute a model’s output to each neuron in a middle layer. We then derive an approximation scheme of neuron attribution to tremendously reduce the computation overhead. Finally, we weight neurons based on their attribution results and launch feature-level attacks. Extensive experiments confirm the superiority of our approach to the state-of-the-art benchmarks.
众所周知,深度神经网络(DNNs)容易受到对抗样本的攻击。因此,在对安全敏感的应用中,设计有效的攻击算法以预先识别深度神经网络的缺陷势在必行。为了有效地应对目标模型具体信息未知的黑盒场景,基于特征级迁移的攻击方法建议对本地模型的中间特征输出进行干扰,然后直接使用生成的对抗样本攻击目标模型。由于特征的可迁移性,特征级攻击在合成更具可迁移性的对抗样本方面展现出了潜力。然而,现有的特征级攻击通常采用不准确的神经元重要性估计方法,这降低了它们的可迁移性。为了克服这些缺陷,在本文中,我们提出了基于神经元归因的攻击(NAA)方法,该方法通过更准确的神经元重要性估计来进行特征级攻击。具体来说,我们首先将模型的输出完全归因于中间层的每个神经元。然后,我们推导出一种神经元归因的近似方案,以极大地减少计算开销。最后,我们根据神经元的归因结果对其进行加权,并发起特征级攻击。 大量实验证实了我们的方法相对于当前最先进基准方法的优越性。
引言-Introduction
该部分主要阐述研究背景与动机,强调深度神经网络(DNNs)在安全关键领域应用广泛但易受对抗攻击,引出对有效攻击算法的需求。具体内容如下:
- 研究背景:DNNs在自动驾驶、医疗诊断等安全关键领域应用广泛,但易受对抗攻击。攻击者在干净图像上添加人眼不可察觉的扰动,误导DNN做出错误判断。因此,设计有效攻击算法识别DNN缺陷,对提升其安全性至关重要。
- 对抗攻击分类:分为白盒攻击和黑盒攻击。白盒攻击能获取目标模型结构和参数来生成对抗样本;黑盒攻击无法获取这些信息,更符合现实应用场景,本文重点研究黑盒攻击。
- 黑盒攻击方法:主要有基于查询和基于迁移两种。基于查询的方法通过查询近似梯度信息生成对抗样本,但实际中大量查询不被允许,实用性差。基于迁移的攻击利用白盒攻击先攻击本地代理模型,再将生成的对抗样本迁移到目标模型。其中,特征级迁移攻击通过破坏本地模型中间特征图生成对抗样本,因其利用了不同DNN模型共享关键特征的特性,在缓解过拟合和合成可迁移对抗样本方面有潜力。
- 现有问题与解决方法:现有特征级攻击因依赖不准确的神经元重要性度量,可迁移性受限。如NRDM将所有神经元视为重要神经元,同时破坏正负特征;FDA虽区分神经元重要性极性,但对同符号神经元同等看待;FIA测量神经元重要性时,原输入的反向传播梯度存在饱和问题。为解决这些问题,本文提出NAA,基于更准确的神经元重要性度量进行特征级攻击。先将模型输出完全归因于中间层神经元,再推导近似方案降低计算成本,最后根据归因结果加权神经元发起攻击。
- 研究贡献:一是利用神经元归因更好地度量神经元重要性,设计NAA克服现有特征级攻击缺陷,提升对抗样本可迁移性;二是设计神经元归因近似方法,大幅降低时间消耗,提高攻击效率;三是通过综合实验验证了方法的有效性和高效性,在攻击未防御和防御模型时均达到了最优性能。

图1. 良性图像以及由我们的方法生成的对抗图像上的模型注意力可视化结果。与良性图像相比,源模型和目标模型在对抗图像上的注意力都发生了显著变化。
相关工作-Related Work
该部分主要介绍了对抗攻击和对抗防御两方面的相关研究工作,为后续提出的基于神经元归因的攻击(NAA)方法做了铺垫,具体内容如下:
- 对抗攻击
- 攻击分类:对抗攻击分为白盒攻击和黑盒攻击。白盒攻击下攻击者可获取模型结构和参数信息,如利用梯度信息的FGSM、I-FGSM等方法,但在实际应用中模型信息通常是隐藏的,白盒攻击不现实。因此,黑盒对抗攻击更具研究意义,本文主要关注基于迁移的黑盒对抗攻击。
- 基于迁移的黑盒攻击:利用源模型生成的对抗样本对其他模型的误导能力进行攻击。许多研究致力于提高对抗样本的可迁移性,如采用高级梯度方法(MIM、NIM)和输入变换方法(DIM、PIM等)。此外,一些研究关注模型内部层,如TAP、NRDM等方法通过在特征图上操作增强对抗样本可迁移性,ILA对现有对抗样本微调,FDA通过破坏目标层特征引入新攻击方法,FIA通过计算激活值与反向传播梯度的乘积衡量神经元重要性,但这些方法在神经元重要性测量上存在不足,本文的NAA方法则利用神经元归因更准确地反映神经元对输出的影响。
- 对抗防御:对抗防御对于减轻对抗攻击威胁十分重要,主要有对抗训练和去噪两类。对抗训练通过将对抗样本加入训练数据重新训练模型来提高模型的鲁棒性,如集成对抗训练利用从多个模型迁移的对抗样本进行防御。去噪则是在数据输入模型前通过预处理机制过滤对抗扰动,使模型能正确分类处理后的图像且不降低性能。文中列举了多种先进防御方法,如利用高级表示引导去噪器、随机调整大小和填充、基于JPEG的防御压缩框架等,这些方法用于验证本文攻击方法对先进防御模型的有效性。
方法-Approach
该部分详细介绍了基于神经元归因的攻击(NAA)方法,包括神经元归因的定义、近似计算方法以及NAA算法的具体实现,具体内容如下:
- 神经元归因:特征级攻击旨在破坏正特征或扩大负特征来生成对抗样本,关键在于衡量神经元重要性。受相关研究启发,定义输入图像
x
x
x 相对于基线图像
x
′
x'
x′ 的归因
A
A
A,公式为
A
:
=
∑
i
=
1
N
2
(
x
i
−
x
i
′
)
∫
0
1
∂
F
∂
x
i
(
x
′
+
α
(
x
−
x
′
)
)
d
α
A:=\sum_{i=1}^{N^{2}}\left(x_{i}-x_{i}'\right) \int_{0}^{1} \frac{\partial F}{\partial x_{i}}\left(x'+\alpha\left(x-x'\right)\right) d \alpha
A:=∑i=1N2(xi−xi′)∫01∂xi∂F(x′+α(x−x′))dα,其中
N
×
N
N×N
N×N 为图像像素数,
∂
F
∂
x
i
(
⋅
)
\frac{\partial F}{\partial x_{i}}(\cdot)
∂xi∂F(⋅) 是
F
F
F 对第
i
i
i 像素的偏导数。
当 F ( x ′ ) ≈ 0 F(x') ≈0 F(x′)≈0 时, A ≈ F ( x ) A ≈F(x) A≈F(x),实际中常用黑色图像作为基线。进一步将 A A A 归因到某一层 y y y 的每个神经元 y j y_{j} yj,令 x α = x ′ + α ( x − x ′ ) x_{\alpha}=x'+\alpha\left(x-x'\right) xα=x′+α(x−x′),其归因 A y j = ∑ i = 1 N 2 ( x i − x i ′ ) ∫ 0 1 ∂ F ∂ y j ( y ( x α ) ) ∂ y j ∂ x i ( x α ) d α A_{y_{j}}=\sum_{i=1}^{N^{2}}\left(x_{i}-x_{i}'\right) \int_{0}^{1} \frac{\partial F}{\partial y_{j}}\left(y\left(x_{\alpha}\right)\right) \frac{\partial y_{j}}{\partial x_{i}}\left(x_{\alpha}\right) d \alpha Ayj=∑i=1N2(xi−xi′)∫01∂yj∂F(y(xα))∂xi∂yj(xα)dα ,且 ∑ y j ∈ y A y j = A \sum_{y_{j} \in y} A_{y_{j}}=A ∑yj∈yAyj=A,反映神经元对输出的真实影响。
实际计算时,沿直线采样 n n n 个虚拟图像,用黎曼和近似积分得到 A y j ≈ 1 n ∑ m = 1 n ( ∂ F ∂ y j ( y ( x m ) ) ) ( ∑ i = 1 N 2 ( x i − x i ′ ) ∂ y j ∂ x i ( x m ) ) A_{y_{j}} \approx \frac{1}{n} \sum_{m=1}^{n}\left(\frac{\partial F}{\partial y_{j}}\left(y\left(x_{m}\right)\right)\right)\left(\sum_{i=1}^{N^{2}}\left(x_{i}-x_{i}'\right) \frac{\partial y_{j}}{\partial x_{i}}\left(x_{m}\right)\right) Ayj≈n1∑m=1n(∂yj∂F(y(xm)))(∑i=1N2(xi−xi′)∂xi∂yj(xm)) 。 - 近似方法:直接计算神经元归因
A
y
j
A_{y_{j}}
Ayj 的计算成本极高,因为要计算每个神经元的
∂
y
j
∂
x
i
\frac{\partial y_{j}}{\partial x_{i}}
∂xi∂yj。基于大多数传统DNN模型中,
∂
F
∂
y
j
(
y
(
x
m
)
)
\frac{\partial F}{\partial y_{j}}(y(x_{m}))
∂yj∂F(y(xm))(与
y
y
y 层后网络相关)和
∑
i
=
1
N
2
(
x
i
−
x
i
′
)
∂
y
j
∂
x
i
(
x
m
)
\sum_{i=1}^{N^{2}}(x_{i}-x_{i}') \frac{\partial y_{j}}{\partial x_{i}}(x_{m})
∑i=1N2(xi−xi′)∂xi∂yj(xm)(与网络前层相关)线性独立的假设,对公式进行简化。
最终得到更简单的形式 A y j ≈ Δ y j ⋅ I A ( y j ) A_{y_{j}} ≈\Delta y_{j} \cdot IA(y_{j}) Ayj≈Δyj⋅IA(yj) ,其中 Δ y j = y j − y j ′ \Delta y_{j}=y_{j}-y_{j}' Δyj=yj−yj′ 为相对激活, I A ( y j ) = 1 n ∑ m = 1 n ∂ F ∂ y j ( y ( x m ) ) IA(y_{j})=\frac{1}{n} \sum_{m=1}^{n} \frac{\partial F}{\partial y_{j}}(y(x_{m})) IA(yj)=n1∑m=1n∂yj∂F(y(xm)) 为集成注意力。该近似将神经元归因计算复杂度从 O ( H ∗ W ∗ C ) O(H * W * C) O(H∗W∗C) 降为 O ( 1 ) O(1) O(1) ,显著节省计算时间。 - NAA算法:通过最小化所有神经元对输出的总归因,可抑制正归因并扩大负归因。考虑同一层
y
y
y 中所有神经元的归因
A
y
=
∑
y
j
∈
y
A
y
j
=
∑
y
j
∈
y
Δ
y
j
⋅
I
A
(
y
j
)
=
(
y
−
y
′
)
⋅
I
A
(
y
)
A_{y}=\sum_{y_{j} \in y} A_{y_{j}}=\sum_{y_{j} \in y} \Delta y_{j} \cdot IA\left(y_{j}\right)=\left(y-y'\right) \cdot IA(y)
Ay=∑yj∈yAyj=∑yj∈yΔyj⋅IA(yj)=(y−y′)⋅IA(y) 。
为平衡正负归因影响并区分不同值神经元归因的显著程度,引入超参数 γ \gamma γ 和正负归因变换函数 f p ( A y j ) f_{p}(A_{y_{j}}) fp(Ayj)、 − f n ( − A y j ) -f_{n}(-A_{y_{j}}) −fn(−Ayj) ,计算目标层 y y y 所有神经元的加权归因 W A y = ∑ A y j ≥ 0 y j ∈ y f p ( A y j ) − γ ⋅ ∑ A y j < 0 y j ∈ y f n ( − A y j ) WA_{y}=\sum_{\substack{A_{y_{j}} \geq 0 \\ y_{j} \in y}} f_{p}\left(A_{y_{j}}\right)-\gamma \cdot \sum_{\substack{A_{y_{j}}<0 \\ y_{j} \in y}} f_{n}\left(-A_{y_{j}}\right) WAy=∑Ayj≥0yj∈yfp(Ayj)−γ⋅∑Ayj<0yj∈yfn(−Ayj) 。
NAA的目标是求解约束最小化问题 m i n x a d v W A y s . t . ∥ x − x a d v ∥ ∞ < ϵ min _{x^{a d v}} WA_{y} \ \ \ s.t. \left\| x-x^{a d v}\right\| _{\infty}<\epsilon minxadvWAy s.t. x−xadv ∞<ϵ ,利用MIM算法求解,具体过程见算法1。

实验-Experiments
这部分主要通过一系列实验评估基于神经元归因的攻击(NAA)方法的有效性,包括实验设置、攻击结果分析以及消融研究,具体内容如下:
- 实验设置
- 数据集:从ILSVRC 2012验证集中随机抽取1000张不同类别的图像,确保攻击模型的分类成功率接近100%。
- 模型:选取Inception-v3、Inception-v4、Inception-Resnet-v2和Resnet-v2-152作为源模型,同时考虑未防御模型和防御模型(对抗训练和采用先进防御技术的模型)作为目标模型。防御模型包括对抗训练的Inception-v3、Inception-Resnet-v2,以及多个集成模型,还选用了7种先进防御方法的模型。
- 基线方法:选择基于梯度的迭代对抗攻击方法MIM作为基线,同时选取NRDM、FDA和FIA这三种特征级对抗攻击方法作为竞争基线。将所有方法与DIM和PIM两种输入变换方法结合,进一步验证NAA的优越性,分别表示为NAA-PD、MIM-PD、NRDM-PD、FDA-PD和FIA-PD。
- 评估指标:以攻击成功率衡量攻击性能,即成功误导目标模型的对抗样本在所有生成对抗样本中的比例。
- 参数设置:为保证公平比较,遵循相关研究设置最大扰动 ϵ = 16 \epsilon = 16 ϵ=16、迭代次数 T = 10 T = 10 T=10 、步长 α = ϵ T = 1.6 \alpha=\frac{\epsilon}{T}=1.6 α=Tϵ=1.6 ,所有基线方法的衰减因子 μ = 1.0 \mu = 1.0 μ=1.0 。对于输入变换方法,DIM的变换概率设为0.7,PIM的放大因子设为2.5、内核大小设为3。NAA方法中,选择中间层作为目标层,并根据前人研究实现集成注意力,初始设置 γ = 1 \gamma = 1 γ=1 且变换函数为线性函数。
- 攻击结果
-
对未防御模型的攻击:在白盒设置下,NAA攻击准确率接近100%;在黑盒设置下,NAA优于所有基线方法,虽然其白盒攻击成功率与FIA相近且略低于MIM,但黑盒攻击成功率更高,表明NAA的对抗样本可迁移性更强。
-
对对抗训练模型的攻击:NAA在所有设置下均大幅优于基线方法,攻击成功率平均高出10.5%,再次证明其对对抗训练模型的强大攻击能力和高可迁移性。
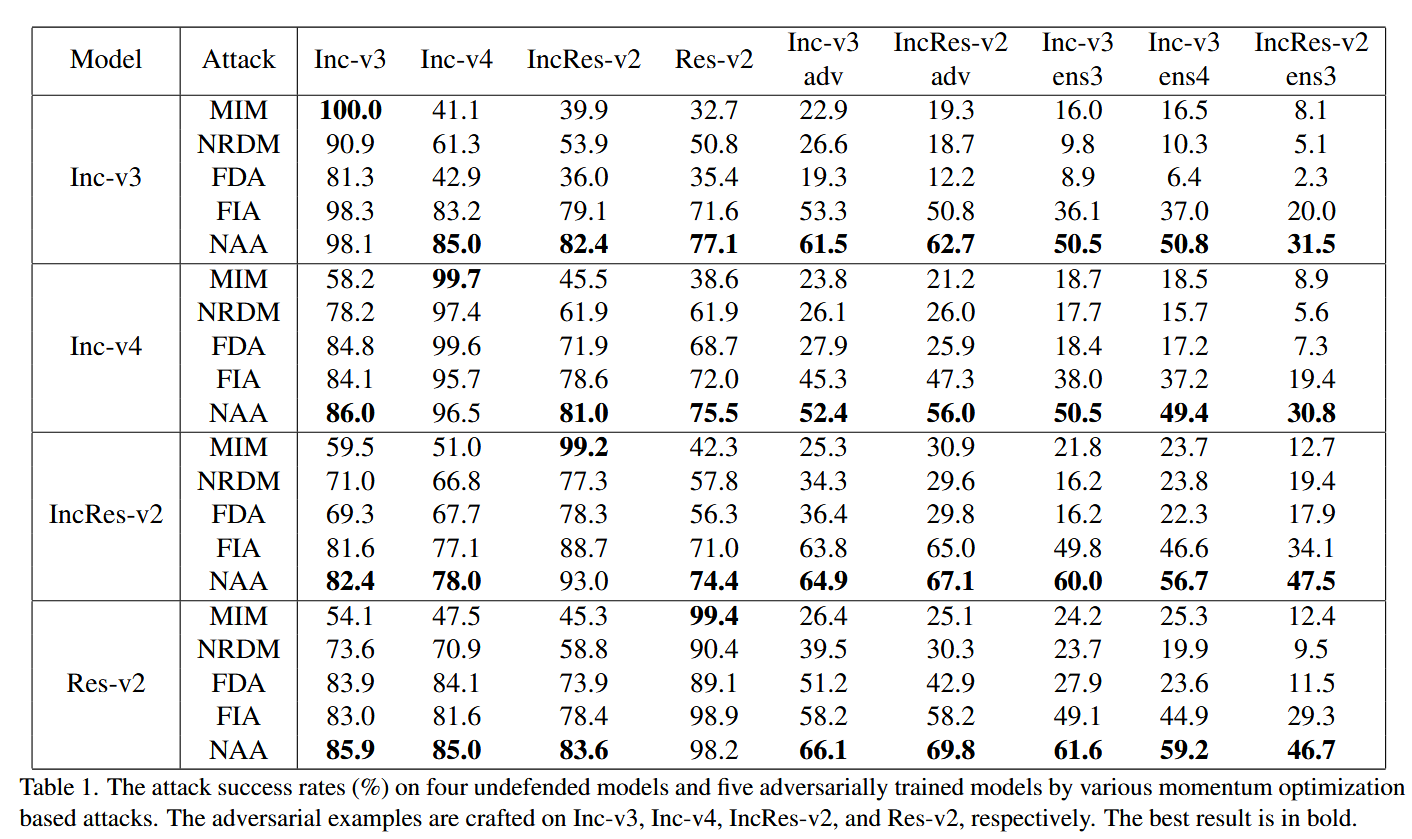
表1. 各种基于动量优化的攻击方法对四个未防御模型和五个对抗训练模型的攻击成功率(%)。对抗样本分别在Inception-v3(Inc-v3)、Inception-v4(Inc-v4)、Inception-Resnet-v2(IncRes-v2)和Resnet-v2上生成。最佳结果以粗体显示。 -
结合输入变换方法的攻击:所有攻击方法结合PIM和DIM后,NAA-PD在黑盒设置下平均攻击成功率比基线方法高出10.7%,进一步凸显NAA的优势。
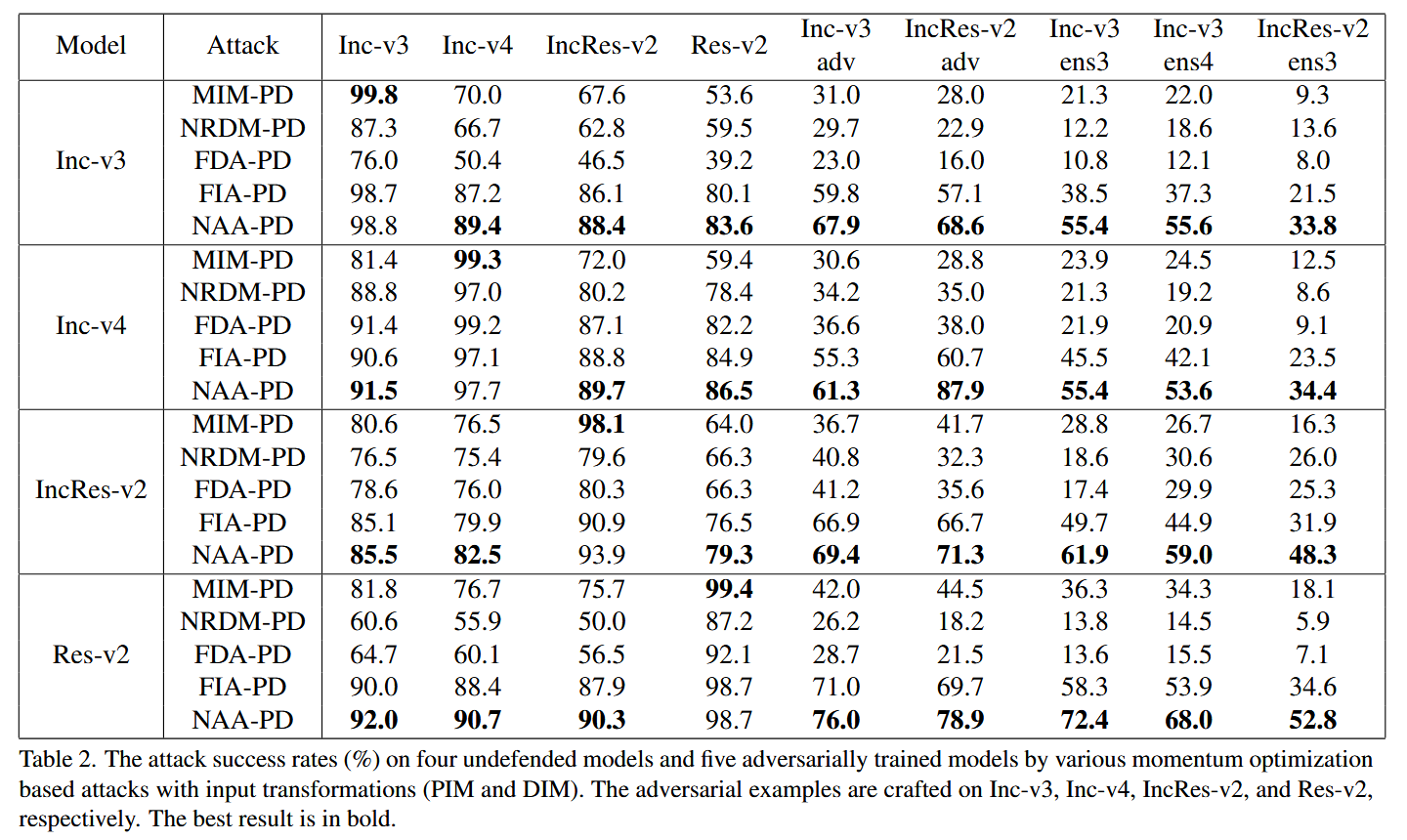
图2. 不同目标层设置下NAA的攻击成功率(%)。 -
对先进防御模型的攻击:以Inc-v3为源模型生成对抗样本,在7种先进防御模型上测试。NAA-PD平均攻击成功率达57.9% ,比所有基线方法高出至少5.9%,对先进防御方法构成较大威胁。
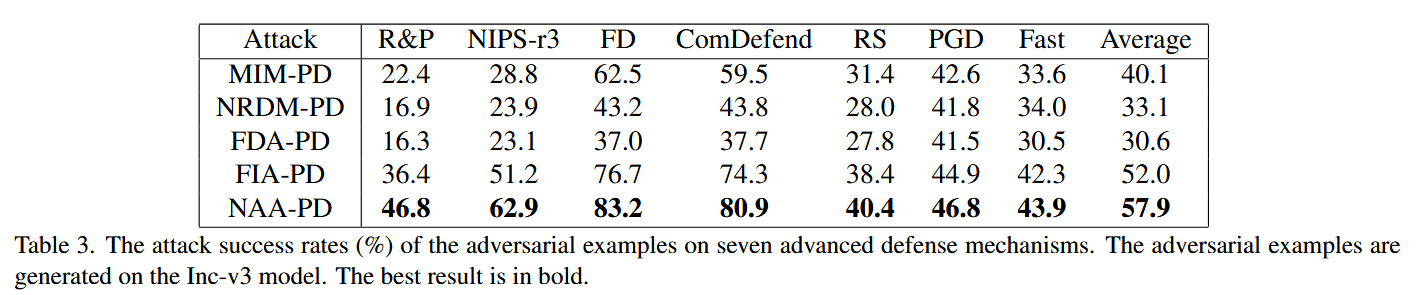
表3. 在七种先进防御机制上对抗样本的攻击成功率(%)。这些对抗样本是在Inception-v3(Inc-v3)模型上生成的。最佳结果以粗体显示。
-
- 消融研究
- 目标特征图层:以Inc-v3为源模型,在不同目标层使用NAA生成对抗样本。结果显示,攻击深层在白盒攻击中性能最佳,但攻击中间层在可迁移性方面表现更优,因为浅层特征对输出影响小,深层特征易使对抗样本过拟合源模型,中间层特征综合性能最好。
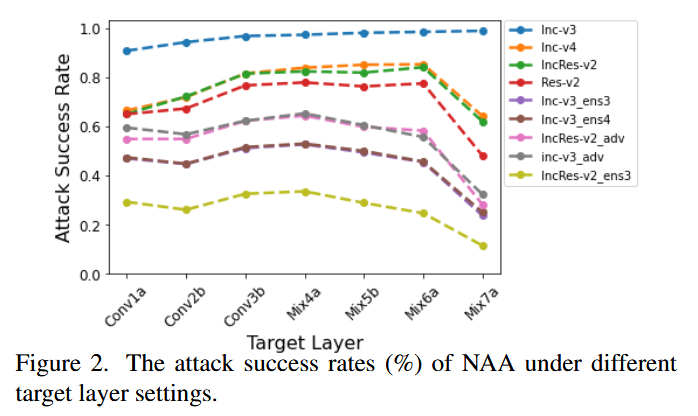
图2. 不同目标层设置下NAA的攻击成功率(%)。 - 集成步数:通过改变Inc-v3模型生成对抗样本的集成步数发现,集成步数增加时可迁移性提升,但计算成本也随之增加。综合考虑性能和计算成本,选择
n
=
30
n = 30
n=30 。
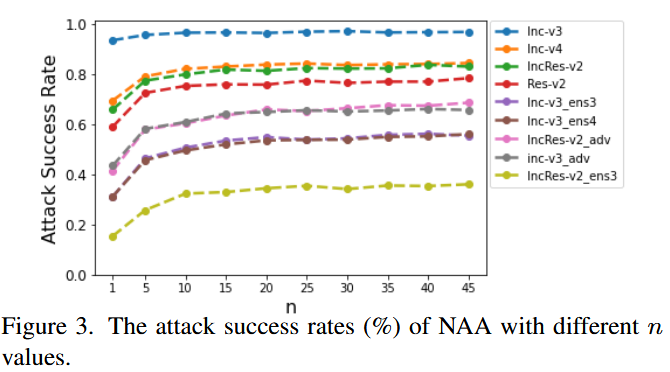
图3. 不同 n n n 值下基于神经元归因的攻击(NAA)的攻击成功率(%)。
- 目标特征图层:以Inc-v3为源模型,在不同目标层使用NAA生成对抗样本。结果显示,攻击深层在白盒攻击中性能最佳,但攻击中间层在可迁移性方面表现更优,因为浅层特征对输出影响小,深层特征易使对抗样本过拟合源模型,中间层特征综合性能最好。
不过原句中“KaTeX parse error: Expected 'EOF', got '#' at position 1: #̲##”可能是文档中存在错误或未完整显示的内容,如果有更准确的信息,可以随时告诉我,以便更精准翻译。
- 加权归因:研究神经元归因极性和值的重要性。改变
γ
\gamma
γ值发现,
γ
=
1
\gamma = 1
γ=1时攻击成功率最高,说明正负归因同样重要;尝试不同变换函数后,线性函数组合的攻击效果最佳,表明不同值的神经元归因重要性相同,应同等对待。
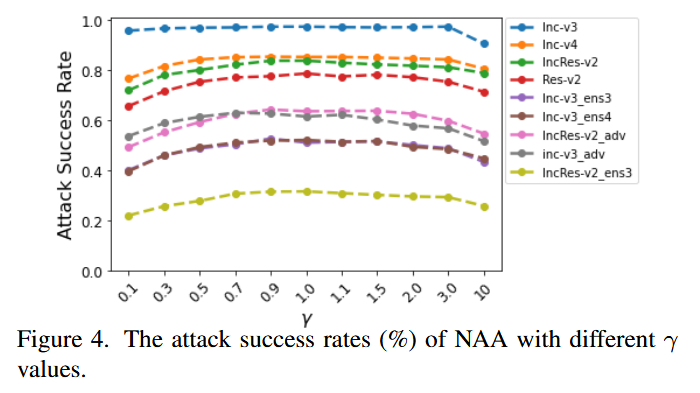
图4. 不同
γ
γ
γ 值下NAA的攻击成功率(%)。

图5. 不同变换函数组合下,未防御模型和对抗训练模型的平均攻击成功率热力图。
结论-Conclusion
本文提出基于神经元归因的攻击(NAA)方法来生成可迁移的对抗样本。首先利用神经元归因更精确地评估神经元重要性,为降低计算时间,推导出神经元归因的近似方案。最后,通过最小化正负神经元归因值的加权组合生成对抗样本。实验结果证实,该方法相较于当前最先进的基线方法,在性能上有显著优势,能有效提升对抗样本的可迁移性,对深度神经网络的安全性研究具有重要意义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











