







Scale-Invariant Adversarial Attack against Arbitrary-scale Super-resolution
本文 “Scale-Invariant Adversarial Attack against Arbitrary-scale Super-resolution” 提出了一种针对任意尺度超分辨率(SR)的尺度不变对抗攻击方法 SIAGT,旨在评估基于连续表示的任意尺度 SR 方法的鲁棒性,同时探讨了该攻击方法在版权保护等实际场景中的应用潜力。
摘要-Abstract
The advent of local continuous image function (LIIF) has garnered significant attention for arbitrary-scale super-resolution (SR) techniques. However, while the vulnerabilities of fixed-scale SR have been assessed, the robustness of continuous representation-based arbitrary-scale SR against adversarial attacks remains an area warranting further exploration. The elaborately designed adversarial attacks for fixed-scale SR are scale-dependent, which will cause time-consuming and memory-consuming problems when applied to arbitrary-scale SR. To address this concern, we propose a simple yet effective “scale-invariant” SR adversarial attack method with good transferability, termed SIAGT. Specifically, we propose to construct resource-saving attacks by exploiting finite discrete points of continuous representation. In addition, we formulate a coordinate-dependent loss to enhance the cross-model transferability of the attack. The attack can significantly deteriorate the SR images while introducing imperceptible distortion to the targeted low-resolution (LR) images. Experiments carried out on three popular LIIF-based SR approaches and four classical SR datasets show remarkable attack performance and transferability of SIAGT.
局部连续图像函数(LIIF)的出现,使得任意尺度超分辨率(SR)技术备受关注。然而,尽管固定尺度超分辨率的脆弱性已得到评估,但基于连续表示的任意尺度超分辨率在对抗攻击下的稳健性仍有待进一步探索。为固定尺度超分辨率精心设计的对抗攻击是依赖尺度的,将其应用于任意尺度超分辨率时会导致耗时和耗内存的问题。为解决这一问题,我们提出了一种简单而有效的、具有良好迁移性的 “尺度不变” 超分辨率对抗攻击方法,称为 SIAGT。具体而言,我们建议通过利用连续表示的有限离散点来构建节省资源的攻击。此外,我们制定了一种坐标相关损失,以增强攻击的跨模型迁移性。这种攻击可以在对目标低分辨率(LR)图像引入难以察觉的失真的同时,显著降低超分辨率图像的质量。在三种流行的基于 LIIF 的超分辨率方法和四个经典超分辨率数据集上进行的实验,展示了 SIAGT卓越的攻击性能和转移性。
引言-Introduction
图像超分辨率旨在从低分辨率图像重建高分辨率图像,分为固定尺度和任意尺度超分辨率两类。本部分主要阐述了研究背景、问题以及提出的解决方案,具体内容如下:
- 研究背景:固定尺度超分辨率需为每个缩放因子单独训练模型,限制了应用;而基于学习连续表示的任意尺度超分辨率,凭借单一网络就能以连续方式恢复图像,成为当前研究热点。评估超分辨率模型的脆弱性对开发更可靠的模型至关重要,对抗攻击是评估深度神经网络稳健性的主流方法。
- 存在问题:已有研究评估了固定尺度超分辨率模型的稳健性,但所采用的攻击方法依赖尺度,针对固定尺度超分辨率任务设计,其基于固定尺度超分辨率输出的特殊损失设计,在应用于任意尺度超分辨率方法时,不可避免地存在耗时耗内存的问题,具有明显的实际应用缺陷。
- 解决方案:提出一种简单、节省资源且有效的具有良好迁移性的尺度不变超分辨率对抗攻击方法 SIAGT,主要针对基于连续表示(受局部连续图像函数 LIIF 启发)的超分辨率方法设计。该方法的核心是基于尺度不变的连续表示设计损失,通过将连续图像划分为有限块并采样有限坐标点构建损失,同时提出坐标相关损失提高跨模型转移性。
- 研究贡献:首次提出用于评估任意尺度超分辨率方法稳健性的尺度不变对抗攻击方法;提出的坐标相关损失可稳定提升攻击在基于连续表示的超分辨率方法上的跨模型转移性;在多个模型和数据集上的实验及消融研究验证了 SIAGT 的有效性和高效性。
- 实际价值:在版权保护方面有应用潜力,可防止通过任意尺度超分辨率未经授权地恢复高质量图像,如在出版业、在线图像市场和流媒体服务中,对低分辨率预览图像进行对抗扰动嵌入,能确保超分辨率处理后的图像质量下降,保护原始图像版权。

图1:原始低分辨率图像
I
L
R
I^{LR}
ILR 与对抗图像
I
a
d
v
I^{adv}
Iadv 的超分辨率(SR)输出对比(由 LIIF 生成)。在任意尺度下,通过我们的攻击方法 SIAGT 生成的对抗图像
I
a
d
v
I^{adv}
Iadv 的超分辨率输出均出现质量下降。
相关工作-Related Work
该部分主要介绍了任意尺度超分辨率、超分辨率的对抗攻击以及跨模型迁移性三个方面的相关研究进展,为后续提出的针对任意尺度超分辨率的对抗攻击方法做了理论铺垫,具体内容如下:
- 任意尺度超分辨率:基于深度学习的固定尺度单图像超分辨率发展成熟,但大多局限于特定整数上采样尺度,需为每个尺度训练不同模型。为突破限制,研究转向任意尺度超分辨率。LIIF 首次将坐标与任意分辨率的连续图像关联,通过连续图像函数预测 RGB 值。此后,基于 LIIF 衍生出多种方法,如 UltraSR、IPE 利用位置编码改进高频信息表示;LTE 引入局部纹理估计器提升重建性能;A-LIIF 提出自适应局部隐式图像函数;CiaoSR 和 CLIT 利用注意力机制;LMF 融合潜在调制函数与神经场技术。这些方法在实际应用中展现出便利性和灵活性,也凸显了研究其对抗攻击的重要性。
- 超分辨率的对抗攻击:超分辨率在生成高质量图像和下游计算机视觉任务中至关重要,确保其稳健性意义重大。分类任务中的对抗攻击是在输入样本添加不可察觉扰动,使分类器输出错误结果。梯度下降规避攻击率先研究机器学习模型测试时的规避攻击,FGSM基于梯度生成对抗样本,但攻击成功率低。后续I-FGSM和PGD通过迭代攻击策略提升了攻击性能。在超分辨率领域,对抗攻击研究尚不全面,目前仅Choi等人对图像超分辨率的对抗攻击方法进行了初步探索,他们通过优化整个超分辨率图像输出的退化来评估固定尺度超分辨率的稳健性,但该方法应用于大规模超分辨率任务时存在时间和内存消耗问题,不适用于任意尺度超分辨率场景。
- 跨模型转移性:在白盒攻击中,需要获取模型架构和参数,其难度较大。因此提高攻击的跨模型迁移性意义重大。在图像分类领域,已有研究关注此问题,但在超分辨率任务中,由于其是像素级任务,与分类这类特征级任务存在本质区别,目前尚无研究探索提高超分辨率任务中对抗攻击的跨模型迁移性,这是一个具有创新性和挑战性的问题。
任意尺度超分辨率攻击-Attack On Arbitrary-scale Super-Resolution
预备知识-Preliminary
这部分主要介绍了任意尺度超分辨率(SR)中连续图像表示的概念,以及基于 LIIF 的 SR 方法的核心原理,为后续理解针对任意尺度SR的攻击方法奠定基础,具体内容如下:
- 连续图像表示概念:与固定尺度 SR 方法使用的离散图像表示(用像素的二维数组离散表示图像)不同,受视觉世界连续性的启发,任意尺度 SR 方法采用“连续图像表示”。该表示将图像视为一个连续函数,像素值通过相应的坐标点作为输入来计算(坐标点是连续的),用这种方式表示的图像称为连续图像。
- 基于LIIF的SR方法原理:目前基于 LIIF 的 SR 方法是最流行的任意尺度 SR 方法,其核心由两个函数构成:一个是 DNN 编码器 E φ ( ⋅ ) E_{\varphi}(\cdot) Eφ(⋅) ,另一个是连续图像函数 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅)(通常参数化为多层感知器 MLP)。DNN 编码器 E φ ( ⋅ ) E_{\varphi}(\cdot) Eφ(⋅) 从低分辨率图像 I L R I^{LR} ILR 中提取潜在代码(即特征) Z = E φ ( I L R ) Z = E_{\varphi}(I^{LR}) Z=Eφ(ILR),连续图像函数 f θ f_{\theta} fθ 则将潜在代码 Z Z Z 和坐标作为输入,并生成 RGB 值。其形式化定义为: s = f θ ( Z , x ) s = f_{\theta}(Z, x) s=fθ(Z,x),其中 x ∈ X x \in X x∈X 是连续图像域中的二维坐标, s ∈ S s \in S s∈S 是预测的超分辨率图像 I S R I^{SR} ISR 的 RGB 值。对于基于 LIIF 的方法,生成 I S R I^{SR} ISR 中每个像素的 RGB 值都需要一次查询(每次查询指使用特定坐标点作为输入执行一次上述公式),生成整个 I S R I^{SR} ISR 总共需要 ( r h H × r w W ) (r_{h}H × r_{w}W) (rhH×rwW) 次查询,这使得计算非常耗时。需要注意的是,连续图像 I I I 是唯一的, I L R I^{LR} ILR 和 I S R I^{SR} ISR 可看作是连续图像 I I I 在不同分辨率下的离散表示,潜在代码 Z Z Z 不是连续表示的,而 RGB 值 s s s 是连续表示的,因为它是通过连续的坐标 x x x 计算得到的。
问题公式化及动机-Problem Formulation and Motivation
这部分主要阐述了对抗攻击的目标、传统尺度依赖攻击的问题,进而引出设计尺度不变攻击的需求及核心思路,具体内容如下:
- 攻击目标:对抗攻击针对单图像超分辨率(SISR)方法,是指人为地向低分辨率(LR)图像 I L R I^{LR} ILR 中注入人眼难以察觉的小扰动,目的是使生成的超分辨率图像 I S R I^{SR} ISR 质量显著下降。给定 I L R I^{LR} ILR,添加对抗扰动 δ \delta δ 得到对抗 LR 图像 I a d v = I L R + δ I^{adv}=I^{LR}+\delta Iadv=ILR+δ,优化目标为 δ = a r g m a x δ ∗ L ( I a d v , I L R ) \delta=\underset{\delta^{*}}{arg max } \mathcal{L}\left(I^{adv}, I^{LR}\right) δ=δ∗argmaxL(Iadv,ILR),同时满足 ∥ δ ∗ ∥ p ≤ ϵ \left\| \delta^{*}\right\| _{p} \leq \epsilon ∥δ∗∥p≤ϵ ,其中 L ( ⋅ ) \mathcal{L}(\cdot) L(⋅) 表示损失函数, ϵ \epsilon ϵ 是攻击强度,用于限制对抗扰动 δ \delta δ 的大小。
- 尺度依赖攻击的问题:以往的 SR 对抗攻击方法是尺度依赖(SD)的,其试图最大化由固定上采样尺度
r
r
r 从
I
L
R
I^{LR}
ILR 生成的离散表示超分辨率图像的退化程度。具体来说,设
Φ
(
⋅
,
⋅
)
\Phi(\cdot, \cdot)
Φ(⋅,⋅) 表示固定尺度 SR 模型,以往方法使用原始干净 LR 图像的 SR 输出
Φ
(
I
L
R
,
r
)
\Phi(I^{LR}, r)
Φ(ILR,r) 与对抗 LR 图像的 SR 输出
Φ
(
I
a
d
v
,
r
)
\Phi(I^{adv}, r)
Φ(Iadv,r) 之间的
L
2
L_{2}
L2 距离作为损失函数,即
L
S
D
=
∥
Φ
(
I
a
d
v
,
r
)
−
Φ
(
I
L
R
,
r
)
∥
2
\mathcal{L}_{\mathcal{SD}}=\left\| \Phi\left(I^{adv}, r\right)-\Phi\left(I^{LR}, r\right)\right\| _{2}
LSD=
Φ(Iadv,r)−Φ(ILR,r)
2 ,该方法对固定尺度 SR 方法攻击性能出色。但随着基于 LIIF 的 SR 方法兴起,尺度依赖攻击在任意尺度 SR 中面临困境。由于生成
I
S
R
I^{SR}
ISR 时每个像素的 RGB 值都需一次查询,生成整个
I
S
R
I^{SR}
ISR 需要大量查询,且尺度依赖攻击构建损失依赖离散表示的
I
S
R
I^{SR}
ISR,所以随着上采样尺度
r
r
r 增加,其时间和资源消耗会急剧增大,变得难以接受。如在 Set5 数据集上对 LIIF 采用尺度依赖攻击的实验显示,随着尺度增加,攻击的时间和内存成本呈指数上升。这表明需要为任意尺度 SR 设计一种尺度不变的攻击方法,且该攻击应作用于连续图像,而非离散的 SR 图像,以确保在任意上采样尺度下都能使 SR 图像质量下降。然而,面对连续图像(在连续表示域中可无限细分,有无限坐标),构建类似传统的损失函数非常困难,因为无法遍历所有坐标点。同时,实验验证仅利用潜在代码
z
z
z 构建损失会导致攻击性能明显低于尺度依赖的SR攻击方法。
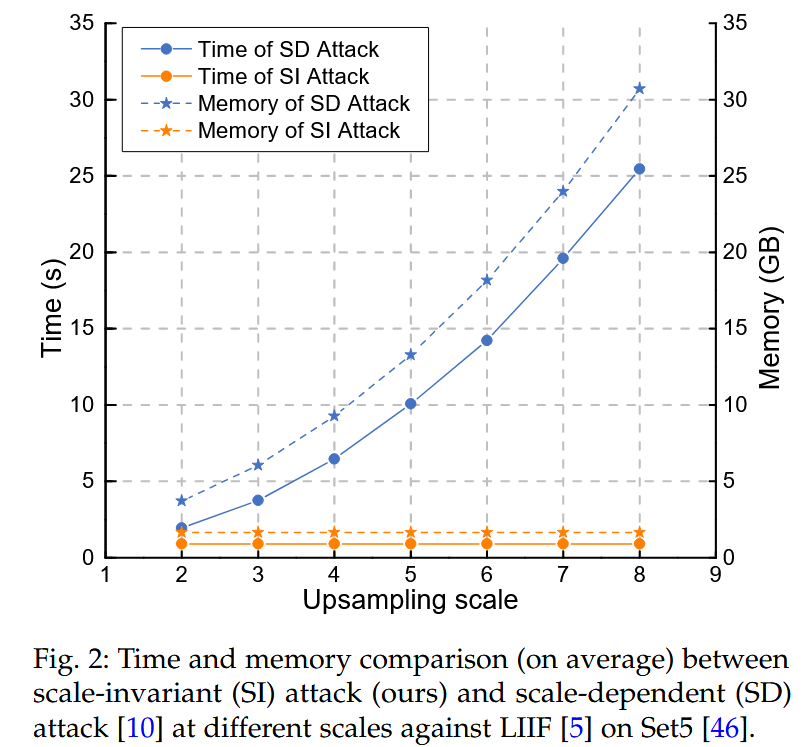
图2:在 Set5 数据集上,针对 LIIF 模型,我们提出的尺度不变(SI)攻击与尺度依赖(SD)攻击在不同尺度下的平均时间和内存消耗对比。 - 设计尺度不变攻击的思路:一个简单有效的思路是通过调整连续图像中有限离散坐标点的值来改变连续图像。例如,在连续图像中改变一个坐标点的值,会使周围许多坐标点的值发生变化,且影响范围较大。因此,通过修改连续图像中有限数量的离散(非相邻)点,可改变大量坐标点的值,从而高效构建攻击,实现使连续图像质量下降的目的。基于此思路设计的尺度不变攻击方法(SI)具有出色的省时和省内存特性,基本不受尺度影响。
尺度不变对抗攻击-Scale-invariant Adversarial Attack
该部分详细介绍了针对任意尺度超分辨率的尺度不变对抗攻击方法,具体内容如下:
- 攻击构建思路:摒弃在离散 SR 输出上构建攻击的方式,转而在连续图像上构建尺度不变(SI)攻击。因为对连续图像的攻击等同于同时对任意尺度的 SR 图像进行攻击。
- 攻击具体步骤
- 图像分块:将连续图像 I I I 划分为有限个块。在实际经验研究中发现,将连续图像 I I I 均匀分割为 H × W H×W H×W 个块时,能取得良好的攻击性能。
- 构建损失:在每个块中随机选择坐标,利用这些坐标计算得到的 RGB 值来构建损失。以将连续图像 I I I 划分为 2 × 2 2×2 2×2 个块为例,在每个块中随机查询 n n n 个坐标(如 x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn ),损失 L S I L_{SI} LSI 定义为 L S I = ∥ Ψ ( I a d v , Λ ) − Ψ ( I L R , Λ ) ∥ 2 \mathcal{L}_{SI}=\left\| \Psi\left(I^{adv}, \Lambda\right)-\Psi\left(I^{LR}, \Lambda\right)\right\| _{2} LSI= Ψ(Iadv,Λ)−Ψ(ILR,Λ) 2. 其中, Λ \Lambda Λ 表示所有块的查询坐标集合, Ψ ( ⋅ , ⋅ ) \Psi(\cdot, \cdot) Ψ(⋅,⋅) 表示任意尺度 SR 模型。需要注意的是, L S I L_{SI} LSI 损失不能直接应用于编码器 E φ ( ⋅ ) E_{\varphi}(\cdot) Eφ(⋅) 生成的潜在代码 z z z 中选定的点,因为潜在代码 z z z 不是连续表示的,只有坐标 x ∈ X x \in X x∈X 处于连续图像域。所以这里通过 I L R I^{LR} ILR 和 I a d v I^{adv} Iadv 的 SR 结果中的有限 RGB 值,来反映连续图像中有限离散点的信息。
- 攻击复杂度分析:尺度不变攻击方法的复杂度为 O ( H × W ) O(H×W) O(H×W),而尺度依赖攻击方法的复杂度为 O ( r h H × r w W ) O(r_{h}H×r_{w}W) O(rhH×rwW)。这意味着尺度不变攻击的时间和内存消耗是固定的,而尺度依赖攻击的消耗会随着上采样尺度的增加呈指数上升。例如,当采样尺度 r = 30 , 30 r = {30,30} r=30,30 时,该方法比尺度依赖的SR攻击快数百倍。
提高攻击迁移性-Improving Attack Transferability
该部分主要聚焦于提升任意尺度超分辨率攻击的跨模型迁移性,提出了基于坐标设计方法的新思路,并详细介绍了相关损失函数及总损失函数,具体内容如下:
- 跨模型转移性研究现状及问题:跨模型迁移性对白盒攻击意义重大,在图像分类领域已有研究致力于提升攻击的跨模型迁移性,但这些方法聚焦于特征的通用性和不变性,适用于强特征依赖的分类任务,却与基于坐标的任意尺度超分辨率任务不兼容。在超分辨率任务中,提高攻击跨模型迁移性仍是一个未被探索的新问题。
- 提升攻击转移性的方法:基于观察到超分辨率模型处理低频信息相对容易,而对高频信息(如边缘、纹理等)的重建存在困难,且这种局限性在不同超分辨率模型中普遍存在。因此,通过增加对抗低分辨率图像中的高频信息,使超分辨率模型更难生成高质量输出,以此提升攻击的跨模型转移性。
- 具体实现 - 损失函数设计:提出通过扩大查询坐标与其相邻坐标的 RGB 值差距来增加高频信息。形式上,定义损失 L T R L_{TR} LTR 为 L T R = ∥ Ψ ( I a d v , Λ ⊕ Δ G ) − Ψ ( I a d v , Λ ) ∥ 2 \mathcal{L}_{TR}=\left\| \Psi\left(I^{adv}, \Lambda \oplus \Delta G\right)-\Psi\left(I^{adv}, \Lambda\right)\right\| _{2} LTR= Ψ(Iadv,Λ⊕ΔG)−Ψ(Iadv,Λ) 2 ,其中 Δ G \Delta G ΔG 是一组随机生成的坐标偏移, ⊕ \oplus ⊕ 表示将两个集合中相同索引的对应坐标相加。虽然该操作旨在最大化连续图像中相邻坐标的 RGB 值差异,但仍遵循扰动约束,确保攻击几乎不可察觉。通过这种方式,在连续图像中相邻坐标间产生更大的 RGB 值差异,会使 I a d v I^{adv} Iadv 图像产生更多高频信息,进而提升攻击的跨模型转移性。
- 总损失函数:将 L S I L_{SI} LSI 和 L T R L_{TR} LTR 结合,得到 SIAGT 方法的总损失函数为 L f i n a l = L S I + β ⋅ L T R \mathcal{L}_{final }=\mathcal{L}_{SI}+\beta \cdot \mathcal{L}_{TR} Lfinal=LSI+β⋅LTR ,其中 β \beta β 是用于平衡 L S I L_{SI} LSI 和 L T R L_{TR} LTR 的权重值。
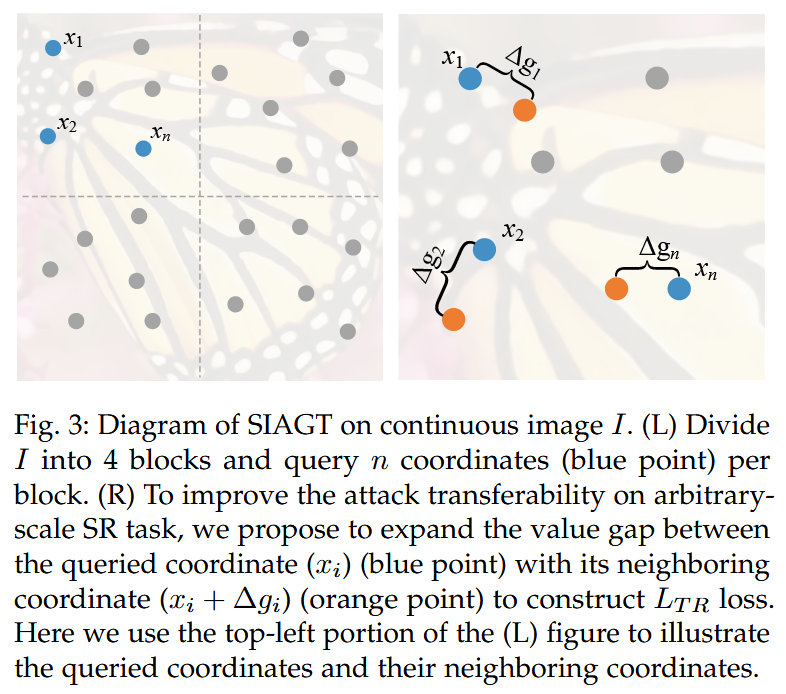
图3:SIAGT在连续图像I上的示意图。(左图)将图像
I
I
I 划分为 4 个块,每个块查询
n
n
n 个坐标(蓝色点)。(右图)为提高在任意尺度超分辨率任务上的攻击转移性,我们提议扩大查询坐标(
(
x
i
)
(x_{i})
(xi),蓝色点)与其相邻坐标
(
x
i
+
Δ
g
i
)
(x_{i}+\Delta g_{i})
(xi+Δgi)(橙色点)之间的数值差距,以构建
L
T
R
L_{TR}
LTR 损失。这里我们使用左图的左上角部分来说明查询坐标及其相邻坐标。

图4:LIIF在处理图像中低频和高频信息方面的性能。
攻击迭代策略-Attack Iteration Strategy
这部分主要介绍了针对任意尺度超分辨率攻击的迭代策略,对比了传统策略与改进策略,突出改进策略在提升攻击性能上的优势,具体内容如下:
- 传统迭代策略及问题:在迭代策略上,通常参考常用的 PGD(投影梯度下降)类似的
l
∞
l_{\infty}
l∞ -范数攻击,但在每次迭代的扰动幅度设置上有所不同。传统PGD更新
I
a
d
v
I^{adv}
Iadv(在 LIIF 的实现中,
I
a
d
v
I^{adv}
Iadv 的值在 [-1,1] 范围内)的策略为:
I ~ t + 1 a d v = c l i p − 1 , 1 ( I t a d v + ϵ T s i g n ( ∇ L f i n a l ) ) \tilde{I}_{t + 1}^{adv} = clip_{-1,1}(I_{t}^{adv} + \frac{\epsilon}{T} sign(\nabla \mathcal{L}_{final})) I~t+1adv=clip−1,1(Itadv+Tϵsign(∇Lfinal))
I t + 1 a d v = c l i p − ϵ , ϵ ( I ‾ t + 1 a d v − I L R ) + I L R I_{t + 1}^{adv} = clip_{-\epsilon,\epsilon}(\overline{I}_{t + 1}^{adv} - I^{LR}) + I^{LR} It+1adv=clip−ϵ,ϵ(It+1adv−ILR)+ILR
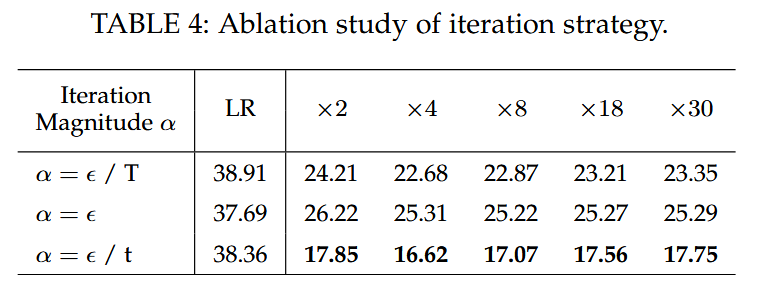
其中, ϵ \epsilon ϵ 是攻击强度, t t t 是当前迭代索引(范围是 [ 1 , T ] [1, T] [1,T] ), T T T 是总迭代次数, s i g n ( ∇ L f i n a l ) sign(\nabla L_{final}) sign(∇Lfinal) 是梯度的符号, c l i p a , b ( I ) = m i n ( m a x ( I , a ) , b ) clip_{a,b}(I) = min(max(I, a), b) clipa,b(I)=min(max(I,a),b)。然而,通过实验发现,使用固定强度 ϵ T \frac{\epsilon}{T} Tϵ 的每次迭代并不能达到良好的攻击性能。 - 改进后的迭代策略:提出用 I ~ t + 1 a d v = c l i p − 1 , 1 ( I t a d v + ϵ t s i g n ( ∇ L f i n a l ) ) \tilde{I}_{t + 1}^{adv} = clip_{-1,1}(I_{t}^{adv} + \frac{\epsilon}{t} sign(\nabla \mathcal{L}_{final})) I~t+1adv=clip−1,1(Itadv+tϵsign(∇Lfinal)) 替代传统的更新公式。该操作的目的是在迭代开始时采用较大的扰动幅度,随着迭代次数增加,扰动幅度逐渐变小。这种策略有助于比传统公式更快地逼近对抗样本,从而提升攻击效果。
实验-Experiment
这部分主要介绍了针对尺度不变对抗攻击方法 SIAGT 的实验验证,涵盖实验设置、攻击性能、跨模型转移性、时间消耗、消融研究等多方面,全面验证了 SIAGT 的有效性和性能特点,具体内容如下:
实验设置
- 数据集:使用 Set5、Set14、B100 和 Urban100 四个广泛应用的经典基准数据集,通过 bicubic 下采样生成输入低分辨率图像。
- 目标模型:选取三个任意尺度超分辨率模型,即基础模型 LIIF 以及两个经典模型 LTE、CiaoSR,使用官方提供的预训练权重。
- 评估指标:以 PSNR(峰值信噪比)为主要评估指标,较高的 PSNR 意味着更好的图像质量。理想的超分辨率攻击应使低分辨率干净图像和对抗图像之间的 PSNR 保持较高,同时使相应超分辨率图像之间的 PSNR 较低。
- 实施细节:在攻击强度 ϵ ≤ 8 / 255 \epsilon\leq8/255 ϵ≤8/255( l ∞ l_{\infty} l∞ -范数攻击的常见选择)下评估任意尺度超分辨率的稳健性。上采样尺度设置为 s ∈ { 2 , 3 , 4 , 6 , 8 , 12 , 18 , 24 , 30 } s\in\{2,3,4,6,8,12,18,24,30\} s∈{2,3,4,6,8,12,18,24,30},以充分展示攻击方法在不同尺度下的效果。设置 Δ G \Delta G ΔG 的范围为 [ − 0.5 × 1 0 − 2 , 0.5 × 1 0 − 2 ] [-0.5\times10^{-2}, 0.5\times10^{-2}] [−0.5×10−2,0.5×10−2], β = 2 \beta = 2 β=2 。实验在 Ubuntu 系统、配备 Nvidia A6000 GPU 的环境下进行。
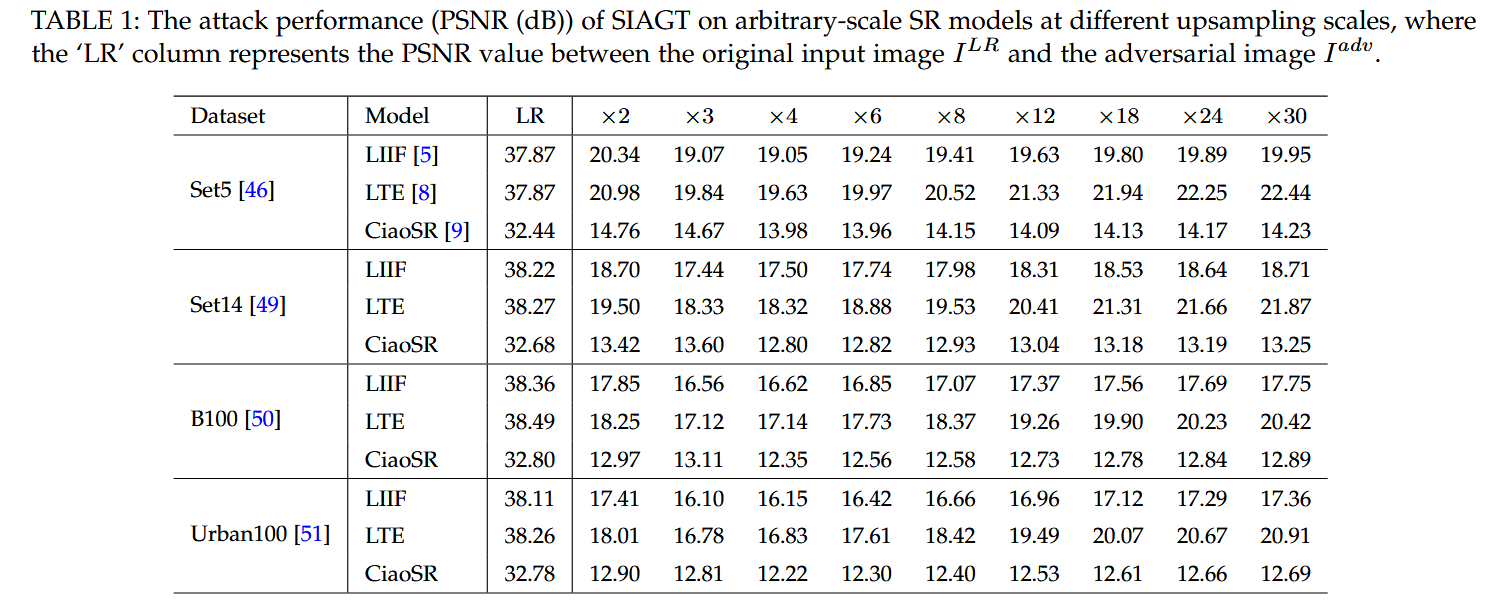
攻击性能
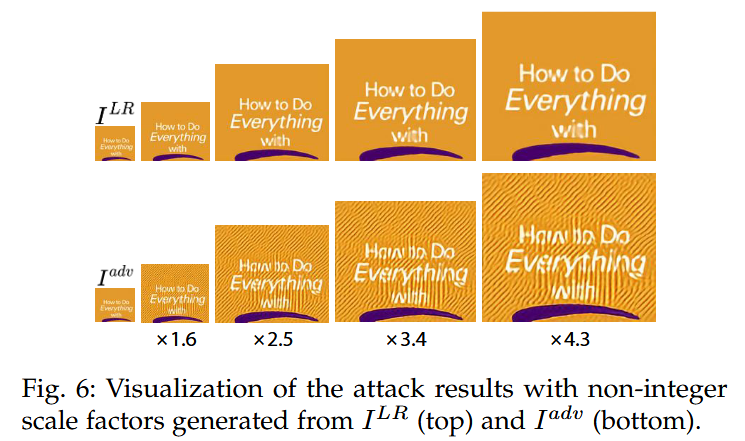
SIAGT 在不同数据集和模型上的实验结果表明,低分辨率干净图像
I
L
R
I^{LR}
ILR 和对抗图像
I
a
d
v
I^{adv}
Iadv 的 PSNR 大多大于30,视觉上几乎无差异;而不同尺度超分辨率图像的 PSNR 大多接近或低于 20,显示出 SIAGT 的尺度不变性和有效性。对非整数尺度因子的实验也显示,
I
a
d
v
I^{adv}
Iadv 的超分辨率图像存在显著变形和失真,表明任意尺度超分辨率在作为预处理技术时存在潜在脆弱性。

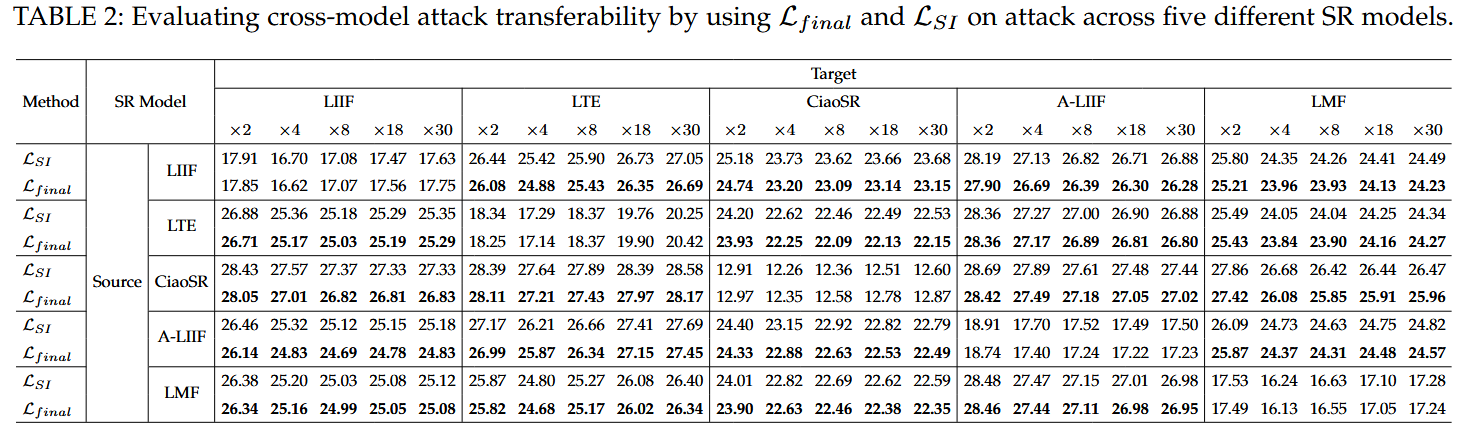
跨模型转移性
为全面评估,将攻击方法的跨模型转移性评估扩展到另外两个任意尺度超分辨率模型 A - LIIF 和 LMF。实验结果显示,使用
L
f
i
n
a
l
L_{final}
Lfinal 损失的攻击在五个超分辨率模型上的跨模型转移性明显优于仅使用
L
S
I
L_{SI}
LSI 损失的攻击,目标模型上
I
a
d
v
I^{adv}
Iadv 的超分辨率输出明显退化。

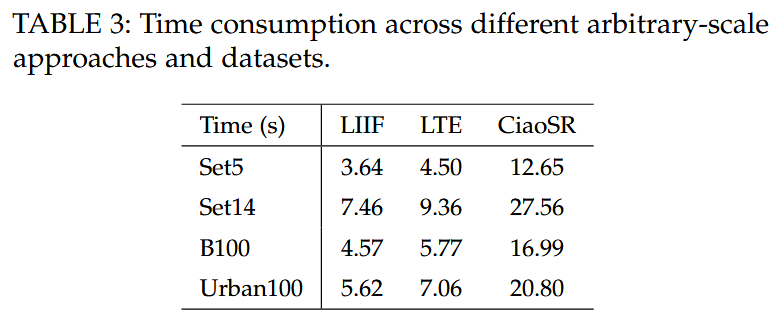
时间消耗
给出了在不同任意尺度超分辨率方法和数据集上,处理每张图像的详细时间消耗(基于
L
f
i
n
a
l
L_{final}
Lfinal 损失),展示了 SIAGT 在时间成本方面的表现。
消融研究
-
迭代策略:对比了本文提出的迭代策略与另外两种固定扰动幅度的策略,结果表明本文策略在攻击性能上显著优于其他两种策略。
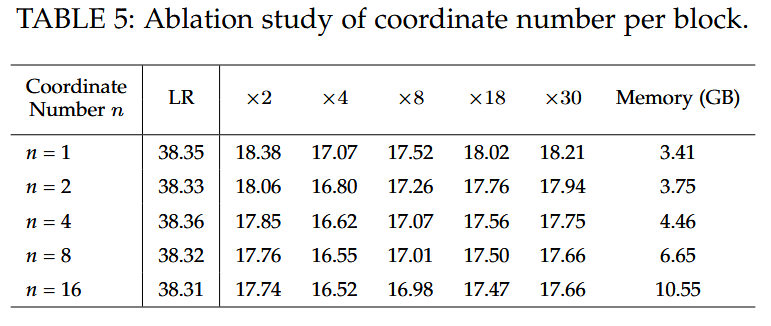
-
坐标查询数:研究了每块坐标查询数 n n n 对攻击性能的影响。发现 n = 1 n = 1 n=1 时攻击性能尚可,随着 n n n 增大性能提升,但 n ≥ 4 n\geq4 n≥4 时提升速度放缓且显存消耗急剧增加,综合考虑选择 n = 4 n = 4 n=4.
-
超参数选择:探究了超参数 β \beta β 和 Δ G \Delta G ΔG 范围对攻击性能的影响。结果显示, β ≥ 2 \beta\geq2 β≥2 时跨模型转移性接近但白盒攻击性能下降,因此选择 β = 2 \beta = 2 β=2; Δ G \Delta G ΔG 范围过大或过小都会导致白盒攻击性能和跨模型转移性下降,权衡后选择 [ − 0.5 × 1 0 − 2 , 0.5 × 1 0 − 2 ] [-0.5\times10^{-2}, 0.5\times10^{-2}] [−0.5×10−2,0.5×10−2] 。
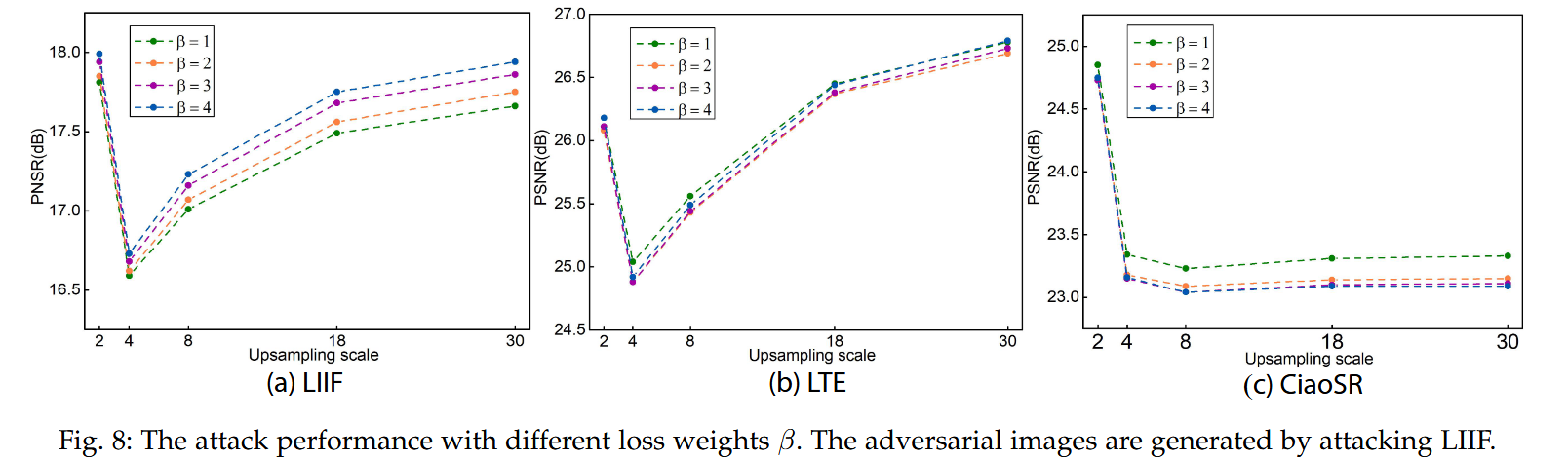
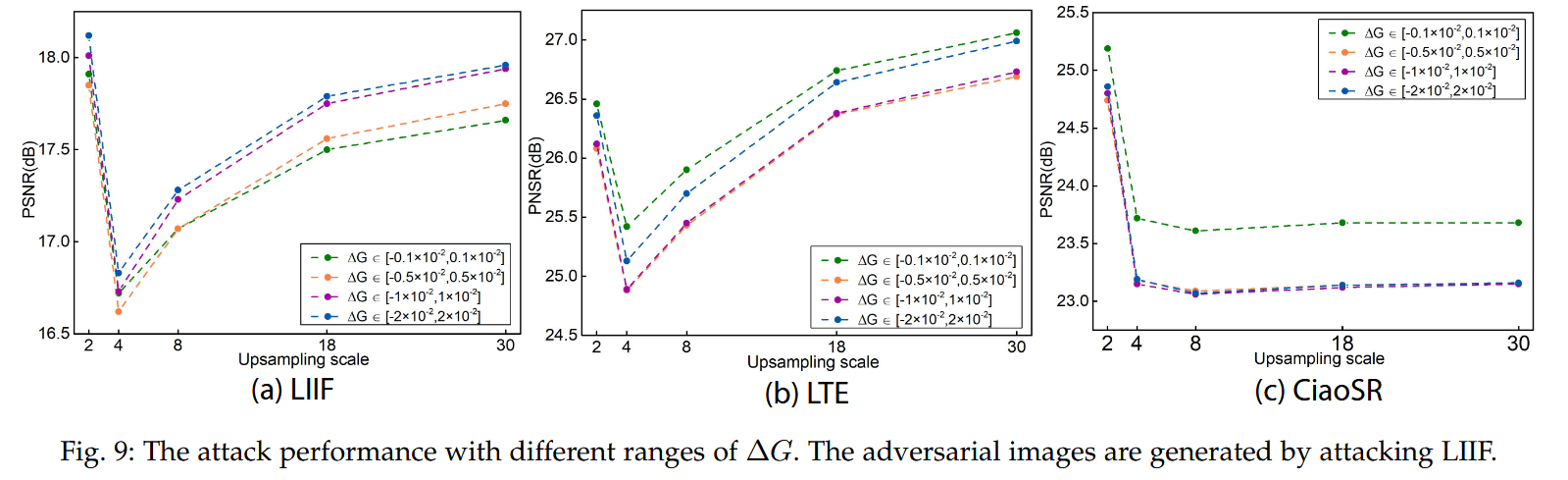
-
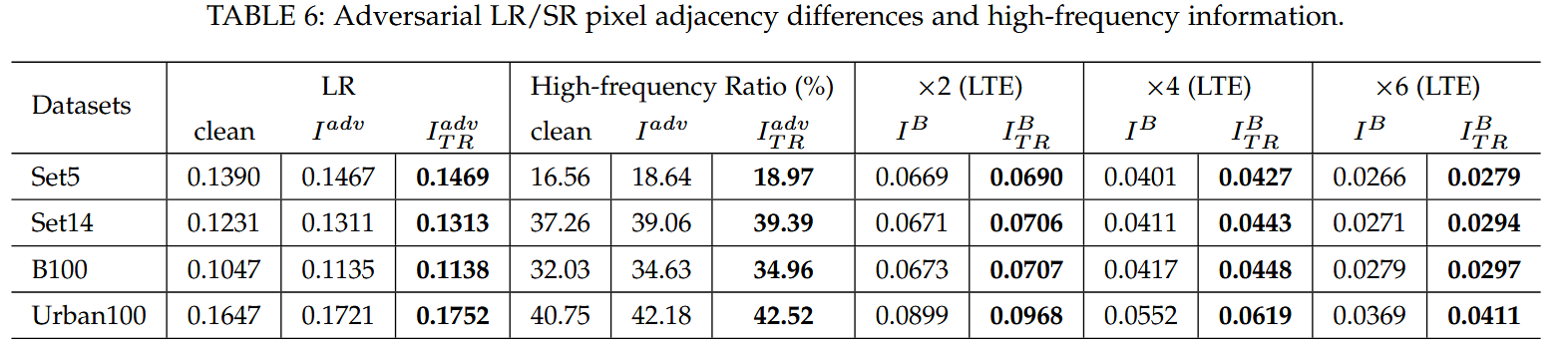
L T R L_{TR} LTR的作用:深入研究 L T R L_{TR} LTR 损失的影响,通过实验发现 L T R L_{TR} LTR 能有效增大对抗低分辨率图像的相邻像素差异,增加高频信息比例,进而降低超分辨率图像质量,提升攻击转移性。

讨论
- 影响攻击性能的因素
- 块数:实验中通常将连续图像 I I I分割为 H × W H×W H×W块( H H H、 W W W约为100 ,是LR图像常用分辨率)。进一步指数级减少块数实验发现,块数减少时攻击性能虽变差,但PSNR仍能保持在30以下,反映了SIAGT方法的实用性和合理性。
- 坐标数与块数耦合:在B100数据集上固定上采样尺度为4,对LIIF模型进行实验。结果显示,增加坐标数和块数会引入更大失真(PSNR值更低),表明这两个因素相互关联,共同影响攻击效果。
- 失真与上采样尺度关系:使用LIIF在B100数据集上对不同小上采样尺度进行实验,发现上采样尺度较小时(如1.01),图像尺寸仅轻微扩大,PSNR值就已低于30;尺度增至1.5时,PSNR值进一步降至20以下,说明失真随上采样尺度增加迅速出现。
- 攻击强度:研究不同攻击强度下SIAGT的不可感知性和有效性。随着攻击强度增加,不同上采样尺度下的攻击性能均提升,攻击强度大于4/255时,SR图像的PSNR值接近或低于20。攻击的不可感知性主要由 ϵ \epsilon ϵ决定,与损失函数设计关系不大,增加高频信息不影响攻击的不可感知性。
- 与其他方法对比
- 攻击性能对比:将SIAGT与基线方法、仅基于潜在代码 z z z构建损失的方法( L l a t e n t L_{latent} Llatent)、仅使用 L S I L_{SI} LSI的方法进行对比。结果表明,SIAGT在节省资源的同时,攻击性能与基线方法相近,且明显优于 L l a t e n t L_{latent} Llatent,验证了SIAGT的必要性和有效性。
- 跨模型转移性对比:对比SIAGT与图像分类中用于提升跨模型转移性的方法(如DIM、ILA),发现DIM无法成功攻击LIIF,ILA提升跨模型转移性的能力也不如SIAGT。
- 对下游任务的影响
- 文本识别:在TextZoom数据集上,使用LIIF模型和预训练的MORAN文本识别器。结果显示,SR模型可使文本识别准确率平均提高0.9%,但使用 I a d v I^{adv} Iadv作为输入会使准确率显著降低17%。
- 面部检测:在WIDER FACE数据集上,使用Retinaface模型。SR模型能使面部检测准确率平均提高20.73%,而使用 I a d v I^{adv} Iadv作为输入会使准确率大幅降低36.28%。
- 街景门牌号识别:在SVHN数据集上,使用百度开源的OCR模型。对 I L R I^{LR} ILR的OCR识别准确率为54.25% , I L R I^{LR} ILR的SR版本可将准确率提升至55.15%,但 I a d v I^{adv} Iadv的SR版本准确率仅为25.02%,表明对抗样本对下游任务有负面影响。
- 基于人类感知的评估
- LPIPS指标评估:使用与人类视觉感知更相关的LPIPS指标评估,结果显示SIAGT生成的对抗低分辨率图像与原始干净低分辨率图像在PSNR上较高且LPIPS较低,相似性高;但其超分辨率版本则相反,PSNR低且LPIPS高,相似性低,反映了SIAGT在降低超分辨率图像感知质量方面的有效性。
- 人类评估:通过对60人进行问卷调查,对比原始干净低分辨率图像与对抗低分辨率图像,以及它们的超分辨率图像质量。结果显示,44.49%的参与者无法区分原始与对抗低分辨率图像,28.99%认为对抗图像更好,26.52%更倾向原始图像,表明攻击具有不可感知性;对于超分辨率图像,84.33%的参与者认为原始低分辨率图像的超分辨率版本质量更好,12.16%认为对抗低分辨率图像的超分辨率版本更好,3.51%无法区分,证明了攻击在降低超分辨率图像质量方面的有效性。
- 其他相关发现
- 查询坐标选择:对比随机选择坐标与在高频或低频区域选择坐标的策略,发现随机选择策略攻击性能最佳,因其适应性强、简单省时,所以SIAGT采用随机选择策略。
- 对不同图像的攻击效果:研究发现攻击对有文字和无文字图像的效果无显著差异,文字的存在对攻击效果影响不大。
局限和结论-Limitation and Conclusion
- 局限性:
- 本文提出的SIAGT是针对任意尺度超分辨率的尺度不变攻击方法,存在应用范围的局限性。由于其损失项 L S I L_{SI} LSI依赖特定坐标因素,该方法无法应用于固定尺度超分辨率方法,限制了攻击的通用性 。
- 结论:
- 研究成果:提出了针对任意尺度超分辨率的SIAGT攻击方法,其基于连续表示构建攻击,通过调整连续表示中的有限离散点改变其外观,同时提出坐标相关损失解决跨模型转移性问题。
- 研究验证:在多种基于LIIF的超分辨率方法和经典数据集上进行实验,验证了SIAGT的有效性和高效性。
- 未来展望:未来计划将该对抗攻击思路拓展到其他基于连续表示的模型和任务,如Nerf等,进一步探索其应用和影响。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











