







You Only Need Less Attention at Each Stage in Vision Transformers

本文 “You Only Need Less Attention at Each Stage in Vision Transformers” 提出了LaViT,旨在解决 Vision Transformers(ViTs)中自注意力机制计算复杂度高和注意力饱和问题。LaViT 在每个阶段仅在少数初始层计算传统自注意力,后续层通过注意力变换利用之前计算的注意力分数,减少计算量。同时引入注意力残差模块保留上下文信息,设计对角保持损失函数维持注意力矩阵特性。实验表明,LaViT 在多个视觉任务(分类、检测、分割)中性能优异,计算复杂度和内存消耗更低。
摘要-Abstract
The advent of Vision Transformers (ViTs) marks a substantial paradigm shift in the realm of computer vision. ViTs capture the global information of images through selfattention modules, which perform dot product computations among patchified image tokens. While self-attention modules empower ViTs to capture long-range dependencies, the computational complexity grows quadratically with the number of tokens, which is a major hindrance to the practical application of ViTs. Moreover, the self-attention mechanism in deep ViTs is also susceptible to the attention saturation issue. Accordingly, we argue against the necessity of computing the attention scores in every layer, and we propose the Less-Attention Vision Transformer (LaViT), which computes only a few attention operations at each stage and calculates the subsequent feature alignments in other layers via attention transformations that leverage the previously calculated attention scores. This novel approach can mitigate two primary issues plaguing traditional selfattention modules: the heavy computational burden and attention saturation. Our proposed architecture offers superior efficiency and ease of implementation, merely requiring matrix multiplications that are highly optimized in contemporary deep learning frameworks. Moreover, our architecture demonstrates exceptional performance across various vision tasks including classification, detection and segmentation.
视觉Transformer(ViTs)的出现标志着计算机视觉领域发生了重大的范式转变。ViTs通过自注意力模块捕捉图像的全局信息,该模块对分块后的图像token进行点积计算。虽然自注意力模块使ViTs能够捕捉长距离依赖关系,但计算复杂度会随着标记数量的增加呈二次方增长,这严重阻碍了ViTs的实际应用。此外,深度ViTs中的自注意力机制还容易出现注意力饱和问题。因此,我们认为没有必要在每一层都计算注意力分数,并提出了少注意力视觉Transformer(LaViT)。LaViT在每个阶段仅执行少量注意力操作,在其他层则通过利用先前计算的注意力分数进行注意力变换来计算后续的特征对齐。这种新颖的方法可以缓解困扰传统自注意力模块的两个主要问题:沉重的计算负担和注意力饱和。我们提出的架构具有更高的效率和易于实现的特点,仅需进行在当代深度学习框架中经过高度优化的矩阵乘法运算。此外,我们的架构在包括分类、检测和分割在内的各种视觉任务中均展现出卓越的性能。
引言-Introduction
这部分内容主要介绍了研究背景和动机,提出了LaViT框架并阐述其优势,还总结了研究的主要贡献,具体如下:
- 研究背景:深度学习和大规模数据集推动计算机视觉快速发展,卷积神经网络(CNNs)在图像分类、目标检测和语义分割等任务中表现出色。受Transformer在自然语言处理领域成功的启发,视觉Transformer(ViTs)通过自注意力机制捕捉图像长程依赖,但自注意力机制计算复杂度高,随着图像分辨率提高计算负担加重,且存在注意力饱和问题。
- 研究动机:现有减少自注意力计算负担的方法,如动态选择或修剪token,存在设计复杂和可能丢失关键token的问题。鉴于此,文章思考是否有必要在网络的每个阶段都使用自注意力机制。
- LaViT框架:提出Less-Attention Vision Transformer(LaViT),其由普通注意力(VA)层和少注意力(LA)层构成。在每个阶段,仅在少数初始VA层计算传统自注意力并存储分数,后续LA层利用之前计算的注意力矩阵生成注意力分数,降低计算成本。同时,通过跨阶段下采样时在注意力层集成残差连接,保存关键语义信息,并设计新的损失函数保持注意力矩阵的对角线特性。
- 研究贡献:提出新的ViT架构,通过重新参数化前层计算的注意力矩阵生成注意力分数,解决注意力饱和和计算负担问题;设计新的损失函数,在注意力重新参数化过程中保持注意力矩阵的对角线特性,确保其准确反映输入token之间的相对重要性;该架构在多个视觉任务中性能优异,且计算复杂度和内存消耗更低 。
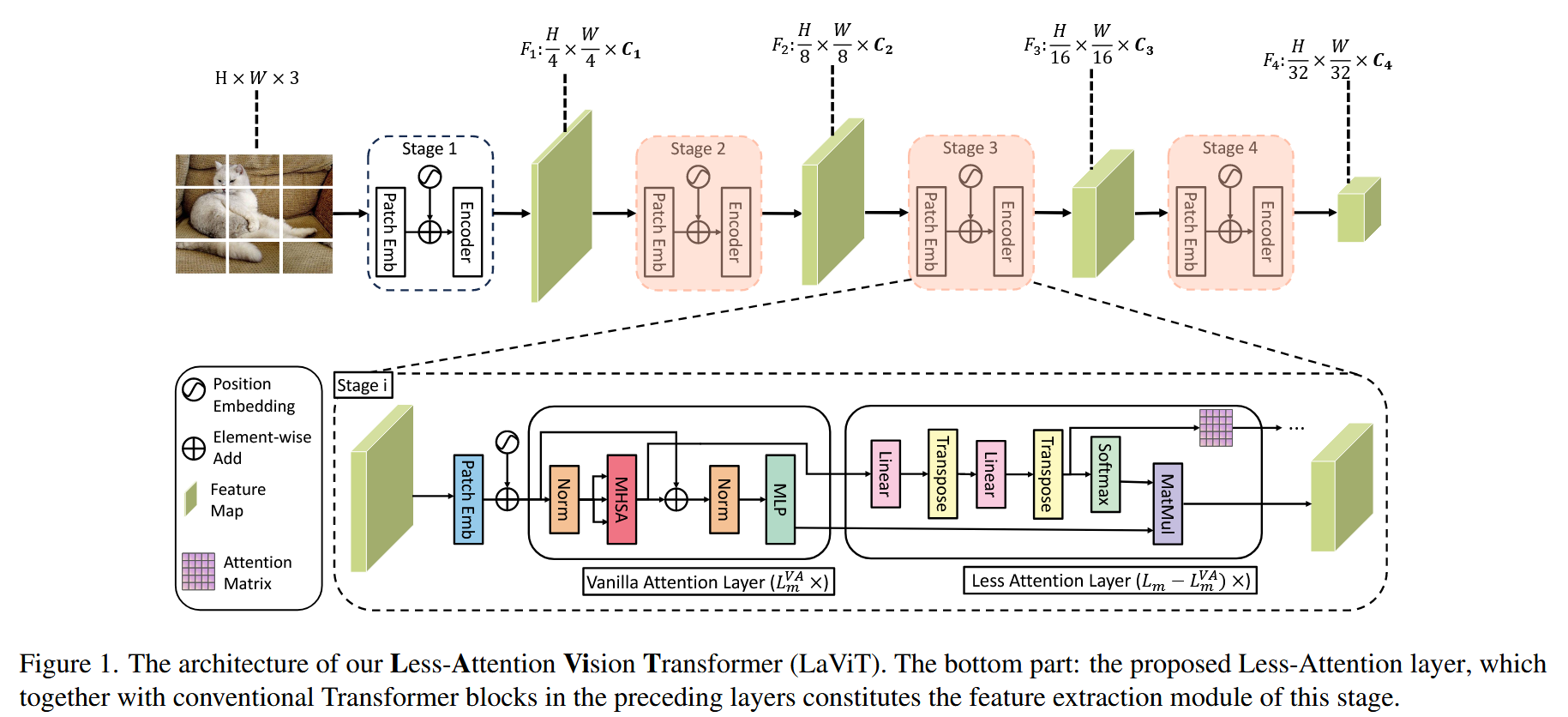
图1. 我们的少注意力视觉Transformer(LaViT)架构。底部部分:所提出的少注意力层,它与前层的传统Transformer块共同构成了该阶段的特征提取模块。
相关工作-Related Work
这部分内容主要回顾了与本文研究相关的工作,涵盖视觉Transformer、高效视觉Transformer以及注意力机制三个方面,具体如下:
- 视觉Transformer(Vision Transformers):Transformer最初用于机器翻译,后通过ViT应用于计算机视觉任务。ViT的关键创新在于利用自注意力机制捕捉图像远距离区域间的长程依赖。受其成功启发,出现了诸多变体模型,如DeiT通过引入蒸馏token提高训练数据效率,CvT和CeiT将卷积结构融入ViT框架,结合了CNNs的空间不变性和ViTs的长程依赖建模能力,推动了基于Transformer架构在计算机视觉领域的发展。
- 高效视觉Transformer(Efficient Vision Transformers):尽管ViTs效果显著,但计算负担巨大。相关研究通过多种方式解决自注意力操作的二次计算成本问题,包括采用分层下采样操作,在不同阶段逐步减少token数量,使ViTs能够学习层次结构;引入token选择模块,去除意义较小的token以减轻计算负担;设计轻量级架构等。
- 注意力机制(Attention Mechanisms):ViTs的核心组件是注意力机制,它计算所有图像块之间的成对交互,导致计算复杂度与输入大小呈二次方关系,阻碍了ViTs在实际中的应用。一些研究提出利用稀疏注意力机制,根据相关性或邻近性选择性地关注部分图像块,如自适应稀疏token修剪框架,同时采用结构化稀疏模式等技术进一步降低计算复杂度。此外,注意力饱和也是一个重要问题,随着网络层数增加,注意力矩阵变化有限,影响深层ViTs捕捉额外语义信息的能力和训练稳定性,因此精心设计ViTs中的自注意力机制至关重要。
方法-Methodology
视觉Transformer-Vision Transformer
这部分内容主要介绍了视觉Transformer(ViT)的基本设计,包括图像分块与嵌入、多头自注意力机制以及下采样操作,具体如下:
- 图像分块与嵌入:输入图像 x ∈ R H × W × C x \in \mathbb{R}^{H×W×C} x∈RH×W×C,将其划分为 N = H W / p 2 N = HW/p^{2} N=HW/p2 个大小为 p × p p×p p×p 像素且具有 C C C 通道的图像块 P i ∈ R p × p × C P_{i} \in \mathbb{R}^{p×p×C} Pi∈Rp×p×C, p p p 为超参数,决定了token的粒度。通过卷积操作提取图像块嵌入,将每个图像块投影到嵌入空间 Z ∈ R N × D Z \in \mathbb{R}^{N×D} Z∈RN×D, D D D 为每个图像块的维度。
- 多头自注意力(Multi-Head Self-Attention):在第 l l l 个多头自注意力(MHSA)块中,输入 Z l − 1 Z_{l - 1} Zl−1 被投影为三个可学习的嵌入 Q Q Q、 K K K、 V ∈ R N × D V \in \mathbb{R}^{N×D} V∈RN×D。选择 H H H 个注意力头,每个头的维度为 N × D H N×\frac{D}{H} N×HD。第 h h h 个头的注意力矩阵 A h A_{h} Ah 通过 A h = S o f t m a x ( Q h K h ⊤ d ) A_{h}=Softmax\left(\frac{Q_{h}K_{h}^{\top}}{\sqrt{d}}\right) Ah=Softmax(dQhKh⊤) 计算( d = D / H d = D/H d=D/H,用于避免梯度消失),将所有头的注意力矩阵和值 V V V 分别拼接后,对 V V V 进行加权线性聚合得到 Z M H S A = A V ∈ R N × D Z^{MHSA}=AV \in \mathbb{R}^{N×D} ZMHSA=AV∈RN×D,计算出的注意力可引导模型关注视觉数据中最有价值的token。
- 下采样操作(Downsampling Operation):受CNNs分层架构成功的启发,一些研究将分层结构引入ViTs。将Transformer块划分为 M M M 个阶段,在每个Transformer阶段前应用下采样操作以减少序列长度。本文采用卷积核大小和步长都为2的卷积层进行下采样,这种方法可灵活调整特征图的尺度,构建类似人类视觉系统组织的Transformer分层结构。
少注意力框架-The Less-Attention Framework
这部分主要介绍了少注意力框架(The Less-Attention Framework )的设计,通过改变传统自注意力的计算方式,在减少计算量的同时缓解注意力饱和问题,具体内容如下:
- 整体框架:网络架构在每个阶段分两个阶段提取特征。在初始的几个普通注意力(VA)层,执行标准的多头自注意力(MHSA)操作,用于捕捉整体的长程依赖关系。
- 少注意力(LA)层计算:在后续的少注意力(LA)层,为降低二次计算复杂度和解决注意力饱和问题,通过对存储的注意力分数应用线性变换来模拟注意力矩阵。在第 m m m 阶段,第 l l l 个VA层( l ≤ L m V A l \leq L_{m}^{VA} l≤LmVA, L m V A L_{m}^{VA} LmVA 为该阶段VA层数量)在Softmax函数之前的注意力分数 A m V A , l A_{m}^{VA, l} AmVA,l,按照标准程序计算。在初始普通注意力阶段之后,放弃传统的二次复杂度的MHSA,对 A m V A A_{m}^{VA} AmVA 进行变换来减少注意力计算量。以第 m m m 阶段第 l l l 层( l > L m V A l > L_{m}^{VA} l>LmVA,即LA层)为例,注意力矩阵 A m l = Ψ ( Θ ( A m l − 1 ) ⊤ ) ⊤ A_{m}^{l}=\Psi\left(\Theta\left(A_{m}^{l - 1}\right)^{\top}\right)^{\top} Aml=Ψ(Θ(Aml−1)⊤)⊤,其中 Ψ \Psi Ψ 和 Θ \Theta Θ 是维度为 R N × N \mathbb{R}^{N×N} RN×N 的线性变换层,通过在两个线性层之间插入转置操作来保持矩阵相似性,避免单层线性变换按行操作可能导致的对角特征丢失。之后,通过 Z L A , l = S o f t m a x ( A m l ) V l Z^{LA, l}=Softmax\left(A_{m}^{l}\right)V^{l} ZLA,l=Softmax(Aml)Vl 得到该层输出。
基于残差的注意力下采样-Residual-based Attention Downsampling
这部分内容主要介绍了基于残差的注意力下采样方法,旨在解决分层ViTs跨阶段计算时,下采样操作导致的关键上下文信息丢失问题,具体内容如下:
- 设计背景:在分层ViTs中,跨阶段计算时对特征图进行下采样虽能减少token数量,但会丢失重要的上下文信息。而前一阶段学习到的注意力亲和力有助于当前阶段捕捉更复杂的全局关系。受ResNet引入捷径连接缓解特征饱和问题的启发,文章在架构中融入类似概念到下采样注意力计算中。
- Attention Residual(AR)模块设计:直接将捷径连接应用于注意力矩阵存在挑战,因为当前阶段和前一阶段的注意力维度不同。为此设计AR模块,包含深度可分离卷积(DWConv)和1×1卷积(Conv1×1)。以前一阶段(第
m
−
1
m - 1
m−1 阶段)最后一个注意力矩阵
A
m
−
1
l
a
s
t
A_{m - 1}^{last}
Am−1last (维度为
R
B
×
H
×
N
m
−
1
×
N
m
−
1
\mathbb{R}^{B×H×N_{m - 1}×N_{m - 1}}
RB×H×Nm−1×Nm−1,
N
m
−
1
N_{m - 1}
Nm−1 为该阶段token数量)为例,利用步长为2、内核大小为2的DWConv算子,将多头维度
H
H
H 视为常规图像空间的通道维度,捕捉注意力下采样过程中token之间的空间依赖关系,使输出矩阵尺寸适配当前阶段(
R
B
×
H
×
N
m
×
N
m
\mathbb{R}^{B×H×N_{m}×N_{m}}
RB×H×Nm×Nm,
N
m
=
N
m
−
1
/
2
N_{m}=N_{m - 1}/2
Nm=Nm−1/2 )。之后,通过Conv1×1操作在不同头之间交换信息。从
A
m
−
1
l
a
s
t
A_{m - 1}^{last}
Am−1last 到当前阶段下采样后的初始注意力矩阵
A
m
i
n
i
t
A_{m}^{init}
Aminit 的变换公式为
A
m
i
n
i
t
=
C
o
n
v
1
×
1
(
N
o
r
m
(
D
W
C
o
n
v
(
A
m
−
1
l
a
s
t
)
)
)
A_{m}^{init }=Conv_{1× 1}\left(Norm\left(DWConv\left(A_{m - 1}^{last }\right)\right)\right)
Aminit=Conv1×1(Norm(DWConv(Am−1last))).
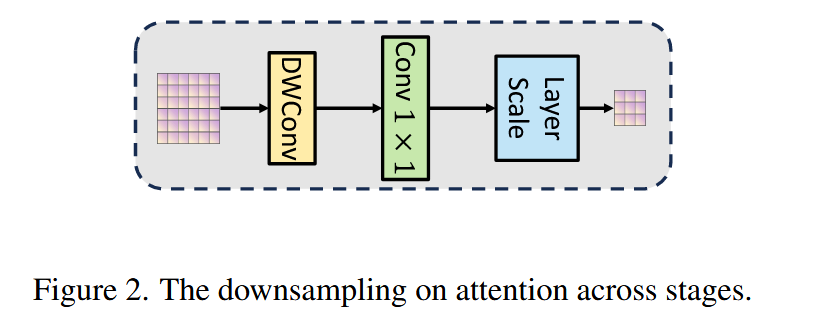
图2. 跨阶段注意力下采样。 - 注意力分数计算:第 m m m 阶段第一层的注意力分数 A m V A A_{m}^{VA} AmVA,是通过标准MHSA计算结果与上述残差计算结果相加得到,即 A m V A ← A m V A + L S ( A m i n i t ) A_{m}^{VA} \leftarrow A_{m}^{VA}+LS\left(A_{m}^{init}\right) AmVA←AmVA+LS(Aminit),其中 L S LS LS 是用于缓解注意力饱和的Layer-Scale算子。
- 设计原则与优势:该模块设计遵循两个原则,一是利用DWConv在采样时捕捉空间局部关系,有效压缩注意力关系;二是使用Conv1×1操作跨头交换注意力信息,促进前一阶段注意力向后一阶段高效传播。这种基于残差的注意力下采样模块只需对现有ViT骨干网络进行少量代码修改,可应用于各种Transformer架构,通过消融实验将进一步验证其重要性。
对角线保持损失-Diagonality Preserving Loss
这部分内容主要介绍了对角保持损失(Diagonality Preserving Loss)的设计原因、具体形式以及在模型训练中的应用,具体如下:
- 设计原因:在Transformer模块中引入注意力变换算子以降低计算成本和缓解注意力饱和问题,但线性变换按行处理注意力矩阵,可能会损害其捕捉token间相似性的能力。而常规注意力矩阵应具备对称性( A i j = A j i A_{ij}=A_{ji} Aij=Aji)和对角元素优势( A i i > A i j , ∀ j ≠ i A_{ii}>A_{ij},\forall j \neq i Aii>Aij,∀j=i)这两个基本属性,为保证变换后的注意力矩阵保留这些属性,从而准确传达token间的关系,设计了对角保持损失。
- 损失函数形式:第 l l l 层的对角保持损失 L D P , l \mathcal{L}_{DP, l} LDP,l,由两部分组成,公式为 L D P , l = ∑ i = 1 N ∑ j = 1 N ∣ A i j − A j i ∣ + ∑ i = 1 N ( ( N − 1 ) A i i − ∑ j ≠ i A j ) \mathcal{L}_{DP, l}=\sum_{i = 1}^{N}\sum_{j = 1}^{N}\left|A_{ij}-A_{ji}\right|+\sum_{i = 1}^{N}\left((N - 1)A_{ii}-\sum_{j \neq i}A_{j}\right) LDP,l=∑i=1N∑j=1N∣Aij−Aji∣+∑i=1N((N−1)Aii−∑j=iAj),其中第一部分用于保持矩阵的对称性,第二部分用于确保对角元素大于非对角元素,以维持对角元素优势。
- 在训练中的应用:将对角保持损失 L D P , l \mathcal{L}_{DP, l} LDP,l 添加到所有变换层,并与传统的交叉熵(CE)损失结合。模型训练的总损失为 L t o t a l = L C E + ∑ m = 1 M ∑ l = 1 L m L D P , l \mathcal{L}_{total }=\mathcal{L}_{CE}+\sum_{m = 1}^{M}\sum_{l = 1}^{L_{m}}\mathcal{L}_{DP, l} Ltotal=LCE+∑m=1M∑l=1LmLDP,l,其中 L C E = c r o s s − e n t r o p y ( Z C l s , y ) \mathcal{L}_{CE}= cross - entropy\left(Z_{Cls}, y\right) LCE=cross−entropy(ZCls,y), Z C l s Z_{Cls} ZCls 是最后一层表示中的分类token, y y y 是真实标签。
实验-Experiments
这部分内容主要通过在多个基准数据集上进行实验,评估了LaViT模型的性能,并通过消融实验探究了模型各组件的作用,具体如下:
- 实验设置
-
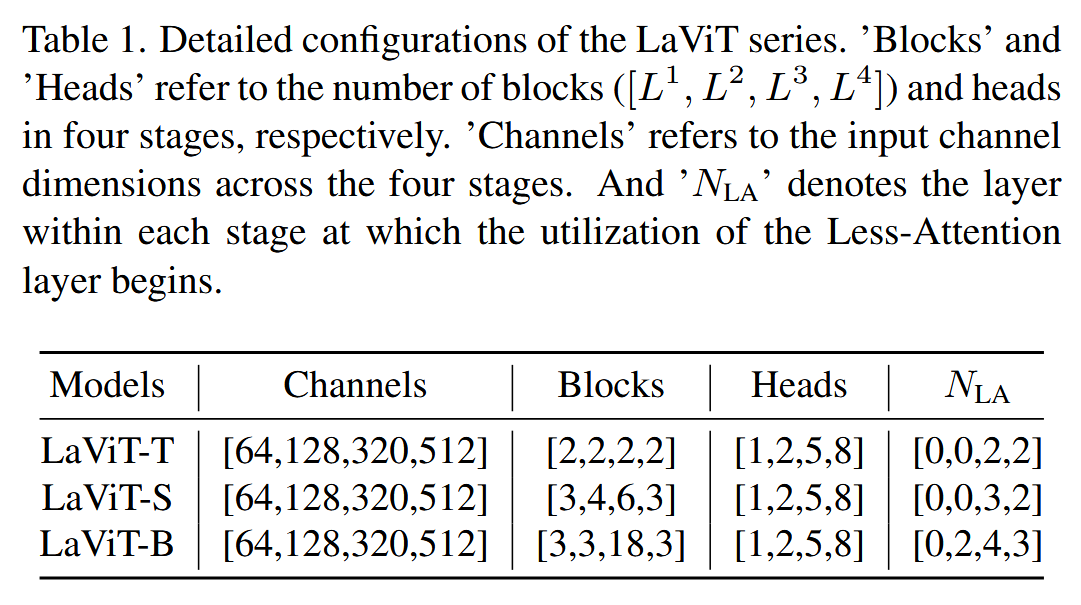
模型变体:为便于对比且保持计算复杂度相似,构建了LaViT-T、LaViT-S和LaViT-B三个模型,它们在块数、通道数、头数以及少注意力层起始位置等方面存在差异。
表1. LaViT系列的详细配置。“Blocks”(块数)和“Heads”(头数)分别指四个阶段中的块数( ( [ L 1 , L 2 , L 3 , L 4 ] ) ([L^{1}, L^{2}, L^{3}, L^{4}]) ([L1,L2,L3,L4]) )和头数。“Channels”(通道数)指四个阶段的输入通道维度。“ N L A N_{LA} NLA”表示每个阶段中开始使用少注意力层的层号。
-
基线模型:选择多种CNNs(如ResNet、RegNet、EfficientNet )、ViTs(如ViT、DeiT、CvT等)和高效ViTs(如HVT、PVT、DynamicViT等)作为基线模型。
-
- 实验结果
- 图像分类(ImageNet-1K):实验设置与DeiT相同,采用AdamW优化器训练300个epoch。结果显示,LaViT在不同计算复杂度的模型组中均表现出色,在tiny和small模型簇中,Top1准确率分别至少超越其他模型0.2%和0.5% ,且计算成本更低;在base-size模型中,性能优于基于PVT的模型。
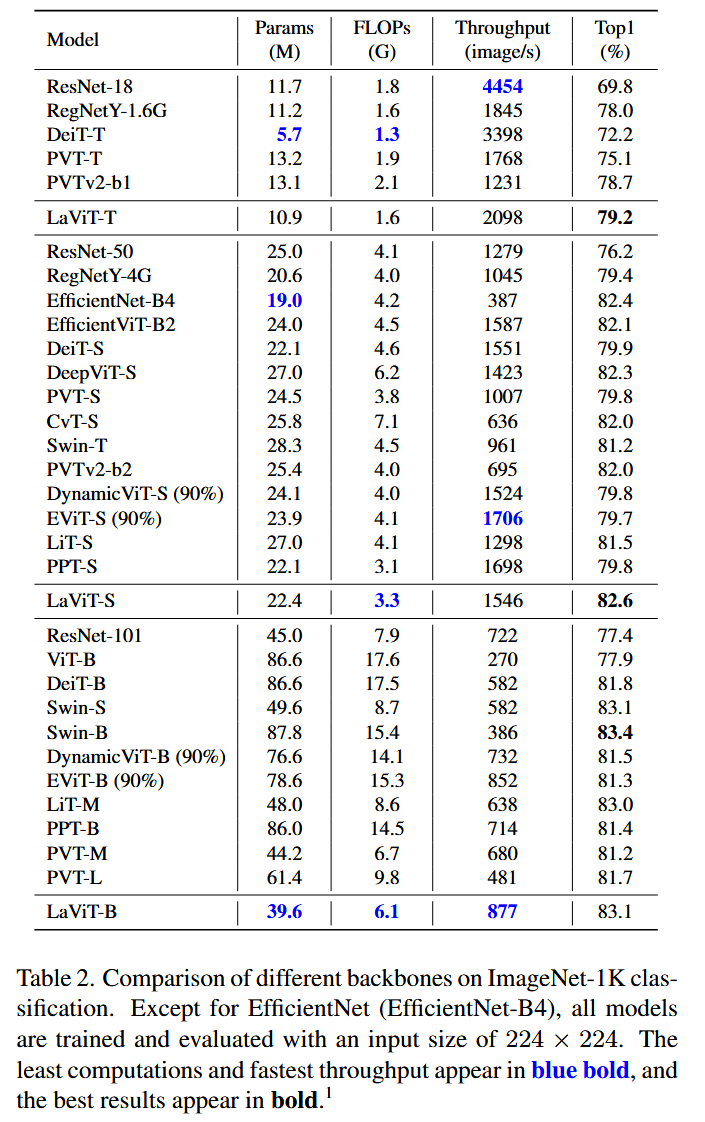
表2. ImageNet-1K分类任务中不同骨干网络的对比。除了EfficientNet(EfficientNet-B4)外,所有模型均以224×224的输入尺寸进行训练和评估。计算量最少和吞吐量最快的数据以蓝色加粗显示,最佳结果以加粗显示。 - 目标检测(COCO2017):基于RetinaNet框架,使用ImageNet-1K预训练权重,AdamW优化器训练。LaViT模型相比CNN和Transformer同类模型优势明显,如LaViT-T在1×训练调度下比ResNet的平均精度均值(AP)高9.9 - 12.5 ,且训练负担更小。
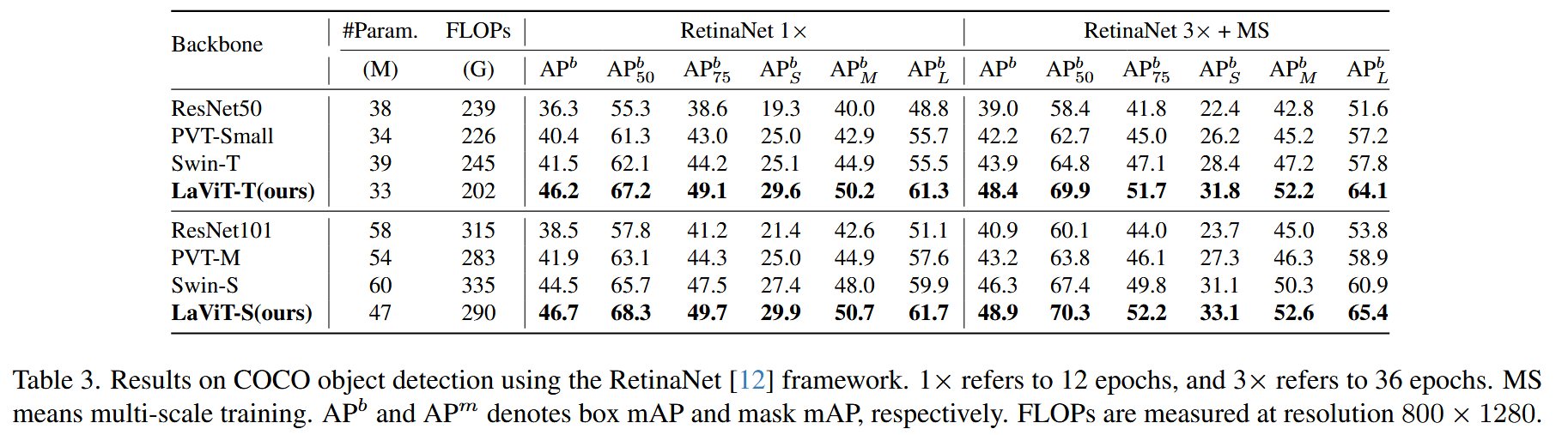
表3. 使用RetinaNet框架在COCO目标检测任务上的结果。1×表示训练12个epoch,3×表示训练36个epoch。MS表示多尺度训练。 A P b AP^{b} APb 和 A P m AP^{m} APm 分别表示边界框平均精度均值(box mAP)和掩码平均精度均值(mask mAP)。每秒浮点运算次数(FLOPs)是在分辨率为800×1280下测量的。 - 语义分割(ADE20K):以Semantic FPN和UperNet为骨干网络,按特定设置训练。LaViT在平均交并比(mIoU)指标上优于Swin Transformer,如LaViT-S在UperNet框架下比Focal-T的mIoU高1.4,MS mIOU高2.5。
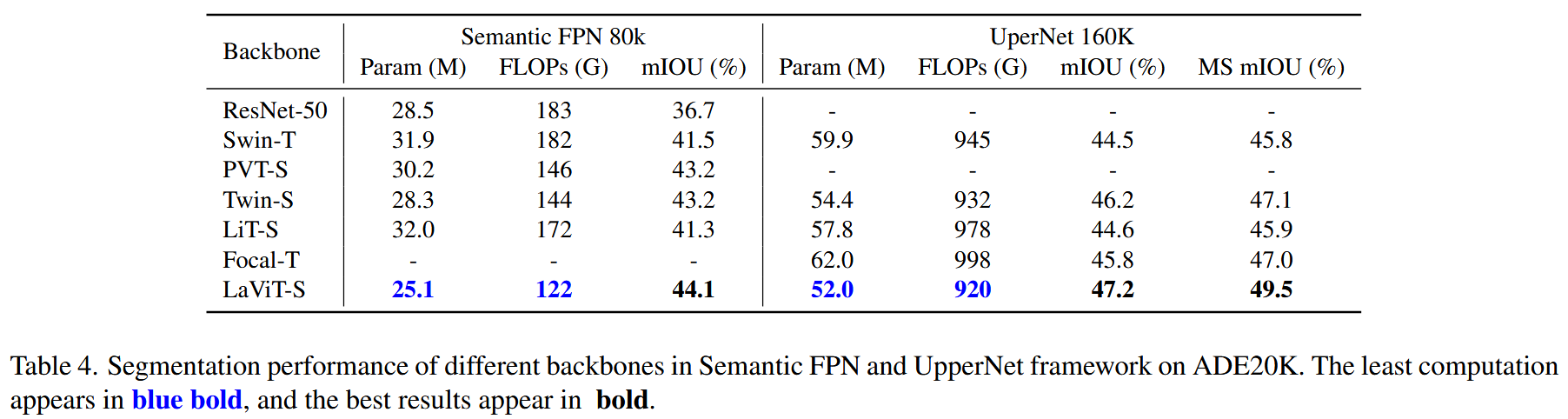
表4. 在ADE20K数据集上,不同骨干网络在语义特征金字塔网络(Semantic FPN)和UperNet框架中的分割性能。计算量最小的数据以蓝色加粗显示,最佳结果以加粗显示。
- 图像分类(ImageNet-1K):实验设置与DeiT相同,采用AdamW优化器训练300个epoch。结果显示,LaViT在不同计算复杂度的模型组中均表现出色,在tiny和small模型簇中,Top1准确率分别至少超越其他模型0.2%和0.5% ,且计算成本更低;在base-size模型中,性能优于基于PVT的模型。
- 消融实验
- 注意力饱和:对比使用ViT和PVT作为骨干网络时,有无LaViT模块的注意力相似比,结果表明LaViT有效缓解了注意力饱和问题。
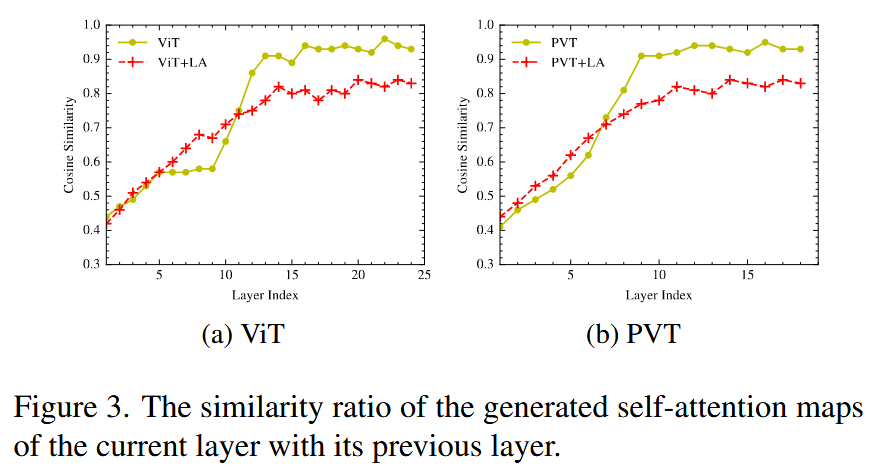
图3. 当前层生成的自注意力图与前一层的相似比。 - 模块扩展性:将少注意力模块应用于多种ViT架构,均提高了准确率并降低计算需求,在Vanilla ViT/DeiT架构上提升最显著,在DeepViT中计算资源下降最多。
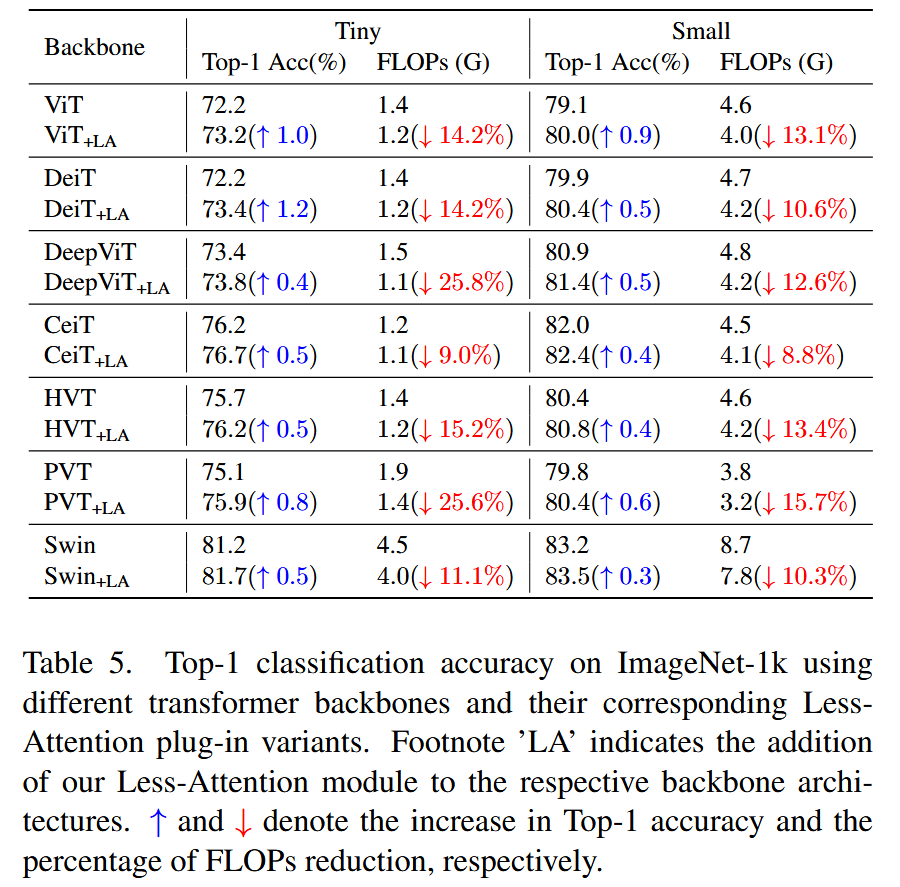
表5. 使用不同Transformer骨干网络及其相应的少注意力插件变体在ImageNet-1k上的Top-1分类准确率。脚注“LA”表示在相应的骨干网络架构中添加了我们的少注意力模块。“↑”和“↓”分别表示Top-1准确率的提升幅度和每秒浮点运算次数(FLOPs)的降低百分比。 - 各组件重要性:在ImageNet-1K数据集上的消融实验表明,少注意力层、注意力残差模块和对角保持损失函数对模型性能至关重要,去除这些组件会导致模型精度下降。
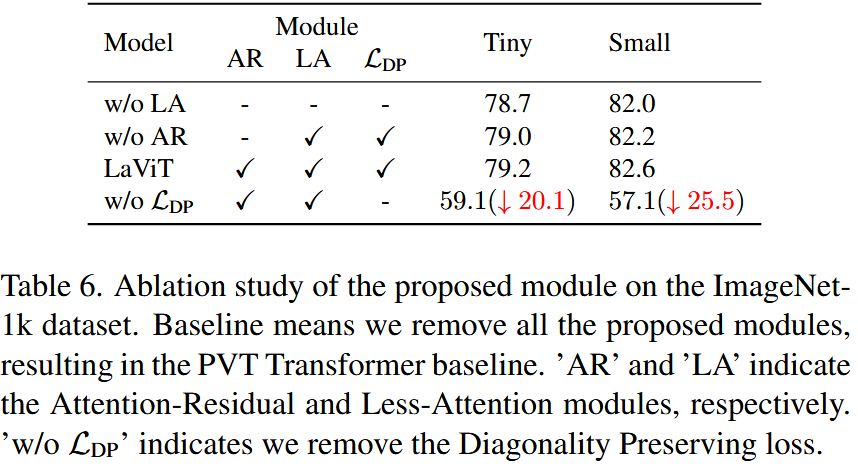
表6. 在ImageNet1k数据集上对所提模块的消融实验。基线表示我们移除了所有所提模块,得到PVT Transformer基线模型。“AR”和“LA”分别表示注意力残差模块和少注意力模块。“w/o L D P L_{DP} LDP”表示我们移除了对角保持损失。 - 少注意力层起始位置选择:实验发现,在阶段较深层使用少注意力层可平衡模型性能和计算成本,过早使用会降低模型性能,过晚使用则会增加计算成本。
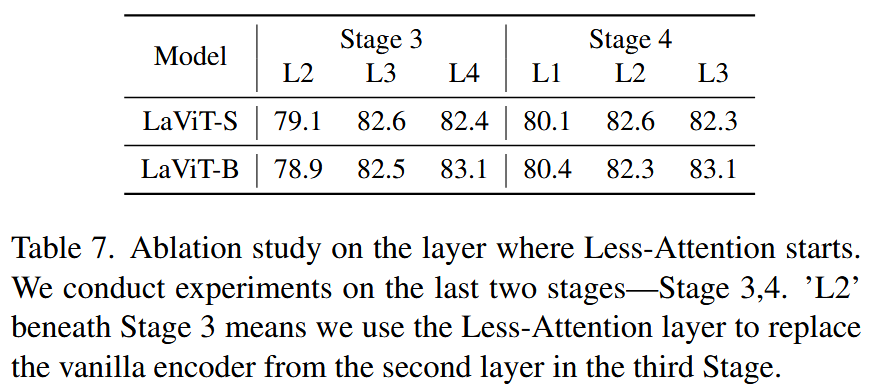
表7. 关于少注意力层起始位置的消融实验。我们在最后两个阶段——第3阶段和第4阶段进行实验。第3阶段下方的“L2”表示我们从第3阶段的第2层开始使用少注意力层替换普通编码器。
- 注意力饱和:对比使用ViT和PVT作为骨干网络时,有无LaViT模块的注意力相似比,结果表明LaViT有效缓解了注意力饱和问题。
结论-Conclusion
这部分内容总结了LaViT模型的设计目的、核心方法、性能优势以及实验验证结果,强调了其在计算机视觉领域的重要价值,具体如下:
- 模型设计目的与方法:旨在降低视觉Transformer(ViTs)中自注意力机制高昂的计算成本,提出了少注意力视觉Transformer(LaViT)。LaViT借助多头自注意力(MHSA)块中已计算的依赖关系,通过重用之前MSA块的注意力,绕过部分注意力计算。同时,引入对角保持损失函数,促使注意力矩阵在表示token间关系时表现更优。
- 模型性能优势:LaViT的Transformer架构能有效捕捉token间的关联。在参数数量和每秒浮点运算次数(FLOPs)方面,保持了高效的计算特性,在性能上超越了基线模型。
- 实验验证结果:大量实验证实了LaViT作为多种下游任务基础架构的有效性。在分类和分割等任务中,LaViT的性能优于以往的Transformer架构,达到了当前的领先水平。这表明LaViT为计算机视觉任务提供了一种高效且性能卓越的解决方案,具有重要的研究和应用价值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











