







CLIP is Strong Enough to Fight Back: Test-time Counterattacks towards Zero-shot Adversarial Robustness of CLIP

本文 “CLIP is Strong Enough to Fight Back: Test-time Counterattacks towards Zero-shot Adversarial Robustness of CLIP” 聚焦 CLIP 对抗攻击的鲁棒性问题,指出现有对抗训练和提示调整方法存在训练耗时、过拟合和损害干净图像分类精度等局限。提出测试时反击(TTC)范式,利用 CLIP 预训练视觉编码器反击对抗图像,实现鲁棒性,且无需训练。通过在 16 个数据集上实验,对比多种基线方法,结果表明 TTC 能显著提升对抗图像分类准确率(平均提升 36.47%),对干净图像准确率影响较小(平均下降 1.76%),在对抗微调模型上也能进一步增强鲁棒性,但该方法存在在部分对抗微调模型上增益不明显、推理计算开销大、攻击强度未知时难调参等局限 。
摘要-Abstract
Despite its prevalent use in image-text matching tasks in a zero-shot manner, CLIP has been shown to be highly vulnerable to adversarial perturbations added onto images. Recent studies propose to finetune the vision encoder of CLIP with adversarial samples generated on the fly, and show improved robustness against adversarial attacks on a spectrum of downstream datasets, a property termed as zero-shot robustness. In this paper, we show that malicious perturbations that seek to maximise the classification loss lead to ‘falsely stable’ images, and propose to leverage the pre-trained vision encoder of CLIP to counterattack such adversarial images during inference to achieve robustness. Our paradigm is simple and training-free, providing the first method to defend CLIP from adversarial attacks at test time, which is orthogonal to existing methods aiming to boost zero-shot adversarial robustness of CLIP. We conduct experiments across 16 classification datasets, and demonstrate stable and consistent gains compared to test-time defence methods adapted from existing adversarial robustness studies that do not rely on external networks, without noticeably impairing performance on clean images. We also show that our paradigm can be employed on CLIP models that have been adversarially finetuned to further enhance their robustness at test time.
尽管CLIP在零样本图像文本匹配任务中得到广泛应用,但它极易受到添加在图像上的对抗扰动的影响。最近的研究提出利用即时生成的对抗样本对CLIP的视觉编码器进行微调,结果显示在一系列下游数据集上,模型对抗攻击的鲁棒性有所提高,这一特性被称为零样本鲁棒性。在本文中,我们指出旨在最大化分类损失的恶意扰动会导致图像出现 “虚假稳定” 的现象,并提议在推理过程中利用CLIP的预训练视觉编码器对这类对抗图像进行反击,以实现鲁棒性。我们的方法简单且无需训练,是首个在测试时防御CLIP免受对抗攻击的方法,与现有的旨在提升CLIP零样本对抗鲁棒性的方法相互补充。我们在16个分类数据集上进行了实验,结果表明,与现有的不依赖外部网络的对抗鲁棒性研究中改编的测试时防御方法相比,我们的方法能实现稳定且持续的性能提升,同时不会显著降低在干净图像上的性能。我们还证明了我们的方法可以应用于经过对抗微调的CLIP模型,以在测试时进一步增强其鲁棒性。
引言-Introduction
这部分内容主要介绍研究背景和提出的新方法,具体如下:
- 研究背景与问题:随着图像-文本数据的丰富和自监督学习技术的进步,视觉语言模型(VLM)备受关注,CLIP作为代表性的VLM,能零样本匹配图像和文本。然而,研究发现给图像添加微小的不可察觉的扰动会使CLIP误分类,这引发了对基础模型安全性和可靠性的担忧,本文聚焦于CLIP对抗扰动的鲁棒性研究。
- 现有研究方法及局限:现有增强CLIP对抗鲁棒性的方法分为两类。一类是基于对抗训练的对抗微调(AFT),通过动态生成对抗图像微调CLIP的视觉编码器,虽能提升零样本鲁棒性,但存在训练耗时、模型过拟合以及干净图像分类精度下降的问题;另一类是基于提示调整的对抗提示调整(APT),在嵌入空间插入可学习文本token并调整,但同样存在训练方面的局限。
- 本文方法及贡献:受现有对抗鲁棒性研究中测试时防御方法的启发,提出一种测试时范式——利用CLIP的表达能力在测试时反击对抗攻击。该方法基于观察到的对抗图像的“虚假稳定性”,利用CLIP预训练视觉编码器将对抗图像从其有害嵌入中推离。同时提出 τ \tau τ-阈值加权反击方法,在不影响干净图像性能的前提下有效对抗攻击。此方法是首个利用CLIP自身能力进行测试时防御的方法,简单且无需训练,在16个分类数据集上实验效果显著,还可用于进一步提升对抗微调后CLIP模型的鲁棒性。

图1. 测试时反击利用CLIP的表达能力生成反击策略,在不微调视觉编码器的情况下保护CLIP免受攻击。
相关工作-Related Work
这部分内容主要回顾了与对抗鲁棒性和视觉语言模型(VLM)对抗鲁棒性相关的研究,具体如下:
- 对抗鲁棒性
- 对抗攻击现象:自深度学习发展早期,人们就发现神经网络易受对抗攻击,添加微小的、人类难以察觉且受 L p L_{p} Lp范数约束的对抗扰动,就能使网络对样本的分类出错。
- 防御方法:对抗训练(AT)通过实时生成对抗样本训练网络,提升了对抗攻击的鲁棒性,但存在训练成本高的问题。其他防御方法还包括测试时防御,如使用生成模型净化测试图像或基于目标调整测试图像,其中Hedge Defense(HD)与本文工作最为相关。HD基于损失函数在真实标签附近更平滑的发现,对测试图像进行反击,但它应用于对抗训练后的模型;而本文聚焦CLIP,强调CLIP无需对抗训练,自身就具备防御能力。
- VLMs及其对抗鲁棒性
- 研究现状:基础模型的对抗鲁棒性研究日益受到关注,本文聚焦于CLIP的对抗鲁棒性增强。
- 现有方法:现有增强CLIP对抗鲁棒性的方法主要有两类。一类是对抗微调,如Mao等人提出的TeCoA,利用动态生成的对抗样本微调CLIP的视觉编码器,并将学到的鲁棒性迁移到下游分类数据集;Wang等人在此基础上通过添加正则化项改进了模型在干净和对抗图像上的泛化能力。另一类是对抗提示调整,基于CLIP的提示调整,如Li等人发现文本提示在对抗攻击和鲁棒性中起重要作用,通过插入可学习token并调整来提升鲁棒性;Zhang等人也提出了类似方法。
- 本文创新:本文舍弃训练过程,提出CLIP可通过反击对抗图像来自卫,是首个针对CLIP的测试时防御方法。
方法-Methodology
预备知识与设置-Preliminaries and Setup
该部分主要介绍了CLIP在图像分类场景下的零样本分类方式、对抗攻击手段以及对抗微调增强鲁棒性的原理,为后续提出的测试时反击方法做铺垫,具体内容如下:
- CLIP的零样本分类:CLIP是通过4亿图像文本对对比预训练的视觉语言模型,它利用视觉编码器 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅) 和文本编码器 g ϕ ( ⋅ ) g_{\phi}(\cdot) gϕ(⋅) 分别生成图像和文本的表示,通过两者表示的余弦相似度来匹配图像与文本。在推理时,CLIP以零样本方式进行分类,对于给定的一组用文本名称定义的类别 c 1 , . . . , c K c_{1}, ..., c_{K} c1,...,cK,CLIP将测试图像 x x x 与由模板 T T T(通常为“a photo of [CLASS]”)包裹的候选类别名称对应的文本提示进行匹配,计算出相似度得分 s i s_{i} si,并通过归一化得到图像属于每个类别的概率 p i p_{i} pi,概率最高的候选类别即为预测类别。
- CLIP的对抗攻击:CLIP极易受到对抗扰动影响。在攻击者知晓CLIP模型权重和梯度的情况下,可恶意设计一个受
L
p
L_{p}
Lp-半径约束的小扰动
δ
\delta
δ,通过公式
δ
a
=
a
r
g
m
a
x
δ
L
(
x
+
δ
,
t
c
)
,
s
.
t
.
∥
δ
∥
p
≤
ϵ
a
\delta_{a}=arg max _{\delta} L\left(x+\delta, t_{c}\right), s.t. \| \delta\| _{p} \leq \epsilon_{a}
δa=argmaxδL(x+δ,tc),s.t.∥δ∥p≤ϵa 来使CLIP误分类,其中
t
c
t_{c}
tc 是图像
x
x
x 的真实标签,
L
L
L 通常为交叉熵损失函数,
ϵ
a
\epsilon_{a}
ϵa 是攻击预算,以确保扰动细微且难以被人察觉。该过程可通过投影梯度下降(PGD)近似,对抗图像则是原始图像与扰动的叠加
x
′
:
=
x
+
δ
a
x':=x+\delta_{a}
x′:=x+δa.
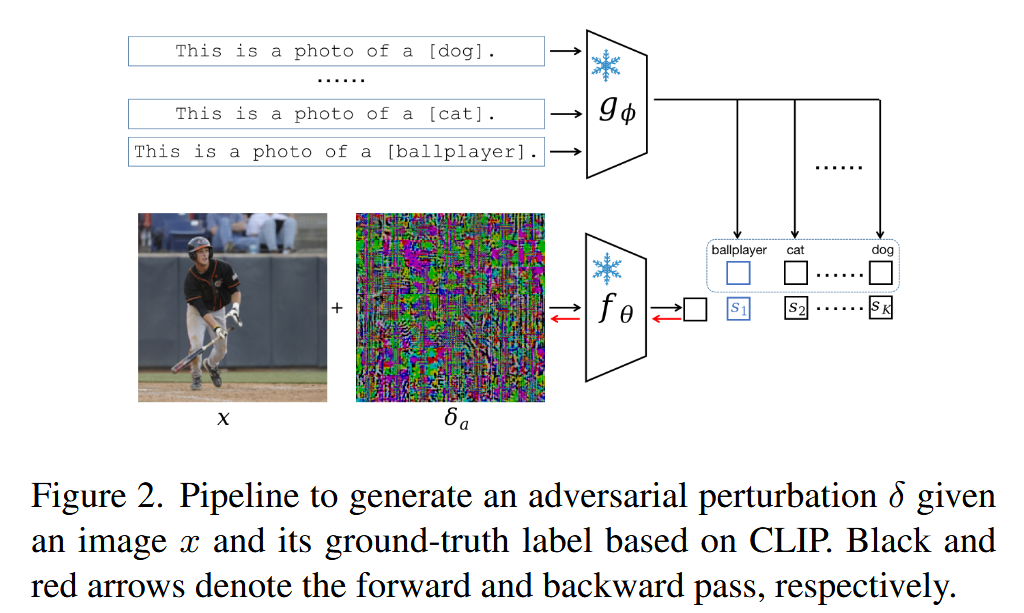
图2. 基于CLIP,给定图像 x x x 及其真实标签生成对抗扰动 δ δ δ 的流程。黑色箭头和红色箭头分别表示前向传播和反向传播。 - 对抗微调增强CLIP的对抗鲁棒性:对抗微调是增强CLIP对抗鲁棒性的一种方式,通过交替生成对抗图像(遵循上述对抗攻击公式),并利用这些对抗图像对视觉编码器 f θ f_{\theta} fθ 进行微调。例如,TeCoA方法在一个数据集上使对抗图像 x ′ x' x′ 与真实文本 T ( t c ) T(t_{c}) T(tc) 对齐进行微调;PMG-AFT方法则在TeCoA基础上施加两个CLIP引导的正则化项,以改善在干净和对抗图像上的泛化能力。经过微调后,CLIP学习到了对抗攻击的鲁棒性,并能在无需进一步训练的情况下迁移到下游分类数据集。
测试时反击-Test-time Counterattacks
该部分内容提出了测试时反击(Test-time Counterattacks,TTC)方法,用于增强CLIP在测试时对对抗攻击的防御能力,具体内容如下:
- 提出背景:虽然对抗微调能显著提高CLIP的对抗鲁棒性,但存在生成对抗样本和微调视觉编码器权重过程繁琐等问题。因此,本文探索CLIP在测试时自我防御的能力,提出了首个针对CLIP的测试时防御方法TTC。
- 基本原理:CLIP的预训练视觉编码器
f
θ
f_{\theta}
fθ 具有强大的图像特征捕捉能力。成功欺骗CLIP的对抗图像,可能被困在攻击者诱导的不利环境中,而预训练的
f
θ
f_{\theta}
fθ 可利用其表达能力引导图像摆脱这种环境。受无监督攻击方法启发,TTC以原始图像嵌入
f
θ
(
x
)
f_{\theta}(x)
fθ(x) 为锚点,通过最大化对抗攻击图像嵌入
f
θ
(
x
+
δ
t
t
c
)
f_{\theta}(x+\delta_{t t c})
fθ(x+δttc) 与锚点的
L
2
L_{2}
L2 距离,生成测试时反击扰动
δ
t
t
c
\delta_{t t c}
δttc,公式为
δ
t
t
c
=
a
r
g
m
a
x
δ
∥
f
θ
(
x
+
δ
)
−
f
θ
(
x
)
∥
,
s
.
t
.
∥
δ
∥
p
≤
ϵ
t
t
c
\delta_{t t c}=arg max _{\delta}\left\| f_{\theta}(x+\delta)-f_{\theta}(x)\right\| , s.t. \| \delta\| _{p} \leq \epsilon_{t t c}
δttc=argmaxδ∥fθ(x+δ)−fθ(x)∥,s.t.∥δ∥p≤ϵttc.
该过程同样可通过PGD近似,虽然反击不需要不可察觉,但为保持与现有研究一致的攻击风格,反击预算 ϵ t t c \epsilon_{t t c} ϵttc 仍受 L p L_{p} Lp-半径约束。实验表明, ϵ t t c = 4 / 255 \epsilon_{t t c}=4 / 255 ϵttc=4/255 时能显著提高CLIP的对抗鲁棒性,且整个过程中视觉编码器权重 θ \theta θ 保持不变。
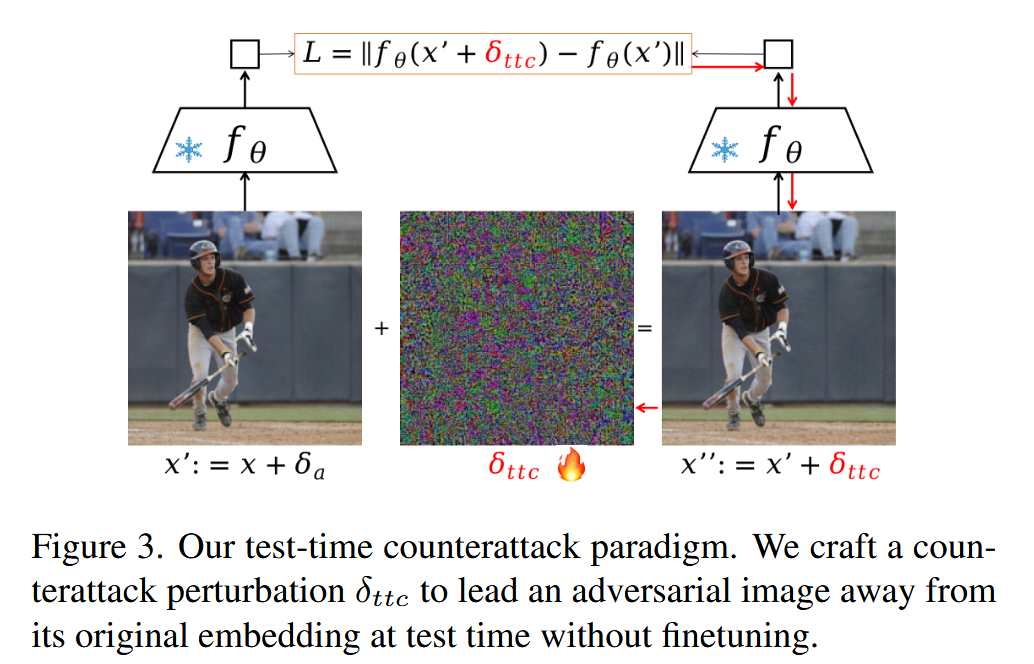
图3. 我们的测试时反击范式。在测试时,我们设计一个反击扰动 δ t t e \delta_{tte} δtte,在不进行微调的情况下,使对抗图像远离其原始嵌入。 - 与相关方法对比:在现有针对非基础模型的方法中,TTC与Hedge Defense(HD)最为相关。二者的重要区别在于,HD应用于对抗训练的模型,而TTC表明未经对抗微调的CLIP,也能利用其视觉编码器的表达能力进行自我防御。
τ τ τ 阈值加权反击- τ τ τ-thresholded Weighted Counterattacks
该部分内容在测试时反击(TTC)方法的基础上,提出了 τ τ τ-阈值加权反击方法,旨在有效对抗攻击的同时,降低对干净图像的影响,具体如下:
- 提出原因:TTC在利用CLIP预训练视觉编码器防御对抗攻击时,存在反击可能损害自然图像的风险。为解决该问题,基于TTC思想进一步提出 τ τ τ-阈值加权反击方法。
- 理论依据:研究发现,与干净图像相比,对抗图像对小随机噪声更具鲁棒性,仅在随机噪声足够大时才会变得脆弱。通过分析迭代攻击方法(如PGD)得到的对抗图像,定义了由随机噪声 n n n 诱导的随机变量 τ τ τ,公式为 τ = ∥ f θ ( x + n ) − f θ ( x ) ∥ ∥ f θ ( x ) ∥ \tau=\frac{\left\| f_{\theta}(x+n)-f_{\theta}(x)\right\| }{\left\| f_{\theta}(x)\right\| } τ=∥fθ(x)∥∥fθ(x+n)−fθ(x)∥,它表示在图像上施加随机噪声 n n n 时,潜在空间中 L 2 L_{2} L2 漂移的比例。实验结果显示,当添加小随机噪声( ϵ r a n d o m = 1 / 255 , 4 / 255 \epsilon_{random }=1 / 255,4 / 255 ϵrandom=1/255,4/255)时,对抗图像的 τ τ τ 值异常小,表明其被困在有害环境中,呈现“虚假稳定”状态;只有当随机噪声强度增加, τ τ τ 值才会大幅上升。
- 方法介绍:基于上述分析,提出基于PGD的 τ τ τ-阈值加权反击方法。在PGD迭代过程中,以公式(3)为攻击目标。在零次迭代时,先应用一个未经更新的随机扰动 δ t t c 0 \delta_{t t c}^{0} δttc0,并根据公式计算 τ τ τ 值作为指标。若 τ τ τ 值高于用户定义的阈值 τ t h r e s \tau_{thres} τthres,说明图像不是“虚假稳定”,则停止反击并返回随机噪声 δ t t c 0 \delta_{t t c}^{0} δttc0;否则继续反击。考虑到仅使用一个 δ t t c \delta_{t t c} δttc 可能不是最优选择,对所有步骤的反击扰动向量进行加权,权重公式为 w j = e x p ( β ⋅ j ) ∑ j = 0 N e x p ( β ⋅ j ) w_{j}=\frac{exp (\beta \cdot j)}{\sum_{j=0}^{N} exp (\beta \cdot j)} wj=∑j=0Nexp(β⋅j)exp(β⋅j),最终的反击扰动 δ t t c = ∑ j = 0 N w j δ t t c j \delta_{t t c}=\sum_{j=0}^{N} w_{j} \delta_{t t c}^{j} δttc=∑j=0Nwjδttcj,其中 β > 0 \beta>0 β>0 是控制权重上升速率的超参数, N N N 是反击的步数, δ t t c j \delta_{t t c}^{j} δttcj 是第 j j j 步得到的反击扰动。该方法总结在算法1中。
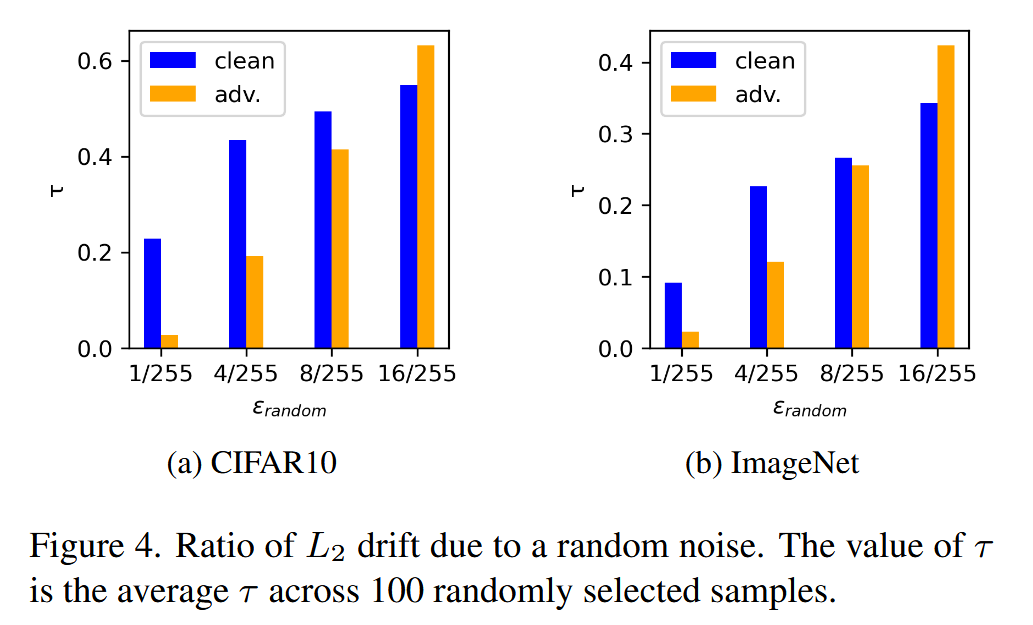
图4. 由随机噪声引起的
L
2
L_{2}
L2 漂移比率。
τ
τ
τ 的值是从100个随机选择的样本中计算出的平均
τ
τ
τ 值。

实验-Experiments
这部分主要通过一系列实验验证了测试时反击(TTC)范式的有效性,具体内容如下:
- 实验设置
- 数据集:选用16个数据集开展实验,包含通用物体识别、细粒度识别、场景识别以及领域特定数据集,所有数据集均按照CLIP的预处理流程进行处理。
- 实现细节:设定反击预算 ϵ t t c = 4 / 255 \epsilon_{ttc}=4/255 ϵttc=4/255、阈值 τ t h r e s = 0.2 \tau_{thres}=0.2 τthres=0.2,反击步数 N = 2 N = 2 N=2, β = 2.0 \beta = 2.0 β=2.0,且所有攻击和反击均受 L ∞ L_{\infty} L∞ 半径约束。
- 基线方法:由于缺乏针对CLIP的测试时防御方法,因此从现有对抗鲁棒性研究中选取了几种不依赖辅助网络的测试时方法作为基线,包括Anti-adversary、Hedge Defense(HD)、测试时变换集成(TTE)、随机噪声(RN)。同时,实现了对抗微调方法(TeCoA、PMG - AFT、FARE)和干净图像微调(CLIP - FT)作为参考。
- TTC在原始CLIP上的效果
-
ϵ
a
=
1
/
255
\epsilon_{a}=1/255
ϵa=1/255 时的鲁棒性:在攻击预算
ϵ
a
=
1
/
255
\epsilon_{a}=1/255
ϵa=1/255、10步PGD攻击下,TTC在大多数下游数据集上的对抗图像分类准确率最高,平均提升36.47% ,且对干净图像准确率影响较小(平均下降1.76% )。相比之下,其他测试时防御方法(如Anti - adversary和HD)对对抗准确率的提升有限,RN几乎无法提升鲁棒性,TTE虽能提升但不稳定。
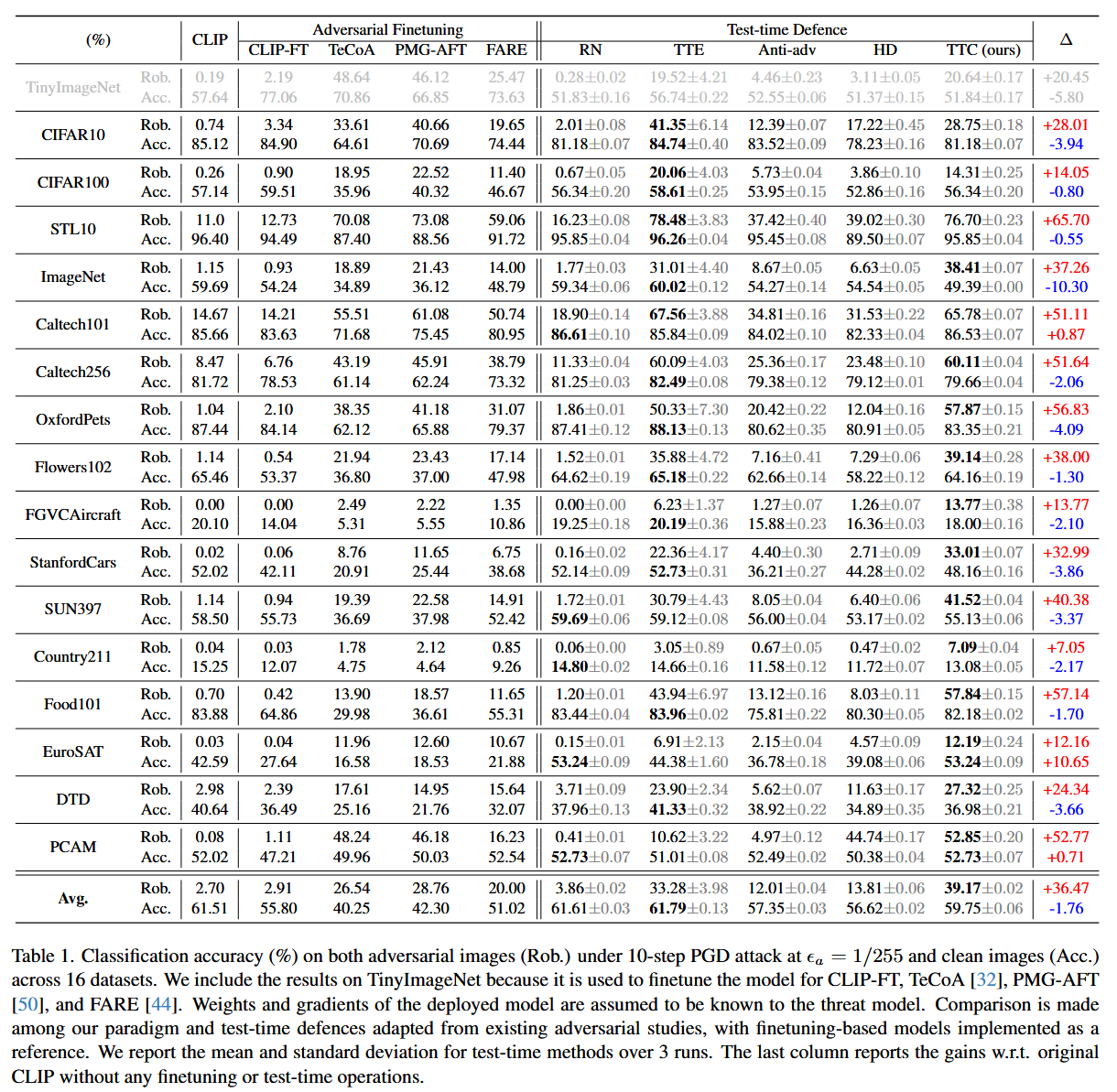
表1. 在攻击预算 ϵ a = 1 / 255 \epsilon_{a}=1/255 ϵa=1/255、10步投影梯度下降(PGD)攻击下对抗图像的分类准确率(Rob.,单位:%),以及16个数据集上干净图像的分类准确率(Acc.,单位:%)。我们纳入了TinyImageNet上的结果,因为它被用于对CLIP-FT、TeCoA、PMG-AFT和FARE的模型进行微调。假设威胁模型知晓所部署模型的权重和梯度。我们将我们的范式与从现有对抗研究中改编而来的测试时防御方法进行比较,并将基于微调的模型作为参考。我们报告测试时方法在3次运行中的平均值和标准差。最后一列报告相对于未进行任何微调或测试时操作的原始CLIP的准确率增益。 -
ϵ
a
=
4
/
255
\epsilon_{a}=4/255
ϵa=4/255 时的鲁棒性:在更高攻击预算
ϵ
a
=
4
/
255
\epsilon_{a}=4/255
ϵa=4/255 下,TTC仍能提供稳定的鲁棒性增益,而Anti - Adversary和HD在这种情况下几乎无法提供鲁棒性,TTE的防御效果有限且可靠性低。
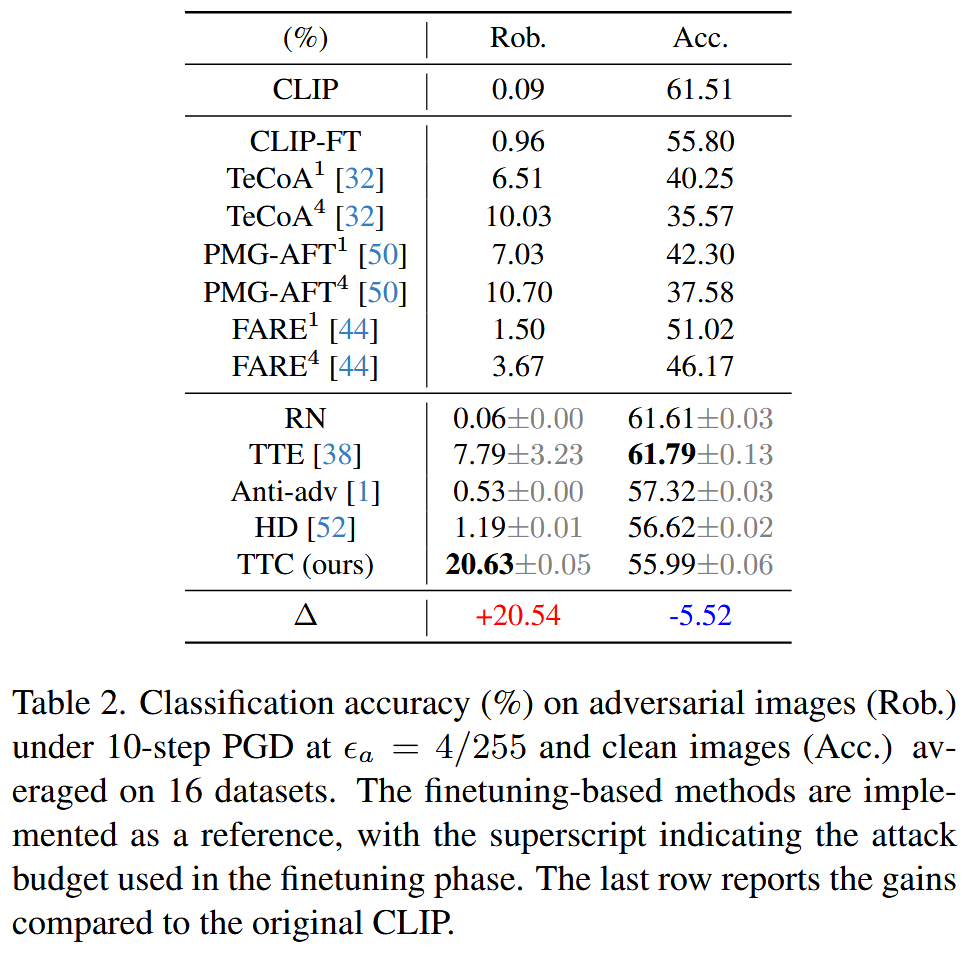
表2. 在攻击预算 ϵ a = 4 / 255 \epsilon_{a}=4/255 ϵa=4/255、10步投影梯度下降(PGD)攻击下对抗图像的分类准确率(Rob.,单位:%),以及16个数据集上干净图像的平均分类准确率(Acc.,单位:%)。基于微调的方法作为参考进行实施,上标表示微调阶段使用的攻击预算。最后一行报告与原始CLIP相比的准确率增益。
-
ϵ
a
=
1
/
255
\epsilon_{a}=1/255
ϵa=1/255 时的鲁棒性:在攻击预算
ϵ
a
=
1
/
255
\epsilon_{a}=1/255
ϵa=1/255、10步PGD攻击下,TTC在大多数下游数据集上的对抗图像分类准确率最高,平均提升36.47% ,且对干净图像准确率影响较小(平均下降1.76% )。相比之下,其他测试时防御方法(如Anti - adversary和HD)对对抗准确率的提升有限,RN几乎无法提升鲁棒性,TTE虽能提升但不稳定。
- TTC在对抗微调CLIP上的效果:TTC可应用于对抗微调后的CLIP模型,进一步提升其对抗鲁棒性。在TeCoA、PMG - AFT、FARE模型上应用TTC后,对抗鲁棒性准确率分别达到29.06% 、30.81% 、33.85% ,较原模型分别提升2.52、2.05、13.85个百分点。不过,对抗微调会降低CLIP对像素空间变化的敏感性,从而导致TTC在这些模型上的增益相比原始CLIP较小。
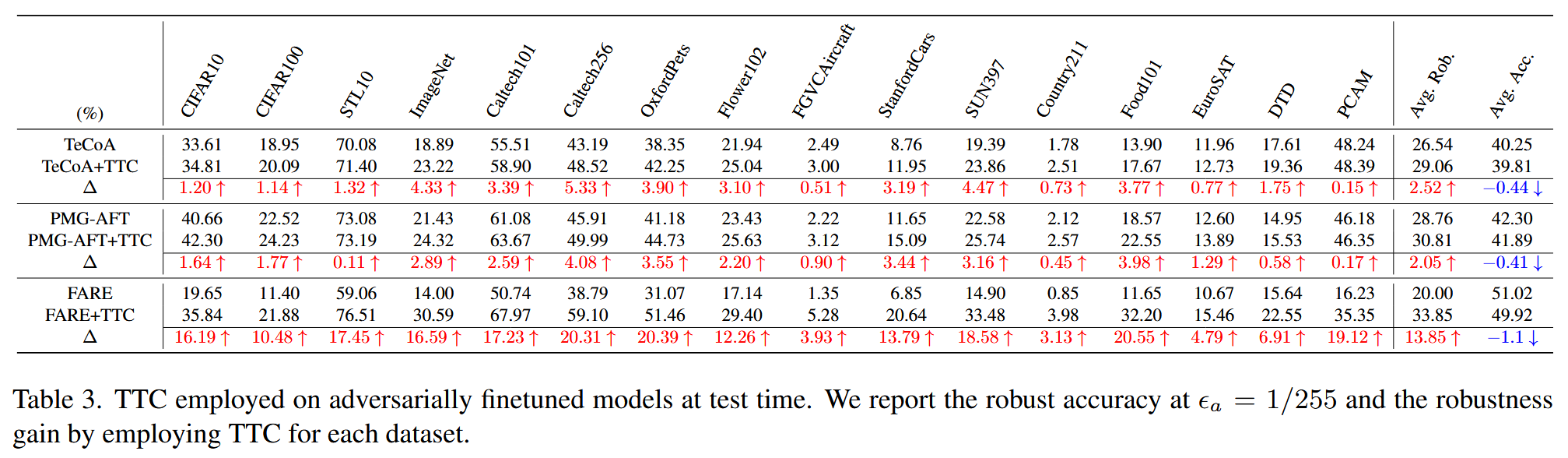
表3. 在测试时将TTC应用于对抗微调模型的结果。我们报告了在 ϵ a = 1 / 255 \epsilon_{a}=1 / 255 ϵa=1/255 时的鲁棒准确率,以及在每个数据集上应用TTC所带来的鲁棒性提升。 - 消融研究:反击步数
N
N
N 对TTC性能影响显著。对于较小攻击(
ϵ
a
=
1
/
255
\epsilon_{a}=1/255
ϵa=1/255 ),多数数据集上CLIP在少于三步的反击下就能有效防御,过多反击会损害图像;对于强攻击(
ϵ
a
=
4
/
255
\epsilon_{a}=4/255
ϵa=4/255 ),则需要更多反击步数才能达到合理准确率。此外,TTC在多数数据集上对干净图像准确率影响不大,但在部分数据集(如SUN397、OxfordPets、ImageNet)上,干净图像对
N
N
N 的增加较为敏感。
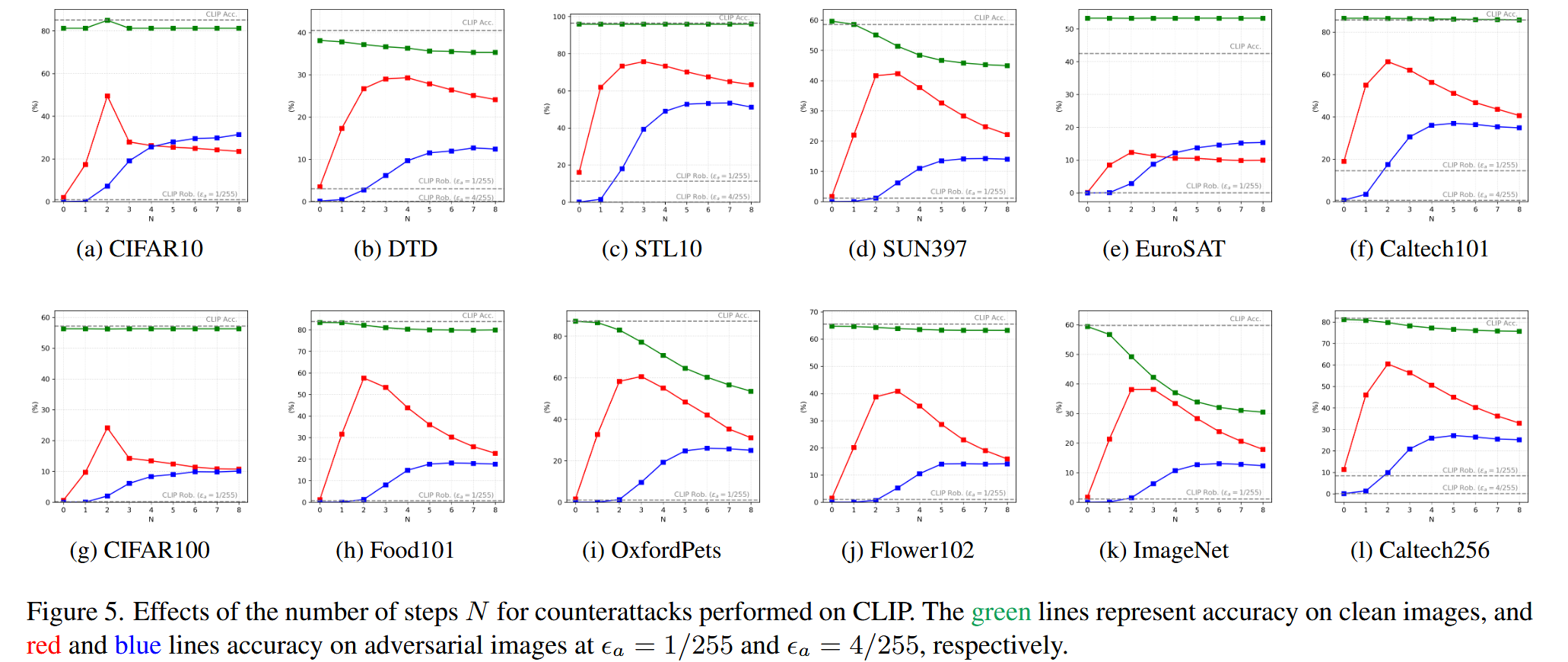
图5. 对CLIP进行反击时步数 N N N 的影响。绿色线条代表干净图像的准确率,红色和蓝色线条分别代表攻击预算 ϵ a = 1 / 255 \epsilon_{a}=1 / 255 ϵa=1/255 和 ϵ a = 4 / 255 \epsilon_{a}=4 / 255 ϵa=4/255 时对抗图像的准确率。
局限性-Limitations
这部分主要讨论了本文所提方法存在的局限性,具体内容如下:
- 在部分对抗微调模型上鲁棒性增益不明显:将TTC应用于TeCoA和PMG-AFT等对抗微调模型时,其鲁棒性提升效果不如在原始CLIP上显著。这是因为对抗微调会降低CLIP的表达能力,而TTC的效果依赖于CLIP预训练视觉编码器的表达能力。对于像CLIP这样学习了大量现实世界知识的大型预训练模型,应谨慎使用对抗微调,未来可探索协调对抗训练和TTC范式的方法,以在提高鲁棒性的同时减少对抗微调的使用。
- 推理时计算开销大且参数难调:虽然TTC不涉及对抗图像训练,但在推理时会增加计算成本。并且,反击步数N对鲁棒性有影响,若事先不知道攻击强度 ϵ a \epsilon_{a} ϵa,很难调整到最合适的N值。为避免过度反击和不必要的计算开销,在攻击未知时,建议采用较少的反击步数(不超过三步)。未来可探索根据测试图像调整步数的方法。
- 可能被自适应攻击破解:根据传统模型对抗鲁棒性研究,测试时防御可能会被自适应攻击绕过。假设攻击者知晓部署的CLIP模型权重和用户执行的TTC操作,文中在附录部分探讨了攻击者可能采用的自适应攻击方式,这种攻击可能会打破TTC的反击防御。
结论-Conclusion
这部分内容对研究成果进行总结,并对未来研究方向提出展望,具体如下:
- 研究成果总结:研究表明CLIP可利用自身预训练视觉编码器,在测试时通过反击对抗攻击来抵御旨在最大化其损失的恶意操纵,且无需依赖任何辅助网络。基于对抗图像“虚假稳定”的发现,提出 τ τ τ-阈值反击方法,引导对抗图像在潜在空间中远离其原始嵌入。在16个数据集上的实验显示,TTC在对抗图像上实现了稳定且可观的准确率,同时在对抗微调的CLIP模型上进一步增强了鲁棒性。
- 对抗微调的问题及建议:研究发现用对抗图像微调CLIP会降低其自身的表达能力,因此建议谨慎使用对抗微调作为增强大型预训练模型鲁棒性的唯一方法。
- 研究意义及展望:该研究提出的范式是首个无需任何微调就能在推理时防御CLIP的测试时方法,希望能推动未来对CLIP鲁棒化方法的研究,探索替代对抗微调的有效途径。


















 171
171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











