






1. 问题背景
大模型微调的挑战:
预训练模型(如GPT-3、LLaMA)参数量巨大(数十亿至万亿级),直接微调所有参数:
-
计算开销大:需更新全部权重,GPU显存不足。
-
存储冗余:每个任务需保存独立的全量模型副本。
2. LoRA的核心思想

3. 参数初始化策略
| 矩阵 | 初始化方法 | 目的 |
|---|---|---|
| A | 随机高斯分布(均值为0) | 打破对称性,提供多样化的梯度方向,避免所有神经元学习相同特征。 |
| B | 全零初始化 | 确保训练开始时 ΔW=0ΔW=0,模型行为与预训练一致,稳定训练。 |

为什么矩阵B初始化为零?
核心目标:训练稳定性
-
初始状态一致性:
微调开始时,保证模型行为与预训练模型完全一致: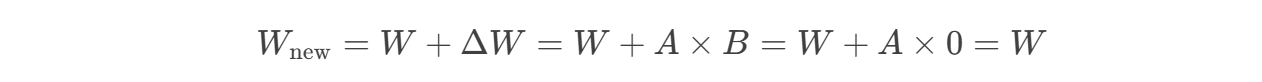
-
类比:如同汽车改装,先保持原厂配置(W),再逐步加装新部件(ΔW),避免直接飙车失控。
-
避免的问题
-
性能突变:
若初始 ΔW≠0,模型可能立即偏离预训练学到的知识(如GPT-3突然忘记如何造句)。 -
梯度爆炸:
随机初始化的 A 和 B 乘积可能产生数值不稳定的梯度。
实验支持
-
论文实验显示:零初始化 BB 可使初始损失与预训练模型相差不足0.1%,而非零初始化可能差50%+。
为什么矩阵A随机初始化?
核心目标:探索多样性
-
打破对称性:
随机高斯初始化(如PyTorch默认的Kaiming初始化)确保:
![]()
联合作用机制
训练动态示例

类比说明
-
B=0B=0:如同汽车油门初始置零,确保启动时不突然加速。
-
AA随机:如同方向盘初始角度各异,确保车辆可灵活转向不同方向。
4. 为什么有效?
(1) 内在低秩性(Intrinsic Low-Rankness)
-
理论依据:大模型的权重变化矩阵 ΔWΔW 通常是低秩的(少数主成分主导变化)。
-
实验验证:在Transformer中,仅调整 r=8 的LoRA即可接近全参数微调效果。
(2) 参数效率
-
参数量对比:
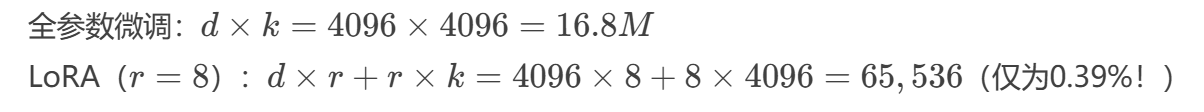
(3) 任务切换便捷性
-
不同任务只需替换轻量的 AA 和 BB(几MB),共享同一预训练模型 WW。
5. 实际应用示例
(1) Hugging Face PEFT库实现
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=8, # 秩
lora_alpha=16, # 缩放因子 α
target_modules=["q", "v"], # 应用于Query和Value层的LoRA
lora_dropout=0.1,
)
model = get_peft_model(pretrained_model, config) # 原始模型参数被冻结
(2) 训练参数量统计
model.print_trainable_parameters() # 输出示例:trainable params: 262,144 || all params: 6,742,016,000 || trainable%: 0.0039
LoRA通过低秩分解和增量更新,实现了:
✅ 高效微调:仅训练0.1%-1%的参数。
✅ 即插即用:无需修改原始模型架构。
✅ 多任务共享:快速切换任务适配器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









