







一.DNS解析的详细步骤
当用户在浏览器中输入一个网址(如www.example.com)并按下回车键时,DNS解析过程开始。
- 客户端查询:首先,客户端(如浏览器或操作系统)会检查本地缓存,看是否已经保存了该域名的IP地址。如果缓存中有记录,则直接使用该IP地址进行连接。
- 本地DNS服务器查询:如果本地缓存中没有找到对应的IP地址,客户端会向本地配置的DNS服务器发送查询请求。本地DNS服务器收到请求后,也会首先检查自己的缓存,看是否有该域名的记录。
- 迭代查询与递归查询:如果本地DNS服务器缓存中没有找到答案,它会开始进行迭代查询或递归查询。迭代查询中,本地DNS服务器会向根域名服务器查询顶级域名服务器的地址,然后再向顶级域名服务器查询权威域名服务器的地址,最后向权威域名服务器查询域名的IP地址。递归查询则是本地DNS服务器代替客户端进行全程查询,直到找到最终的IP地址,然后一次性返回给客户端。
- 根域名服务器查询:在迭代查询中,本地DNS服务器首先会向根域名服务器发送查询请求。根域名服务器会返回顶级域名服务器(如.com和.net等)的地址。
- 顶级域名服务器查询:本地DNS服务器根据根域名服务器返回的地址,向顶级域名服务器发送查询请求。顶级域名服务器会返回权威域名服务器的地址,这个服务器负责管理具体域名的IP地址信息。
- 权威域名服务器查询:本地DNS服务器再向权威域名服务器发送查询请求。权威域名服务器会返回所查询域名的IP地址。
- 返回结果:本地DNS服务器收到权威域名服务器返回的IP地址后,会将这个地址缓存起来,并返回给客户端。客户端收到IP地址后,就可以使用这个地址与目标服务器建立连接,访问网站或服务了。
二.绕过CDN查找主机真实IP的方法
CDN概念
CDN (内容分发网络) 是一组分布在各个地区的服务器,这些服务器存储着数据的副本,能够根据用户距离最近的服务器来满足数据请求。通俗来讲,CDN就是用来加速访问的。
CDN绕过技巧
1.验证是否存在CDN
- 使用多地ping服务:通过多地ping服务检查目标IP地址是否唯一。如果不唯一,多半使用了CDN。使用工具从不同地理位置ping一个网站,并返回不同的IP地址。若返回的IP地址不一致,则可能是使用了CDN。
这里使用了工具多个地点Ping服务器,网站测速 - 站长工具,ping了一下baidu.com


- 使用nslookup命令:利用nslookup命令检测域名解析的IP地址数量。如果解析结果中有多个IP地址,说明使用了CDN。查找发现一个无CDN的网址:xiaodi8.com


2.绕过CDN查找网站真实IP
- 查询历史DNS记录:通过查询历史DNS记录,可以找到使用CDN前的IP地址。这里使用了工具 VenusEye威胁情报中心

- 查询子域名:CDN成本较高,很多站长只对主站或流量大的子站点使用CDN。通过查询子域名找到其真实IP。使用了微步在线(微步在线X情报社区-威胁情报查询_威胁分析平台_开放社区):


- 网络空间引擎搜索:使用网络空间搜索引擎(如Shodan、Fofa)查找目标网站的真实IP。Fofa搜索:输入title:"网站的title关键字"或body:"网站的body特征"这些搜索引擎能够搜索和索引互联网上的设备和服务,通过特定的关键词和特征或者是网站源码,可以找到与目标网站相关的真实IP。
- 利用SSL证书:SSL证书可以暴露真实IP。通过扫描互联网获取SSL证书,进而找到服务器的真实IP
- 利用HTTP标头:通过比较HTTP标头来查找原始服务器。例如,使用SecurityTrails平台搜索特定HTTP标头。
- 利用网站返回的内容:如果原始服务器IP也返回了网站的内容,那么可以在网上搜索大量的相关数据。浏览网站源代码,寻找独特的代码片段。在JavaScript中使用具有访问或标识符参数的第三方服务(例如Google Analytics,reCAPTCHA)是攻击者经常使用的方法
- 使用国外主机解析域名:国内很多CDN只做国内线路,使用国外的主机访问域名可能获取到真实IP,看下国外的服务器ping的ip是否是同一个
- 网站漏洞查找:
遗留文件:如phpinfo页面泄露,可能会显示服务器的外网IP地址。
漏洞探针:如SSRF漏洞,可以通过目标网站上的漏洞让VPS获取对方反向连接的IP地址,还有就是XSS盲打、命令执行反弹shell等 - 网站邮件订阅查找:查看RSS邮件订阅的邮件源码,通常包含服务器的真实IP。
- 全网扫描:
判断厂商:(ipip)——缩小ip范围
通过ip库查询:纯真数据库——确认ip段
通过网站特征进行爆破——就是通过网站特征来一个一个ip爆破 - F5 LTM解码法:通过解码F5 LTM负载均衡器的Set-Cookie字段,获取真实IP。
三.子域名信息收集常用手段
子域名挖掘工具
空间测绘(fofa):网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统

360空间测绘:360网络空间测绘 — 因为看见,所以安全
子域名挖掘机:GitHub - euphrat1ca/LayerDomainFinder: Layer子域名挖掘机
在线子域名爆破工具:在线子域名爆破 - 渗透安全团队:starpoc.vip

ZoomEye查询工具:ZoomEye - Cyberspace Search Engine

chinaz子域名查询工具:子域名查询 - 站长工具
whois查询工具(查看域名的注册信息、联系人、DNS服务器等):Whois.com - Domain Names & Identity for Everyone

四.Nmap全端口扫描
Nmap是一款强大的网络扫描和安全审计工具,它能够通过发送精心设计的网络数据包来探测目标主机上开放的端口、服务版本、操作系统类型等信息,帮助用户发现潜在的安全漏洞和弱点。Nmap支持多种扫描技术和协议,能够灵活应对不同的网络环境和安全需求。
实践:T4 +快速模式 端口扫描,扫描本地回环

思考题:说明SYN半开扫描的原理和跳过主机存活检测扫描使用常见?
答:
- SYN半开扫描的原理:扫描主机向目标主机的各个TCP端口发送SYN请求,但并不完成TCP三次握手的全部过程。如果目标主机的某个端口处于监听状态,它会对SYN请求回复SYN/ACK应答。扫描主机在收到SYN/ACK应答后,并不会继续发送ACK包以完成TCP连接,而是立即发送RST(复位)包中断连接。通过这种方法,扫描主机能够判断出目标主机上哪些端口是开放的,而无需建立完整的TCP连接。这种扫描方式速度较快,且不易被目标主机上的应用程序日志记录,因为连接并未完全建立。

- 跳过主机存活检测扫描使用常见:
1.使用-Pn参数(不ping)可以跳过主机存活检测,直接对目标主机进行扫描
2.使用-sL参数(列表扫描)虽然不会真正发送任何数据包到目标主机,但它会列出指定网络上的所有主机地址,所以也可以被视为一种跳过主机存活检测的扫描方式,尽管它并不提供关于主机存活状态或端口开放情况的任何信息。
五.dirmap目录探测工具实践
Dirmap是一款用于网络安全的目录探测工具,它通过自动化地发送HTTP请求并分析响应来发现Web服务器上的隐藏目录和敏感文件,帮助安全研究人员和渗透测试人员识别潜在的安全漏洞。
实践:探测本地搭建的pikachu靶机目录


高级应用:
1.编辑项目根目录下的dirmap.conf,进行配置

参数配置参考详解
#递归扫描处理配置
[RecursiveScan]
#是否开启递归扫描:关闭:0;开启:1
conf.recursive_scan = 0
#遇到这些状态码,开启递归扫描。默认配置[301,403]
conf.recursive_status_code = [301,403]
#URL超过这个长度就退出扫描
conf.recursive_scan_max_url_length = 60
#这些后缀名不递归扫
conf.recursive_blacklist_exts = ["html",'htm','shtml','png','jpg','webp','bmp','js','css','pdf','ini','mp3','mp4']
#设置排除扫描的目录。默认配置空。其他配置:e.g:['/test1','/test2']
#conf.exclude_subdirs = ['/test1','/test2']
conf.exclude_subdirs = ""
#扫描模式处理配置(4个模式,1次只能选择1个)
[ScanModeHandler]
#字典模式:关闭:0;单字典:1;多字典:2
conf.dict_mode = 1
#单字典模式的路径
conf.dict_mode_load_single_dict = "dict_mode_dict.txt"
#多字典模式的路径,默认配置dictmult
conf.dict_mode_load_mult_dict = "dictmult"
#爆破模式:关闭:0;开启:1
conf.blast_mode = 0
#生成字典最小长度。默认配置3
conf.blast_mode_min = 3
#生成字典最大长度。默认配置3
conf.blast_mode_max = 3
#默认字符集:a-z。暂未使用。
conf.blast_mode_az = "abcdefghijklmnopqrstuvwxyz"
#默认字符集:0-9。暂未使用。
conf.blast_mode_num = "0123456789"
#自定义字符集。默认配置"abc"。使用abc构造字典
conf.blast_mode_custom_charset = "abc"
#自定义继续字符集。默认配置空。
conf.blast_mode_resume_charset = ""
#爬虫模式:关闭:0;开启:1
conf.crawl_mode = 0
#用于生成动态敏感文件payload的后缀字典
conf.crawl_mode_dynamic_fuzz_suffix = "crawl_mode_suffix.txt"
#解析robots.txt文件。暂未实现。
conf.crawl_mode_parse_robots = 0
#解析html页面的xpath表达式
conf.crawl_mode_parse_html = "//*/@href | //*/@src | //form/@action"
#是否进行动态爬虫字典生成。默认配置1,开启爬虫动态字典生成。其他配置:e.g:关闭:0;开启:1
conf.crawl_mode_dynamic_fuzz = 1
#Fuzz模式:关闭:0;单字典:1;多字典:2
conf.fuzz_mode = 0
#单字典模式的路径。
conf.fuzz_mode_load_single_dict = "fuzz_mode_dir.txt"
#多字典模式的路径。默认配置:fuzzmult
conf.fuzz_mode_load_mult_dict = "fuzzmult"
#设置fuzz标签。默认配置{dir}。使用{dir}标签当成字典插入点,将http://target.com/{dir}.php替换成Target : Expect More. Pay Less.字典中的每一行.php。其他配置:e.g:{dir};{ext}
#conf.fuzz_mode_label = "{ext}"
conf.fuzz_mode_label = "{dir}"
#处理payload配置。暂未实现。
[PayloadHandler]
#处理请求配置
[RequestHandler]
#自定义请求头。默认配置空。其他配置:e.g:test1=test1,test2=test2
#conf.request_headers = "test1=test1,test2=test2"
conf.request_headers = ""
#自定义请求User-Agent。默认配置chrome的ua。
conf.request_header_ua = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
#自定义请求cookie。默认配置空,不设置cookie。其他配置e.g:cookie1=cookie1; cookie2=cookie2;
#conf.request_header_cookie = "cookie1=cookie1; cookie2=cookie2"
conf.request_header_cookie = ""
#自定义401认证。暂未实现。因为自定义请求头功能可满足该需求(懒XD)
conf.request_header_401_auth = ""
#自定义请求方法。默认配置get方法。其他配置:e.g:get;head
#conf.request_method = "head"
conf.request_method = "get"
#自定义每个请求超时时间。默认配置3秒。
conf.request_timeout = 3
#随机延迟(0-x)秒发送请求。参数必须是整数。默认配置0秒,无延迟。
conf.request_delay = 0
#自定义单个目标,请求协程线程数。默认配置30线程
conf.request_limit = 30
#自定义最大重试次数。暂未实现。
conf.request_max_retries = 1
#设置持久连接。是否使用session()。暂未实现。
conf.request_persistent_connect = 0
#302重定向。默认False,不重定向。其他配置:e.g:True;False
conf.redirection_302 = False
#payload后添加后缀。默认空,扫描时,不添加后缀。其他配置:e.g:txt;php;asp;jsp
#conf.file_extension = "txt"
conf.file_extension = ""
#处理响应配置
[ResponseHandler]
#设置要记录的响应状态。默认配置[200],记录200状态码。其他配置:e.g:[200,403,301]
#conf.response_status_code = [200,403,301]
conf.response_status_code = [200]
#是否记录content-type响应头。默认配置1记录
#conf.response_header_content_type = 0
conf.response_header_content_type = 1
#是否记录页面大小。默认配置1记录
#conf.response_size = 0
conf.response_size = 1
#是否自动检测404页面。默认配置True,开启自动检测404.其他配置参考e.g:True;False
#conf.auto_check_404_page = False
conf.auto_check_404_page = True
#自定义匹配503页面正则。暂未实现。感觉用不着,可能要废弃。
#conf.custom_503_page = "page 503"
conf.custom_503_page = ""
#自定义正则表达式,匹配页面内容
#conf.custom_response_page = "([0-9]){3}([a-z]){3}test"
conf.custom_response_page = ""
#跳过显示页面大小为x的页面,若不设置,请配置成"None",默认配置“None”。其他大小配置参考e.g:None;0b;1k;1m
#conf.skip_size = "0b"
conf.skip_size = "None"
#代理选项
[ProxyHandler]
#代理配置。默认设置“None”,不开启代理。其他配置e.g:{"http":"http://127.0.0.1:8080","https":"https://127.0.0.1:8080"}
#conf.proxy_server = {"http":"http://127.0.0.1:8080","https":"https://127.0.0.1:8080"}
conf.proxy_server = None
#Debug选项
[DebugMode]
#打印payloads并退出
conf.debug = 0
#update选项
[CheckUpdate]
#github获取更新。暂未实现。
conf.update = 0思考题:为什么dirmap每次扫描条数不一样?
答:
配置因素:dirmap扫描机制、字典文件内容、用户配置以及扫描策略等
其他因素:网络状况、服务器响应速度和目网站的安全策略等因素
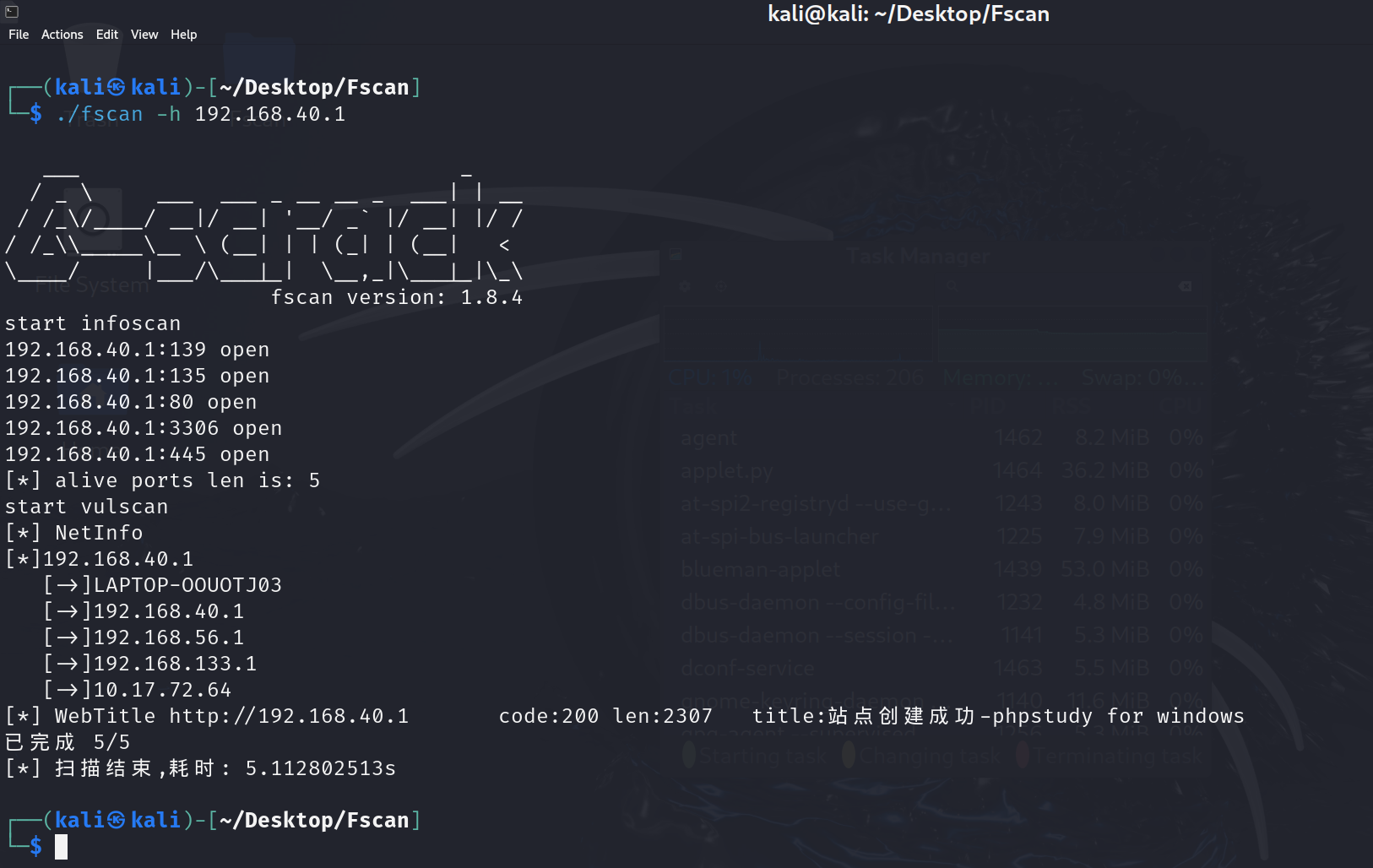
六.Fscan实践
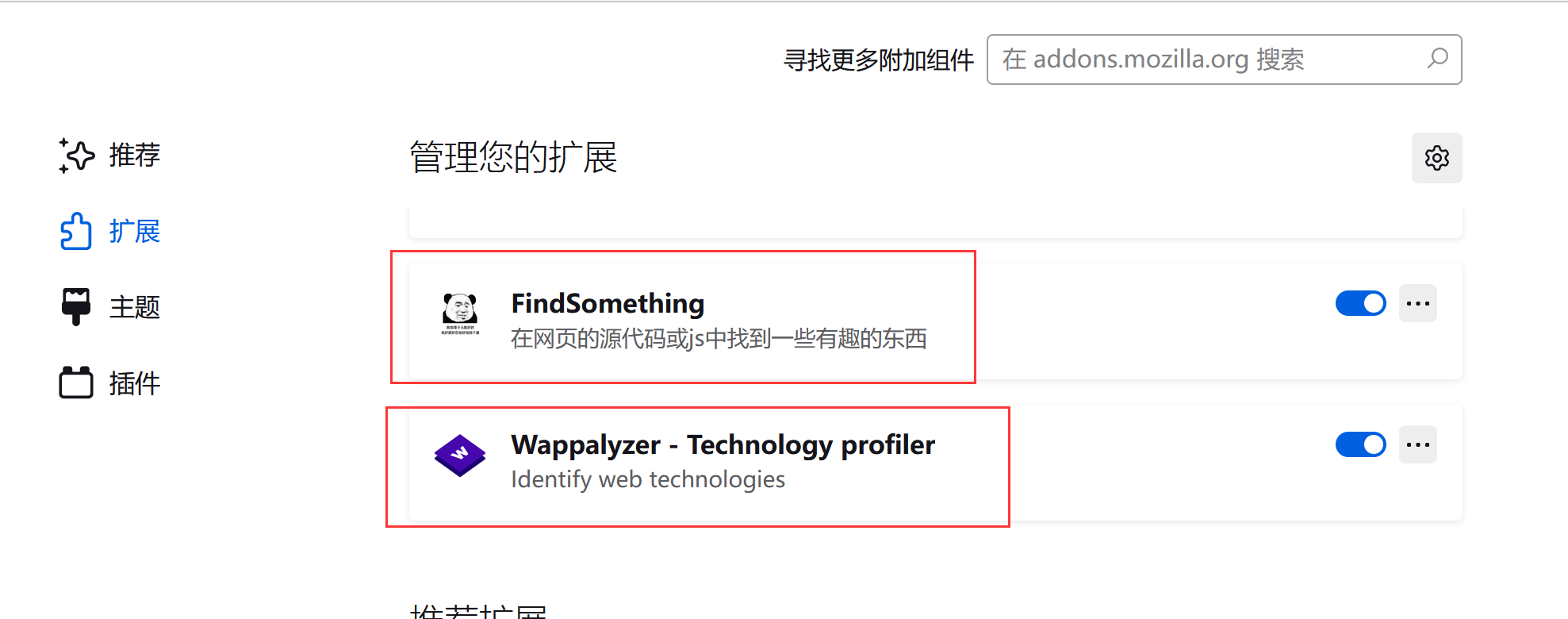
七.课上所演示插件安装成功截图
















 2215
2215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









