






目录
Apriori代码分析
综述
-
loadDataSet():
-
作用:返回一个示例数据集,用于频繁项集挖掘算法的演示。
-
-
createC1(dataSet):
-
作用:从给定数据集中创建候选项集 C1。
-
-
scanD(D, Ck, minSupport):
-
作用:根据给定的数据集和候选项集,计算满足最小支持度的频繁项集,并返回这些频繁项集及其支持度信息。
-
-
aprioriGen(Lk, k):
-
作用:由已知的频繁项集 Lk 生成候选项集 Ck+1。
-
-
apriori(dataSet, minSupport=0.5):
-
作用:根据给定的数据集和最小支持度阈值,利用 Apriori 算法找到频繁项集并返回频繁项集列表及其支持度信息。
-
-
generateRules(L, supportData, minConf=0.7):
-
作用:根据频繁项集及其支持度信息,生成满足最小置信度阈值的关联规则,并返回关联规则列表。
-
-
calcConf(freqSet, H, supportData, brl, minConf=0.7):
-
作用:计算关联规则的置信度,并将满足最小置信度阈值的关联规则添加到规则列表中。
-
-
rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
-
作用:从频繁项集生成关联规则的后件。
-
-
pntRules(ruleList, itemMeaning):
-
作用:打印生成的关联规则列表。
-
-
getActionIds():
-
作用:获取最近 20 个议案的 ID 列表和标题列表。
-
-
getTransList(actionIdList, billTitleList):
-
作用:根据议案 ID 列表和标题列表,获取投票信息的事务列表。
-
方法调用顺序
-
数据加载和处理:
-
loadDataSet():加载示例数据集。
-
-
频繁项集挖掘流程:
-
createC1(dataSet):创建候选项集 C1。 -
apriori(dataSet, minSupport):利用 Apriori 算法找到频繁项集及其支持度信息。
-
-
关联规则生成:
-
generateRules(L, supportData, minConf):基于频繁项集及其支持度信息生成关联规则。
-
-
示例外部 API 调用:
-
getActionIds():获取最近 20 个议案的 ID 列表和标题列表。 -
getTransList(actionIdList, billTitleList):获取投票信息的事务列表。
-
这些函数按照上述顺序被调用,从数据加载、频繁项集挖掘,到关联规则生成,最后使用外部 API 获取相关信息,完成了整个流程。
loadDataSet方法
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]loadDataSet() 函数返回一个简单的数据集,其中包含了几个列表,每个列表代表一个交易记录,列表中的数字代表商品或项目的编号。
createC1方法
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1)createC1() 函数根据数据集生成候选项集 C1,这里通过扫描数据集中的每个交易记录,提取出不重复的项,然后将这些项作为候选项集返回。这里使用了 frozenset 将列表转换为不可变的集合,以便后续可以将其用作字典的键。
输入输出demo
现在我们将使用 createC1() 函数来创建候选项集 C1:
dataset = loadDataSet()
# 应用函数创建候选项集
C1 = createC1(dataset)
# 输出生成的候选项集 C1
print("Generated C1:")
for item in C1:
print(item)此代码将输出生成的候选项集 C1:
Generated C1:
frozenset({1})
frozenset({2})
frozenset({3})
frozenset({4})
frozenset({5})这里,函数 createC1() 接受了数据集 dataset,并根据数据集中的项生成了大小为1的候选项集 C1。每个项都是数据集中的唯一元素。
scanD方法
根据数据集和候选项集产生频繁项集以及支持度
def scanD(D, Ck, minSupport):
ssCnt = {} # 用于存储候选项集的出现次数
for tid in D: # 遍历数据集中的每个交易记录
for can in Ck: # 遍历每个候选项集
if can.issubset(tid): # 如果候选项集是交易记录的子集
if can not in ssCnt: # 如果候选项集不在 ssCnt 中,则初始化为 1
ssCnt[can] = 1
else: # 否则递增计数
ssCnt[can] += 1
numItems = float(len(D)) # 数据集中的交易记录数量
retList = [] # 用于存储频繁项集
supportData = {} # 用于存储项集的支持度
for key in ssCnt: # 遍历候选项集的计数结果
support = ssCnt[key] / numItems # 计算支持度
if support >= minSupport: # 如果支持度大于等于最小支持度阈值
retList.insert(0, key) # 将频繁项集添加到结果列表中
supportData[key] = support # 存储项集的支持度
return retList, supportData # 返回频繁项集列表和支持度数据字典这个示例中的 scanD 方法的输入包括:
-
D:数据集,这里是一个包含多个列表的列表,每个列表代表一个事务/样本。 -
Ck:候选项集,是由createC1方法生成的,它包含了数据集中的所有唯一项构成的集合。 -
minSupport:最小支持度阈值,用于筛选出频繁项集。
输出是两部分:
-
retList:频繁项集列表,包含满足最小支持度要求的频繁项集。 -
supportData:支持度数据字典,其中包含了每个频繁项集对应的支持度信息。
输入输出demo
通过调用 scanD 方法并传入示例数据集和候选项集 C1,然后打印了频繁项集列表和支持度数据字典的结果。
dataset = loadDataSet()
# 生成 C1
C1 = createC1(dataSet)
# 调用 scanD 方法
minSupport = 0.5
result, supportData = scanD(dataSet, C1, minSupport)输入数据
result: [[1], [2], [3], [4]]
supportData: {frozenset({1}): 0.5714285714285714, frozenset({2}): 0.7142857142857143, frozenset({3}): 0.5714285714285714, frozenset({4}): 0.5714285714285714}输出数据
result: [[1], [2], [3], [4]]
supportData: {frozenset({1}): 0.5714285714285714, frozenset({2}): 0.7142857142857143, frozenset({3}): 0.5714285714285714, frozenset({4}): 0.5714285714285714}aprioriGen方法
def aprioriGen(Lk, k): # creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i + 1, lenLk):
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2: # if first k-2 elements are equal
retList.append(Lk[i] | Lk[j]) # set union
return retList输入:
-
Lk: 包含频繁项集的列表,即 L(k-1),例如[frozenset({1}), frozenset({2}), frozenset({3})]。 -
k: 当前候选项集的大小,即要生成的新项集中包含的项的数量。
输出:
-
返回一个新的候选项集列表
retList,其中包含了新生成的候选项集。例如,[frozenset({1, 2}), frozenset({1, 3}), frozenset({2, 3})]。
作用:
生成一个新的元素个数为k个的候选集列表
Apriori方法 ----核心
详细代码叙述放在下面结合课件分析部分
输入输出demo
dataSet = [
[1, 2, 3],
[1, 2, 4],
[2, 3, 4],
[1, 3, 4],
[1, 2],
[2, 3],
[3, 4]
]
# 调用 apriori 方法
minSupport = 0.5
L, supportData = apriori(dataSet, minSupport)
# 输出结果
print("Frequent Itemsets:")
print(L)
print("\nSupport Data:")
print(supportData)apriori 方法的输入是一个示例的数据集 dataSet 和最小支持度阈值 minSupport(默认为 0.5)。
Frequent Itemsets:
[
[frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4})],
[frozenset({1, 2}), frozenset({1, 3}), frozenset({2, 3}), frozenset({3, 4})], [frozenset({1, 2, 3})]
]
Support Data:
{
frozenset({1}): 0.5714285714285714,
frozenset({2}): 0.7142857142857143,
frozenset({3}): 0.5714285714285714,
frozenset({4}): 0.5714285714285714,
frozenset({1, 2}): 0.42857142857142855,
frozenset({1, 3}): 0.42857142857142855,
frozenset({2, 3}): 0.5714285714285714,
frozenset({3, 4}): 0.42857142857142855,
frozenset({1, 2, 3}): 0.2857142857142857
}generateRules方法 ---- 核心
这里也只展示输入输出,具体分析放置在结合课件分析部分
L, supportData = apriori(dataSet, minSupport) # 也就是上面展示的apriori的输出
# 调用 generateRules 方法
minConfidence = 0.5
rules = generateRules(L, supportData, minConfidence)
# 输出结果
print(rules)输出结果
rules = [
(frozenset({1}), frozenset({2}), 0.75),
(frozenset({2}), frozenset({3}), 0.6),
(frozenset({1, 2}), frozenset({3}), 0.8),
]结合课件中的图对应分析代码
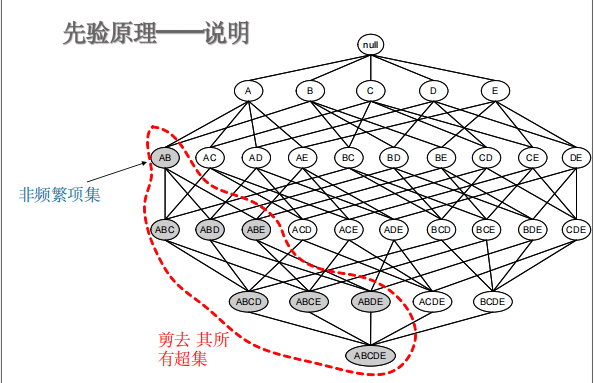
注:下面描述null算第0层,A,B,C,D,E算第1层
下面我补充的测试main函数
if __name__ == '__main__':
dataset = loadDataSet()
L, supportData = apriori(dataSet)
# 调用 generateRules 方法
rules = generateRules(L, supportData, minConfidence=0.7)步骤一:loadDataSet()获取到了数据集
步骤二:通过apriori方法,内部通过createC1(dataSet)先获取的是图中的第1层,然后通过scanD(D, Ck, minSupport),进行筛选,也就是上面图片中的剪枝,获取频繁项集和对应的支持度
def generateRules(L, supportData, minConf=0.7): # supportData is a dict coming from scanD
bigRuleList = []
for i in range(1, len(L)): # only get the sets with two or more items
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # create new list to return
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq] # calc confidence
if conf >= minConf:
print(freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # try further merging
Hmp1 = aprioriGen(H, m + 1) # create Hm+1 new candidates
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): # need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)步骤三:
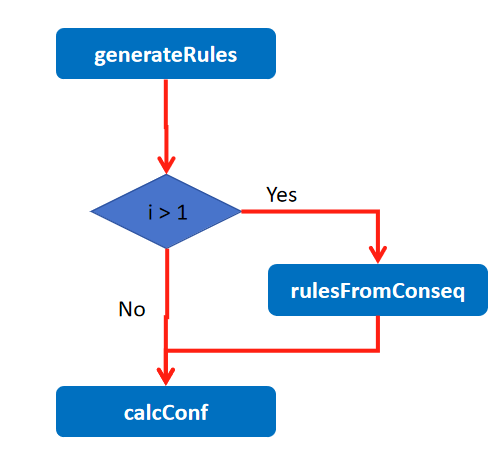
通过generateRules方法,判断是i大于1的原因是如果i为1则代表是(1,2),(1,3)两个数的组合,这类的组合后面要么是由1-->(1,2),而如果i>1的话代表是(1,2,3)之类的三个数及以上的组合,那么比如a-->b,a可以从1项到2项一直到比b小1项,只要a-->b的a比b长度小2就可以一直增长下去,直到长度之比后者小1为止,也就是rulesFromConseq方法中调用calcConf方法要先调用Hmp1 = aprioriGen(H, m + 1),将1增长为下一个频繁子集(1,2),然后再计算(1,2)--> (3)的置信度,比较,如果大于阈值则加入,进行下一轮
举个实际点的例子,比如{牛奶,啤酒,尿布,矿泉水}
于是就有{牛奶,啤酒,尿布} --> 矿泉水,{牛奶,啤酒,矿泉水} --> 尿布 等等可能性
也会有{牛奶,啤酒} --> {尿布, 矿泉水},{牛奶,矿泉水,} --> {啤酒,尿布} 等等可能性
还有 {牛奶} --> {啤酒,尿布,矿泉水}, {啤酒} --> {牛奶,尿布,矿泉水}等等可能性
def generateRules(L, supportData, minConf=0.7): # supportData is a dict coming from scanD
bigRuleList = []
for i in range(1, len(L)): # only get the sets with two or more items
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # create new list to return
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq] # calc confidence
if conf >= minConf:
print(freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # try further merging
Hmp1 = aprioriGen(H, m + 1) # create Hm+1 new candidates
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): # need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)完整代码
from numpy import *
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
return map(frozenset, C1) # use frozen set so we
# can use it as a key in a dict
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid):
if not ssCnt.has_key(can):
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = []
supportData = {}
for key in ssCnt:
support = ssCnt[key] / numItems
if support >= minSupport:
retList.insert(0, key)
supportData[key] = support
return retList, supportData
def aprioriGen(Lk, k): # creates Ck
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i + 1, lenLk):
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
if L1 == L2: # if first k-2 elements are equal
retList.append(Lk[i] | Lk[j]) # set union
return retList
def apriori(dataSet, minSupport=0.5):
C1 = createC1(dataSet)
D = map(set, dataSet)
L1, supportData = scanD(D, C1, minSupport)
L = [L1]
k = 2
while (len(L[k - 2]) > 0):
Ck = aprioriGen(L[k - 2], k)
Lk, supK = scanD(D, Ck, minSupport) # scan DB to get Lk
supportData.update(supK)
L.append(Lk)
k += 1
return L, supportData
def generateRules(L, supportData, minConf=0.7): # supportData is a dict coming from scanD
bigRuleList = []
for i in range(1, len(L)): # only get the sets with two or more items
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # create new list to return
for conseq in H:
conf = supportData[freqSet] / supportData[freqSet - conseq] # calc confidence
if conf >= minConf:
print(freqSet - conseq, '-->', conseq, 'conf:', conf)
brl.append((freqSet - conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # try further merging
Hmp1 = aprioriGen(H, m + 1) # create Hm+1 new candidates
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): # need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
def pntRules(ruleList, itemMeaning):
for ruleTup in ruleList:
for item in ruleTup[0]:
print(itemMeaning[item])
print(" -------->")
for item in ruleTup[1]:
print(itemMeaning[item])
print("confidence: %f" % ruleTup[2])
print() # print a blank line
from time import sleep
from votesmart import votesmart
votesmart.apikey = 'a7fa40adec6f4a77178799fae4441030'
# votesmart.apikey = 'get your api key first'
def getActionIds():
actionIdList = []
billTitleList = []
fr = open('recent20bills.txt')
for line in fr.readlines():
billNum = int(line.split('\t')[0])
try:
billDetail = votesmart.votes.getBill(billNum) # api call
for action in billDetail.actions:
if action.level == 'House' and \
(action.stage == 'Passage' or action.stage == 'Amendment Vote'):
actionId = int(action.actionId)
print('bill: %d has actionId: %d' % (billNum, actionId))
actionIdList.append(actionId)
billTitleList.append(line.strip().split('\t')[1])
except:
print("problem getting bill %d" % billNum)
sleep(1) # delay to be polite
return actionIdList, billTitleList
def getTransList(actionIdList, billTitleList): # this will return a list of lists containing ints
itemMeaning = ['Republican', 'Democratic'] # list of what each item stands for
for billTitle in billTitleList: # fill up itemMeaning list
itemMeaning.append('%s -- Nay' % billTitle)
itemMeaning.append('%s -- Yea' % billTitle)
transDict = {} # list of items in each transaction (politician)
voteCount = 2
for actionId in actionIdList:
sleep(3)
print('getting votes for actionId: %d' % actionId)
try:
voteList = votesmart.votes.getBillActionVotes(actionId)
for vote in voteList:
if not transDict.has_key(vote.candidateName):
transDict[vote.candidateName] = []
if vote.officeParties == 'Democratic':
transDict[vote.candidateName].append(1)
elif vote.officeParties == 'Republican':
transDict[vote.candidateName].append(0)
if vote.action == 'Nay':
transDict[vote.candidateName].append(voteCount)
elif vote.action == 'Yea':
transDict[vote.candidateName].append(voteCount + 1)
except:
print("problem getting actionId: %d" % actionId)
voteCount += 2
return transDict, itemMeaning















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









