







问题的背景:

![]()
超市的会员卡记录了大量的用户购买数据,通过分析这些数据可以帮助商店分析用户的购买行为。从大规模数据集中寻找物品间的隐含关系被称为关联规则分析(association analysis)或关联规则学习(association rule learning)。举个例子说就是发现用户购买了一件商品(如帽子)后,会购买另一件商品(如围巾)的概率。关联规则分析需要从大规模的商品数据中,发现和统计各种商品的组合(频繁项集发现)是一个非常费时费力的事情,这个也是关联规则分析的主要问题。为了解决这个问题提出了apriori算法,也叫先验算法。
1993年,R.Agrawal等人首次提出了挖掘顾客交易数据中项目集间的关联规则问题,其核心是基于两阶段频繁集思想的递推算法。该关联规则在分类上属于单维、单层及布尔关联规则,典型的算法是Aprior算法。
Aprior算法将发现关联规则的过程分为两个步骤:第一步通过迭代,检索出事务数据库中的所有频繁项集,即支持度不低于用户设定的阈值的项集;第二步利用频繁项集构造出满足用户最小信任度的规则。其中,挖掘或识别出所有频繁项集是该算法的核心,占整个计算量的大部分。
问题定义:
关联规则分析是为了在大规模数据集中寻找有趣关系的任务。这些关系分为两种,频繁项集和关联规则。
频繁项集(frequent item sets)是经常出现在一块的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。
apriori算法就是为了发现频繁项集。频繁项集发现后再进行关联规则分析,需要用到条件概型。
需要思考的问题:
1、频繁项集,频繁如何定义,也就是说怎样才算频繁?
2、应该如何去定义商品间的购买关系,也就是凭什么说他们存在某个关系?
3、如何去过滤掉一些不需要的商品关系,筛选出想要的商品关系?
第一个问题会在讲apriori算法原理的时候解决。
第二个问题需要用到条件概型
,其中P(AB)是A商品和B商品同时出现的概率,P(B)是B商品出现的概率,P(A|B)是在B商品出现的情况下出现A商品的概率。在关联规则分析中,我们将P(AB)称为A和B同时出现的的
支持度,P(B)称为B出现的支持度。P(A|B)指定是购买B再购买A的
可信度。
apriori原理:
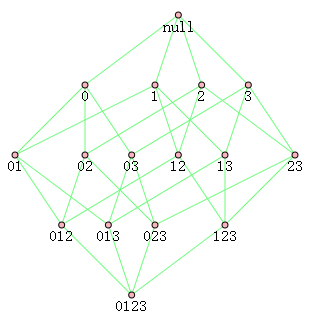
如下图对于{0,1,2,3}的组合如下共有15种,即2的N次方减1种,其中N为商品种数。因此计算所有组合的次数时间复杂度是很大的。
如何降低复杂度呢?
研究人员发现了一种所谓的Apriori原理,如果某个项集是频繁的,那么它的所有子集也是频繁的。逆否命题是,如果某个项集不是频繁的,那么包含这个项集的项集也不是频繁的。这个原理可作为减枝的依据,例如{0}不是频繁的,那么包含0的所有项集都不是频繁的,包含0的项集出现次数就不用统计了。
第一个问题的解决方法:
频繁项集的频繁是自定义的,根据实验场景定义一个次数,低于这个次数的项集就可以减枝减掉。
算法图例说明
为了便于计算,
下面的支持度用项集出现次数来代替。
假设有一个数据库D,其中有4个事务记录,分别表示为:
TID Items T1 I1,I3,I4 T2 I2,I3,I5 T3 I1,I2,I3,I5 T4 I2,I5
这里预定最小支持度minSupport=2,下面用图例说明算法运行的过程:
TID Items T1 I1,I3,I4 T2 I2,I3,I5 T3 I1,I2,I3,I5 T4 I2,I5
扫描D,对每个候选项进行支持度计数得到表C1:
项集 支持度计数 {I1} 2 {I2} 3 {I3} 3 {I4} 1 {I5} 3
比较候选项支持度计数与最小支持度minSupport,产生1维最大项目集L1:
项集 支持度计数 {I1} 2 {I2} 3 {I3} 3 {I5} 3
由L1产生候选项集C2:
项集 {I1,I2} {I1,I3} {I1,I5} {I2,I3} {I2,I5} {I3,I5}
扫描D,对每个候选项集进行支持度计数:
项集 支持度计数 {I1,I2} 1 {I1,I3} 2 {I1,I5} 1 {I2,I3} 2 {I2,I5} 3 {I3,I5} 2
比较候选项支持度计数与最小支持度minSupport,产生2维最大项目集L2:
项集 支持度计数 {I1,I3} 2 {I2,I3} 2 {I2,I5} 3 {I3,I5} 2
由L2产生候选项集C3:
项集 {I2,I3,I5}
扫描D,对每个候选项集进行支持度计数:
项集 支持度计数 {I2,I3,I5} 2
比较候选项支持度计数与最小支持度minSupport,产生3维最大项目集L3:
项集 支持度计数 {I2,I3,I5} 2
算法终止。
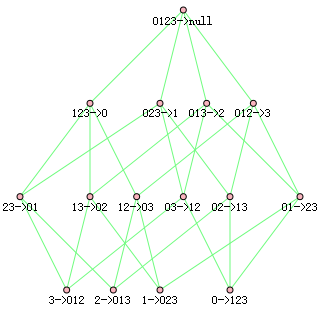
从频繁项中挖掘关联规则:
关联规则挖掘也可以进行减枝,例如012->3,可信度可用如下公式计算为,
对于以012->3为根节点的所有节点,例如03->12,可信度可用如下公式计算为
观察发现分子是一样的,分母由于子节点是父节点的子集,所以对应的概率更大,上面的例子P(12) >= P(012)。
所以可以得出如果某条规则不满足最小可信度,那么该规则的所有子集也不会满足最小可信度要求。
在ipython和python3.4环境下进行的实验,代码如下:
例子数据
def loadDataSet(): return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]] def loadDataSet2(): return [[1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6], [1, 2, 3, 4, 5, 6]]
""" 创建集合大小为1的项集 """ def createC1(dataSet): C1 = [] for transaction in dataSet: for item in transaction: if not [item] in C1: C1.append([item]) C1.sort() return map(frozenset, C1)#use frozen set so we #can use it as a key in a dict """ 计算指定项集的支持度 D是数据集合,Ck是要求支持度的项集,minSupport是最小支持度 """ def scanD(D, Ck, minSupport): ssCnt = {} for tid in D: for can in Ck: if can.issubset(tid): if not ssCnt.get(can): ssCnt[can]=1 else: ssCnt[can] += 1 numItems = float(len(D)) retList = [] supportData = {} for key in ssCnt: support = ssCnt[key]/numItems if support >= minSupport: retList.insert(0,key) supportData[key] = support return retList, supportData """ 生成集合大小比原来的大一的项集 """ def aprioriGen(Lk, k): #creates Ck retList = [] lenLk = len(Lk) # 如果Lk只有一项,则retList为[] for i in range(lenLk): for j in range(i+1, lenLk): # 为了每次添加的都是单个项构成的集合,所以Lk中项的大小是k-1,那么前k-2项相同,才能使合并后只比原来多一项。 L1 = list(Lk[i])[:k-2]; L2 = list(Lk[j])[:k-2] L1.sort(); L2.sort() if L1==L2: #if first k-2 elements are equal retList.append(Lk[i] | Lk[j]) #set union return retList """ 求出数据集合中,支持度大于最小支持度的所有项集 """ def apriori(dataSet, minSupport = 0.5): C1 = createC1(dataSet) # 转化为list类型重要 C1 = list(C1) D = map(set, dataSet) # 转化为list类型重要 D = list(D) # print(D) # print(C1) L1, supportData = scanD(D, C1, minSupport) # print(L1) L = [L1] k = 2 while (len(L[k-2]) > 0): Ck = aprioriGen(L[k-2], k) Lk, supK = scanD(D, Ck, minSupport)#scan DB to get Lk supportData.update(supK) L.append(Lk) k += 1 return L, supportData """ 计算 freqSet-conseq -> conseq 的可信度, conseq是H中的元素 """ def calcConf(freqSet, H, supportData, brl, minConf=0.7): prunedH = [] #create new list to return for conseq in H: conf = supportData[freqSet]/supportData[freqSet-conseq] #calc confidence if conf >= minConf: print(freqSet-conseq,'-->',conseq,'conf:',conf) brl.append((freqSet-conseq, conseq, conf)) prunedH.append(conseq) return prunedH """ # 1个元素的集合 -> (len(freqSet) - 1) 元素的集合 # 2个元素的集合 -> (len(freqSet) - 2) 元素的集合 # ... """ def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7): print("H:", H) m = len(H[0]) if (len(freqSet) > (m + 1)): #try further merging Hmp1 = aprioriGen(H, m+1)#create Hm+1 new candidates # print("Hmp1:",Hmp1) Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf) # print("Hmp1:",Hmp1) if (len(Hmp1) > 1): #need at least two sets to merge rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf) """ 两个元素的集合求关联规则 三个元素的集合求关联规则 ... """ def generateRules(L, supportData, minConf=0.7): #supportData is a dict coming from scanD bigRuleList = [] for i in range(1, len(L)):#only get the sets with two or more items print(L[i]) for freqSet in L[i]: H1 = [frozenset([item]) for item in freqSet] print(H1) if (i > 1): rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) else: calcConf(freqSet, H1, supportData, bigRuleList, minConf) return bigRuleList
进行apriori算法项集为1的测试,如果可行再应用到递推中
# 加载数据 dataSet=loadDataSet() dataSet
# 获取集合大小为1的所有项集 C1=createC1(dataSet) # print(len(C1)) # TypeError: object of type 'map' has no len() C1 = list(C1) C1
# 将数据类型转换为集合 D=map(set, dataSet) # print(len(D)) D = list(D) D
# 求集合大小为1的项集的支持度,返回留下支持度大于最小支持度的项集和它们的支持度 L1, suppData0 = scanD(D, C1, 0.5) print(L1) print(suppData0)
测试priori算法L1, suppData0 = apriori(dataSet) print(L1) print() print(suppData0)
L1, suppData0 = apriori(dataSet, minSupport=0.7) print(L1) print() print(suppData0)
测试关联规则
L, suppData = apriori(dataSet, minSupport=0.5) print(L) print() print(suppData)
rules = generateRules(L, suppData, minConf=0.7)
rules = generateRules(L, suppData, minConf=0.5) rules
缺点:每次增加频繁项集的大小,Apriori算法都会重新扫描整个数据集合。![]()

当数据集很大时,这会显著降低频繁项集的发现速度。
参考自:《机器学习实战》
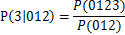
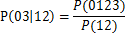















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









