package com.sangguigu.wc;
/*
*有界流处理文件形式
*
*/
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
//最后输出的时候有异常,在主方法中抛出
public static void main(String[] args) throws Exception{
//1.创建流式执行环境
StreamExecutionEnvironment evn = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文件
DataStreamSource<String> lineDaraStreamSource= evn.readTextFile("input/word.txt");
//3.转换
SingleOutputStreamOperator<Tuple2<String,Long>> wordAndOneTuple = lineDaraStreamSource.flatMap( (String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word: words) {
out.collect(Tuple2.of(word,1L));
}
} )
.returns(Types.TUPLE(Types.STRING,Types.LONG));
// 4.按照word进行分组 0代表二元组的第一个参数进行分组
KeyedStream<Tuple2<String,Long>,String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5.分组内进行聚合统计 1代表二元组的第一个参数进行求和
SingleOutputStreamOperator<Tuple2<String,Long>> sum = wordAndOneKeyedStream.sum(1);
//6.打印结果
sum.print();
//7.启动执行,跟之前的批处理不一样,这里是需要启动才行
evn.execute();
}
}
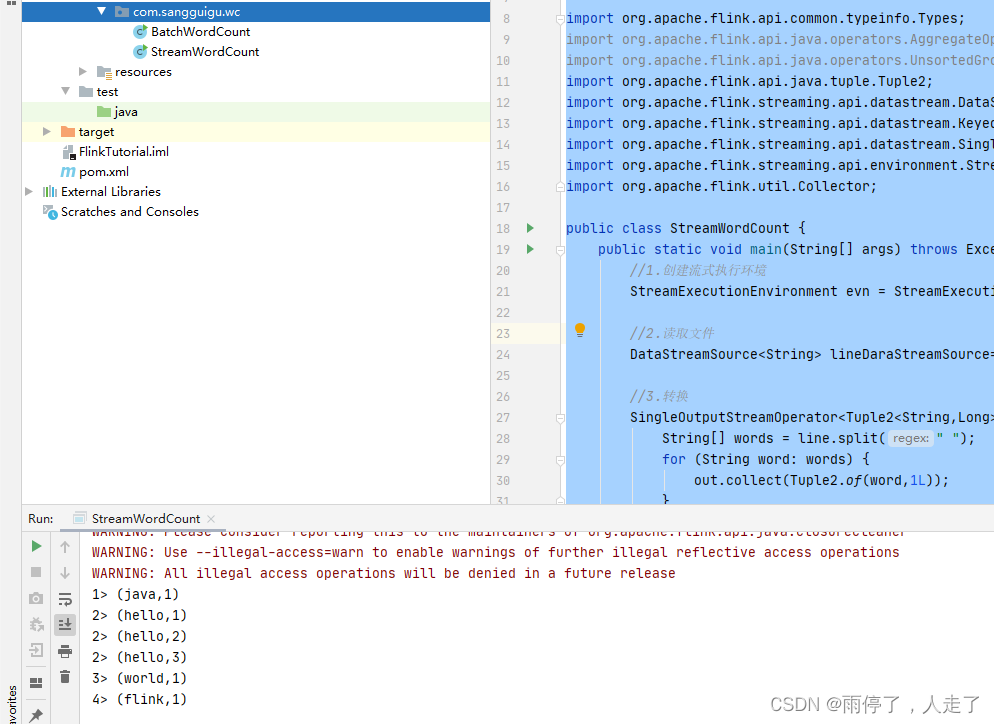
结果,可以看出数据是一条一条统计的:






















 1662
1662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









