






14天阅读挑战赛
努力是为了不平庸~
具体代码连接:http://t.csdn.cn/vXDTE
学习完树之后,又操作了Huffman,突然遇见它,分外亲切,于是想再加深一下理解!
Huffman树主要应用于文件压缩节省空间...
目的是当年为了解决远距离同学的数据传输最优化问题.
通过我片面操作的有了片面的结论:
在Huffman应用与字符压缩的时候,虽然原理是树,但是确实主要的就表,有好几种记录表来记录信息:孩子双亲以及权重的记录,单个字符对应编码串的记录等,最后通过各种表的记录来翻译huff编码.
思路:根据文件字符出现的频率,对其排序进行编码。频率越高的词,Huffman编码越短,可以最大化压缩节省空间
1.各种结构体:
1.单个node存储字符与出现次数
2.根据ASII码,字符共128种且有部分无法打印显示
创建List记录表
3.创建孩子双亲记录表:
4.字符编码记录表:通过char就可以确定它的编码串
2.初始化:
1.List记录表的初始化,length是为了记录有多少种不同的字符串(与后文cat:category相同);
2.创建字符编码记录表
3.字符计数:(靠字符串与整数的变换)
ASII数组,字符的编码小于128;
memset ASII数组全置为0;
ASII [i] 的值表示字符 i 的出现次数
ASII数组非0的数据都交给List记录表吧!
4.创建孩子双亲权重记录表:
二叉树有一种数组表示方法:创建孩子双亲权重记录表的过程其实就是创建了一颗树;
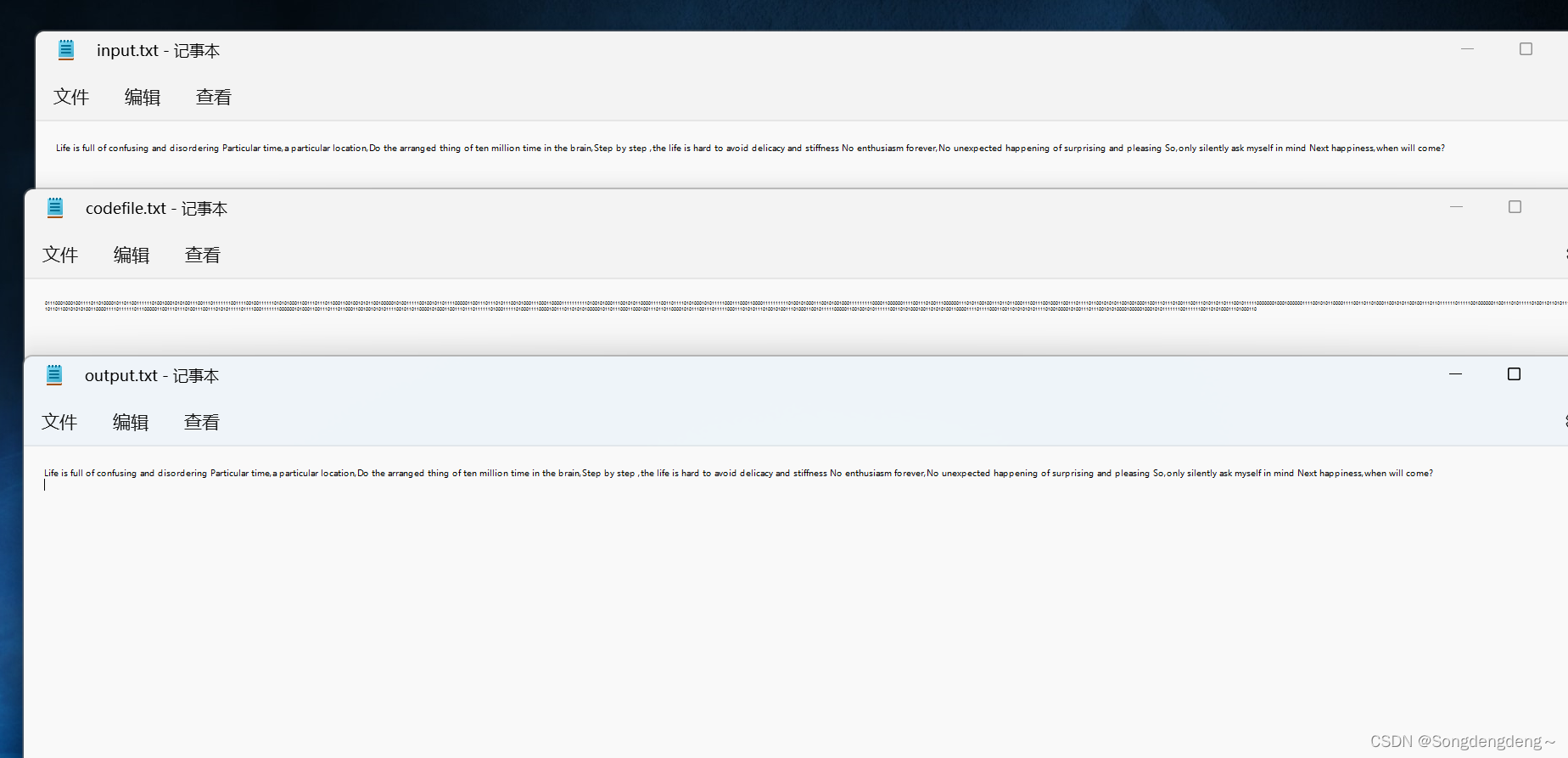
5.生成code文件:
1.只查找叶子结点,并得出单个字符的编码串;
因为是从叶子往上知道根节点(0节点就是根节点),所以编码串顺序为倒序,通过从后往前取来解决;
2.获得编码串;
当前叶子的父母为p,如果它是p的左孩子则存入 0,否则 1
然后p的父母为q,如果它是q的左孩子则存入 0,否则 1、、(开始套娃!!!)
直到p==0;
3.获得codefile.txt文本
由上得到的是出现字符的编码,有编码记录表记录,遍历源文件source,挨个字符转化为编码串并存入codefile.txt当中;
6.解码并存入output文件:
因为每个编码串不可能有重叠部分:每个结点都特意被放在了叶子结点上,如果要有前缀重叠部分就一定得是祖先与后辈的关系!
通过特定的编码串找回原来的叶子结点(无左右孩子就是其判断条件!)














 578
578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









