






目录
什么是朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的统计分类算法。该算法的基本假设是所有特征都是相互独立的,这也是“朴素”(Naive)一词的来源。朴素贝叶斯是一种简单而有效的分类方法,特别适用于文本分类问题。
在朴素贝叶斯分类中,贝叶斯定理用于计算给定类别的先验概率,并通过观察到的特征来计算后验概率。具体而言,对于一个给定的数据点,算法计算每个可能类别的后验概率,并将数据点分配给具有最高后验概率的类别。
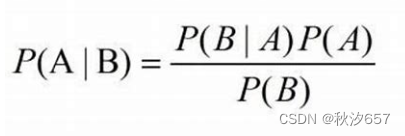
怎么实现朴素贝叶斯
朴素贝叶斯算法在文本分类、垃圾邮件过滤、情感分析等任务中经常被使用。本次实验进行朴素贝叶斯实现 垃圾邮件分类 。
下面是朴素贝叶斯分类器的实现和使用的主要步骤:
1. 初始化:
在初始化中,我们创建两个空字典,一个用于存储类别的概率 (class_probs),另一个用于存储每个类别中每个单词的概率 (word_probs)。
class NaiveBayesClassifier:
def __init__(self):
self.class_probs = {} # 存储各类别的概率
self.word_probs = {} # 存储每个类别中每个单词的概率
2. 训练 (fit) 方法:
在训练方法中,首先计算每个类别在训练集中出现的概率 (class_probs)。这是通过统计每个类别在标签 (y_train) 中出现的次数,并除以总文档数得到的。
def fit(self, X_train, y_train):
# 计算类别的概率
total_docs = len(y_train) # 训练集文档总数
unique_classes = set(y_train) # 类别的唯一集合
for cls in unique_classes:
cls_count = y_train.count(cls) # 类别出现的次数
self.class_probs[cls] = cls_count / total_docs # 类别的概率
# 计算每个类别中每个单词的概率
vectorizer = CountVectorizer()
X_train_vectorized = vectorizer.fit_transform(X_train)
for cls in unique_classes:
cls_indices = [i for i, label in enumerate(y_train) if label == cls]
cls_word_count = X_train_vectorized[cls_indices, :].sum(axis=0)
cls_word_count = cls_word_count.A1
total_words_in_class = cls_word_count.sum()
self.word_probs[cls] = {}
for word, index in vectorizer.vocabulary_.items():
# 计算拉普拉斯平滑后的单词概率
self.word_probs[cls][word] = (cls_word_count[index] + 1) / (total_words_in_class + len(vectorizer.vocabulary_))
3. 预测 (predict) 方法:
在预测方法中,对于每个测试文档,计算属于每个类别的概率,并选择具有最高概率的类别作为预测结果。
def predict(self, X_test):
predictions = []
for document in X_test:
document_probs = {cls: self.class_probs[cls] for cls in self.class_probs.keys()}
for word in document.split():
for cls in self.class_probs.keys():
if word in self.word_probs[cls]:
# 更新文档概率,考虑每个单词的概率
document_probs[cls] *= self.word_probs[cls][word]
predicted_class = max(document_probs, key=document_probs.get) # 取概率最大的类别
predictions.append(predicted_class)
return predictions
4. 加载数据 (load_data) 函数:
这个函数用于加载数据,本次实验文件夹结构是 email/ham 或 email/spam。它遍历文件夹中的文件,读取文件内容并将内容添加到emails 列表中,同时将类别标签添加到 labels 列表中。
def load_data(folder):
emails = []
labels = []
for filename in os.listdir(folder):
path = os.path.join(folder, filename)
with open(path, 'r', encoding='utf-8', errors='ignore') as file:
content = file.read()
emails.append(content)
labels.append(folder.split('/')[-1]) # 假设文件夹结构是 email/ham 或 email/spam
return emails, labels
5.使用贝叶斯实现垃圾邮件分类:
这部分代码加载数据,将垃圾邮件和非垃圾邮件合并,然后将数据分为训练集和测试集。接着,实例化并训练 NaiveBayesClassifier,进行预测,并最后评估分类器的性能。
# 加载数据
ham_emails, ham_labels = load_data('email/ham')
spam_emails, spam_labels = load_data('email/spam')
# 合并垃圾邮件和非垃圾邮件
all_emails = ham_emails + spam_emails
all_labels = ham_labels + spam_labels
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(all_emails, all_labels, test_size=0.2, random_state=42)
# 训练朴素贝叶斯分类器
classifier = NaiveBayesClassifier()
classifier.fit(X_train, y_train)
# 在测试集上进行预测
predictions = classifier.predict(X_test)
# 评估性能
accuracy = accuracy_score(y_test, predictions)
# 打印结果
print(f'准确率: {accuracy:.2f}')
print('预测结果:')
print(predictions)运行结果:
准确率: 0.90
预测结果:
['ham', 'spam', 'ham', 'spam', 'ham', 'spam', 'spam', 'spam', 'spam', 'ham']

总结:
朴素贝叶斯的优点是它对小规模数据集也能表现良好,而且相对简单,易于实现。朴素贝叶斯是一种简单而有效的分类方法,适用于文本分类等任务。















 9273
9273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









