






 本文介绍了朴素贝叶斯分类算法在文本处理中的应用,包括计算先验概率、条件概率,以及如何用Python和jieba库构建单词库和进行垃圾邮件分类。作者还提到朴素贝叶斯算法在垃圾邮件过滤中的优点,如高效性、适应性和模型简洁性,并提及了与SVM的对比。
本文介绍了朴素贝叶斯分类算法在文本处理中的应用,包括计算先验概率、条件概率,以及如何用Python和jieba库构建单词库和进行垃圾邮件分类。作者还提到朴素贝叶斯算法在垃圾邮件过滤中的优点,如高效性、适应性和模型简洁性,并提及了与SVM的对比。
1.朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的分类算法,它被广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。该算法建立在特征之间条件独立的假设上,因此称为"朴素"贝叶斯。
在朴素贝叶斯分类中,我们首先从训练数据中学习类别与特征之间的联合概率分布。然后,当给定一个新的样本时,算法会计算该样本属于每个类别的概率,并将其分类为具有最高概率的那个类别。
朴素贝叶斯算法的关键步骤包括:
- 计算先验概率:根据训练数据计算每个类别的先验概率,即在没有任何其他信息的情况下,样本属于某一类的概率。
- 计算条件概率:对于每个特征,计算在已知类别的情况下,该特征发生的条件概率。
- 应用贝叶斯定理:利用贝叶斯定理计算后验概率,即在观察到特定特征情况下,属于某一类别的概率。
- 类别判定:根据后验概率进行分类决策。
2.什么是贝叶斯
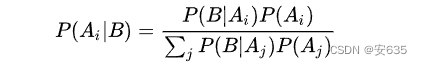
贝叶斯定理是概率论中的一条重要定理,用于计算在已知某一事件发生的情况下,另一事件发生的条件概率。按我的理解为是 条件概率、
3.样本数据构建
基于我已经分辨好的垃圾邮件和良好邮件,构成两种不同的数据集。
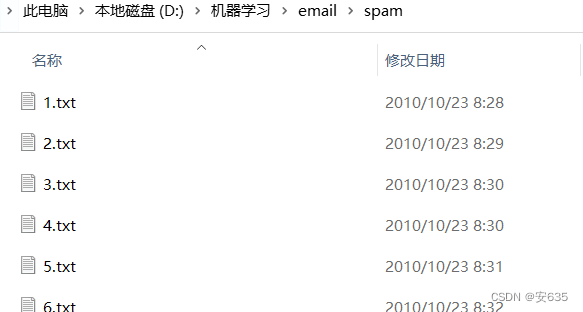

分成spam和ham两种,还有test的文件
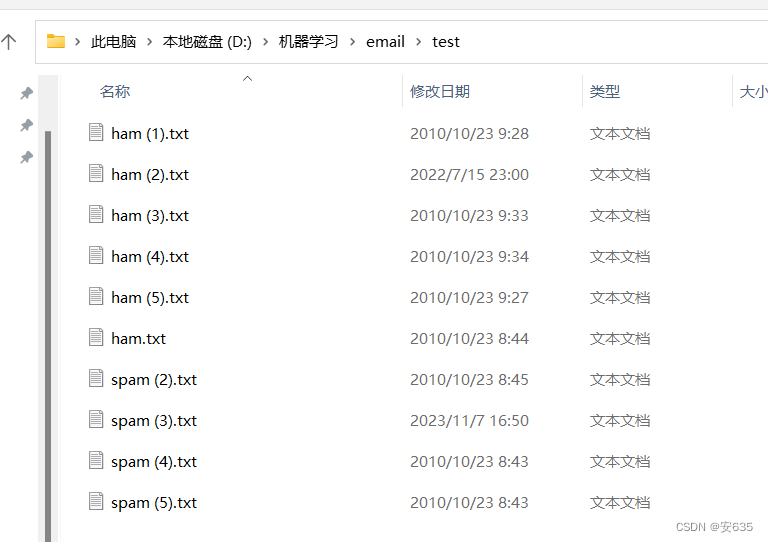
我将他们统一命名为以ham或者spam开头的文件
4.用python代码构建单词库
利用了jieba库,提高了我构建单词库的效率,对于spam的构建也是类似的。大致原理就是便利ham文件夹下的所有txt文件,然后去检索每个以空格分隔的字符串,寻找单词库中是否存在同一个,没有则添加,有则略过。
def ham_words():
folder_path = './email/ham'
# 获取文件夹下的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 初始化单词库
word_all_ham = set()
# 遍历所有 txt 文件
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
# 读取文件内容,去掉标点符号
content = f.read().replace('-',' ').replace(':',' ').replace(',', '').replace('.', '').replace('?', '').replace('!', '').replace('&',' ').replace('=',' ').replace('(',' ').replace(')',' ').replace('\\',' ')
# 对内容进行分词
words = jieba.cut(content)
# 将分词结果添加到单词库
word_all_ham.update(words)
# 将单词库保存为 txt 文件
with open('./email/word_all_ham.txt', 'w') as f:
for word in word_all_ham:
f.write(word + '\n')
print('ham 单词库创建完成!')5.利用python代码构建目标邮件的单词库,并且检索ham和spam单词库的词出现的频率
这里的txt_path是指spam或者pam的单词库路径,去检索word 在他们这两个单词库的出现频率
def find_word(file_words,txt_path):
word_dict = {}
# 读取词库文件,构建词库
with open(file_words, 'r') as f:
for line in f:
word = line.strip()
if word:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
# 读取文本文件
with open(txt_path, 'r') as f:
content = f.read()
# 将内容转换为小写并去除标点符号
content = re.sub(r'[^\w\s]', '', content.lower())
# 使用 jieba 进行分词
words = jieba.cut(content)
# 统计单词频率
for word in words:
if word in word_dict:
word_dict[word] += 1
# 输出结果
count_all = 0
for word, count in word_dict.items():
#print(f'{word}: {count}')
count_all+=count-1
return count_all6.完整代码
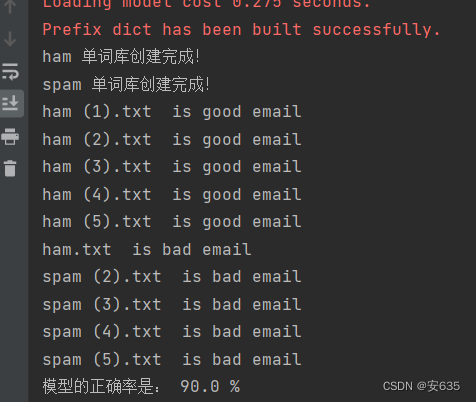
下面的main函数主要是对上面那些代码的调用,和统计模型的正确率。核心思想还是贝叶斯公式。
import os
import re
import jieba
def ham_words():
folder_path = './email/ham'
# 获取文件夹下的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 初始化单词库
word_all_ham = set()
# 遍历所有 txt 文件
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
# 读取文件内容,去掉标点符号
content = f.read().replace('-',' ').replace(':',' ').replace(',', '').replace('.', '').replace('?', '').replace('!', '').replace('&',' ').replace('=',' ').replace('(',' ').replace(')',' ').replace('\\',' ')
# 对内容进行分词
words = jieba.cut(content)
# 将分词结果添加到单词库
word_all_ham.update(words)
# 将单词库保存为 txt 文件
with open('./email/word_all_ham.txt', 'w') as f:
for word in word_all_ham:
f.write(word + '\n')
print('ham 单词库创建完成!')
def spam_words():
folder_path = './email/spam'
# 获取文件夹下的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 初始化单词库
word_all_spam = set()
# 遍历所有 txt 文件
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
# 读取文件内容,去掉标点符号
content = f.read().replace('-',' ').replace(':',' ').replace(',', '').replace('.', '').replace('?', '').replace('!', '').replace('&',' ').replace('=',' ').replace('(',' ').replace(')',' ').replace('\\',' ')
# 对内容进行分词
words = jieba.cut(content)
# 将分词结果添加到单词库
word_all_spam.update(words)
# 将单词库保存为 txt 文件
with open('./email/word_all_spam.txt', 'w') as f:
for word in word_all_spam:
f.write(word + '\n')
print('spam 单词库创建完成!')
def find_word(file_words,txt_path):
word_dict = {}
# 读取词库文件,构建词库
with open(file_words, 'r') as f:
for line in f:
word = line.strip()
if word:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 0
# 读取文本文件
with open(txt_path, 'r') as f:
content = f.read()
# 将内容转换为小写并去除标点符号
content = re.sub(r'[^\w\s]', '', content.lower())
# 使用 jieba 进行分词
words = jieba.cut(content)
# 统计单词频率
for word in words:
if word in word_dict:
word_dict[word] += 1
# 输出结果
count_all = 0
for word, count in word_dict.items():
#print(f'{word}: {count}')
count_all+=count
return count_all
def counts_of_txt(text):
# 统计单词数
with open(text, 'r') as file:
content = file.read()
#过滤符号
words = re.findall(r'\b\w+\b', content)
word_count = len(words)
#print("单词数:", word_count)
return word_count
if __name__ == '__main__':
ham_words_path = './email/word_all_ham.txt'
spam_words_path = './email/word_all_spam.txt'
test_path = './email/test/'
ham_words()
spam_words()
#txt_path = './email/test/21.txt'
test_files = [f for f in os.listdir(test_path) if f.endswith('.txt')]
test_num = len(test_files)
P_right = 0
for txt_path in test_files:
temp_path = test_path + txt_path
true_mark = 0 # 对于邮件来说真正是不是有效的标识符
temp_mark = 0 # 对于模型来说判断是不是有效的标识符
#print(temp_path)
spam_word = find_word(spam_words_path, temp_path)
ham_word = find_word(ham_words_path, temp_path)
word_nums = counts_of_txt(temp_path)
# print('spam = ', spam_word)
# print('ham = ', ham_word)
if word_nums!=0:
P_of_ham = ham_word / (word_nums * 1.0) * 1 / 2
P_of_spam = spam_word / (word_nums * 1.0) * 1 / 2 # 这个1/2是由样本数量决定
if P_of_ham > P_of_spam:
print(txt_path," is good email")
temp_mark = 1
else:
print(txt_path," is bad email")
temp_mark = 2
else:
temp_mark = 2
print(txt_path, " is bad email")
if 'ham' in txt_path:
true_mark = 1
if 'spam' in txt_path:
true_mark = 2
if true_mark == temp_mark:
P_right += 1
print('模型的正确率是:',(P_right)/test_num * 100 ,'%')
7.总结
朴素贝叶斯公式在垃圾邮件的分类上,实现是比较简单易懂的,也存在着一些优势
- 高效性能:朴素贝叶斯算法通常在处理文本数据时具有高效的训练和预测速度,这对于大规模垃圾邮件分类任务非常重要。
- 适应文本特征:朴素贝叶斯算法在处理文本特征时表现良好,能够有效地捕捉单词出现的概率信息,适用于垃圾邮件中常见的文本特征。
- 相对简单的模型:朴素贝叶斯算法的模型相对简单,易于实现和调整,同时在一定程度上能够处理高维度的文本特征。
在做垃圾邮件分类的算法SVM支持向量机也是一个比较常用的办法,有机会也会去尝试写一下,然后分享出来

















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









