







- 项目中的数据仅供学习参考,切勿商业用途
项目背景
- 数字化转型—随着互联网技术的发展,越来越多的旅游信息和用户反馈通过数字化平台进行分享和交流,这为数据分析提供了丰富的资源。
- 用户生成内容的增长—社交媒体和旅游分享平台的兴起使得用户生成内容(UGC)成为旅游信息的重要来源,这些内容包含了用户的旅行体验、评价和建议。
- 市场竞争加剧—旅游市场竞争激烈,旅游服务提供商需要通过深入分析用户数据来获取竞争优势。
项目意义
- 市场趋势预测—通过分析游记排行,可以预测哪些目的地、旅游活动或服务可能会受到欢迎,从而帮助旅游企业提前做好准备。
- 用户偏好分析—了解用户对不同旅游目的地、活动和服务的偏好,可以帮助旅游企业提供更符合市场需求的产品。
- 内容营销—游记中的正面评价和精彩故事可以作为内容营销的素材,吸引更多用户关注和参与。
爬虫部分
网页结构解析
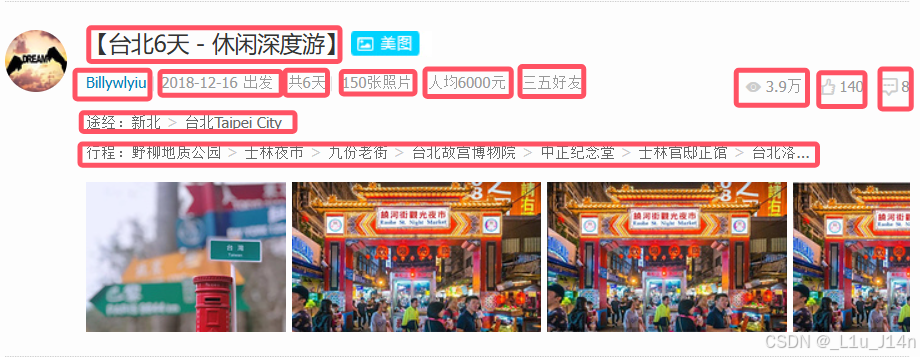
需要爬取的数据在图中框出,分别为标题、用户名、出发日期、出行天数、照片数、人均价格、出行团体、浏览数、点赞数、评论数、途径地、行程路线。
爬虫代码解读
main()函数
if __name__ == '__main__':
# 初始化线程列表
thread_list = []
for i in range(1, 11):
# 计算每一页的起始和结束页码
start_page = (i - 1) * 20 + 1
end_page = i*20
# 创建线程以获取页面
t = threading.Thread(target=get_page, args=(start_page, end_page))
thread_list.append(t)
t.start()
# break
# 每启动一个线程后暂停
time.sleep(10)
print(f'{
t.name}启动成功')
# 等待所有线程完成
for t in thread_list:
t.join()
get_page()函数
def get_page(start_page, end_page): # 定义一个获取页面信息的函数,接收起始页和结束页作为参数
chrome_path = '../driver/chromedriver.exe'
service = Service(chrome_path)
driver = webdriver.Chrome(service=service)
driver.maximize_window()
# all_data=[]
for i in range(start_page, end_page+1): # 遍历页面,从起始页到结束页
url = f'https://travel.qunar.com/travelbook/list/24-zhongguo-300667/hot_heat/{
i}.htm'
print(f'正在爬取第{
i}页')</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









