







相关课程与技术:《数据采集与网络爬虫技术》、requests、BeautifulSoup、pymongo等等。
这是我一年前的项目了,今天决定总结出来分享给大家!一起学习啊。
目录
一、项目的目的与意义
此次项目主要针对去哪儿旅游网站广州景点门票的数据分析,利用的景点相关信息与用户对景点的评论评分数据进行对比与分析,寻找出适合个人用户游玩的景点。
二、采集目标确定
因此通过对去哪儿旅游网站主页的分析,需要采集两部分的信息:
第一、景点的详细信息:包括景点名称、景点热度、地址、门票价格、门票销量数、景点区域、景点主题;
第二、景点的评论评分:包括评论内容、评论用户ID、评论时间、体验所给的星星级别。
通过分析上述数据可以观察出景点的评价、景点的游玩体验感受情况、景点的热度、用户喜欢度等情况,从而可以根据景点与用户所喜欢的价格、类型等推荐出最好的景点,让用户更方便快捷的去选择与游玩。
三、去哪儿旅游网站分析
本项目主要通过广州景点门票的景点信息及评论数据作为数据采集研究对象。在采集前根据网页的后缀以及网址的特点来进行网页的区分。
首先静态网页主要是以.html、.htm、.html、.shtml、.xml作为后缀的网页。静态网页的内容是固定的,每个页面都是独立的页面不会根据浏览者的不同需求而改变。而动态网页是使用ASP 或PHP 或 JSP 等作为后缀的网页,并且能够自动更新,因事因人而变,交互性较强。动态网页网址中的符号“?”对搜索引擎检索存在一定的问题,需要一定的技术处理才能适应其要求。所以较为容易的判断出去哪儿旅游网站的网页是动态的。如图3-1 网页网址所示。
图3-1 网页网址
景点的详细信息是先放在列表中,然后再存到Excel表格中。而本次项目景点的详细信息我使用requests与BeautifulSoup方法提取景点下的数据。而评论数据则是直接存储到json中,利用pymongo与selenium方法,可以直接通过get方式进行内容提取。如下图3-2方法确定。
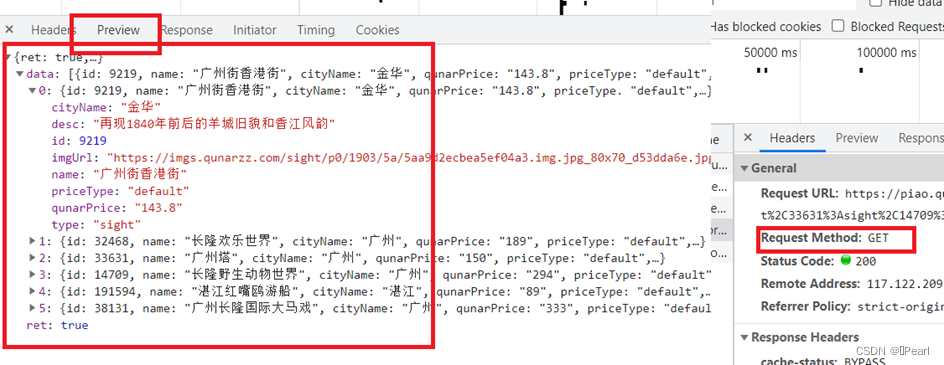
图3-2 方法确定
Json格式的层次结构简洁清晰,通常以键值对的形式存储,有利于开发者阅读和编写,同时也易于机器解析和生成,能够有效地提升网络传输效率。在爬虫的过程中,可以在开发者模式返回的网页里找到完整的json格式的数据,这时就可以运用requests包中的json函数将爬取到的原文本转化格式,从而方便提取内容。如景点评论页面中的用户评论数据就是json格式,如下图3-3 评论页面所示。
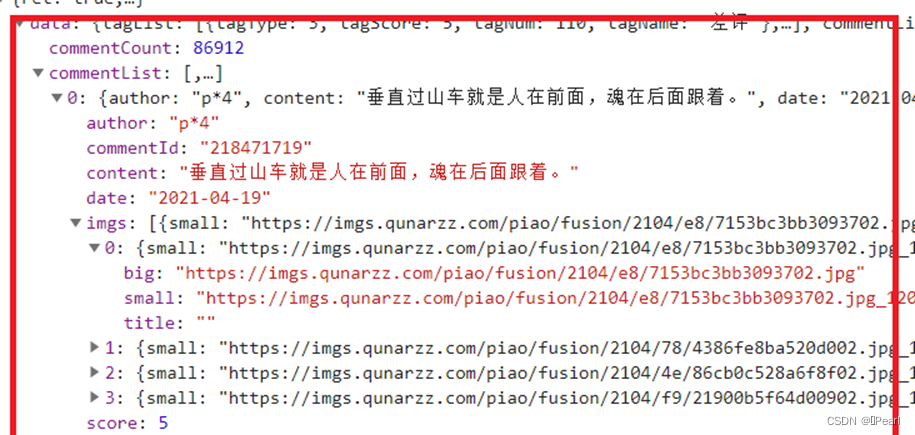
图3-3 评论数据
四、数据采集流程与步骤说明
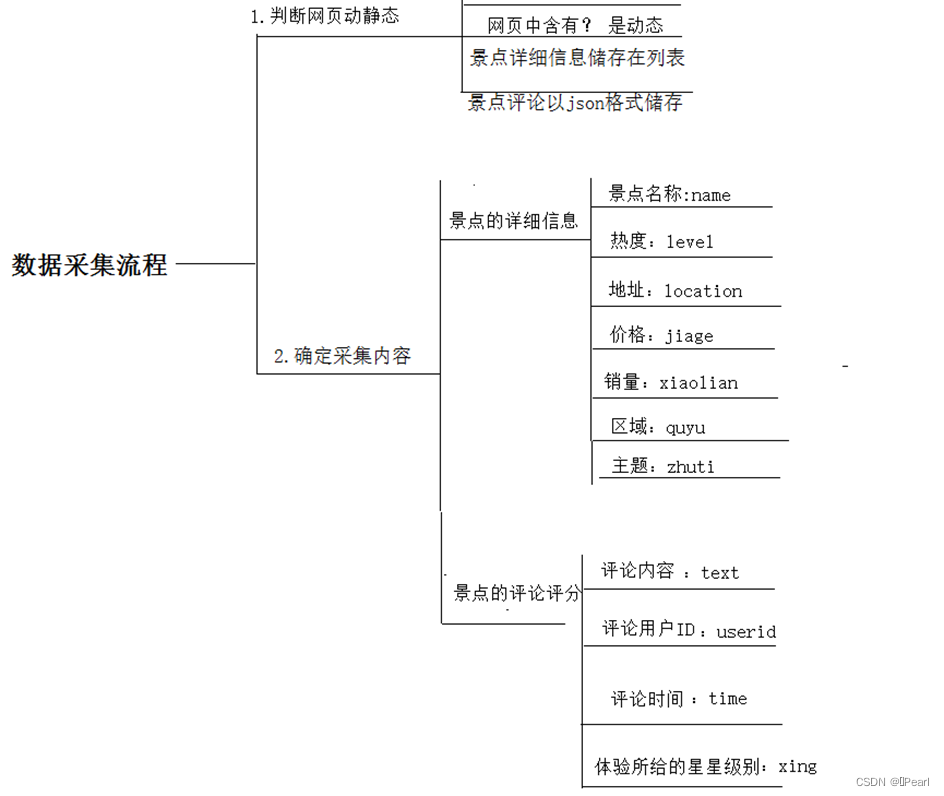
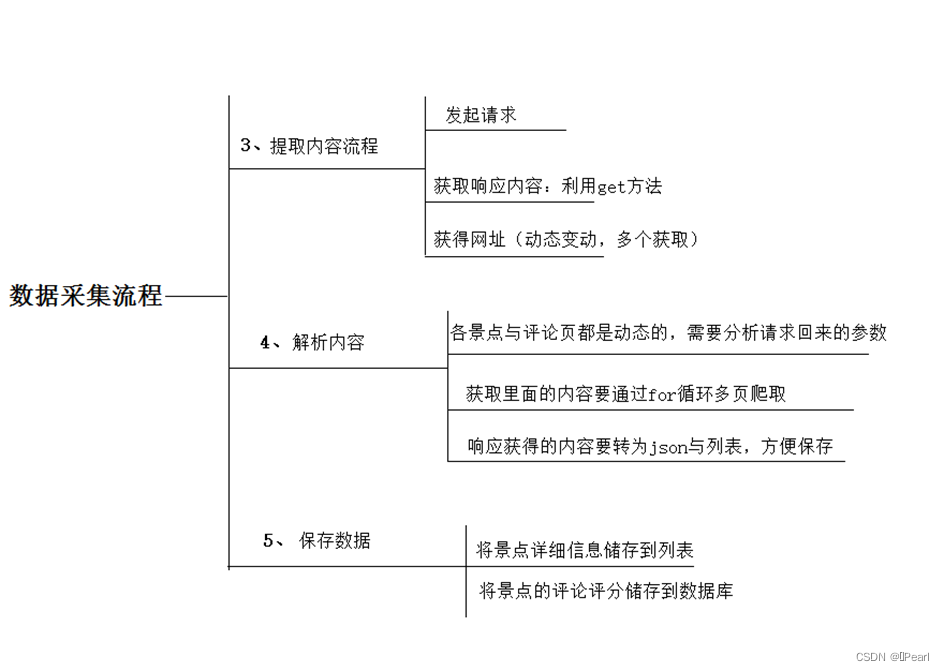
图4 数据采集步骤
图片步骤说明:总体来说此次项目的实现步骤就是分析数据,获取信息,即模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或Excel表格中。
核心信息采集主要分为4个步骤:发起请求、获取响应体、解析内容与保存数据。
发起请求:使用http库向目标站点发起请求,即发送一个Request,Request包含:请求头、请求体等,然后利用get方法获取。获取响应内容如果服务器能正常响应,则会得到一个Response: Response包含:html,json,图片,视频等。解析内容的话,就是解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等,我利用了Beautifulsoup进行解析。解析json数据:json模块。保存数据:我运用了Excel表格和数据库来保存。
五、数据采集实现过程
(1)进入搜索广州门票首页
核心代码展示:
browser=webdriver.Chrome()
url='https://piao.qunar.com/'
browser.get(url)
time.sleep(10)
input=browser.find_element_by_css_selector('#searchValue')
input.send_keys('广州')
button=browser.find_element_by_xpath('//*[@id="searchBtn"]')
button.click()
url='https://piao.qunar.com/ticket/list.htm?keyword=%E5%B9%BF%E5%B7%9E&https://piao.qunar.com/ticket/list.htm?keyword=%E5%B9%BF%E5%B7%9E®ion=&from=mps_search_suggestregion=&from=mps_search_suggest'
res=requests.get(url)
res.text
图5-1 进入广州首页爬取结果
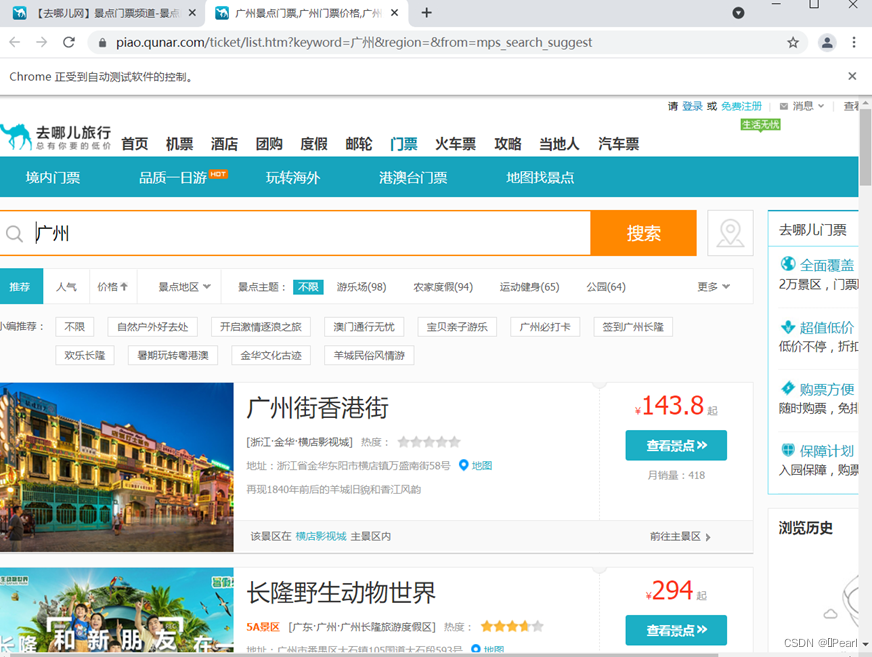
图5-2 进入广州首页页面展示
(2)景点详细页面信息获取
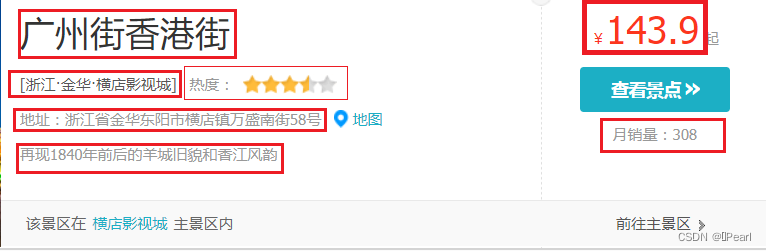
图5-3 景点详细信息网页内容
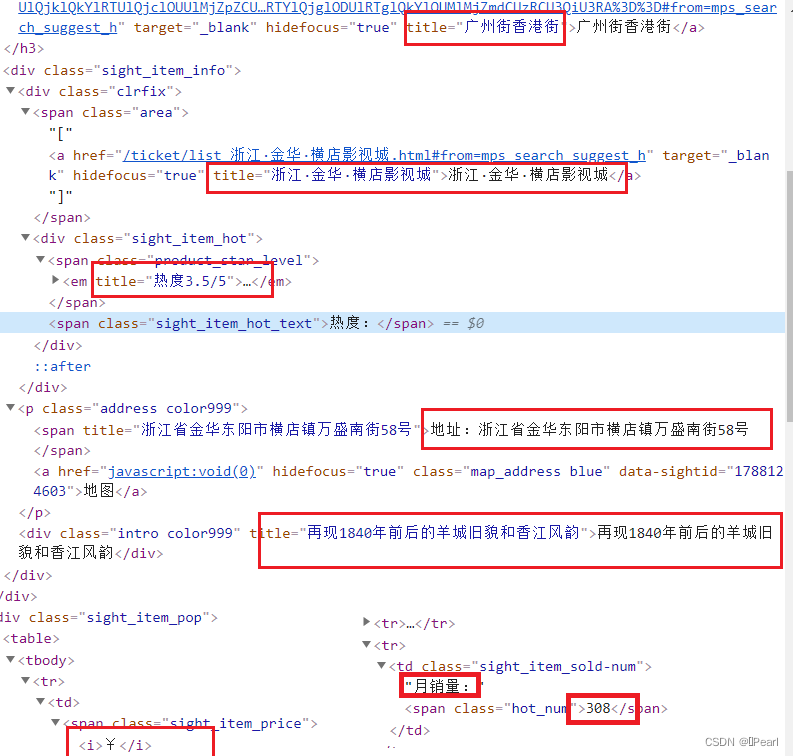
图5-4 景点详细信息页面获取内容
核心代码展示:
for place in soup.select('.sight_item_detail'):
name=place.select('.name')[0].text
level=place.select('.product_star_level')[0].text
location=place.select('.address span')[0].text.strip()
jiage=place.select('.sight_item_pop em')[0].text.strip()
xiaolian=place.select('.hot_num')[0].text.strip()
quyu=place.select('.area a')[0].text.strip()
zhuti=place.select('.intro')[0].text.strip()
movies.append({
'景点名':name,
'热度':level,
'':location,
'价格':jiage,
'销量':xiaolian,
'区域':quyu,
'主题':zhuti
})
图5-5 景点详细页面爬取结果
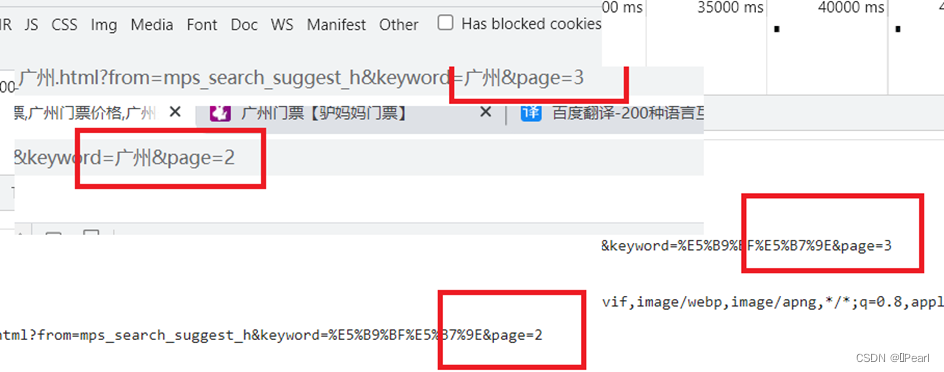 图5-6 网页路径规律
图5-6 网页路径规律
解析:找寻网页网址url的规律,通过翻页,可以发现在网址的最后page=2,变成page=3。因此可以得出:
url='https://piao.qunar.com/ticket/list.htm?keyword=%E5%B9%BF%E5%B7%9E®ion=&from=mps_search_suggest&page='+str(a)通过该url进行for循环翻页爬取。
df=pd.DataFrame(movies) #将列表转换成DataFrame数据框 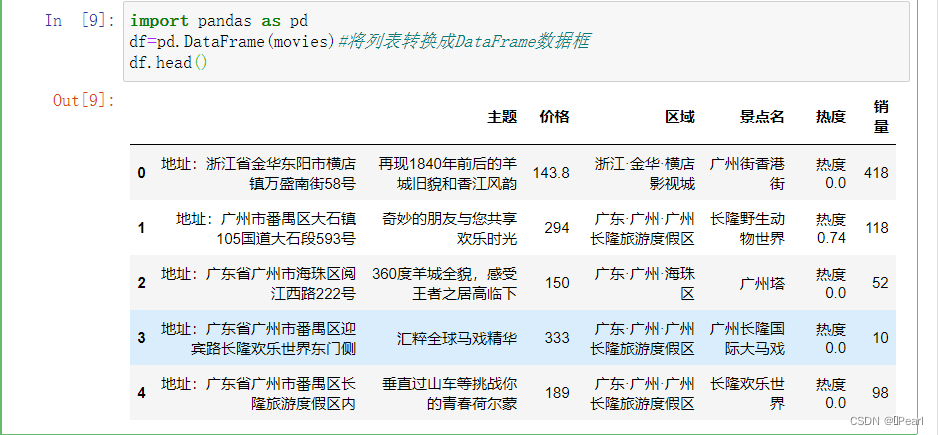 图5-7 列表转换
图5-7 列表转换
df=pd.DataFrame(movies)#将列表转换成DataFrame数据框
df.head()
df.to_excel('top200.xlsx')#保存为top200.xlsx 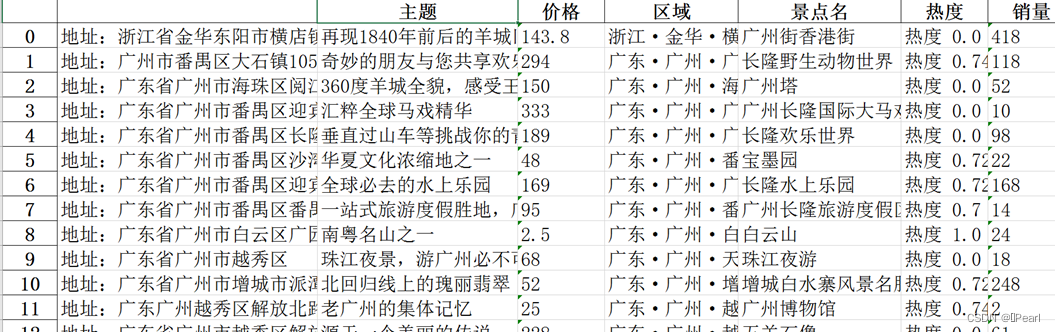
图5-8 Excel表格结果
(3)景点评论评分页面信息获取
由于评论数据是直接存储在json格式中,可以通过get方式直接获取。
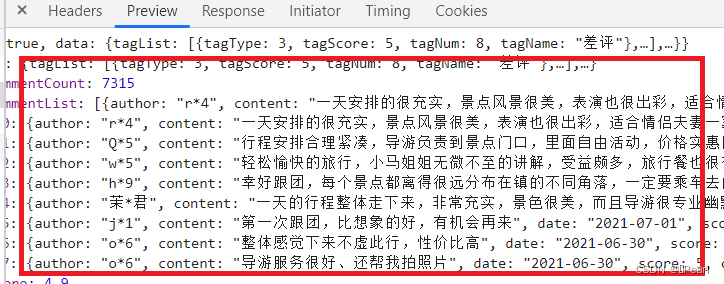
图5-9 评论页面获取内容
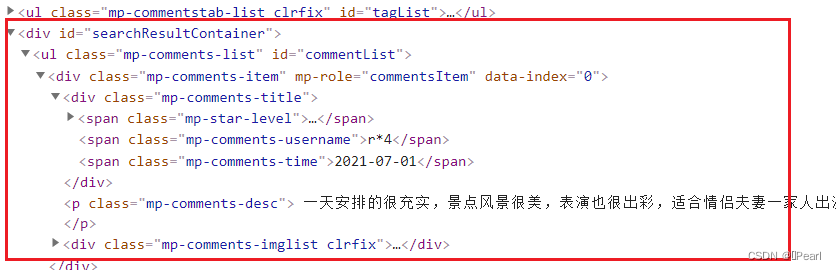
图5-10 评论信息获取
核心代码设计展示:
for a in alinks:
browser2 = webdriver.Chrome()
href = a.get_attribute('href') #获取详细内容页网址 (get_attribute :获取属性值)
browser2.get(href)
comments = browser2.find_elements_by_css_selector('.mp-comments-item')
for comment in comments:
# print(comment.find_element_by_css_selector('.sight_item_info p').text)
view = {
'user':comment.find_element_by_css_selector('.mp-comments-usernam').text,
'time':comment.find_element_by_css_selector('.mp-comments-time').text,
'view':comment.find_element_by_css_selector('.mp-comments-desc').text,
}
db['zhu']
图14 评论信息爬取结果
六、数据采集结果说明
最初始采集的景点有1125个,每一页15个景点。部分数据如下图所示:

图6-1 景点详细页面信息内容展示
评论数据采集了两个景点的全部信息,第一个景点一共有732页评论,第二个景点一共有16750页,共爬取出了261139条数据。部分数据如下图:

图 6-2 评论页信息展示
七、项目总结与个人心得
这次项目从选择网站到完成,耗费的时间出乎我的意料,毕竟是第一次做项目,但对于个人而言,这是一次综合性的考验与锻炼了。从学习这门课程的时候,其实我就一直有一个想法,尝试做一个项目,本以为可以轻轻松松的完成,可当真正实现去爬取数据的时候才发现,每一个细节的错误,都可能让你原地踏步。尤其是在爬取评论数据的详细信息时,遇到信息爬取不出,每一次的爬取错误也不一样,明明代码又没有出错的情况,真的很让我崩溃,一开始我尝试部分代码运行,它成功了,但当我把这部分代码与其他的,也能运行出来的代码放一起时,却依旧不行,最后,通过不断的查阅资料,换取爬取方法,才解决了这个问题。并且,这个整整花了我两天时间的通宵,真的现实总是残酷的。无论干什么,细心、耐心真的挺重要的,就这次项目来说,到完成,爬取出来的东西可能对别人来说,就挺容易的,而我,真的尽力了,但如果我放弃了,那么不就连这点东西都没了吗,因此,对于自己的成果,我还是挺欣慰的,尤其是拿去给老师看过后得到表扬,真的超级激动与开心。毕竟我努力了,以后我还可以深入学习,爬取更加厉害的数据,做更加厉害的项目。
最后希望小伙伴们看到这篇文章的时候,也不要放弃自己,努力总会有收获的,尝试最重要。
















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











