






一、初识python爬虫
什么是爬虫?
-
爬取网络数据的虫子(Python程序)
爬虫实质是什么呢?
-
模拟浏览器的工作原理,向服务器请求相应的数据
浏览器的工作原理
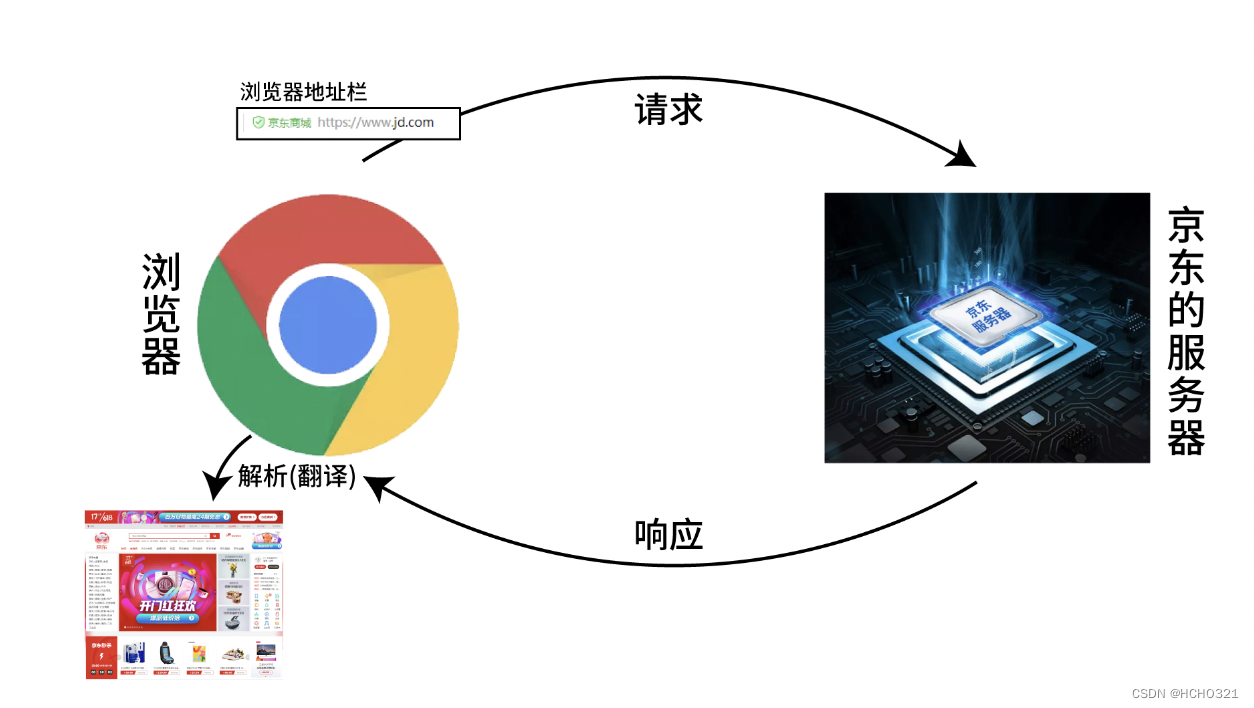
爬虫的工作原理如下图:

方法一:3行代码爬取数据
第一步:分析需求,需要什么样的数据。如京东最受欢迎的鞋子颜色与鞋码。
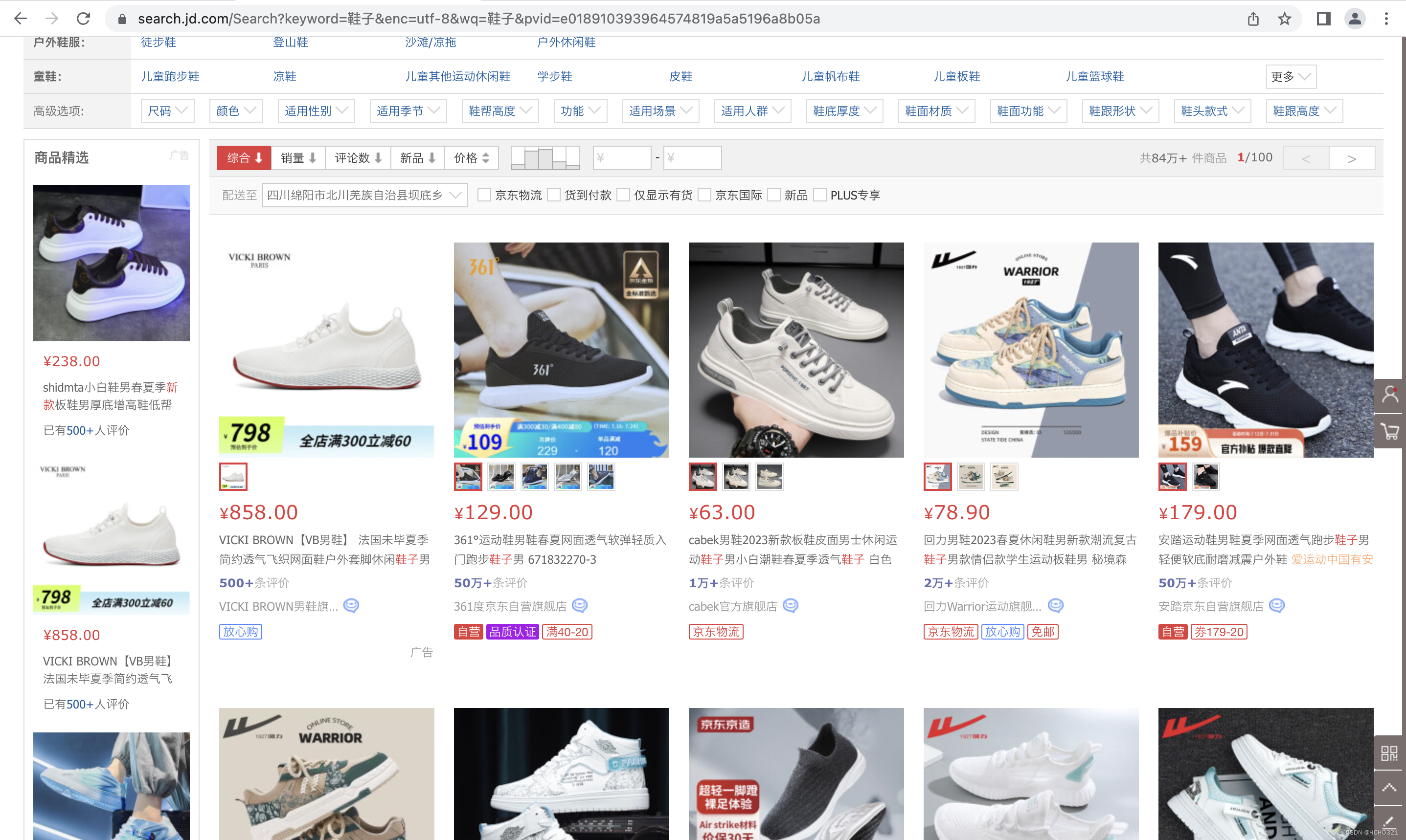
销量?数据来源?
页面没有明确的销量数据,其销量也是有相对时间或其他范围,故我们使用评论数间接反应销量。
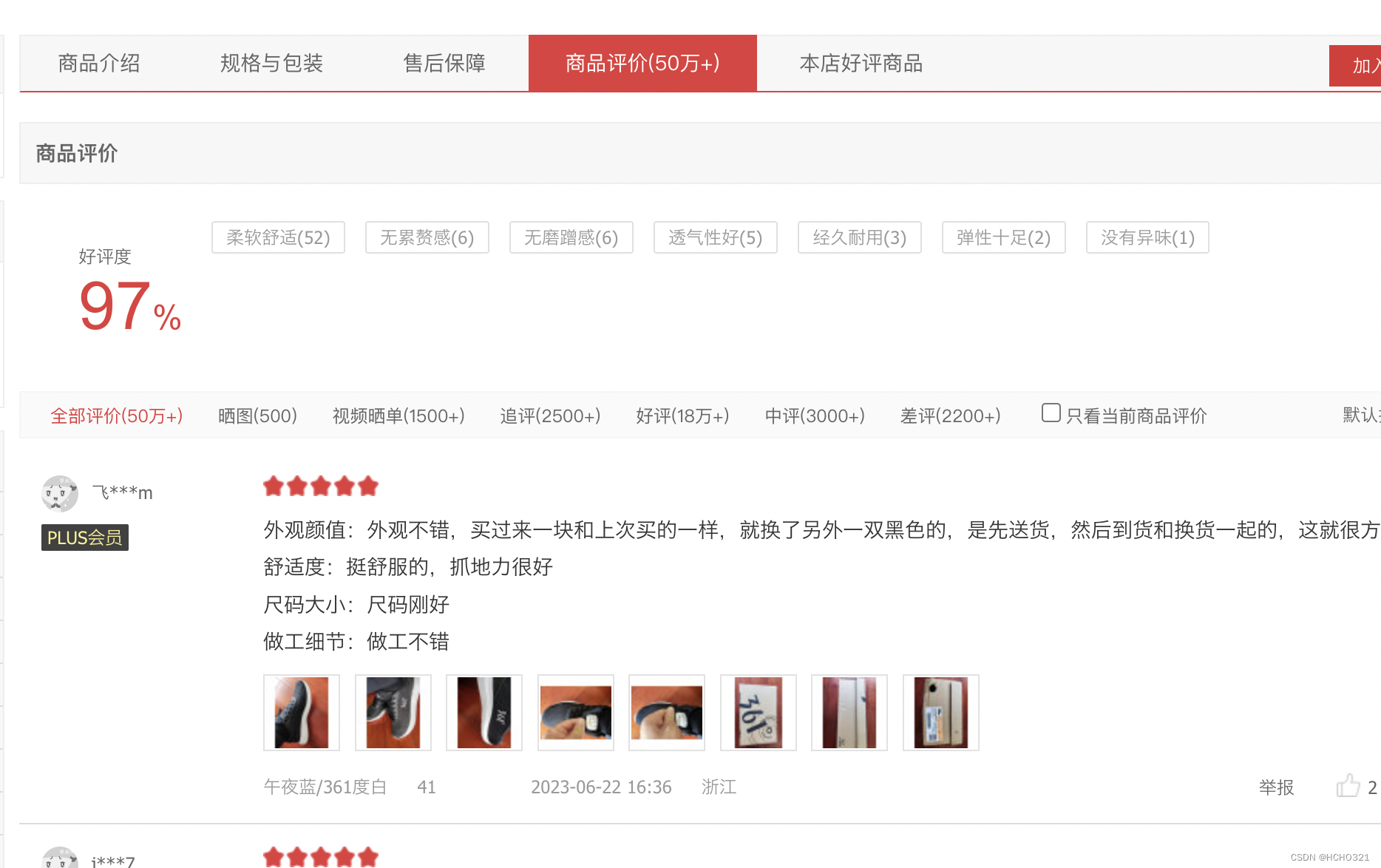
评论区复制一小段评论,在程序员调试窗口搜索,并且在header处找到我们所需要的URL
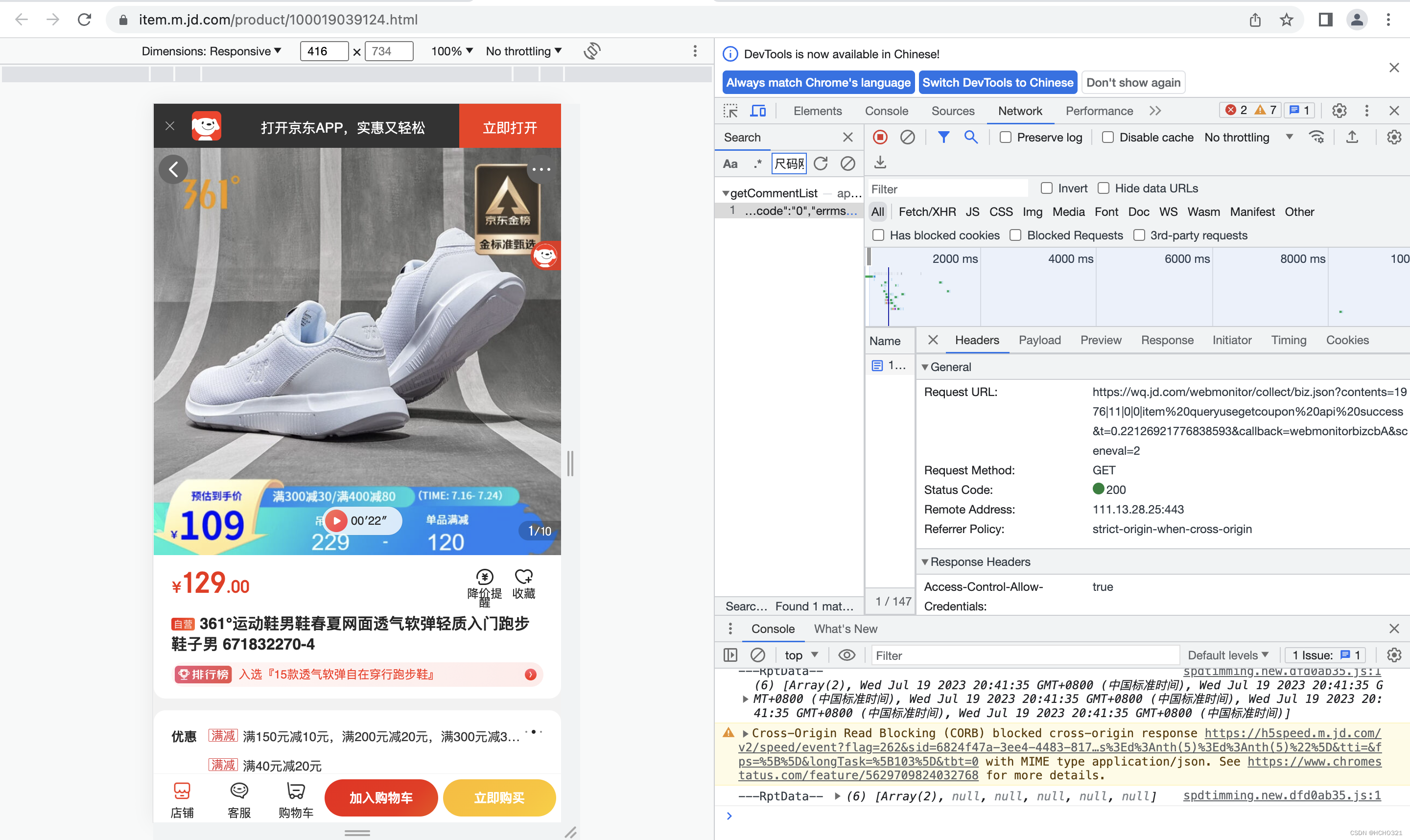
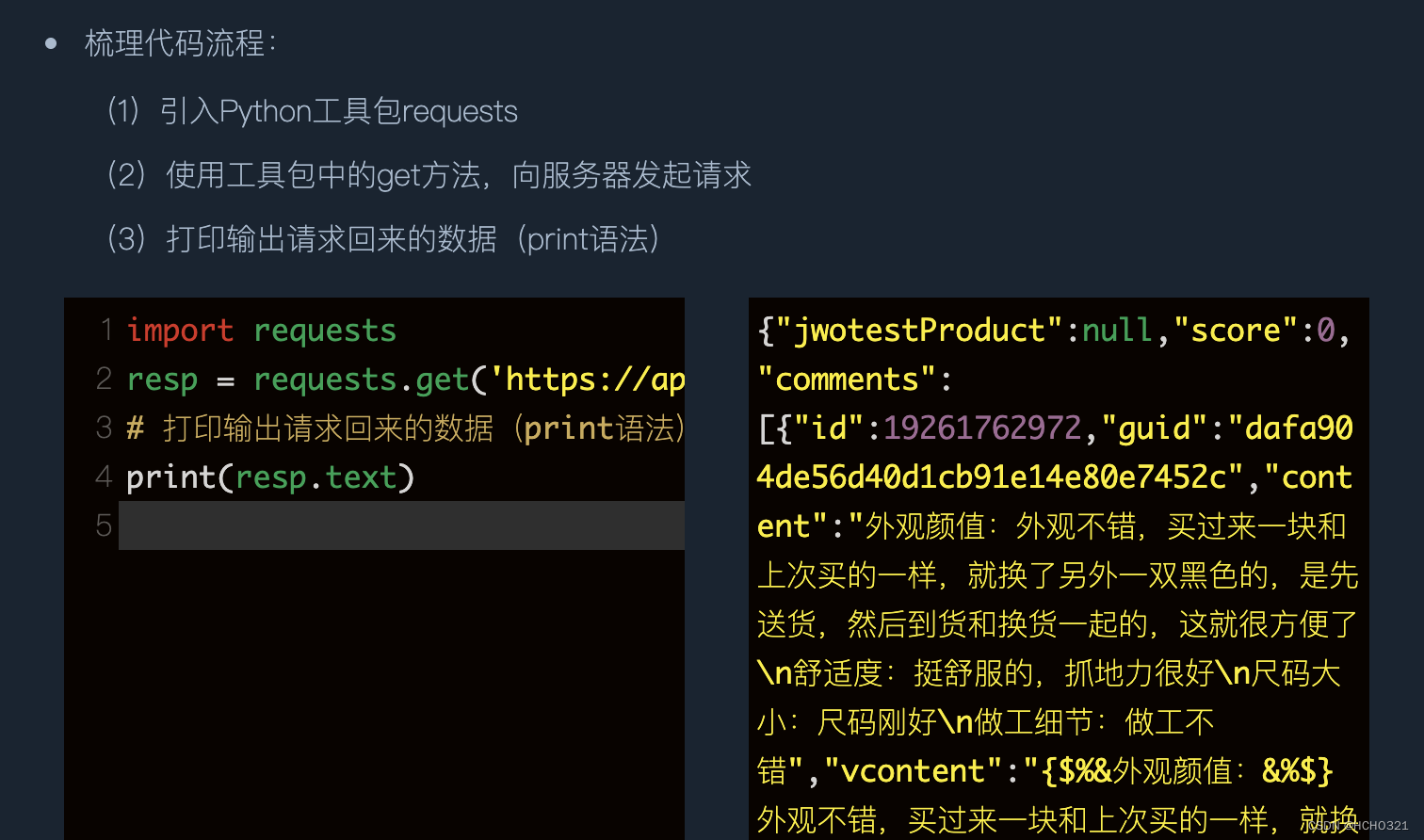
# 梳理代码流程:
# 引入Python工具包requests
import requests
# 使用工具包中的get方法,向服务器发起请求,这里是从header复制过来的“URL”
resp = requests.get('URL')
# 打印输出请求回来的数据(print语法)
print(resp.text)
第二步:提取所需数据
如何解析这堆杂乱无章的数据?
(1)打开网页工具 www.json.cn
(2)将数据整理成Json格式:以大括号开头和结尾
(3)找到目标数据值对应的名字了解数据 打开网页工具 www.json.cn
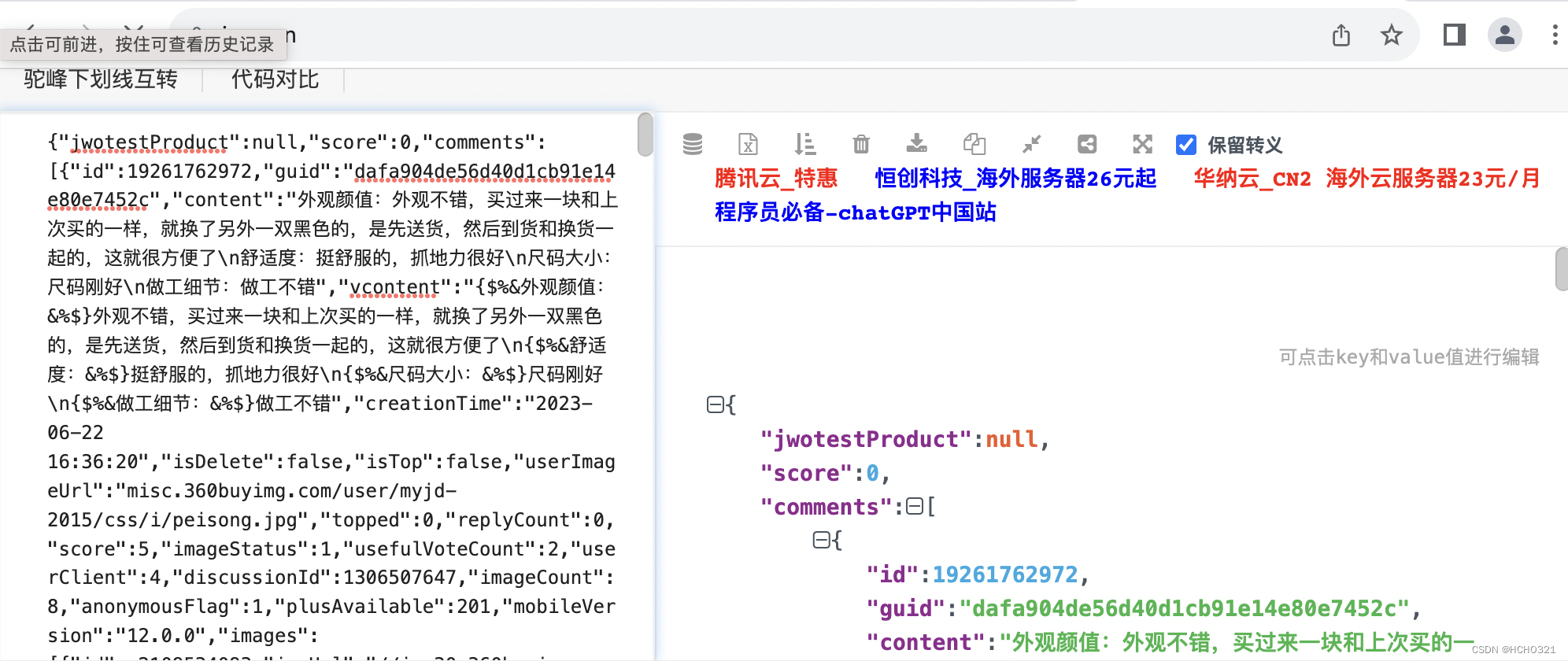
找到所需数据
修改文本格式:去掉文本的前缀后缀,只保留到大括号(这里文本不用修改)
import requests
import json
resp = requests.get('https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1689775052396&loginType=3&uuid=122270672.1689774671777566244798.1689774672.1689774672.1689774672.1&productId=8240108&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield=')
rest = resp.text
# 传给json工具,将其整理为json格式(类似网页版json)
json_data = json.loads(rest)
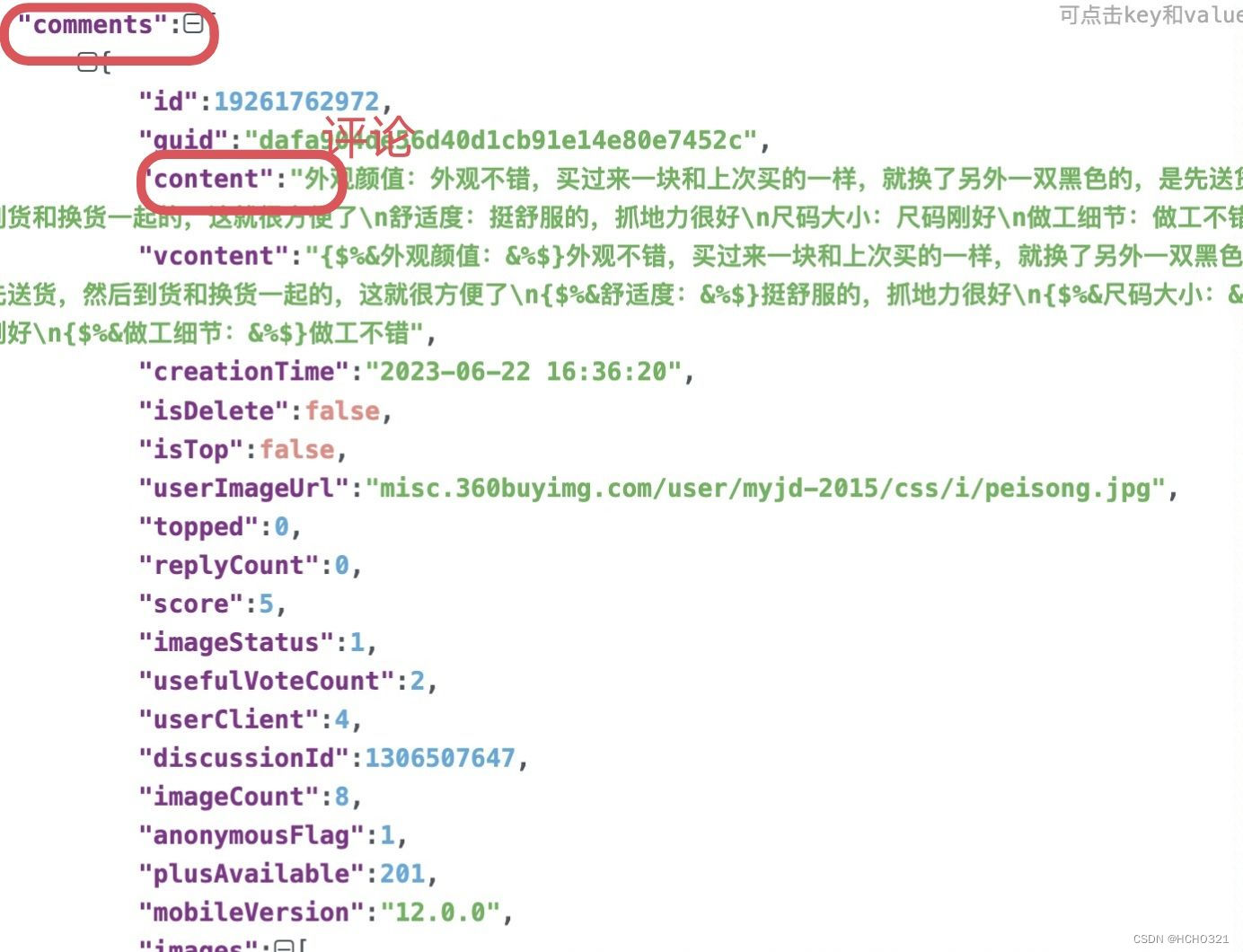
# 找到目标数据值对应的名字
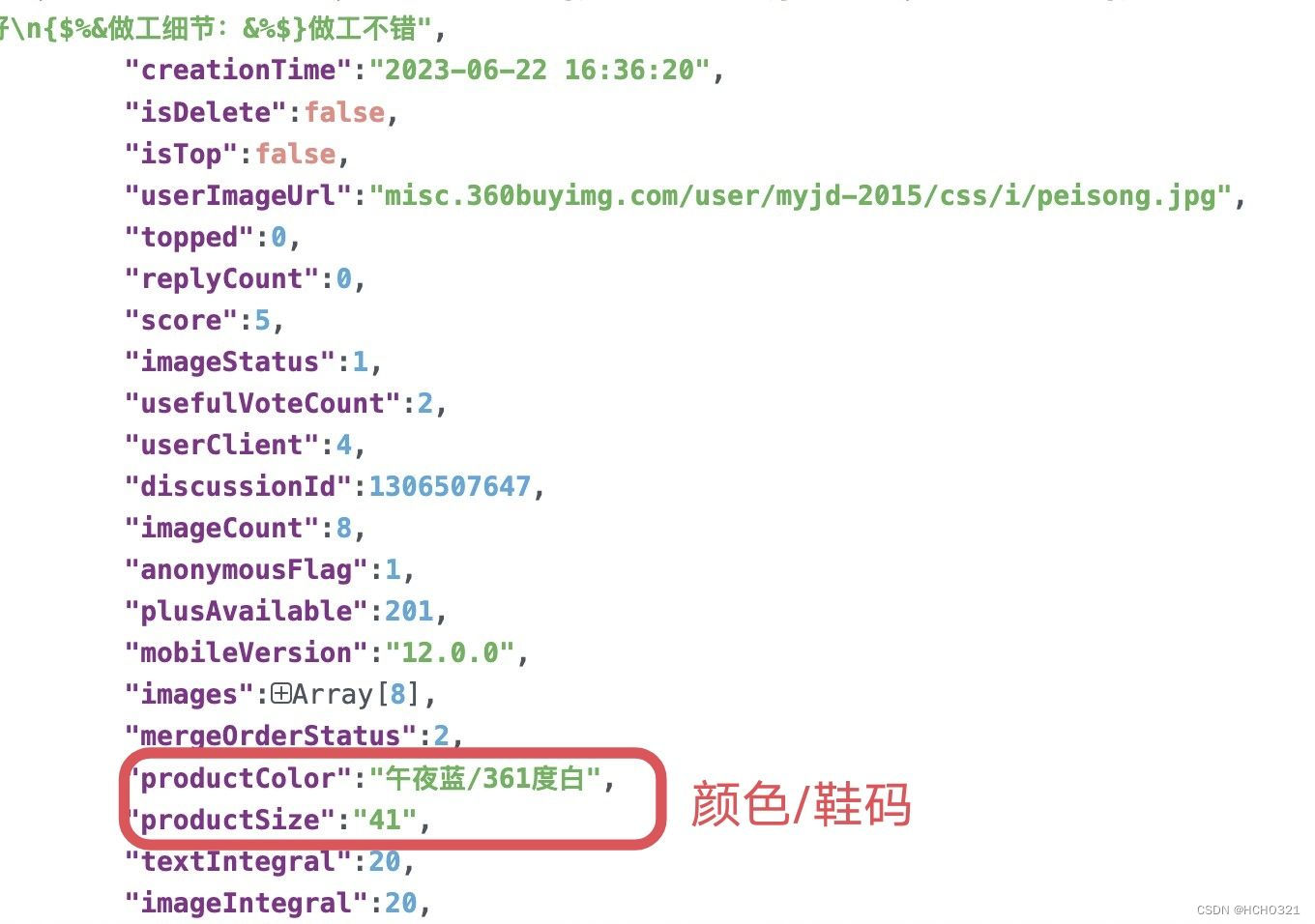
# 所需数据评价(content)、颜色(productColor)、鞋码(productSize)
# 10个object
comments = json_data['comments']
for item in comments:
#item 代表每一个object
color = item['productColor']
size = item['productSize']
print(color)
print(size)

replace补充
Python replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
replace()方法语法:
str.replace(old, new[, max])
参数
old -- 将被替换的子字符串。
new -- 新字符串,用于替换old子字符串。
max -- 可选字符串, 替换不超过 max 次例子:
rest = 'hellopython'.replace('python','')
print(rest)
运行结果:
hello第三步:保存数据
学会引入openpyxl工具包存储数据?
(1)创建一个Excel表格
(2)创建一个sheet
(3)在sheet里面保存数据
(4)把表格保存在一个磁盘里import requests
import json
import openpyxl
# 创建一个Excel表格wk
wk = openpyxl.Workbook()
# 创建一个sheet
sheet = wk.create_sheet()
resp = requests.get('https://api.m.jd.com/?appid=item-v3&functionId=pc_club_productPageComments&client=pc&clientVersion=1.0.0&t=1689775052396&loginType=3&uuid=122270672.1689774671777566244798.1689774672.1689774672.1689774672.1&productId=8240108&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1&bbtf=&shield=')
rest = resp.text
json_data = json.loads(rest)
comments = json_data['comments']
for item in comments:
color = item['productColor']
size = item['productSize']
# 在sheet里面保存数据
sheet.append([color, size])
wk.save('./sheet1.0.xlsx')
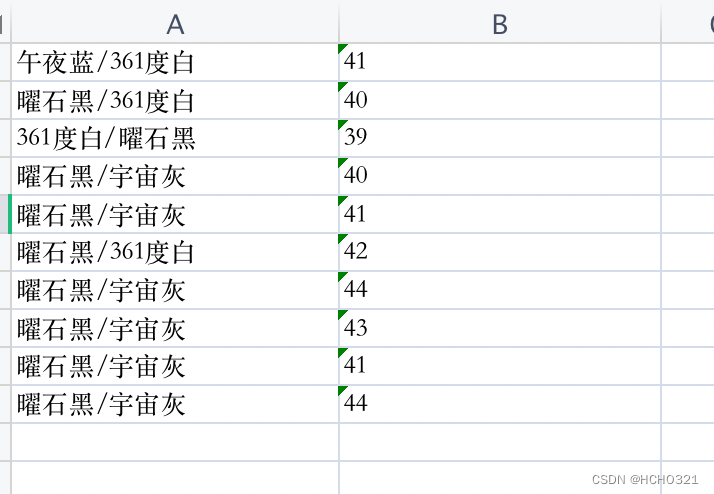
数据可视化
import matplotlib
import requests
import json
import openpyxl
import matplotlib.pyplot as plt
wk = openpyxl.load_workbook('./sheet1.0.xlsx')
sheet = wk['Sheet1']
colors = []
sizes = []
for i in range(1, 21):
colors.append(sheet['A' + str(i)].value)
sizes.append(sheet['B' + str(i)].value)
color_class = set(colors)
count = len(colors)
color_percent = []
for clr in color_class:
color_percent.append(colors.count(clr) / count)
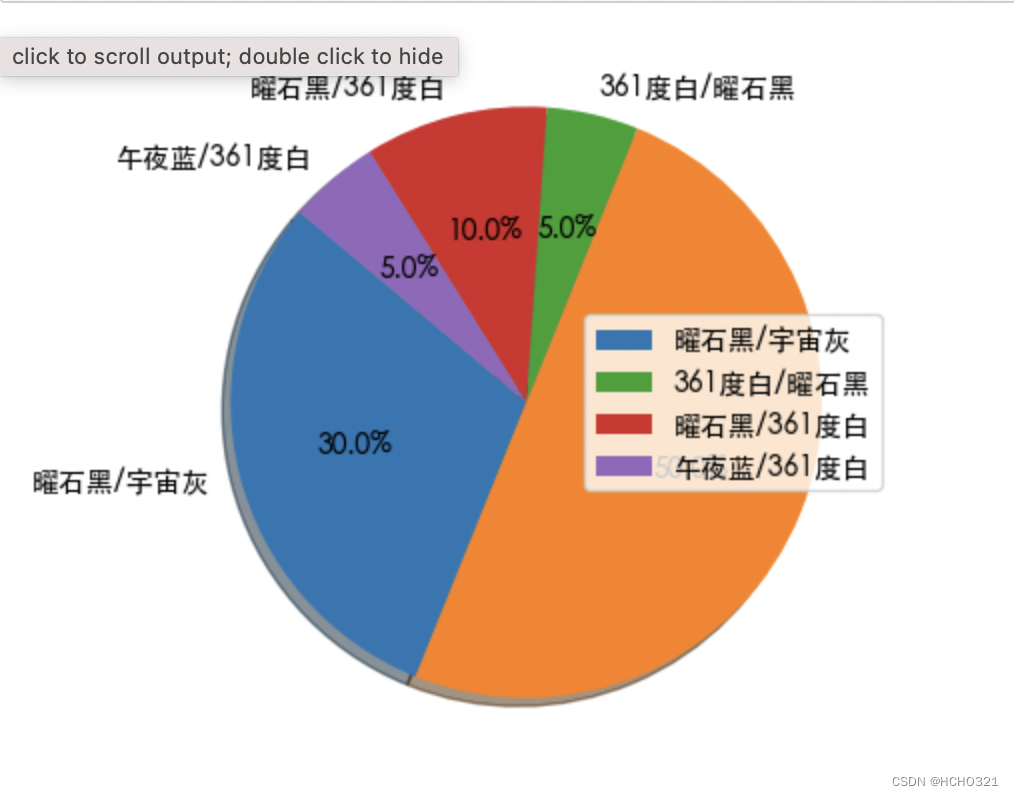
plt.pie(x=color_percent, labels=color_class, autopct='%1.1f%%', shadow=True, startangle=90)
plt.rcParams['font.sans-serif'] = 'Heiti TC'
plt.legend()
plt.savefig('./sheet.png')
结果展示:















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









