







服务发现概述
从 Internet 刚开始兴起,如何动态感知后端服务的地址变化就是一个必须要面对的问题,为此人们定义了 DNS 协议,基于此协议,调用方只需要记住由固定字符串组成的域名,就能轻松完成对后端服务的访问,而不用担心流量最终会访问到哪些机器 IP,因为有代理组件会基于 DNS 地址解析后的地址列表,将流量透明的、均匀的分发到不同的后端机器上。
在使用微服务构建复杂的分布式系统时,如何感知 backend 服务实例的动态上下线,也是微服务框架最需要关心并解决的问题之一。业界将这个问题称之为 - 微服务的地址发现(Service Discovery),业界比较有代表性的微服务框架如 SpringCloud、Dubbo 等都抽象了强大的动态地址发现能力,并且为了满足微服务业务场景的需求,绝大多数框架的地址发现都是基于自己设计的一套机制来实现,因此在能力、灵活性上都要比传统 DNS 丰富得多。如 SpringCloud 中常用的 Eureka, Dubbo 中常用的 Zookeeper、Nacos 等,这些注册中心实现不止能够传递地址(IP + Port),还包括一些微服务的 Metadata 信息,如实例序列化类型、实例方法列表、各个方法级的定制化配置等。
下图是微服务中 Service Discovery 的基本工作原理图,微服务体系中的实例大概可分为三种角色:服务提供者(Provider)、服务消费者(Consumer)和注册中心(Registry)。而不同框架实现间最主要的区别就体现在注册中心数据的组织:地址如何组织、以什么粒度组织、除地址外还同步哪些数据?
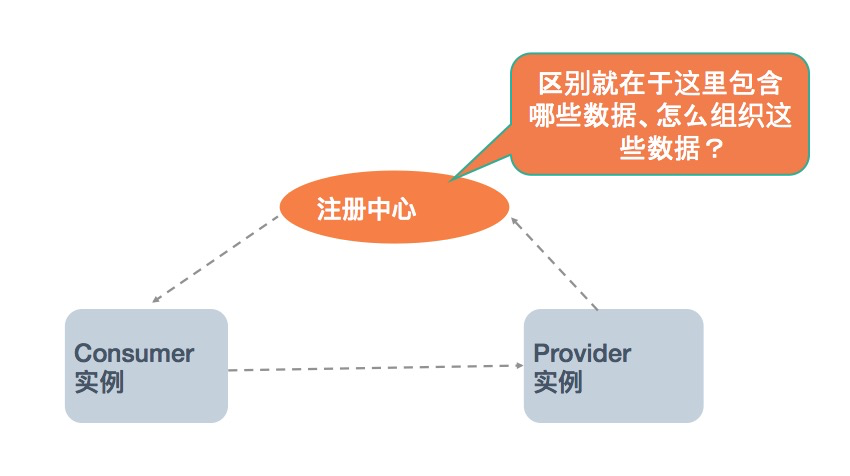
dubbo地址发现机制解析
我们先以一个 DEMO 应用为例,来快速的看一下 Dubbo “接口粒度”服务发现与“应用粒度”服务发现体现出来的区别。这里我们重点关注 Provider 实例是如何向注册中心注册的,并且,为了体现注册中心数据量变化,我们观察的是两个 Provider 实例的场景。
应用 DEMO 提供的服务列表如下:
<dubbo:service interface="org.apache.dubbo.samples.basic.api.DemoService" ref="demoService"/>
<dubbo:service interface="org.apache.dubbo.samples.basic.api.GreetingService" ref="greetingService"/>
我们示例注册中心实现采用的是 Zookeeper ,启动 192.168.0.103 和 192.168.0.104 两个实例后,以下是两种模式下注册中心的实际数据
接口粒度服务发现
192.168.0.103 实例注册的数据
dubbo://192.168.0.103:20880/org.apache.dubbo.samples.basic.api.DemoService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.DemoService&methods=testVoid,sayHello&pid=995&release=2.7.7&side=provider×tamp=1596988171266
dubbo://192.168.0.103:20880/org.apache.dubbo.samples.basic.api.GreetingService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.GreetingService&methods=greeting&pid=995&release=2.7.7&side=provider×tamp=1596988170816
192.168.0.104 实例注册的数据
dubbo://192.168.0.104:20880/org.apache.dubbo.samples.basic.api.DemoService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.DemoService&methods=testVoid,sayHello&pid=995&release=2.7.7&side=provider×tamp=1596988171266
dubbo://192.168.0.104:20880/org.apache.dubbo.samples.basic.api.GreetingService?anyhost=true&application=demo-provider&default=true&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.samples.basic.api.GreetingService&methods=greeting&pid=995&release=2.7.7&side=provider×tamp=1596988170816
应用粒度服务发现
192.168.0.103 与 192.168.0.104 两个实例共享一份注册中心数据,如下:
{
"name": "demo-provider",
"id": "192.168.0.103:20880",
"address": "192.168.0.103",
"port": 20880,
"metadata": {
"dubbo.endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"dubbo.metadata.storage-type": "local",
"dubbo.revision": "6785535733750099598"
},
"time": 1583461240877
}
{
"name": "demo-provider",
"id": "192.168.0.104:20880",
"address": "192.168.0.104",
"port": 20880,
"metadata": {
"dubbo.endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"dubbo.metadata.storage-type": "local",
"dubbo.revision": "7829635812370099387"
},
"time": 1583461240877
}
对比以上两种不同粒度的服务发现模式,从 “接口粒度” 升级到 “应用粒度” 后我们可以总结出最大的区别是:注册中心数据量不再与接口数成正比,不论应用提供有多少接口,注册中心只有一条实例数据。
那么接下来我们详细看下这个变化给 Dubbo 带来了哪些好处。
dubbo应用级服务发现的意义
- 与业界主流微服务框架对齐,比如SpringCloud,Kubernetes Native Service等
- 提升性能与可伸缩性。注册中心数据的重新组织(减少),能最大幅度的减轻注册中心的存储、推送压力,进而减少 Dubbo Consumer 侧的地址计算压力;集群规模也开始变得可预测、可评估(与 RPC 接口数量无关,只与实例部署规模相关)。
对齐主流微服务模型
自动、透明的实例地址发现(负载均衡)是所有微服务框架需要解决的事情,这能让后端的部署结构对上游微服务透明,上游服务只需要从收到的地址列表中选取一个,发起调用就可以了。要实现以上目标,涉及两个关键点的自动同步:
- 实例地址,服务消费方需要知道地址以建立连接
- RPC 方法定义,服务消费方需要知道 RPC 服务的具体定义,不论服务类型是 rest 或 rmi 等。
概念介绍,dubbo中应用,服务和实例的概念区分:
应用是一个独立的逻辑单元,一个应用可以包含多个服务,每个服务可以包含多个实例。而实例是一个具体的服务实例,一个实例可以运行在一个独立的进程中,也可以运行在多个进程中。
应用和实例在Dubbo中有以下关系:
- 应用在Dubbo中是一个逻辑单元,可以包含多个服务。
- 每个服务可以有多个实例,每个实例都是一个具体的服务提供者或消费者。
- 在Dubbo的注册中心中,应用和实例都是一个注册节点,应用节点下面包含多个服务节点,服务节点下面包含多个实例节点。
- 应用和实例都可以配置相应的元数据信息,用于描述应用或实例的基本信息和特性,例如应用名称、实例IP地址、服务端口等。
- 在Dubbo的路由和负载均衡等功能中,应用和实例都可以作为选择的对象,根据实际情况进行选择和调度。
rest通信和rmi通信
两种通信协议的区别:
- 通信协议不同:REST通信基于HTTP协议,而RMI通信基于Java的RMI协议。
- 通信方式不同:REST通信是基于请求和响应的方式,客户端发送HTTP请求到服务器,服务器返回HTTP响应;而RMI通信是基于对象的方式,客户端通过RMI协议调用服务器上的Java对象。
- 应用场景不同:REST通信适用于Web应用程序的开发和通信,而RMI通信适用于Java平台上的分布式应用程序的开发和通信。
- 跨语言支持不同:REST通信支持多种语言,可以与其他语言的Web应用程序进行通信;而RMI通信只支持Java语言。
Spring Cloud
Spring Cloud 通过注册中心只同步了应用与实例地址,消费方可以基于实例地址与服务提供方建立连接,但是消费方对于如何发起 http 调用(SpringCloud 基于 rest 通信)一无所知,比如对方有哪些 http endpoint,需要传入哪些参数等。
RPC 服务这部分信息目前都是通过线下约定或离线的管理系统来协商的。这种架构的优缺点总结如下。 优势:部署结构清晰、地址推送量小; 缺点:地址订阅需要指定应用名, provider 应用变更(拆分)需消费端感知;RPC 调用无法全自动同步。

dubbo
Dubbo 通过注册中心同时同步了实例地址和 RPC 方法,因此其能实现 RPC 过程的自动同步,面向 RPC 编程、面向 RPC 治理,对后端应用的拆分消费端无感知,其缺点则是地址推送数量变大,和 RPC 方法成正比。

dubbo+Kubernetes
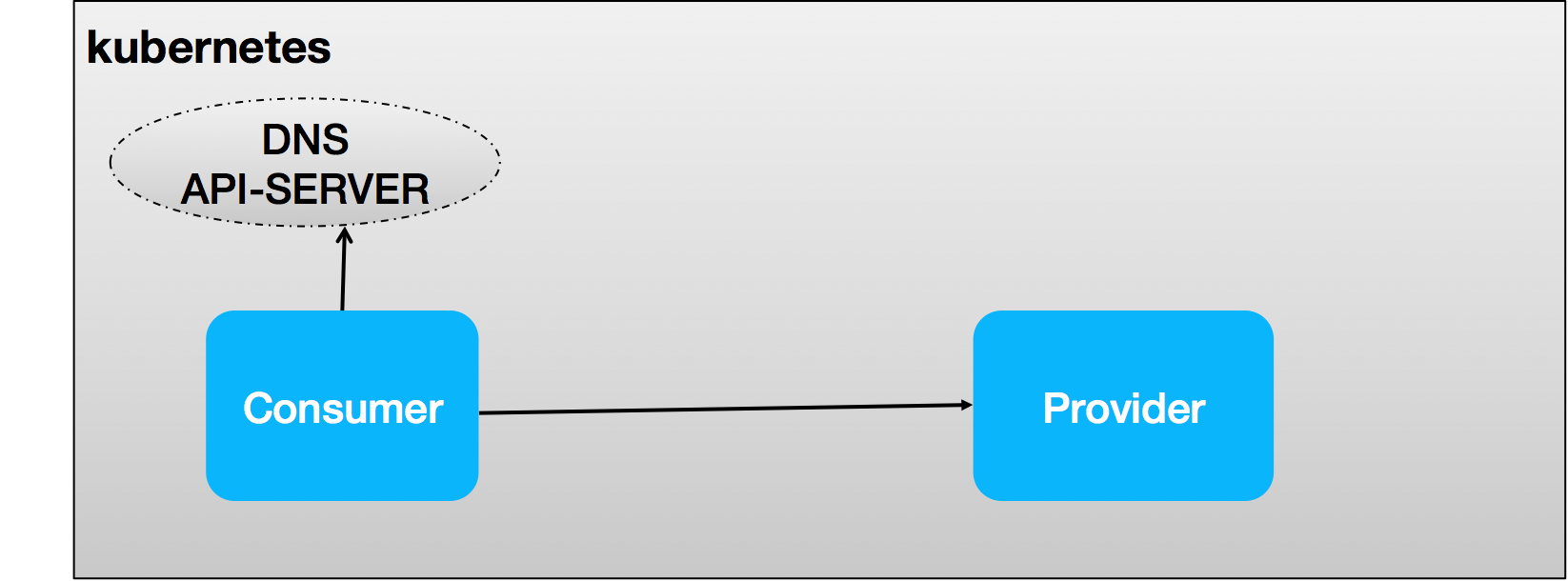
Dubbo 要支持 Kubernetes native service,相比之前自建注册中心的服务发现体系来说,在工作机制上主要有两点变化:
- 服务注册由平台接管,provider不再需要关心服务注册
- consumer端服务发现将是dubbo关注的重点,通过对接平台层的API-Server,DNS等,Dubbo client可以通过一个Service Name(通常对应到Application Name)查询到一组Endpoints(一组运行provider的pod),通过将Endpoints映射到Dubbo内部地址列表,以驱动Dubbo内置的负载均衡机制工作。
Kubernetes Service 作为一个抽象概念,怎么映射到 Dubbo 是一个值得讨论的点
- Service Name - > Application Name,Dubbo 应用和 Kubernetes 服务一一对应,对于微服务运维和建设环节透明,与开发阶段解耦。
apiVersion: v1 kind: Service metadata: name: provider-app-name spec: selector: app: provider-app-name ports: - protocol: TCP port: targetPort: 9376
- Service Name - > Dubbo RPC Service,Kubernetes 要维护调度的服务与应用内建 RPC 服务绑定,维护的服务数量变多。
--- apiVersion: v1 kind: Service metadata: name: rpc-service-1 spec: selector: app: provider-app-name ports: ## ... --- apiVersion: v1 kind: Service metadata: name: rpc-service-2 spec: selector: app: provider-app-name ports: ## ... --- apiVersion: v1 kind: Service metadata: name: rpc-service-N spec: selector: app: provider-app-name ports: ## ...
更大规模的微服务集群 - 解决性能瓶颈
这部分涉及到和注册中心、配置中心的交互,关于不同模型下注册中心数据的变化,之前原理部分我们简单分析过。为更直观的对比服务模型变更带来的推送效率提升,我们来通过一个示例看一下不同模型注册中心的对比:

图中左边是微服务框架的一个典型工作流程,Provider 和 Consumer 通过注册中心实现自动化的地址通知。其中,Provider 实例的信息如图中表格所示: 应用 DEMO 包含三个接口 DemoService 1 2 3,当前实例的 ip 地址为 10.210.134.30。
- 对于 Spring Cloud 和 Kubernetes 模型,注册中心只会存储一条
DEMO - 10.210.134.30+metadata的数据; - 对于老的 Dubbo 模型,注册中心存储了三条接口粒度的数据,分别对应三个接口 DemoService 1 2 3,并且很多的址数据都是重复的;
可以总结出,基于应用粒度的模型所存储和推送的数据量是和应用、实例数成正比的,只有当我们的应用数增多或应用的实例数增长时,地址推送压力才会上涨。 而对于基于接口粒度的模型,数据量是和接口数量正相关的,鉴于一个应用通常发布多个接口的现状,这个数量级本身比应用粒度是要乘以倍数的;另外一个关键点在于,接口粒度导致的集群规模评估的不透明,相对于实例、应用增长都通常是在运维侧的规划之中,接口的定义更多的是业务侧的内部行为,往往可以绕过评估给集群带来压力。
以 Consumer 端服务订阅举例,根据我对社区部分 Dubbo 中大规模头部用户的粗略统计,根据受统计公司的实际场景,一个 Consumer 应用要消费(订阅)的 Provier 应用数量往往要超过 10 个,而具体到其要消费(订阅)的的接口数量则通常要达到 30 个,平均情况下 Consumer 订阅的 3 个接口来自同一个 Provider 应用,如此计算下来,如果以应用粒度为地址通知和选址基本单位,则平均地址推送和计算量将下降 60% 还要多, 而在极端情况下,也就是当 Consumer 端消费的接口更多的来自同一个应用时,这个地址推送与内存消耗的占用将会进一步得到降低,甚至可以超过 80% 以上。
一个典型的极端场景即是 Dubbo 体系中的网关型应用,有些网关应用消费(订阅)达 100+ 应用,而消费(订阅)的服务有 1000+ ,平均有 10 个接口来自同一个应用,如果我们把地址推送和计算的粒度改为应用,则地址推送量从原来的 n * 1000 变为 n * 100,地址数量降低可达近 90%。
应用级服务发现工作原理
设计原则
上面一节我们从服务模型及支撑大规模集群的角度分别给出了 Dubbo 往应用级服务发现靠拢的好处和原因,但这么做的同时接口粒度的服务治理能力还是要继续保留,这是 Dubbo 框架编程模型易用性、服务治理能力优势的基础。 以下是我认为我们做服务模型迁移仍要坚持的设计原则
- 新的服务发现模型要实现对原有 Dubbo 消费端开发者的无感知迁移,即 Dubbo 继续面向 RPC 服务编程、面向 RPC 服务治理,做到对用户侧完全无感知。
基本原理详解
应用级服务发现作为一种新的服务发现机制,和以前 Dubbo 基于 RPC 服务粒度的服务发现在核心流程上基本上是一致的:即服务提供者往注册中心注册地址信息,服务消费者从注册中心拉取&订阅地址信息。
这里主要的不同有以下两点:
注册中心数据以“应用 - 实例列表”格式组织,不再包含RPC服务信息
以下是每个 Instance metadata 的示例数据,总的原则是 metadata 只包含当前 instance 节点相关的信息,不涉及 RPC 服务粒度的信息。
总体信息概括如下:实例地址、实例各种环境标、metadata service 元数据、其他少量必要属性。
{
"name": "provider-app-name",
"id": "192.168.0.102:20880",
"address": "192.168.0.102",
"port": 20880,
"sslPort": null,
"payload": {
"id": null,
"name": "provider-app-name",
"metadata": {
"metadataService": "{\"dubbo\":{\"version\":\"1.0.0\",\"dubbo\":\"2.0.2\",\"release\":\"2.7.5\",\"port\":\"20881\"}}",
"endpoints": "[{\"port\":20880,\"protocol\":\"dubbo\"}]",
"storage-type": "local",
"revision": "6785535733750099598",
}
},
"registrationTimeUTC": 1583461240877,
"serviceType": "DYNAMIC",
"uriSpec": null
}
Client-Server自行协商PRC方法信息
在注册中心不再同步 RPC 服务信息后,服务自省在服务消费端和提供端之间建立了一条内置的 RPC 服务信息协商机制,这也是“服务自省”这个名字的由来。服务端实例会暴露一个预定义的 MetadataService RPC 服务,消费端通过调用 MetadataService 获取每个实例 RPC 方法相关的配置信息。

当前 MetadataService 返回的数据格式如下,
[
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.DemoService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314",
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.HelloService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314",
"dubbo://192.168.0.102:20880/org.apache.dubbo.demo.WorldService?anyhost=true&application=demo-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=9585&release=2.7.5&side=provider×tamp=1583469714314"
]
熟悉 Dubbo 基于 RPC 服务粒度的服务发现模型的开发者应该能看出来,服务自省机制机制将以前注册中心传递的 URL 一拆为二:
- 一部分和实例相关的数据继续保留在注册中心,如 ip、port、机器标识等。
- 另一部分和 RPC 方法相关的数据从注册中心移除,转而通过 MetadataService 暴露给消费端。
以下是服务自省的一个完整工作流程图,详细描述了服务注册、服务发现、MetadataService、RPC 调用间的协作流程。
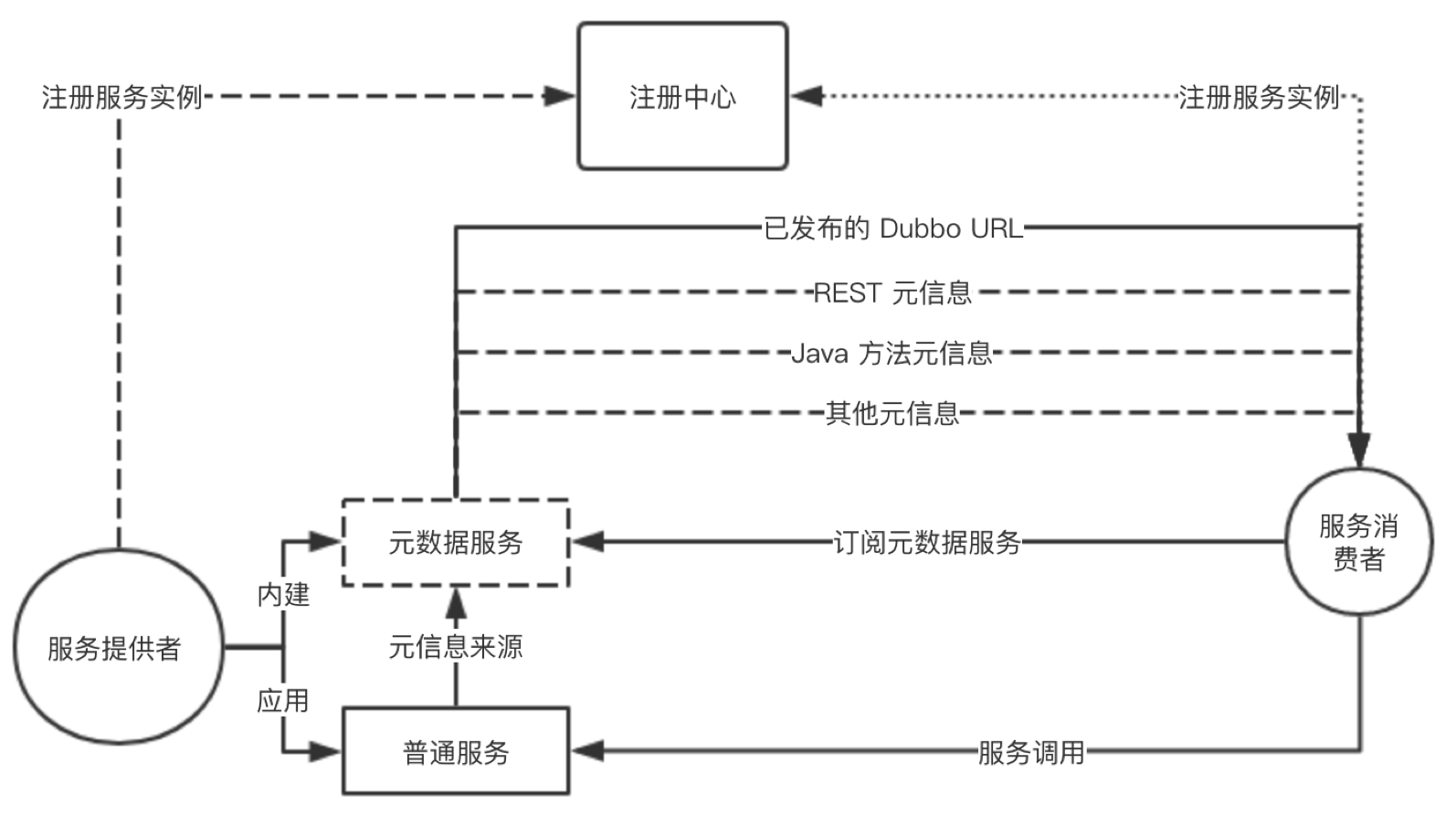
- 服务提供者启动,首先解析应用定义的普通服务并依次注册为RPC服务,紧接着注册内建的MetadataService服务,最后打开TCP监听端口。
- 启动完成后,将实例信息注册到注册中心(仅限ip,port等实例相关数据),提供者启动完成。
- 服务消费者启动,首先依据其要的消费的provider应用名到注册中心查询地址列表,并完成订阅(以实现后续地址变更自动通知)。
- 消费端拿到地址列表后,紧接着对 MetadataService 发起调用,返回结果中包含了所有应用定义的“普通服务”及其相关配置信息。
- 至此,消费者可以接收外部流量,并对提供者发起 Dubbo RPC 调用
服务自省中的关键机制
元数据同步机制
Client 与 Server 间在收到地址推送后的配置同步是服务自省的关键环节,目前针对元数据同步有两种具体的可选方案,分别是:
- 内建 MetadataService。
- 独立的元数据中心,通过中心化的元数据集群协调数据。
- 内建 MetadataService MetadataService 通过标准的 Dubbo 协议暴露,根据查询条件,会将内存中符合条件的“普通服务”配置返回给消费者。这一步发生在消费端选址和调用前。
- 元数据中心 复用 2.7 版本中引入的元数据中心,provider 实例启动后,会尝试将内部的 RPC 服务组织成元数据的格式同步到元数据中心,而 consumer 则在每次收到注册中心推送更新后,主动查询元数据中心。

RPC服务 <-> 应用映射关系
我们以往基于RPC服务来检索地址,现在consumer需要通过指定provider应用名才能实现地址查询或者订阅。
老的 Consumer 开发与配置示例:
<!-- 框架直接通过 RPC Service 1/2/N 去注册中心查询或订阅地址列表 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:reference interface="RPC Service 1" />
<dubbo:reference interface="RPC Service 2" />
<dubbo:reference interface="RPC Service N" />
新的 Consumer 开发与配置示例:
<!-- 框架需要通过额外的 provided-by="provider-app-x" 才能在注册中心查询或订阅到地址列表 -->
<dubbo:registry address="zookeeper://127.0.0.1:2181?registry-type=service"/>
<dubbo:reference interface="RPC Service 1" provided-by="provider-app-x"/>
<dubbo:reference interface="RPC Service 2" provided-by="provider-app-x" />
<dubbo:reference interface="RPC Service N" provided-by="provider-app-y" />
以上指定 provider 应用名的方式是 Spring Cloud 当前的做法,需要 consumer 端的开发者显示指定其要消费的 provider 应用。
以上问题的根源在于注册中心不知道任何 RPC 服务相关的信息,因此只能通过应用名来查询。
为了使整个开发流程对老的 Dubbo 用户更透明,同时避免指定 provider 对可扩展性带来的影响(参见下方说明),我们设计了一套 RPC 服务到应用名的映射关系,以尝试在 consumer 端自动完成 RPC 服务到 provider 应用名的转换。

















 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











