









Dubbo3 概述
Dubbo3以基于应用级别的服务发现,适应云原生技术两大诉求发展而来。那升级dubbo3.0后能带来哪些好处呢?
按官方说法,以下是官网的原文
相比于 2.x 版本中的基于接口粒度的服务发现机制,3.x 引入了全新的基于应用粒度的服务发现机制, 新模型带来两方面的巨大优势:
- 进一步提升了 Dubbo3 在大规模集群实践中的性能与稳定性。新模型可大幅提高系统资源利用率,降低 Dubbo 地址的单机内存消耗(50%),降低注册中心集群的存储与推送压力(90%), Dubbo 可支持集群规模步入百万实例层次。
- 打通与其他异构微服务体系的地址互发现障碍。新模型使得 Dubbo3 能实现与异构微服务体系如Spring Cloud、Kubernetes Service、gRPC 等,在地址发现层面的互通, 为连通 Dubbo 与其他微服务体系提供可行方案。
公司部署的Dubbo2.x服务面临的主要问题
先看下dubbo2.x经典的工作原理图
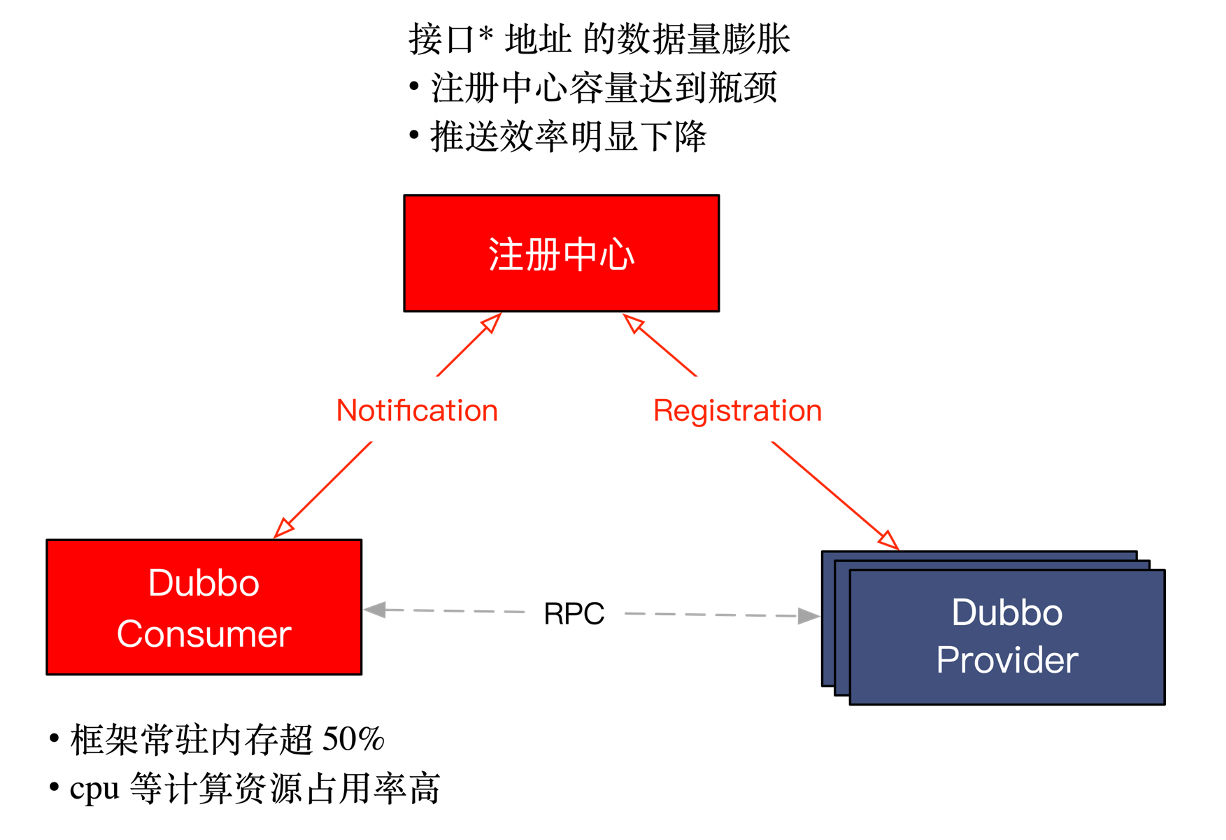
1、我们都知道,Dubbo2.x是基于接口级别的服务发现,现在都是微服务当道,每个服务至少几十上百个接口,对于业务处于快速发展的我们,每个月不停有项目产品上线,每个项目少则十几个微服务,多则几十个微服务,加上存量的上千个微服务,导致注册节点的数据量非常大。
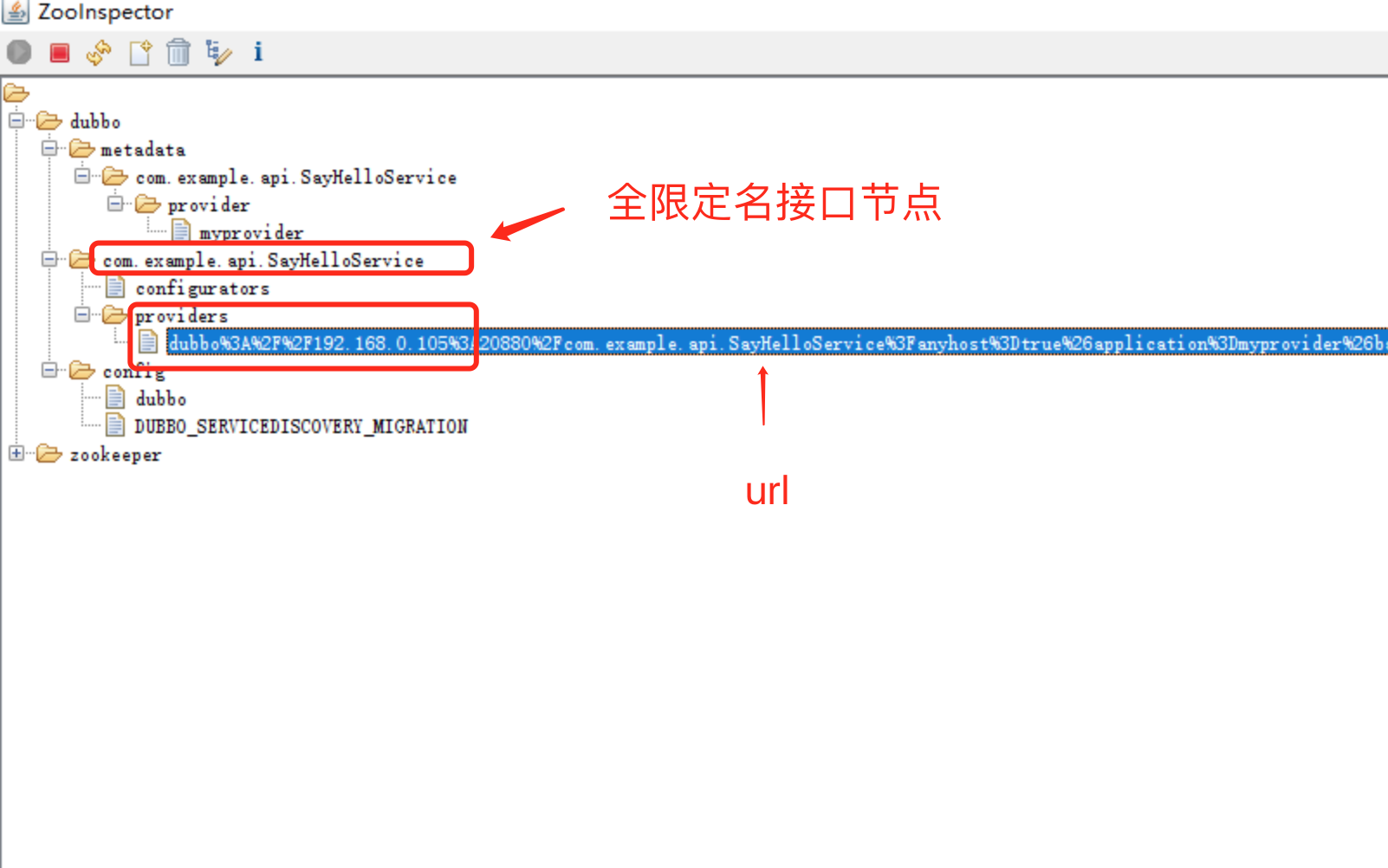
假如一个微服务应用有100个接口,每个应用部署10台机器,那么zookeeper的目录下有100个全限定名接口目录(注:我们公司是zookeeper作为注册中心),而每个接口目录的provider下有10个机器url,每个url只是IP和Port不同,其他参数诸如重试次数、接口的容错策略等都是相同的,就会产生1000条重复数据,增加了注册中心的压力。
zookeeper节点如下:
2、另外,消费者服务也需要订阅注册中心存储的服务接口的providers目录,因为要感知服务提供者接口的上下线,以更新本地缓存接口列表。
3、还有一个原因,当一个节点下线时,假设有100个接口,消费服务会收到100个订阅通知,对消费端服务来说也增加了不少cpu压力、常驻内存已超40%。
替换成Dubbo3.0后的效果
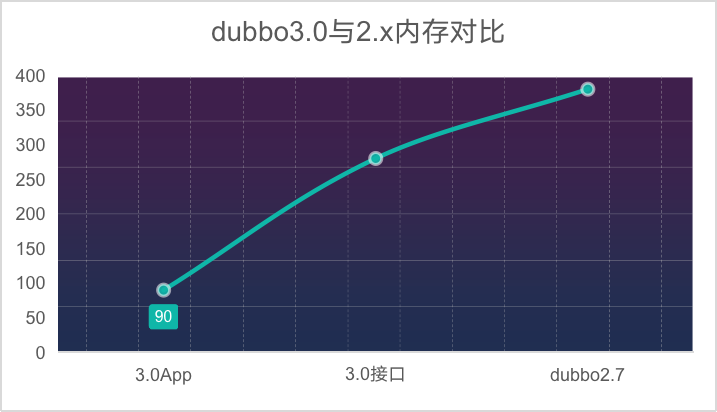
图一
图一 服务发现模型内存占用变化
图一是消费端进程采样的内存对比数据。其中横轴是dubbo版本,纵轴是实际内存表现
- Dubbo3 接口级服务发现模型,常驻内存较 2.x 版本下降约 50%
- Dubbo3 应用级服务发现模型,常驻内存较 2.x 版本下降约 73%















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









