






目录
一、决策树是什么
决策树通常用于分类和回归问题。它通过对数据集进行递归地划分,最终生成一棵树状结构,其中每个内部节点表示一个特征,每个叶子节点表示一个类别或数值。
二、 决策树分类原理
决策树的划分依据
1.信息增益:
信息增益就是用来评估一个特征对于分类任务的贡献程度的指标

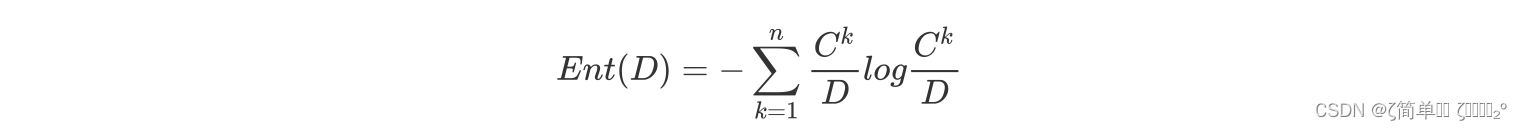
 2.信息增益率:
2.信息增益率:
信息增益率是一种改进的特征选择度量方法,用于解决信息增益对取值较多的特征有偏好的问题,通过对信息增益进行调整,考虑了特征的取值数量对信息增益的影响。
 3.基尼指数:
3.基尼指数:
基尼指数是一种衡量数据集纯度的度量方法,常用于决策树算法中的特征选择。基尼指数越小,表示数据集纯度越高。


三、决策树实现
构建模型
import numpy as np
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, value=None):
self.feature = feature # 划分特征的索引
self.threshold = threshold # 划分阈值
self.left = left # 左子树
self.right = right # 右子树
self.value = value # 叶子节点的预测值
class DecisionTree:
def __init__(self, max_depth=None):
self.max_depth = max_depth
def fit(self, X, y):
self.n_classes = len(set(y))
self.n_features = X.shape[1]
self.tree = self._grow_tree(X, y)
def predict(self, X):
return [self._predict(inputs) for inputs in X]
def _grow_tree(self, X, y, depth=0):
n_samples_per_class = [np.sum(y == i) for i in range(self.n_classes)]
predicted_class = np.argmax(n_samples_per_class)
node = Node(value=predicted_class)
if depth < self.max_depth:
best_gain = 0.0
best_feature = None
best_threshold = None
for feature in range(self.n_features):
thresholds = np.unique(X[:, feature])
for threshold in thresholds:
gain = self._information_gain(X, y, feature, threshold)
if gain > best_gain:
best_gain = gain
best_feature = feature
best_threshold = threshold
if best_gain > 0.0:
left_indices = X[:, best_feature] <= best_threshold
X_left, y_left = X[left_indices], y[left_indices]
X_right, y_right = X[~left_indices], y[~left_indices]
node.feature = best_feature
node.threshold = best_threshold
node.left = self._grow_tree(X_left, y_left, depth + 1)
node.right = self._grow_tree(X_right, y_right, depth + 1)
return node
def _predict(self, inputs):
node = self.tree
while node.left:
if inputs[node.feature] <= node.threshold:
node = node.left
else:
node = node.right
return node.value
def _information_gain(self, X, y, feature, threshold):
parent_entropy = self._entropy(y)
left_indices = X[:, feature] <= threshold
right_indices = X[:, feature] > threshold
n = len(y)
n_left = np.sum(left_indices)
n_right = np.sum(right_indices)
left_entropy = self._entropy(y[left_indices])
right_entropy = self._entropy(y[right_indices])
child_entropy = (n_left / n) * left_entropy + (n_right / n) * right_entropy
return parent_entropy - child_entropy
def _entropy(self, y):
entropy = 0.0
for c in range(self.n_classes):
p = np.mean(y == c)
if p > 0.0:
entropy -= p * np.log2(p)
return entropy实例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型并拟合数据
tree = DecisionTree(max_depth=2)
tree.fit(X_train, y_train)
# 使用模型进行预测
pred_y = tree.predict(X_test)
print(pred_y)
# 计算准确率
accuracy = accuracy_score(y_test, pred_y)
print("Accuracy:", accuracy)结果
 四、实验中的问题
四、实验中的问题
决策树模型没有进行剪枝等优化处理,不适用于处理大规模数据集。
五、实验总结
决策树优点:简单易懂,能处理多种数据类型,能够同时处理多个目标变量,可应对缺失的数据, 不用归一化。
决策树缺点:容易过拟合,对输入数据的表示形式敏感,不稳定性,忽略特征相关性















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









