






采用数据集共有两种,在模型微调时将这两个数据集混合到一起成一个文件,防止chatglm在微调健康建议任务时导致对病历提取和生成任务的灾难性遗忘
1.使用chatgpt生成和手写的用于病历提取和生成任务的数据集(少量)
2. github开源中文医疗问答对话数据集
地址:GitHub - Toyhom/Chinese-medical-dialogue-data: Chinese medical dialogue data 中文医疗对话数据集
数据集清洗和处理过程:
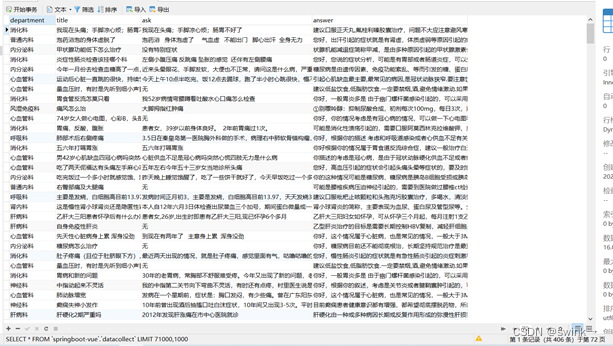
经过初步粗筛导入到数据库中并且使用navicate的数据集:约72000条
 \
\
初步删除、清洗
保留需要的列 、依据需要的数据项类型和格式删除不符合的行:
比如主诉无意义、主诉为“无的”

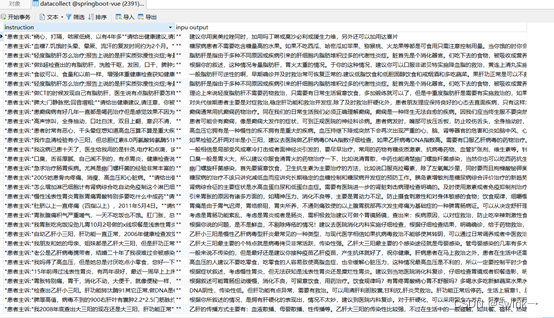
数据清洗和处理最终结果:
格式化、保留需要的列、去除不符合输入要求的行 ,导出成json文件后作为数据集。
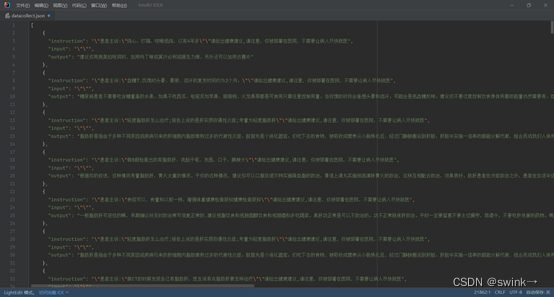
附:使用的关键sql脚本

部分清洗用脚本内容:
DELETE FROM datacollect
WHERE instruction LIKE '%回事%'
OR instruction LIKE '%?%'
OR instruction LIKE '%问%'
OR instruction LIKE '%!%'
OR instruction LIKE '%啊%';
DELETE FROM datacollect
WHERE CHAR_LENGTH(input) < 6
OR CHAR_LENGTH(input) > 50
OR input LIKE '%?'
OR output LIKE '你%'
OR output LIKE '您%'
OR input LIKE '%吗'
OR input LIKE '%么'
OR input LIKE '%办'
OR input LIKE '%下'
OR input LIKE '%谢'
OR input LIKE '%!';
UPDATE datacollect
SET input = CONCAT(input, '请给出健康建议,请注意,你被部署在医院,不需要让病人尽快就医');














 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









