






Hadoop是分布式系统基础架构,具有高速运算和储存、数据存量和增量极大、可以存储极大数据可靠、高效、可伸缩、成本低的优点。Hadoop框架最核心的设计是HDFS和MapReduce。Hadoop核心:Hadoop Common(是一个公共基础设施,用于支撑其他项目,包括RPC、序列化包等)、Hadoop Hdfs(可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取)、Hadoop Mapreduce(分布式计算框架:主要包含map(映射)和reduce(规约)过程)。
分布式文件系统:高度容错性的系统(自动保存多个副本)适合大数据的处理(高吞吐量)流式文件写入(一次写入多次读取)。
NameNode(管理文件系统的命名空间):用于存储元数据以及处理客户端发出的请求。
SN:一个Checkpoint来帮助NameNode更好的工作,DataNode,它为 HDFS 提供存储位置。
HDFS:对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件。

文件上传:
Fsimage在启动的时候读取Fsimage并和Edits合并——》Namenode——》将改动文件写入系统中——》Edtis 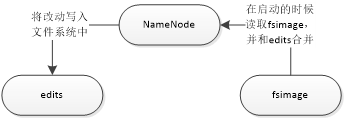
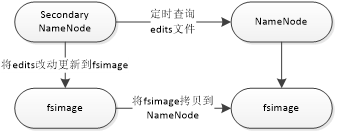
SecondaryNameNode——》定时查询edtis文件——》Namenode——》fsimage
SecondaryNameNode——》将edtis改动更新到fsimage——》fsimage——》将fsimage拷贝到namenode——》fsimage
分布式概念:
HDFS并不是一个单机文件系统,它是分布在多个集群节点上的文件系统。节点之间通过网络通信进行协作,提供个节点文件信息,让每个用户都可以看到文件系统的文件,让多机器上的多用户分享文件和存储空间。
文件存储时被分布在多个节点上。这里涉及到一个数据块的概念,数据存储不是按一个文件存储,而是把一个文件分成一个或多个数据块存储,数据块的概念在上一节已经描述过。数据块在存储时并不是都存在一个节点上,而是被分布存储在各个节点中,并且数据块会在其他节点存储副本。
数据读取从多个节点读取。读取一个文件时,从多个节点中找到该文件的数据块,分布读取所有数据块直到最后一个数据块读取完毕。
宕机处理:
1. 冗余备份
2. 副本存放
3. 备份读取
4. 备份数补充
并行计算框架(MapReduce):
MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
MapReduce:Hadoop分布式计算框架:
Map:映射,把键值对使用函数映射成新的键值对。
reduce:规约,把键值对中键相同的值整合,同时应用
函数映射成新的键值对。















 2608
2608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









