






一.超过容器限制的内存
#这里我们限制pod最多只能使用100M内存,但我们让pod里的容器申请250M内存,我们看看会发生什么
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: mem-example
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
limits:
memory: "100Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
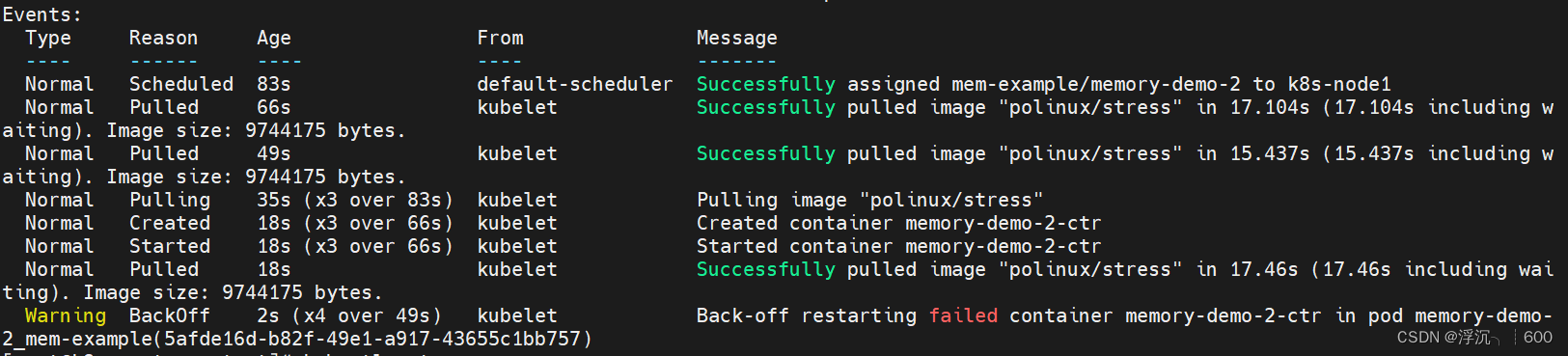
由于容器使用的内存超过限制,k8s认为该容器发生内存泄露,存在故障不停地拉取镜像重启Pod,在多次启动失败以后容器会变为CrashLoopBackOff状态,当容器达到重启策略最大时间以后(默认5分钟),不会再重启该容器


二.如果只设置内存请求值,而不设置上限值会怎样?
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: mem-example
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "1G", "--vm-hang", "1"]#可以看到该pod调度到node1上了,并且可以运行,我们来探索一下为什么可以运行
kubectl get po -n mem-example -o wide
#可以看到,pod中容器运行期间,node1可用内存还有199M
free -h
#将pod删除,发现原本node1节点可用内存是大于容器申请的内存的,所以这个pod处于运行状态
kubectl delete -n mem-example pod memory-demo-2
free -h 

#如果让pod中容器申请资源超出节点所能承受的资源申请会怎么样
apiVersion: v1
kind: Pod
metadata:
name: memory-demo-2
namespace: mem-example
spec:
containers:
- name: memory-demo-2-ctr
image: polinux/stress
resources:
requests:
memory: "50Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "3G", "--vm-hang", "1"]
如果使用资源超出节点能承受的范围,则无法运行,且pod所调度到的节点上资源也不会对pod进行分配

这里来解读一下free -h
[root@k8s-master ~]# free -h
total used free shared buff/cache available
Mem: 1.8G 582M 439M 10M 797M 1.1G
Swap: 0B 0B 0B
#物理内存(RAM)总共有 1.8GiB,其中 582M 已被使用,439M 是完全空闲的,10M 被用于共享内存,797M 被用作缓冲和缓存,1.1G 对于新进程来说是可用的。
total:表示系统总的物理内存(RAM)大小。
used:表示已经被使用的内存大小,包括所有进程、缓冲和缓存。
free:表示完全未被使用的内存大小。
shared:通常很小或接近于零,因为 Linux 不常使用共享内存。这部分内存被多个进程共享。
buff/cache:表示被系统用作缓冲和缓存的内存大小。Linux 会使用一部分内存来缓存文件系统的数据,以提高系统性能。
available:表示对于新启动的进程来说可用的内存大小,不包括 free 列的内存。这个数字考虑了操作系统可能会使用的缓存和缓冲区,因此通常比 free 列的数字大。三.对CPU资源限制
请求和上限都有
kubectl create namespace default-cpu-examplevim cpu.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
namespace: default-cpu-example
spec:
limits:
- default:
cpu: 1
defaultRequest:
cpu: 0.5
type: Containerkubectl create -f cpu.yaml
[root@k8s-master request]# kubectl get limitranges -n default-cpu-example
NAME CREATED AT
cpu-limit-range 2024-05-17T03:26:06Z
#创建一个pod,看看他的cpu限制
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: default-cpu-example
spec:
containers:
- name: nginx
image: nginx#我们来看一下pod-nginx的配置文件
kubectl get po -n default-cpu-example -o yaml |less
#我们在创建nginx这个pod的时候并没有指明container容器里面对cpu的限制,那么,如果该命名空间下,如果存在LimitRange相关资源,则会自动给该命名空间下的Container资源按照LimitRange进行限制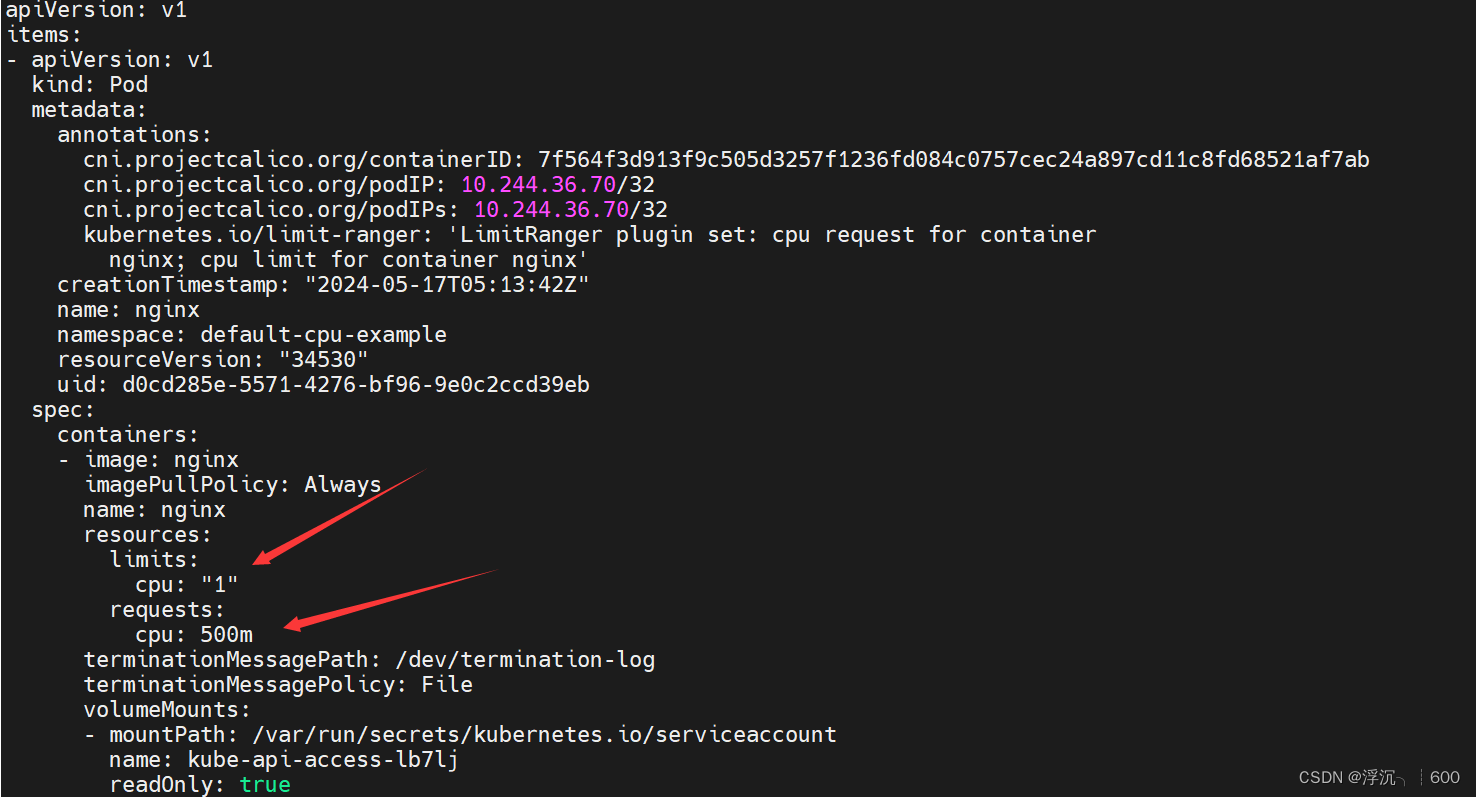
实验完毕,删除实验的命名空间
[root@k8s-master request]# kubectl delete namespaces default-cpu-example
#下图可以看到,我们在删除命名空间以后,原命名空间中的资源也会自动被k8s回收
不指定资源请求值,只设置上限值呢?资源请求值会和上限值一致!
apiVersion: v1
kind: Pod
metadata:
name: cpu-limit
spec:
containers:
- name: cpu-limit
image: nginx
resources:
limits:
cpu: "0.7"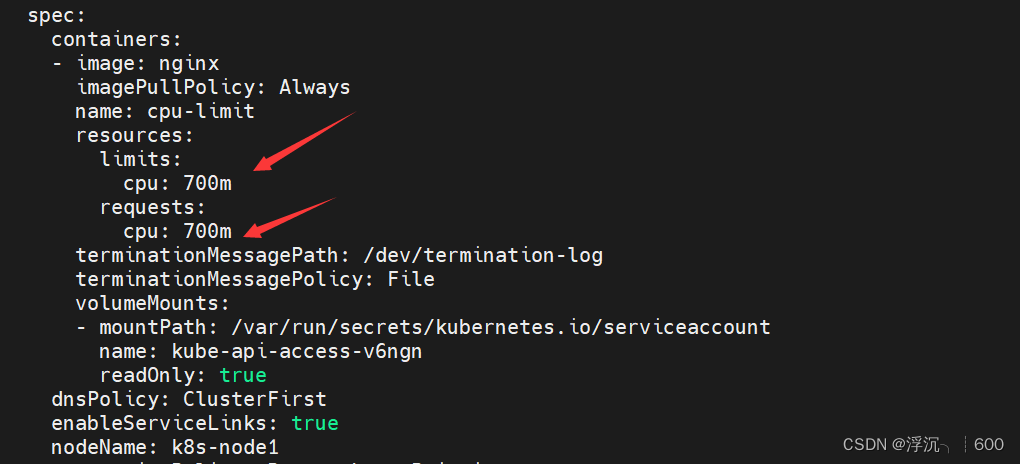

资源请求和上限值一致,虽然实际可能占用不到请求的那么多资源,但是会影响其他资源的创建,空闲的内存即使够创建一个新的容器,也可能导致无法创建,因为系统认为是不安全的,为了验证这一点,我们接着创建一个yaml
#该yaml文件中创建了一个deployment,其中期望副本数3个,每一个副本中的container设置资源上限都是:0.5个cpu和100M内存
vim limit.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: cpu-limit
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: cpu-limit
image: nginx
resources:
limits:
cpu: "0.5"
memory: 100Mkubectl create -f limit.yaml
#我们发现po一直处于Pending状态
kubectl get po
#随便选择一个来查看详细问题
kubectl describe po cpu-limit-5bd5fc9f6d-bfwbn
#可以看到,调度器认为每一个节点都不可调度,提示cpu量不足,无法调度。这里就涉及到抢占的问题了
#在其他工作的节点上,我们可以来查看一下他的可使用内存量以及cpu量,发现远远够用,但是k8s系统认为不安全,就是不能完成调度。并且,pod一旦处于运行状态,里面的容器正常运作以后,不能通过修改配置文件减小资源请求量
free -h
htop查看pod调度详细信息,发现调度器无法进行调度,因为没有任何一个节点可以满足pod和容器的需求 

先前的资源实际并没有使用到限制值的全部资源,即使有剩余的空间,这些空间也是属于原先的pod和容器的,其他容器和pod无权使用,所以资源设置不合理会导致资源的浪费

















 1739
1739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









