






参考了代码随想录跟acwing的dfs部分。
对dfs,回溯问题的理解
1.本质上是穷举所有的方案数,只是dfs可以解决一些for循环不太好解决的问题,这类问题通常是组合,排列问题(求所有的可能),分割字符串问题,子集问题,棋盘问题等。其实也是三大类:指数型,组合型,排列型。
2.每一个dfs问题都对应这一颗n叉树,树的宽度是问题集合的size,树的深度是递归的深度。树的叶子节点就要有返回的限制条件了。for循环横向遍历,递归纵向遍历,回溯不断调整结果集。
3.只是提供了一种解决特定问题的方法,并不意味着这个方法就是高效的,本质还是穷举。改进的方法是需要发现一些肯定不可能的情况,然后跳过,俗称剪枝操作。
4.递归需要考虑的三个部分:
a.递归的参数:有些参数可以用全局变量代替。也可以写到递归函数里面。
b.递归的终点:边界条件的考虑
c. 递归的每层行为:for循环是树宽度的驱动力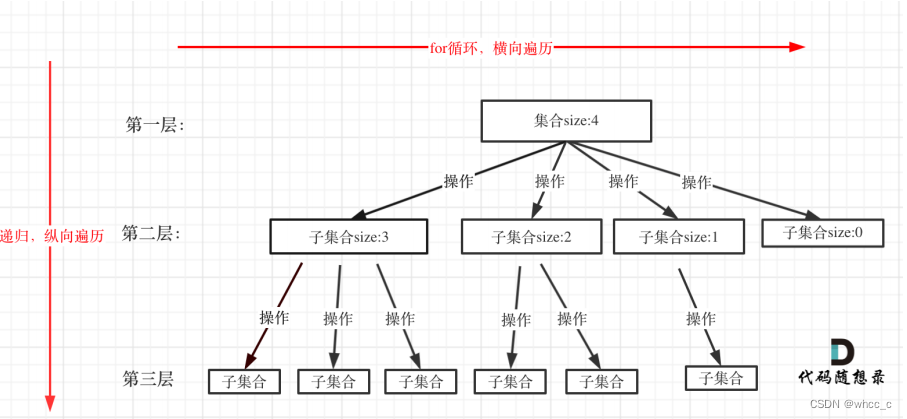

基本模板:
组合问题
组合
力扣77:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
对应的搜索树:
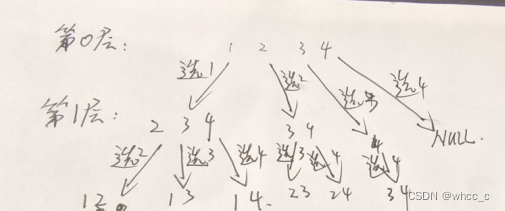
由此可以发现规律:每次选取一个数以后,后面选的数都需要比这个数要大。
1.递归的参数:给定的n,需要遍历的集合大小(树宽);给定的k,需要递归的深度;层数u,当前枚举到的数。
2.递归终止条件:层数(从0开始)>= 给定k的时候
3.每层的行为:记录下当前层枚举的数。
code:
class Solution {
public:
vector<vector<int>> ans; //存结果
vector<int> temp; //存过程
void dfs(int n,int k,int u,int now) //u是层数,now的当前的数
{
if(u>=k)
{
ans.push_back(temp);
return;
}
for(int i = now;i <= n ;i++) //i从当前的now开始增加
{
temp.push_back(i);
dfs(n,k,u+1,i+1);
temp.pop_back(); //恢复现场,要不然temp一直在增加了
}
}
vector<vector<int>> combine(int n, int k) {
dfs(n,k,0,1);
return ans;
}
};组合的剪枝
从上图中可以看出,到选到第四个数的时候第1层已经是空了,当n,k变化时,其实有很多这样的情况,也就是说i确定了起点,确定了已经枚举了的数量后,i的有效终点也是固定的。
举个例子:当n = 4,k = 3的时候,i从1开始的话 可以有123,134;从2开始,只有234,从3开始就已经不可能了。这是我们剪枝的思路。
当前已经枚举到的集合大小是 temp.size(),还需要枚举k - temp.size(),对应的下标是 n - (k - temp.size()) +1。所有最后的代码是
for(int i = now;i <= n - (k - temp.size())+1;i++)
{
temp.push_back(i);
dfs(n,k,u+1,i+1);
temp.pop_back();
}
}组合总和Ⅲ
力扣216:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
本题跟组合那题很相似,但是不同是可用数字已经给出了:1-9,这就给了我们树的宽度,每次循环都是从1到9
1. 递归的参数:k:给定的深度。n:给定的目标值。u:当前的递归的层数(我习惯从0开始)。now:当前到哪个数了。sum:当前枚举的集合的和是多少。
2.递归终止条件:当前的递归深度已经超过或者等于了k。 u>=k。
3.每层的行为:层数+1,sum加上当前枚举的now,now+1进入下一层。
4. 剪枝:①:如果当前sum已经大于n了,说明可用不用继续递归了。
②:第二个就是之前的剪枝
code:注意这里的sum。有的版本是sum+i;dfs(~sum~);sum-i 。 这里我把sum+i放在dfs参数里面,就不要回溯再-了,回溯完回到之前层其实已经回到了没加之前的sum了
class Solution {
public:
vector<vector<int>> ans;
vector<int> temp;
void dfs(int k,int n,int u,int now,int sum)
{
if(sum>n) return ;
if(u>=k)
{
if(sum == n)
ans.push_back(temp);
return;
}
for(int i = now;i<=9 - (k - temp.size())+1;i++)
{
temp.push_back(i);
dfs(k,n,u+1,i+1,sum+i); // 这里sum+i在dfs参数里面,就不要回溯再-了,回溯完回到之前层其实已经回到了没加之前的sum了
temp.pop_back();
}
}
vector<vector<int>> combinationSum3(int k, int n) {
dfs(k,n,0,1,0);
return ans;
}
};总结一下:组合型的问题套路:
1. 组合看成集合。集合是无序的。所以234跟432是一样的。但是我们按照字典序从小到大来排序比较方便。
2.如何保证下一个数比前面的要大? dfs中用参数记录一下当前用到的数即可。
3.剪枝操作:主要在i的枚举上。i的有效值是 n - (k-temp.size()) +1。其中n为给定集合的大小(宽度),k是需要枚举的个数(深度),temp.size()为当前已经枚举的数的大小。+1主要是凑下标的。
电话号码的字⺟组合
力扣17:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
digits中的每个数字都代表了一个集合,看排列方式不是排列型的。
难点在于如何表示对应关系?这里我用map去表示。
预处理:
map<char,string> mp = {
{'2', "abc"}, {'3', "def"}, {'4', "ghi"}, {'5', "jkl"}, {'6', "mno"},
{'7', "pqrs"}, {'8', "tuv"}, {'9', "wxyz"}
}; 递归树: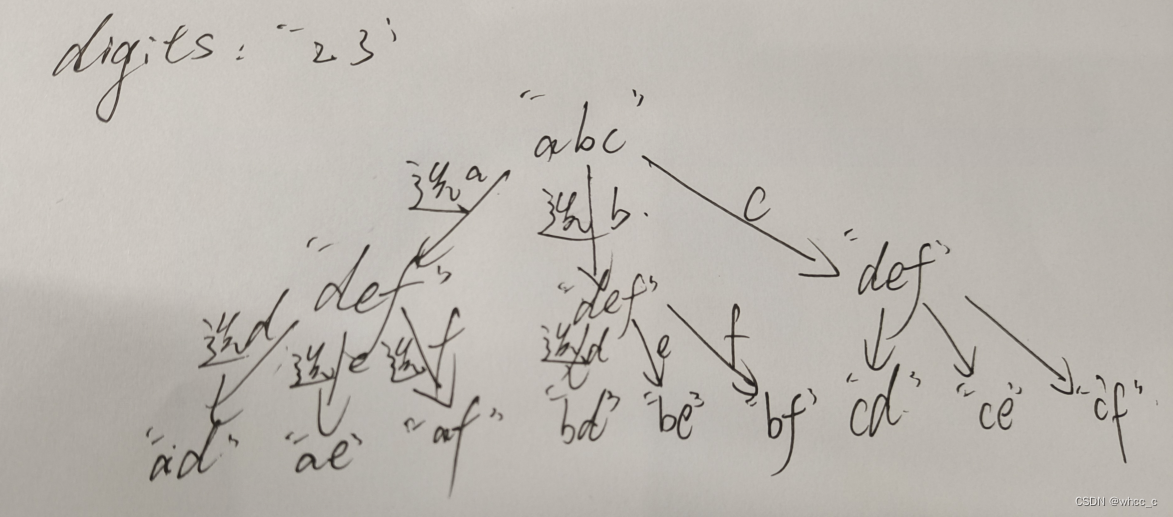
1.递归的参数:u:当前的层数。digits:给定的字符串
2. 递归的终止条件: 当前的u>= digits.size()
3.每一层的行为:将该层的digits上的数字对应的字母集合中第i位加入到集合中,加入下一层。
code:
digits: 给定的一个string
u:枚举digits的每一位
mp[digits[u]]: 如果digits的第i位是'2',那么mp['2']对应的集合就是"abc"。mp['2'].size()就是3
mp[digits[u]][i]: i = 1对应的就是'a',i = 2对应的就是'b',i = 3对应的就是'c'
class Solution {
public:
map<char,string> mp = {
{'2', "abc"}, {'3', "def"}, {'4', "ghi"}, {'5', "jkl"}, {'6', "mno"},
{'7', "pqrs"}, {'8', "tuv"}, {'9', "wxyz"}
};
vector<string> ans;
string current;
void dfs(int u,string &digits)
{
if(u>=digits.size())
{
ans.push_back(current);
return ;
}
for(int i = 0;i<mp[digits[u]].size();i++)
{
current+=(mp[digits[u]][i]);
dfs(u+1 ,digits);
current.pop_back();
}
}
vector<string> letterCombinations(string digits) {
if(digits.size() == 0) return ans;
dfs(0,digits);
return ans;
}
};为什么不用记录当前的数了?因为这里的digits中每个数字都代表了一个集合,跟之前的组合型不一样了。
组合总和
力扣39:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
先根据题意模拟一下: 可用直接看出递归的终止条件了:①sum=tar ② sum>tar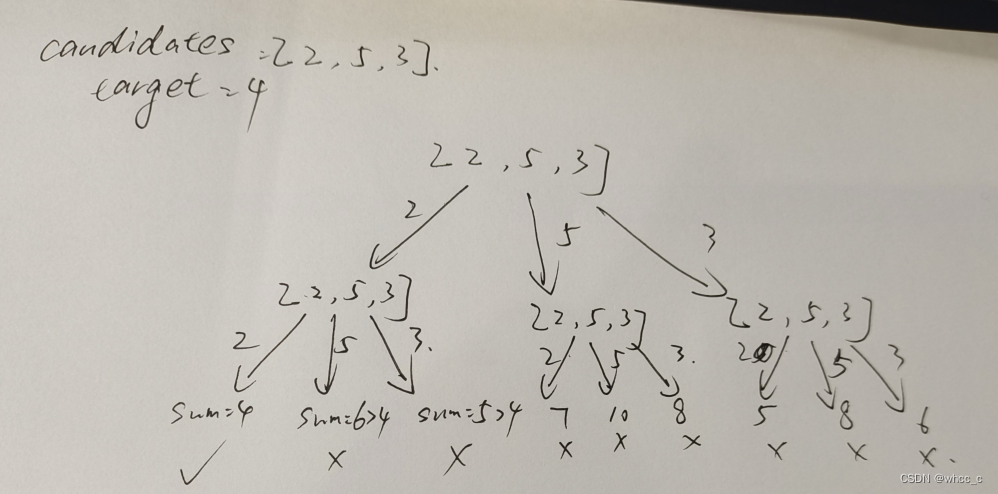
1.递归的参数:can:给定的集合;tar给定的目标和;sum:当前枚举的和;idx:当前枚举的下标
2.递归的终止条件:①sum=tar ② sum>tar
3.每一层的行为:sum加上当前的can[idx]的值。
code: 注意这里dfs的时候不要i+1了,要不然会有很多重复的集合。本题的意思是集合中的元素可用多次使用的,这次用了idx,下次还可以用idx。所以i还是从idx开始,dfs中的参数还是i不是i+1了
class Solution {
public:
vector<int> cur;
vector<vector<int>> ans;
void dfs(vector<int>& can, int tar,int sum,int idx)
{
if(sum > tar) return ;
if(sum == tar)
{
ans.push_back(cur);
return;
}
for(int i = idx;i<can.size();i++)
{
cur.push_back(can[i]);
dfs(can,tar,sum+can[i],i);
cur.pop_back();
}
}
vector<vector<int>> combinationSum(vector<int>& can, int tar) {
dfs(can,tar,0,0);
return ans;
}
};组合总和Ⅱ
力扣40:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
本题的难点在于:如何去重。这是排列组合问题的一大难点。
两个新概念: 树层去重与树根去重
1.递归的参数:给定的vector:candidates;目标值:tar;当前和:sum;当前枚举到的下标:idx;标记数组:used
2.递归的终点:两种情况: ①sum>tar;②sum==tar,这时候要加入答案中
3.每层的行为:首先要判断当前数是否与上一次的数相同。
这里的相同分为两种情况(这里假设n[i] == n[i-1]):第一种相同是因为递归导致的:树的一个根上的节点与它上一个节点的值相同,这是允许的。这种情况下:一定是先到了i-1的节点,才会到第i个节点。
第二种情况:是因为for循环导致的。也就是说已经枚举了以i-1为开头的节点的集合了,现在已经准备开始递归枚举第i个数字开头的节点的集合了。这种情况下第i个数字前的数字是不应该在当前的枚举集合中的。(used[i-1] = 0)
我们可用一个used去记录每次枚举的路径的点是否被选取到:针对树根的递归枚举:used[i]=1的时候,used[i-1]一定也被枚举到。针对树层的for循环枚举:used[i]=1的时候,used[i-1]不一定被枚举到。(n[i-1]==n[i]的话是不能去枚举的(used[i-1]=0),但是对于n[i-1]!=n[i]的情况是可用被枚举的used[i-1] = 1)
搜索树: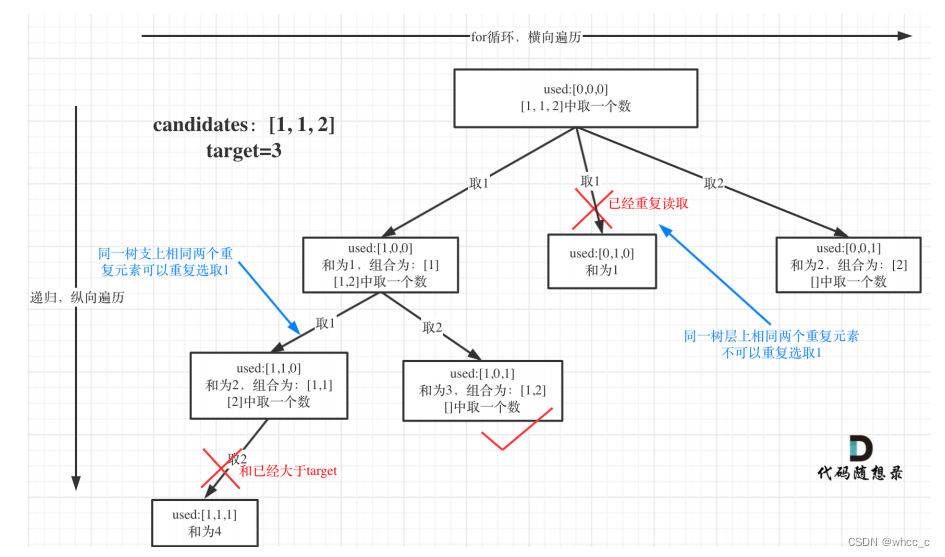
去重的本质是:如何跳过一段连续相同的数!
code: 排序的目的是方便我们去去重
class Solution {
public:
vector<int> temp;
vector<vector<int>> ans;
void dfs(vector<int>& candidates,int tar,int sum,int idx,vector<bool> used)
{
if(sum>tar) return;
if(sum == tar)
{
ans .push_back(temp);
return;
}
for(int i = idx;i<candidates.size();i++)
{
if(i>=1&&candidates[i]==candidates[i-1]&&used[i-1]==0)
continue;
used[i] = 1;
temp.push_back(candidates[i]);
dfs(candidates,tar,sum+candidates[i],i+1,used);
used[i] = 0;
temp.pop_back();
}
}
vector<vector<int>> combinationSum2(vector<int>& candidates, int tar) {
vector<bool> used(candidates.size(),0);
sort(candidates.begin(),candidates.end());
dfs(candidates,tar,0,0,used);
return ans;
}
};递归实现组合型枚举 II
acwing1573 1573. 递归实现组合型枚举 II - AcWing题库
与上一题一样,用于练手即可。
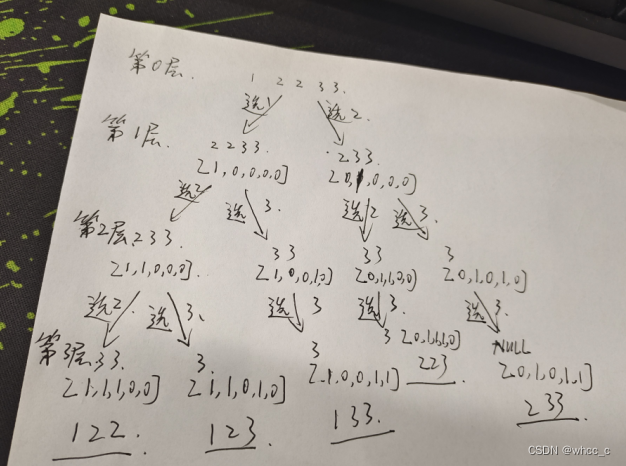
code:
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
vector<vector<int>> ans;
vector<int> temp;
const int N = 50;
bool used[N];
int n,k; // n表示总数,k表示集合要求的大小
int a[N];
void dfs(int u,int idx) // u表示层数,idx表示当前的值
{
if(u>=k)
{
ans.push_back(temp);
return;
}
for(int i = idx;i<n;i++)
{
if(i>0&&a[i-1] == a[i]&&used[i-1]==0) continue;
used[i] = 1;
temp.push_back(a[i]);
dfs(u+1,i+1);
used[i] = 0;
temp.pop_back();
}
}
int main()
{
cin>>n>>k;
for(int i = 0;i<n;i++) cin>>a[i];
sort(a,a+n);
dfs(0,0);
for(int i = 0;i<ans.size();i++)
{
for(int j = 0;j<ans[i].size();j++)
cout<<ans[i][j]<<" ";
cout<<endl;
}
return 0;
}字符串切割问题
分割回文串
力扣131 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
切割子串问题我感觉有点抽象,但是其实跟组合问题差不多。举个例子:
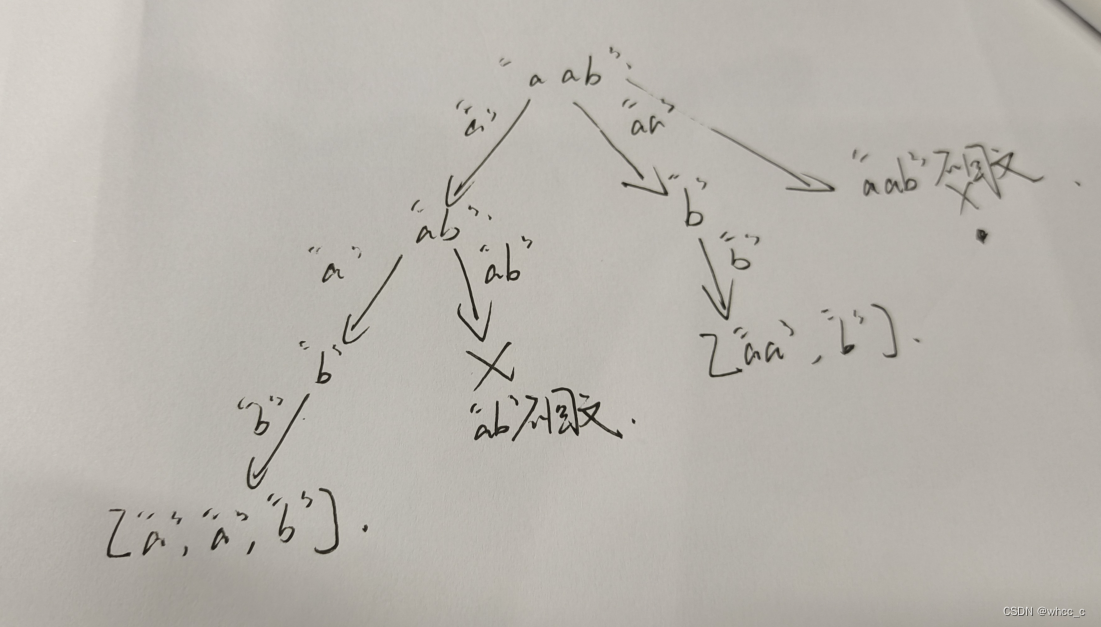
code:
回文的判断:直接用双指针扫一下就行,其他方法也可以
class Solution {
public:
vector<string> temp;
vector<vector<string>> ans;
bool check(string str)
{
int n = str.size();
int l = 0,r = n-1;
while(l<r)
{
if(str[l]==str[r])
l++,r--;
else return 0;
}
return 1;
}
void dfs(const string &s,int idx)
{
if(idx >= s.size())
{
ans.push_back(temp);
return;
}
for(int i = idx;i<s.size();i++)
{
string str = s.substr(idx,i-idx+1);
if(check(str)) temp.push_back(str);
else continue;
dfs(s,i+1);
temp.pop_back();
}
}
vector<vector<string>> partition(string s) {
dfs(s,0);
return ans;
}
};复原ip地址
力扣93:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
这个题目比较有意思,它加入答案集合不是用vector而是用string。所以我们在原字符串上改动即可。
模拟部分情况: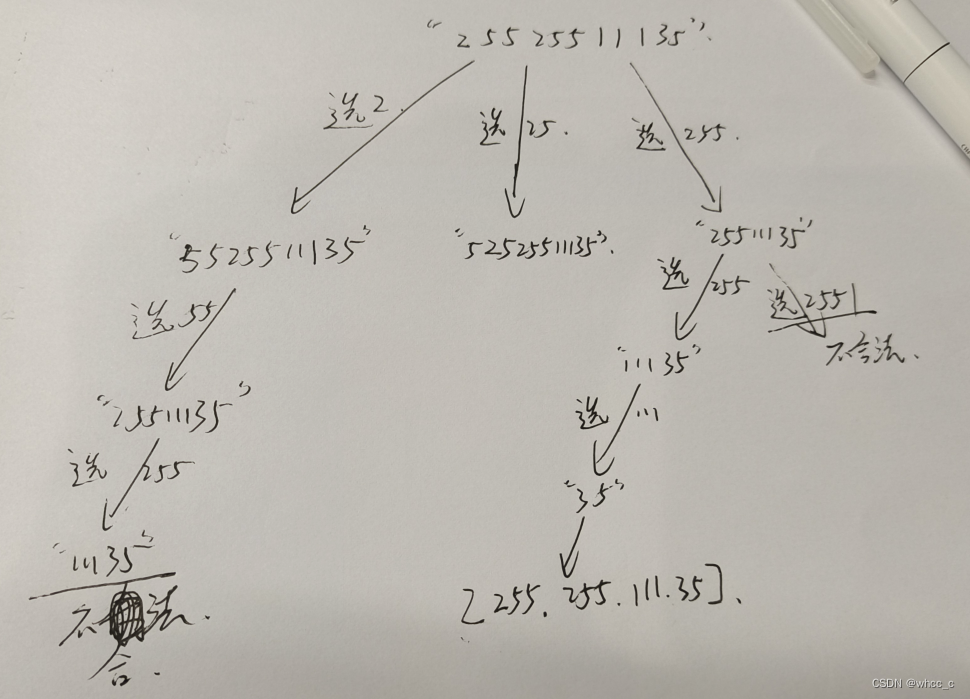
与上一题一样,就是找不同集合,判断当前枚举的集合是否满足条件。
1. 递归的参数:给定的字符串s;当前添加的逗号的个数:point;当前枚举到第几位:idx
2.递归的终止条件:当point = 3时,直接判断最后一段是否满足条件即可。
3.每节点的行为:判断以当前i开头的区间是否满足条件,如果满足条件,需要添加一个‘ . ’然后递归到下一层。如果发现当前区间不满足条件,break或者continue掉即可。
code:
class Solution {
public:
vector<string> ans;
bool check(string str)
{
for(auto i:str)
if(i<'0'||i>'9')
return 0;
unsigned long long x = 0;
for(auto i:str)
x = x*10 +i-'0';
if(x<0||x>255) return 0;
if(str.size()>1&&str[0] == '0') return 0;
return 1;
}
void dfs(string&s,int point,int idx)
{
if(point == 3)
{
string str = s.substr(idx,s.size()-1-idx+1);
if(check(str)&&str!="") ans.push_back(s);
return ;
}
for(int i = idx;i<s.size();i++)
{
string str = s.substr(idx,i-idx+1);
if(check(str))
{
s.insert(s.begin()+1+i,'.');
dfs(s,point+1,i+2);
s.erase(s.begin()+i+1);
}else continue;
}
}
vector<string> restoreIpAddresses(string s) {
dfs(s,0,0);
return ans ;
}
};子集问题
子集
力扣78:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
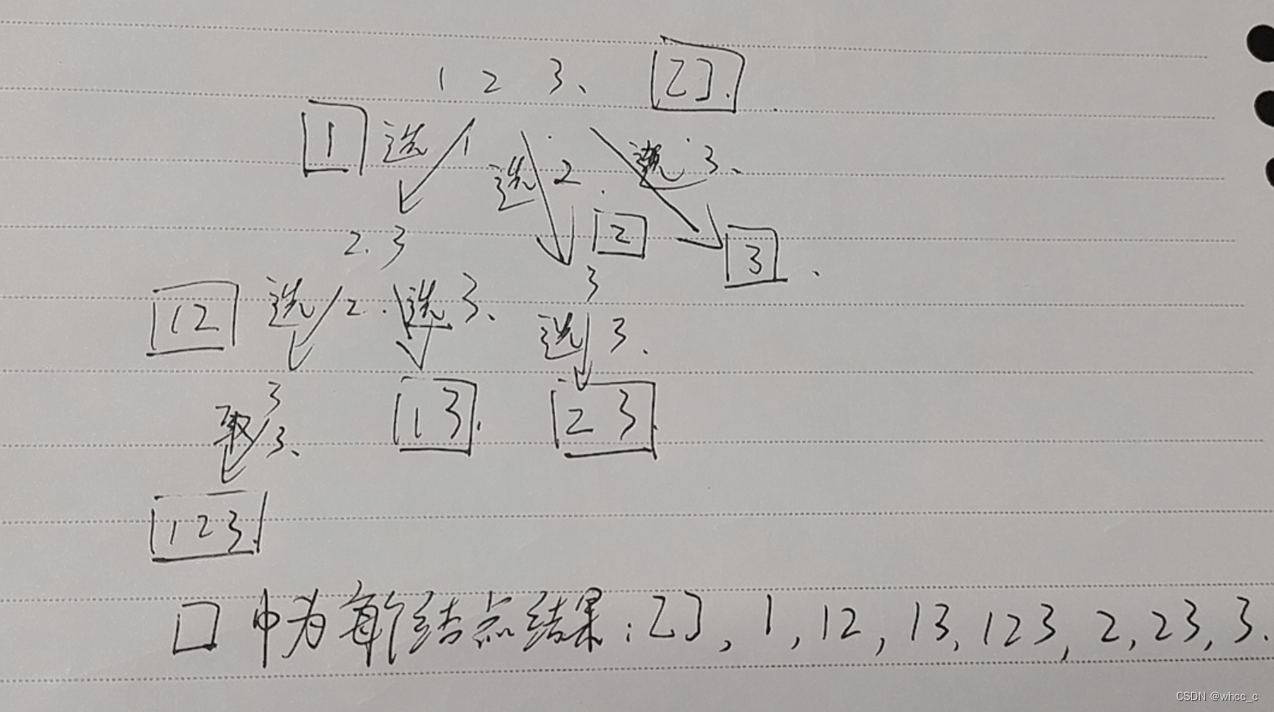
两种思路:① 分析每个元素:每个元素可以放入集合,也可以不放入集合。② 看成是组合问题,只不过之前的组合问题收集的是叶子节点,这里收集的是每个节点的答案。
思路一:

① 递归的参数:nums:给定的数组;u:层数;st:状态数组,表示当前的数 选或者不选
② 递归的终点:层数大于等于nums.size,如果是遍历一下st数组,被选上的数加入集合
③ 每节点的行为:当前的数选或者不选两种状态用st标记下,分别进入递归。
code:
class Solution {
public:
vector<vector<int>> ans;
vector<int> t;
void dfs(vector<int>& nums,int u,vector<bool>& st)
{
if(u>=nums.size())
{
for(int i = 0;i<nums.size();i++)
{
if(st[i])
t.push_back(nums[i]);
}
ans.push_back(t);
t.clear();
return;
}
st[u] = 0;
dfs(nums,u+1,st);
st[u] = 1;
dfs(nums,u+1,st);
}
vector<vector<int>> subsets(vector<int>& nums) {
vector<bool> used(nums.size(),0);
dfs(nums,0,used);
return ans;
}
};
class Solution {
public:
vector<vector<int>> ans;
vector<int> t;
void dfs(vector<int>& nums,int idx)
{
ans.push_back(t);
if(idx>=nums.size()) return ;
for(int i = idx;i<nums.size();i++)
{
t.push_back(nums[i]);
dfs(nums,i+1);
t.pop_back();
}
}
vector<vector<int>> subsets(vector<int>& nums) {
dfs(nums,0);
return ans;
}
};子集Ⅱ
力扣90:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
与子集一样,就是要去重,去重方法还是可以用used的。
code: 记得排序
class Solution {
public:
vector<vector<int>> ans;
vector<int> t;
void dfs(vector<int>& nums,int idx,vector<bool> used)
{
ans.push_back(t);
if(idx>=nums.size()) return ;
for(int i = idx;i<nums.size();i++)
{
if(i>0&&nums[i-1] == nums[i]&&used[i-1] == 0) continue;
t.push_back(nums[i]);
used[i] = 1;
dfs(nums,i+1,used);
t.pop_back();
used[i] = 0;
}
}
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(),nums.end());
vector<bool> used(nums.size(),0);
dfs(nums,0,used);
return ans;
}
};排列问题
全排列
力扣 46:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
全排列的问题要注意:枚举后面数也会用到前面的数,所以for的i应该用0开始。

① 递归的参数:nums表示原始数组;u表示当前枚举到哪个数了
② 递归的终点: u>=nums.size()
③ 每个节点的行为:因为每个数只有用一次,所以用一个数组判重就可以了,没有用过就加入vector,用过了就跳到下一个。
code:
class Solution {
public:
vector<vector<int>> ans;
vector<int> t;
bool st[1000];
void dfs(vector<int>& nums,int u)
{
if(u>=nums.size())
{
ans.push_back(t);
return ;
}
for(int i = 0;i<nums.size();i++)
{
if(!st[i])
{
st[i] = 1;
t.push_back(nums[i]);
dfs(nums,u+1);
st[i] = 0;
t.pop_back();
}
}
}
vector<vector<int>> permute(vector<int>& nums) {
dfs(nums,0);
return ans;
}
};全排列Ⅱ
思路一样,加一个去重数组used即可
code: 记得sort
class Solution {
public:
vector<vector<int>> ans;
vector<int> t;
bool st[100];
void dfs(vector<int>& nums,int u,vector<bool>&used)
{
if(t.size() == nums.size())
{
ans.push_back(t);
return ;
}
for(int i = 0;i<nums.size();i++)
{
if(i>0&&nums[i-1] == nums[i]&&used[i-1] == 0) continue;
if(!st[i])
{
st[i] = 1;
used[i] = 1;
t.push_back(nums[i]);
dfs(nums,u+1,used);
t.pop_back();
st[i] = 0;
used[i] = 0;
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(),nums.end());
vector<bool>used(nums.size(),0);
dfs(nums,0,used);
return ans;
}
};补充:
如果原数组不让sort,那该如何去重?
在每个for循环上面加上一个unordered_set去重即可。这样可以控制所有同一父节点下的子节点没有重复。
每个数只进不出。
因为是局部变量,所有每层的set都会被清空,来保证层与层之间的去重不受影响。
时空效率都不如used数组。
子集问题还是要排序的,具体可以自己模拟下
全排列Ⅱ用set做:
class Solution {
public:
vector<vector<int>> ans;
vector<int> t;
//bool st[100];
void dfs(vector<int>& nums,int u,vector<bool>&used)
{
if(t.size() == nums.size())
{
ans.push_back(t);
return ;
}
unordered_set<int> us; // 位置一定是这边
for(int i = 0;i<nums.size();i++)
{
if(!us.count(nums[i]))
{
if(!st[i])
{
us.insert(nums[i]);
st[i] = 1;
//used[i] = 1;
t.push_back(nums[i]);
dfs(nums,u+1,used);
t.pop_back();
st[i] = 0;
//used[i] = 0;
}
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
//sort(nums.begin(),nums.end());
//vector<bool>used(nums.size(),0);
dfs(nums,0,used);
return ans;
}
};














 399
399











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









