






跟着carl哥刷完了二叉树的力扣题单,收获满满。但是就像carl哥说的那样,刷题不是目的,得总结出自己写题的一套方法论,于是趁热打铁。代码很多是自己的想法,也许是灵感迸发,也许是题解启迪,但希望能悟出自己的东西。
树中的基本概念:
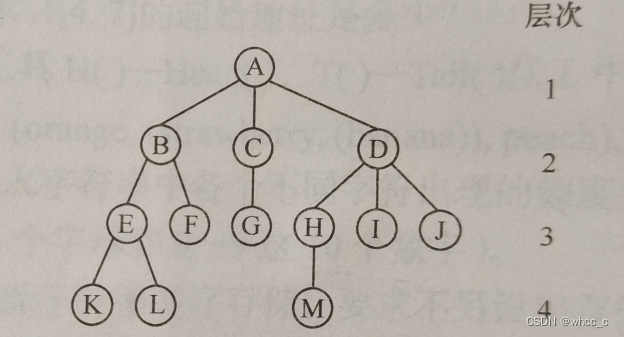
结点: 树中的一个独立单元。
结点的度:结点拥有的子树数量。
树的度:各结点中度的最大值。
叶子:度为0的结点,也叫终端结点。K,L,F,G等
非终端结点:度不为0的结点。
双亲与孩子:结点子树的根称为该结点的孩子,该结点称为孩子的双亲。B的双亲是A,B的孩子有E,F。
兄弟:同一个双亲的孩子之间互称兄弟。H,I,J互称兄弟。
祖先:从根到该结点所经历分支上的所有结点。M的祖先为H,D,A。
子孙:以某结点为根的子树中的任一结点都称为该结点的子孙。B的子孙有:E,K,L,F。
层次:从根开始定义,根为第一层,根的孩子为第二层,以此类推。
堂兄弟:同一层的结点互为堂兄弟。
树的深度:树中结点的最大层次称为树的深度或者高度。
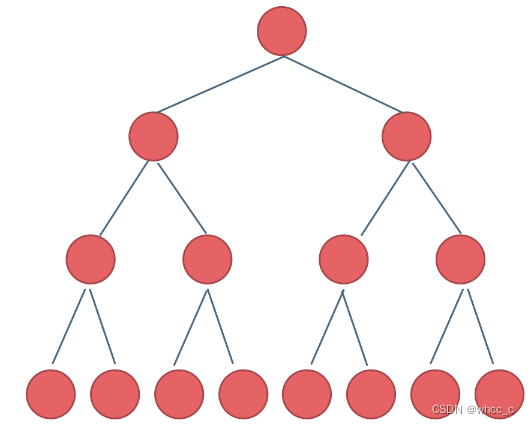
满二叉树:如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。若满二叉树深度为k,就有2^k-1个结点。
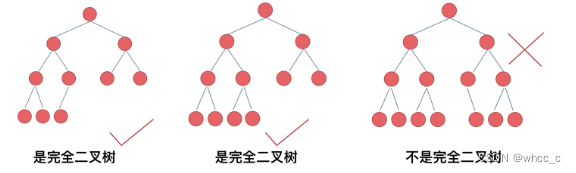
完全二叉树:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层(h从1开始),则该层包含 1~ 2^(h-1) 个节点。
二叉搜索树:
前面介绍的树,都没有数值的,而二叉搜索树是有数值的了,二叉搜索树是一个有序树。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
平衡二叉搜索树:平衡二叉搜索树:又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。

存储方式:链表和数组。链表是通法,缺点是空间利用率低。数组通常只用于存储满二叉树。
二叉树的遍历方式:通常是DFS根BFS。 以下的dfs只写递归法实现。我感觉把dfs掌握就已经很不错了。而且dfs给人一种神秘精致的美感......
- 深度优先遍历
- 前序遍历
- 中序遍历
- 后序遍历
- 广度优先遍历
- 层次遍历
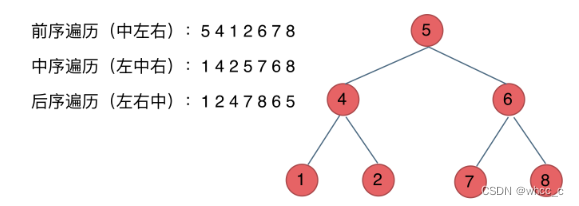
二叉树的定义:力扣上面的二叉树定义一般是这样:其中TreeNode(int x)只需要填写参数x就可以构建一个val为x,左右孩子为空的二叉树结点。如果不这样写的话,单独写TreeNode *root,我们还需要去给val,left,right的值,要不然就是一个野指针了。
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};二叉树解题思路:
- 如果基于递归去结题,不用纠结于每一步会怎么样,多想几步脑袋可能就乱了。只要代码的边界条件和非边界条件的逻辑写对了,其他的事情交给数学归纳法就好了。也就是说,写对了这两个逻辑,你的代码自动就是正确的了,没必要想递归是怎么一层一层走的。
- 节选灵神的话,给迷茫时的自己一点提醒。

二叉树的遍历:
递归三部曲:
- 确定递归函数的参数和返回值
- 返回值一般有void与具体返回值。void一般用于全局搜索,有具体返回值的话就很有可能要重复调用自己了。
- 确定终止条件
- 终止条件一般是判断树是否为空了。一般放在最上面的位置。
- 确定单层递归的逻辑
- 这里注意 可以重复调用这个函数,这就是为什么首先要确定参数与返回值!
三种基础遍历:
三种遍历方式其实就是访问根节点的时机不同。在左右之前访问就是前序遍历,先左就是中序遍历,左右之后就是后序遍历。
二叉树的前序遍历
class Solution {
public:
vector<int> ans;
void dfs(TreeNode * root)
{
if(!root) return ;
ans.push_back(root->val);
dfs(root->left);
dfs(root->right);
}
vector<int> preorderTraversal(TreeNode* root) {
dfs(root);
return ans;
}
};二叉树的后序遍历
class Solution {
public:
vector<int> ans;
void dfs(TreeNode* root)
{
if(!root) return ;
dfs(root->left);
dfs(root->right);
ans.push_back(root->val);
}
vector<int> postorderTraversal(TreeNode* root) {
dfs(root);
return ans;
}
};二叉树的中序遍历
class Solution {
public:
vector<int> vec;
void dfs(TreeNode* root)
{
if(root)
{
dfs(root->left);
vec.push_back(root->val);
dfs(root->right);
}
}
vector<int> inorderTraversal(TreeNode* root) {
dfs(root);
return vec;
}
};层次遍历:
二叉树的层次遍历
BFS是有模板的,所以如果用到层次遍历的话题目就比较简单了,直接套模板即可。
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> ans;
vector<int> vec;
queue<TreeNode*> q;
if(!root) return ans;
q.push(root); //先加入根节点
while(q.size()) // 如果队列不空的话
{
int sum = q.size(); //这里需要记录上一个结点引入的新节点个数
********* 每一层的具体逻辑 *********
vec.clear();
for(int i = 0;i<sum;i++)
{
auto t = q.front(); // 取结点
q.pop(); // 取完就可以删了
vec.push_back(t->val); //对该结点的具体操作
// 加入左右结点
if(t->left) q.push(t->left);
if(t->right) q.push(t->right);
}
ans.push_back(vec);
}
return ans;
}
};二叉树的性质:
二叉树的最大深度
- 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数或者节点数(取决于深度从0开始还是从1开始)
- 二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数或者节点数(取决于高度从0开始还是从1开始)
而根节点的高度就是二叉树的最大深度,所以本题中我们通过后序求的根节点高度来求的二叉树最大深度。
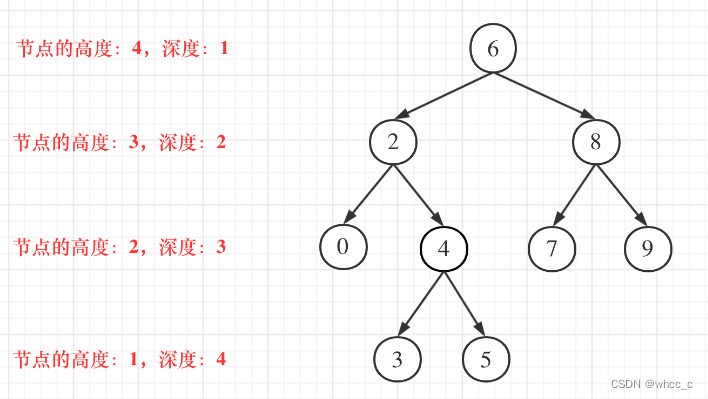
用后续遍历,先左右,最后在中 +1
① 确定函数的返回值和参数:要求的是最大深度,所以返回值是一个int类型的变量。参数就是一个结点。
② 终止条件:遇到空结点就要返回了。
③ 只考虑最小的子问题:一颗二叉树。它的最大深度就是左右子树中的最大高度加上根节点的高度1,所以就是max(left,right)+1就行了。
class Solution {
public:
int dfs(TreeNode * root)
{
if(!root) return 0;
int mx_l = dfs(root->left);
int mx_r = dfs(root->right);
return max(mx_l,mx_r)+1;
}
int maxDepth(TreeNode* root) {
return dfs(root);
}
};其实精简的写法是: 只是这样看的比较看不懂。但是后面只要是root->left跟root->right,基本上就是递归到左右子树了。
class Solution {
public:
int dfs(TreeNode * root)
{
if(!root) return 0;
return max(root->left,root->right)+1;
}
int maxDepth(TreeNode* root) {
return dfs(root);
}
};二叉树的最小深度
① 返回值是int,传入结点即可。
② 遇到空就返回了
③ 当左右子树都不为空的时候,答案取min+1,如果其中有一颗子树为0,那另一边一定是最小深度(因为深度最小为1不能为0 )
class Solution {
public:
int dfs(TreeNode* root)
{
if(!root) return 0;
int mn_l = dfs(root->left);
int mn_r = dfs(root->right);
if(mn_l!=0 && mn_r!=0) return min(mn_l,mn_r)+1;
else return max(mn_l,mn_r)+1;
}
int minDepth(TreeNode* root) {
return dfs(root);
}
};相同的树
后序遍历。(不是说p->val == q->val放在前面就是前序遍历的)
① 返回值就是 bool,传入值是左右两棵子树
② 如果两棵树中有一颗为空了,只有另外一颗也为空才可以返回1,其他情况都返回0
③ 先判断当前两棵树的val,在递归判断左子树跟右子树。
class Solution {
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
if(!p || !q) return p == q;
return p->val == q->val && isSameTree(p->left,q->left)&&isSameTree(p->right,q->right);
}
};对称二叉树
前序后序都可以。
其实跟上一题判断二叉树相等是一样的。
① 这里可以发现,一棵树的根节点是不用去比较的,只需要看树的左右结点的关系就行。返回值是bool,传入值是左子树根右子树
② 如果我们在比较左右子树的时候,如果遇到有空的情况,如果两棵树都为空,这种情况就返回1,其余的情况肯定都是返回0了。
③如果两棵树都存在,先判断。两棵树的val是否相等,然后判断左子树的右孩子跟右子树的左孩子是否满足关系,在判断右子树的左孩子跟左子树的右孩子是否满足。
class Solution {
public:
bool dfs(TreeNode *p,TreeNode *q)
{
if(!p||!q) return p == q;
return p->val == q->val&&dfs(p->left,q->right) && dfs(p->right,q->left);
}
bool isSymmetric(TreeNode* root) {
return dfs(root->left,root->right);
}
};完全二叉树的结点个数
后序遍历:左右遍历完+1(本身)
① 返回int,表示以该根节点的树的结点个数。传入根节点就行。
② 当遇到空结点的时候就返回。空结点的结点个数为0,返回0。
③ 考虑最小的一棵树。它的结点个数就是 左子树的结点个数+右子树的结点个数+1(本身)。
class Solution {
public:
int countNodes(TreeNode* root) {
if(!root) return 0;
return countNodes(root->left)+countNodes(root->right)+1;
}
};平衡二叉树
其实也算是求高度。应该是用后序遍历去解决问题。
①参数:当前传入节点。 返回值:以当前传入节点为根节点的树的高度。如果发现当前树的左右子树已经不满足平衡条件了,我们直接返回-1就行了。
②递归的过程中依然是遇到空节点了为终止,返回0,表示当前节点为根节点的树高度为0
③ 如何判断以当前传入节点为根节点的二叉树是否是平衡二叉树呢?当然是其左子树高度和其右子树高度的差值。分别求出其左右子树的高度,然后如果差值小于等于1,则返回当前二叉树的高度,否则返回-1,表示已经不是二叉平衡树了。
class Solution {
public:
int dfs(TreeNode * root)
{
if(!root) return 0;
int l_h = dfs(root->left);
if(l_h == -1) return -1;
int r_h = dfs(root->right);
if(r_h == -1 ) return -1;
if(abs(l_h-r_h)>1) return -1;
return max(r_h,l_h)+1;
}
bool isBalanced(TreeNode* root) {
return dfs(root) != -1;
}
};这是一道回溯题目。需要遍历树的每一条根。采用中序遍历即可。
① 既然不是一个数的局部属性,所以肯定是要用void去遍历整棵树的了。传入参数就是根节点。
② 遇到叶子结点就收集答案回溯了。
③ 有点像子集型回溯,每一步递归都先收集节点值,然后递归左右结点。
dfs里面str+"->"可以自动回溯,就不需要写 str +="->";dfs(root,str);str.erase(str.size()-3,2);了
class Solution {
public:
vector<string> ans;
void dfs(TreeNode * root,string str)
{
str+=to_string(root->val);
if(!root->left&&!root->right)
{
ans.push_back(str);
return ;
}
if(root->left) dfs(root->left,str+"->");
if(root->right) dfs(root->right,str+"->");
}
vector<string> binaryTreePaths(TreeNode* root) {
string str;
dfs(root,str);
return ans;
}
};左叶子之和
后序遍历。先深入叶子结点再回代出值。
关键:判断当前节点是不是左叶子是无法判断的,必须要通过节点的父节点来判断其左孩子是不是左叶子。
① 判断一个树的左叶子节点之和,那么一定要传入树的根节点,递归函数的返回值为数值之和,所以为int使用题目中给出的函数就可以了。
②如果遍历到空节点,那么左叶子值一定是0
③当遇到左叶子节点的时候,记录数值,然后通过递归求取左子树左叶子之和,和 右子树左叶子之和,相加便是整个树的左叶子之和。
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
int sum = 0;
if(!root) return sum;
if(root->left&&!root->left->left && !root->left->right) //存在左结点,且该结点是叶子结点
sum += root->left->val;
return sum +sumOfLeftLeaves(root->left)+sumOfLeftLeaves(root->right);
}
};找树左下角的值
这个题目用递归去思考会发现最后一个树的情况有很多情况:首先得是最后一层,然后得是最左边。不一定是左子树,也可能是右子树是最左边。所以用bfs很容易解决。
层次遍历也需要灵活应用的。这里让t指向最后一个结点就行。所以先右边再左边。这样可以保证t指向的是层次遍历的最后一个元素。
class Solution {
public:
int findBottomLeftValue(TreeNode* root) {
queue<TreeNode*> q;
TreeNode * t;
q.push(root);
while(q.size())
{
t = q.front();
q.pop();
if(t->right) q.push(t->right);
if(t->left) q.push(t->left);
}
return t->val;
}
};路径总和
直观想法一直收集结点的值,然后到叶子结点判断就可以了。可以用void全局搜,也可以就返回bool,因为子树满足性质,整棵树也满足。
① 返回值就可以是bool,传入参数有:根节点,目前值sum,目标值tar
② 叶子节点比对答案,反正0或1,如果当前root不存在,也返回0
③ 每到一个结点就收集当前值即可。
if(!root) return 0 ;不可以不要。一些结点只有左孩子或者只有右孩子的话,当进入另一个没有孩子的结点就会发生错误。
class Solution {
public:
bool dfs(TreeNode * root,int sum,int tar)
{
if(!root) return 0 ;
sum+=root->val;
if(!root->left&&!root->right)
if(sum == tar)
return 1 ;
return dfs(root->left,sum,tar) || dfs(root->right,sum,tar);
}
bool hasPathSum(TreeNode* root, int tar) {
if(!root) return 0;
return dfs(root,0,tar);
}
};二叉树的修改与构造:
从中序与后序遍历序列构造二叉树
给定了中序,再给定前序或者后序,都可以重构建一颗二叉树。
原理是:前序跟后序可以很快速找到根节点的值,通过这个值就可以再中序确定左右子树的区间。然后一直递归下去构建就可以了。
① 传入参数:中序数组与后序数组。
② 终止条件:后序数组为空了。(这样就找不到根节点的值了)这时候返回空即可。
③ 在中序遍历中找到左右子树所在的区间,再根据区间的大小在后序遍历中找到左右子树后序遍历的区间。当前的根节点左右子树分别等于同左或者同右的中序,后序数组的返回值即可。
注意:
vector的有参构造:第一个是begin(),第二个是end()。也就是说传入的范围是左开右闭的。end()是最后一个元素的下一个元素。
post区间的划分可以根据in区间的去做。因为划分完的左右区间大小是对应的。
class Solution {
public:
TreeNode* trav(vector<int>& inorder, vector<int>& postorder)
{
if(!postorder.size()) return NULL;
int rootVaule = postorder.back();
postorder.pop_back();
auto root = new TreeNode(rootVaule);
int idx ;
for(idx = 0;idx<inorder.size();idx++)
if(inorder[idx] == rootVaule)
break;
vector<int> leftinorder(inorder.begin(),inorder.begin()+idx);
vector<int> rightinorder(inorder.begin()+idx+1,inorder.end());
vector<int> leftpostinorder(postorder.begin(),postorder.begin()+leftinorder.size());
vector<int> rightpostinorder(postorder.begin()+leftinorder.size(),postorder.end());
root->left = trav(leftinorder,leftpostinorder);
root->right = trav(rightinorder,rightpostinorder);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(!inorder.size()) return NULL;
return trav(inorder,postorder);
}
};最大二叉树
思路跟上面一样。区间建树的套路感觉就是这样的。
感觉加上if(nums.size() == 1) return root;比较好,因为剩余一个元素的时候就直接返回就行了,相当于剪枝了。
class Solution {
public:
TreeNode* constructMaximumBinaryTree(vector<int>& nums) {
if(!nums.size()) return nullptr;
int idx = max_element(nums.begin(),nums.end()) - nums.begin();
TreeNode * root = new TreeNode(nums[idx]);
if(nums.size() == 1) return root;
vector<int> l_n(nums.begin(),nums.begin()+idx);
vector<int> r_n(nums.begin()+idx+1,nums.end());
root->left = constructMaximumBinaryTree(l_n);
root->right = constructMaximumBinaryTree(r_n);
return root;
}
};翻转二叉树
前序或者后续都可以,这里用前序。
① 翻转左右孩子是一个局部上的性质,但是通过递归可以扩展到整棵树。所以传入参数是一个根结点,返回的参数是根节点。
② 遇到空结点就可以返回了。
③ 我们不用考虑当前的根节点左右孩子是什么情况,是空还是有值直接交换就可以了。所以具体逻辑就是swap即可。
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(root == 0) return root;
swap(root->left,root->right);
invertTree(root->left);
invertTree(root->right);
return root;
}
};合并二叉树
① 返回的是一个根结点,传入左右子树根结点就行。
② 三种返回情况:如果左右都为空,直接返回空就行,如果左空右不空,返回root1就行,如果右空左不空,返回root2就行。
③ 如果都不空,直接加上val就行。然后递归建左子树跟右子树就行。
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(!root1 && !root2) return nullptr;
if(root1 && !root2) return root1;
if(!root1 && root2) return root2;
root1->val = root1->val + root2->val;
root1->left = mergeTrees(root1->left,root2->left);
root1->right = mergeTrees(root1->right,root2->right);
return root1;
}
};二叉搜索树的性质
二叉搜索树很重要的一条性质就是:中序遍历完之后得到的是一个有序的数组。
验证二叉搜索树
递归有两种遍历方式:
先序遍历: 这种就是看当前结点是否在左右结点的区间范围内,如果在,那就是二叉搜索树。根节点的左右结点范围是负无穷到正无穷。递归左孩子的时候就是将右边界换成当前值,递归有孩子的时候将左边界换为当前值。
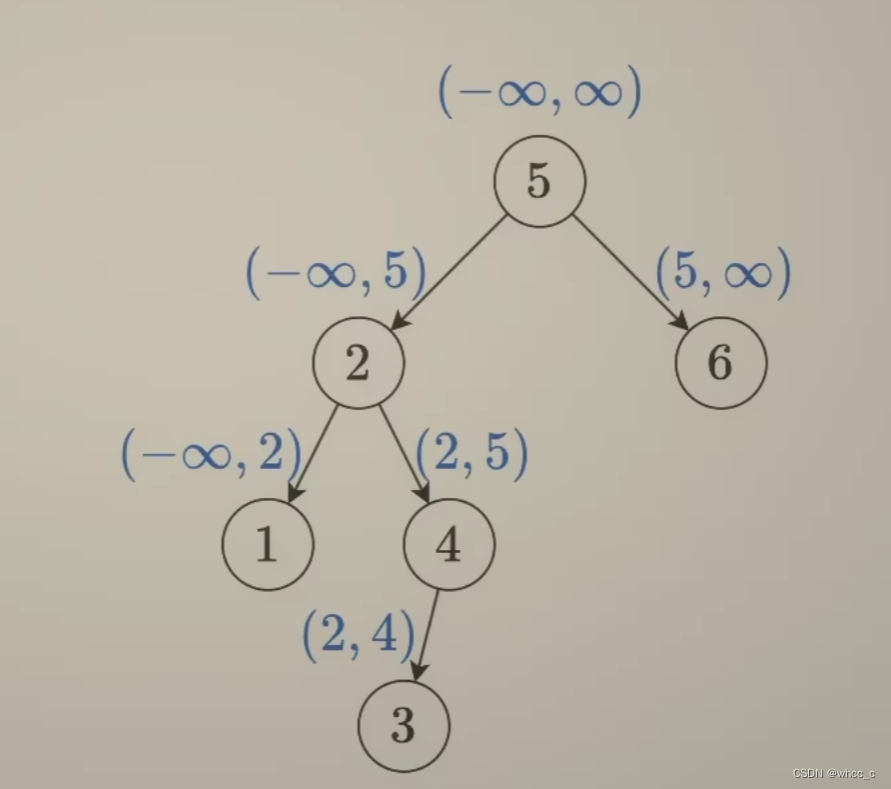
① 返回值为 0或1,传入参数为根节点和左右孩子值作为一个区间左右值
② 终止条件:如果当前结点为空,返回1,如果当前结点的val不在区间中,返回0
③ 依次递归左右孩子即可。
class Solution {
public:
bool isValidBST(TreeNode* root,long left = LONG_MIN,long right = LONG_MAX) {
if(!root) return 1;
long x = root->val;
return left < x&&x<right &&isValidBST(root->left,left,x)&&isValidBST(root->right,x,right);
}
};也可以采用中序遍历,这里使用了一种类似双指针的方法:用一个指针pre记录当前指针cur的前一个,然后根据中序遍历的特点比较cur的val与pre的val即可。
这里满足三个条件才可以说是一棵二叉搜索树,所以说不能isValidBST(cur->left)返回True了,就直接返回True。只有左中判断完了,最后右如果也满足才可以返回True.
class Solution {
public:
TreeNode * pre = NULL;
bool isValidBST(TreeNode* cur) {
if(!cur) return 1;
if(!isValidBST(cur->left)) return 0;
if(pre && cur->val <= pre->val) return 0;
pre = cur;
return isValidBST(cur->right);
}
};这里解释一下如何理解pre指针。以下图为例:采用中序遍历,到第一个结点会先进入递归左子树的函数,还遇不到pre那一行。等到了1结点以后,由于pre为空,所以不会比较cur与pre,程序再往下走就是pre = cur了。这时候pre已经指向了1结点。左右子树都为空,所以从1回溯到5是True。5的左递归走完就到比较当前结点了(因为是中序遍历),这时候比较的是1与5的大小了。此时满足条件:5>1,然后pre = 5,然后cur会右递归再一直左递归到3,然后比较pre与cur .此时pre = 5,cur = 3,不满足条件,返回False。
为什么 if(pre && cur->val <= pre->val) return 0; 放在pre = cur;上面呢?首先pre得不为空才可以比较与cur的值,所以pre一定要与cur->val <= pre->val放在一起。然后一定是先比较两个指针的值再移动指针。要不然就是自己与自己比较了。
二叉搜索树中的搜索
① 可以用返回值为void 去全局搜,相当于无视二叉搜索树的条件,当成普通树去搜。显示是可以的。
class Solution {
public:
TreeNode* rt = NULL;
void dfs(TreeNode* root, int val)
{
if(!root) return ;
if(root->val == val)
rt = root;
dfs(root->left,val);
dfs(root->right,val);
}
TreeNode* searchBST(TreeNode* root, int val) {
dfs(root,val);
return rt;
}
};② 也可以按照返回值是结点的方式去搜:根据二叉搜索树的性质:根节点的值大于左孩子的值,小于右孩子的值。所以先比较根节点,然后搜左右就行了。相当于是先序遍历。
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if(!root) return root;
if(root->val == val ) return root;
else if( root->val > val) return searchBST(root->left,val);
else return searchBST(root->right,val);
}
};二叉搜索树的最小绝对差
① 如果按照int返回,空结点感觉不是很好处理。所以这题我们用void返回全局搜就行了。
②遇到空结点就返回。
③ 按照中序遍历,每次记录更新pre跟cur的差的最小值就行了。
class Solution {
public:
TreeNode * pre = nullptr;
int ans = INT_MAX;
void dfs(TreeNode * cur)
{
if(!cur) return ;
dfs(cur -> left);
if(pre)
ans = min(ans,abs(cur->val-pre->val));
pre = cur;
dfs(cur->right);
}
int getMinimumDifference(TreeNode* root) {
dfs(root);
return ans;
}
};二叉搜索树中的众数
最直观的做法是不是直接中序遍历出有序数组然后找众数呢?但是我们可以用双指针的办法判断前一个数与后一个树是否相等,这样也可以。
① 由于是整个树上找,不是局部性质,所以用返回值void搜就行了。
② 遇到空结点直接返回就行了。
③ 如果pre->val 跟cur->val 相等的话,当前计数器++,如果不相等的话,计数器变1。然后更新一下最大值就行了。
发现了吗? 一般二叉搜素树中用双指针的话pre = cur 都是写在中间结点逻辑处理完以后的。
class Solution {
public:
TreeNode * pre = nullptr;
vector<int> ans;
int max_count = INT_MIN;
int cur_count = 1;
void dfs(TreeNode* root)
{
if(!root) return ;
dfs(root->left);
if(pre && pre->val == root->val)
cur_count += 1 ;
else cur_count = 1;
if(cur_count > max_count)
{
max_count = cur_count;
ans.clear();
ans.push_back(root->val);
}
else if( cur_count == max_count)
ans.push_back(root->val);
pre = root;
dfs(root->right);
}
vector<int> findMode(TreeNode* root) {
dfs(root);
return ans;
}
};二叉树中的双指针法写法总结:
前序:
void dfs(TreeNode * root)
{
if(!root) return ;
ans.push_back(root->val);
***********逻辑代码*************
if(pre)
cout <<"pre:"<<pre->val <<"cur:"<<root->val<<endl;
pre = root;
dfs(root->left);
dfs(root->right);
}
中序:
void dfs(TreeNode* root)
{
if(root)
{
dfs(root->left);
vec.push_back(root->val);
***********逻辑代码*************
if(pre)
cout<<"pre:"<<pre->val<<"cur:"<<root->val<<endl;
pre = root;
dfs(root->right);
}
}
后序:
void dfs(TreeNode* root)
{
if(!root) return ;
dfs(root->left);
dfs(root->right);
***********逻辑代码*************
if(pre)
cout<<"pre:"<<pre->val<<"cur:"<<root->val<<endl;
ans.push_back(root->val);
pre = root;
}二叉树公共祖先问题
236. 二叉树的最近公共祖先
最直观的想法是:从两个结点出发,一直向上找,两个分支第一次相遇的结点就是最近的公共祖先。但是如何实现二叉树自下而上的寻找呢?回溯的过程就是二叉树自下而上的过程。
补充一个总结:

最近公共祖先问题要对递归回溯的结果做一个总的判断:

① 我们可以用TreeNode* 作返回值,传入参数就是三个结点值。
②当遇到空结点时,返回空,当遇到当前结点等于p或者q的时候,说明已经找到了最近公共祖先了。直接然后root即可。
③采用后序遍历,先左后右,利用两个遍历接收。最后做逻辑处理。这种方式还是会遍历整棵树。对于根节点来说,如果答案已经在左子树,由于是后序遍历,右子树也需要遍历完才可以判断结果。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == p || root == q || !root) return root;
auto leftT = lowestCommonAncestor(root->left,p,q);
auto rightT = lowestCommonAncestor(root->right,p,q);
if(leftT && rightT) return root;
else if (!leftT) return rightT;
return leftT;
}
};图示如下:
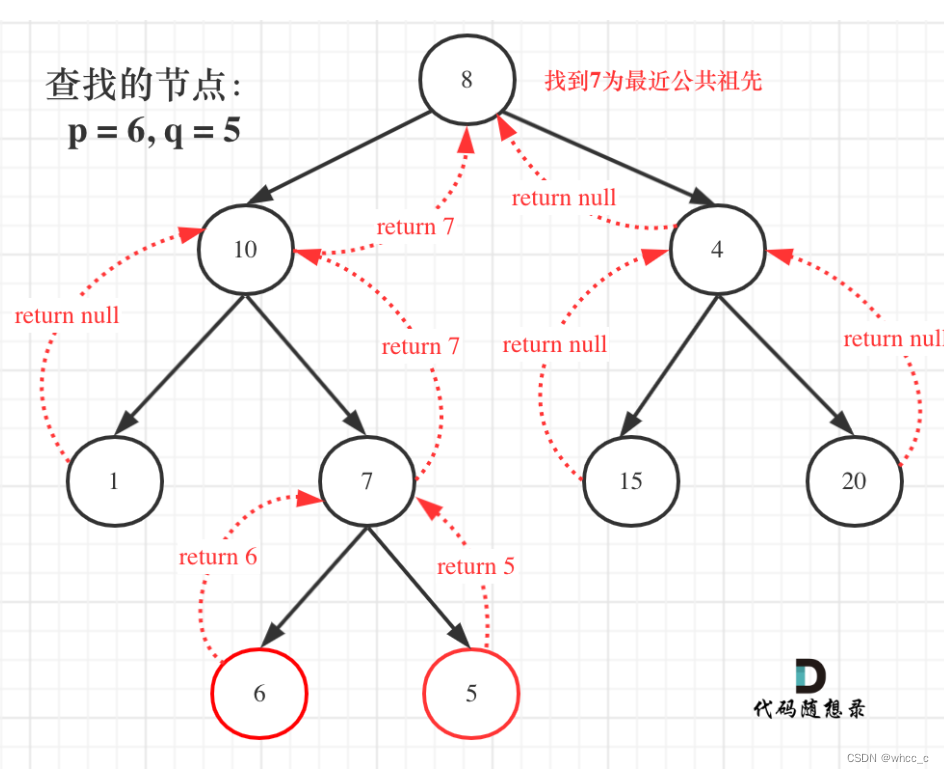
总结:后序遍历更像是把遍历完所有情况再做判断。这题中具体表现为:遍历完所有情况以后将结果一级一级向上返回。
二叉搜索树中的最近公共祖先
由于二叉搜索树的特性:左<中<右,我们可以利用这个性质直接去完成。
这里不用定义两个变量去接受返回值,这里是搜索一条边的写法。
class Solution {
public:
TreeNode* dfs(TreeNode* root,TreeNode *p,TreeNode* q)
{
if(!root) return NULL;
if(root->val > p->val && root->val <q->val)
return root;
if(root->val > p->val &&root->val >q->val)
return dfs(root->left,p,q);
if(root->val <p->val && root->val <q->val)
return dfs(root->right,p,q);
return root;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
return dfs(root,p,q);
}
};二叉搜索树的修改与构造
二叉搜索树中的插入操作
插入操作可以不用想的那么麻烦,按照二叉搜索树的规则一直去比较左右大小然后递归下去,遇到空结点直接插入就行了。
如果返回值是void的话,只需要记录下父节点就行。怎么记录呢?还是用上面的模板就行了。
如果想记录上一个结点的话,用双指针就行了。
class Solution {
public:
TreeNode * pre = NULL;
bool flag = 0;
void dfs(TreeNode* &root,int val)
{
if(flag) return ;
if(!root)
{
TreeNode * t = new TreeNode(val);
if(pre->val >val) pre->left = t;
else pre->right = t;
flag = 1;
return ;
}
pre = root;
if(root->val > val)
dfs(root->left,val);
if(root->val < val)
dfs(root->right,val);
}
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(!root)
{
TreeNode * root = new TreeNode(val);
return root;
}
dfs(root,val);
return root;
}
};返回值是TreeNode* 的写法:
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(!root)
{
auto t = new TreeNode(val);
return t;
}
if(root->val > val) root->left = insertIntoBST(root->left,val);
else if(root->val < val)root->right = insertIntoBST(root->right,val);
return root;
}
};总之,二叉搜索树的插入还是很简单的,一句话:找到空位去插就行了,这种方法得到的一定是符合题意的。但是二叉搜索树的删除就很难了。
删除二叉搜索树中的结点
直接按结点返回即可,利用二叉搜索树的性质。
主要是要分类讨论一下删除后的情况:
- 如果是空结点,返回空即可。
- 如果不是空结点,要判断当前结点值是否与key相等
- 如果相等:
- 该结点是是叶子结点:直接返回NULL即可
- 如果该结点只有左孩子:直接返回右孩子即可
- 如果该结点只有右孩子:直接返回左孩子即可
- 如果该结点有左右孩子,需要把左孩子放到右孩子的最左孩子上,再将右孩子返回
- 如果不相等:继续递归左右孩子即可
- 如果相等:
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if(!root) return root;
if(root->val == key)
{
if(root->left == nullptr&& root->right == nullptr)
{
delete root;
return nullptr;
}
else if(root->left == nullptr)
{
auto t = root->right;
delete root;
return t;
}
else if(root->right == nullptr)
{
auto t = root->left;
delete root;
return t;
}
else
{
auto t = root->right;
while(t->left) t = t->left;
t->left = root -> left;
auto temp = root;
root = root->right;
delete temp;
return root;
}
}
if(root->val > key) root -> left = deleteNode(root->left,key);
if(root->val < key) root -> right = deleteNode(root->right,key);
return root;
}
};修剪二叉搜索树
可以用常规思路:删除结点的做法。但一定要注意用后序遍历!!!即最后处理根结点。要不然根节点不满足直接删了,后面递归左右结点,根结点都没有了怎么递归呢?
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if(!root) return root;
root->left = trimBST(root->left,low,high);
root->right = trimBST(root->right,low,high);
if(root->val >high || root->val < low)
{
if(!root->left && !root->right) return nullptr;
else if(!root->left) return root->right;
else if(!root->right) return root->left;
else
{
auto t = root->right;
while(t->left) t = t->left;
t->left = root->left;
return root->right;
}
}
return root;
}
};为什么上一题是先序遍历? 其实也不算先序遍历。先序是无脑先中间再左再右。二叉搜索树是每次根据节点值只会搜左边或者右边。
也可以这样想:不满足的结点直接移除,返回后面的结点就行了。
如果当前结点值小于low,则接入右孩子满足的值。>high同理
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr) return nullptr;
if (root->val < low) return trimBST(root->right, low, high);
if (root->val > high) return trimBST(root->left, low, high);
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};看上去有点抽象,其实也不算删除结点,而是选择结点。也是根据二叉搜索树的性质:
low = 1, high = 2,当前结点为3,递归进入左子树,最后左子树都满足,返回的是1为根的子树,4都不会走,直接结束了。所以返回的就是1为根的子树。
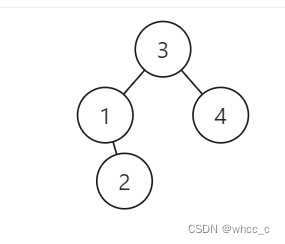
将有序数组转换为二叉搜索树
区间构造树是有模板的。按照前面的模板来就行了。
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
if(!nums.size()) return nullptr;
if(nums.size() == 1) return new TreeNode(nums[0]);
int val = nums[nums.size()/2];
auto t = new TreeNode(val);
vector<int> L(nums.begin(),nums.begin()+nums.size()/2);
vector<int> R(nums.begin()+nums.size()/2+1,nums.end());
t->left = sortedArrayToBST(L);
t->right = sortedArrayToBST(R);
return t;
}
};把二叉搜索树转化成累加树
其实能看图看出:从最右结点一直累加结点值。
class Solution {
public:
int sum;
void dfs(TreeNode * root)
{
if(!root) return ;
dfs(root->right);
sum+=root->val;
root->val = sum;
dfs(root->left);
}
TreeNode* convertBST(TreeNode* root) {
dfs(root);
return root;
}
};补充: 如果将答案集合定义在全局:那么在全局中,那每次dfs之后都要记得回溯,即恢复到没有搜那个点的状态。但是如果定义在函数中就不用回溯,系统栈自动帮你回溯了。前提是不要用引用参数(&)。















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









