









本次数学建模第二小问让我们探究玻璃分类的规律。而看到分类,我便想起了最近在学习机器学习,正好讲到了逻辑回归,正好可以解决这个分类问题,我便顺理成章的去深入了解了一下这个算法。
一,逻辑回归的原理
关于逻辑回归的原理,我去翻阅了博客,找到了算法原理和部分代码,在这我就不写了:
二,数据处理
我们要求的是sigmoid函数的多维形式:
我们要求根据训练样本来求参数w了。怎么求解的,上面的博客讲解的很清楚,再此我重点讲解一下我解题的思路。
先用WPS或excel将空缺值处理补0,然后转化成csv格式(个人习惯),但要在JupyterLab上运行必须用记事本打开另存为UTF-8格式。
为了给机器留有训练数据,我们先将人工分类数据,既将高钾(记为1)和铅钡(记为0)分开,然后进行机器学习的训练。
至于怎么选择特征,emmm,当时由于没有想那么多,根据第一问的数据分析,我们只将二氧化硅(SiO2)作为分类的唯一标准,而验证灵敏度时,我们额外增加其他特征,来观察最终的分类结果,从而来判断我们用的这个逻辑回归是否合理。(个人感觉有些牵强,但是由于时间有限,就只能想这么多)
但我个人觉得这样做过于主观了,在比完赛后我去翻阅了一下西瓜书,发现可以用其他办法进行机器的自动分类,这个我们先不说。
三,代码求解
再优秀的理论都要用实验来检验,当时比赛的时候偷懒了,用spsspro直接分析,但是身为优秀的当代大学生,必须亲身实践,才能有所收获。接下来我将用python一步一步的来实现我们想要的结果。
import numpy as np
import pandas as pd
def loaddata(filename):
file=open(filename)
x=[]
y=[]
for line in file.readlines():
line=line.strip().split()
x.append([1,float(line[0]),float(line[1])])
y.append(float(line[-1]))
xmat=np.mat(x)
ymat=np.mat(y).T
file.close()
return xmat,ymat
def w_calc(xmat,ymat,alpha=0.001,maxlter=1000):
w=np.mat(np.random.randn(3,1))
w_save=[]
for i in range(maxlter):
H = 1/(1+np.exp(-xmat*w))
dw=xmat.T*(H-ymat)
w-=alpha*dw
if i%100==0:
w_save.append([w.copy(),i])
return w,w_save
loaddata函数是将数据转化成矩阵形式。
w_calc函数是关键的训练过程
xmat,ymat=loaddata('./b.txt')
print('xmat:',xmat,xmat.shape)
print('ymat:',ymat,ymat.shape)
w,w_save=w_calc(xmat,ymat,0.001,1000)
print("w:",w)这是转化成的矩阵列表:

🆗,这下就很直观的显示了数据的分布情况了,接下来我们就来找一条线将这个数据集分成两个部分了。
#展示
import warnings
warnings.filterwarnings('ignore')
for wi in w_save:
plt.clf()
w0 = wi[0][0,0]
w1 = wi[0][1,0]
w2 = wi[0][2,0]
plotx1=np.arange(0,100,1)
plotx2=-w0/w2-w1/w2*plotx1
plt.plot(plotx1,c='r',label='decision boundary')
plt.scatter(xmat[:,1][ymat==0].A,xmat[:,2][ymat==0].A,marker='^',s=150,label='label=0')
plt.scatter(xmat[:,1][ymat==1].A,xmat[:,2][ymat==1].A,s=150,label='label=1')
plt.grid()
plt.legend()
plt.title('iter:%s'%np.str(wi[1]))
plt.pause(0.001)
plt.show()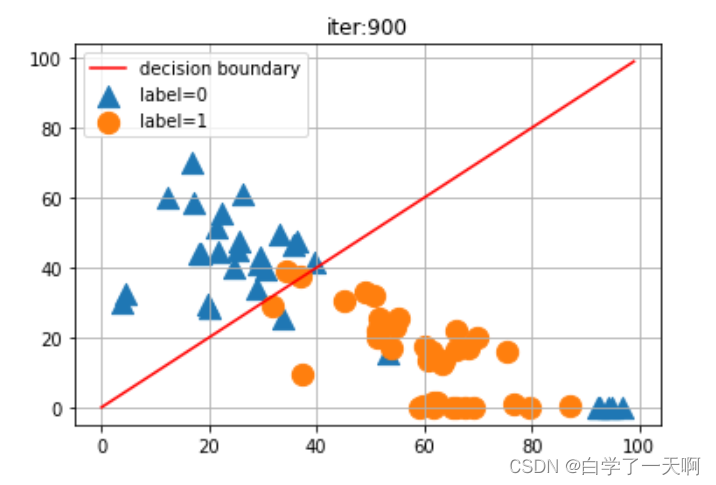
这是经过第九百次训练后给出的分割直线。
最后再来看一下这个直线的数据:
print('常数项:',-w0/w2)
print('x矩阵系数:',-w1/w2)
常数项: 7.2342027714137735
x矩阵系数: 0.1878059625463007
代码讲解我是参考b站上的视频:
这下我们就完成初步的训练阶段。接下来几篇我们将讨论如何去使用我们的训练模型,以及更细致的讲解分类过程,以及我个人的思路。















 2889
2889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









