






文章目录
简介
PR曲线
PR原理
PR曲线的绘制
分析
ROC曲线
ROC原理
ROC曲线的绘制
分析
实验总结
简介:
机器学习建模中,模型评估指标用于评估不同模型的优劣。模型在训练集上的误差通常称为 训练误差 或 经验误差,而在新样本上的误差称为 泛化误差。为了得到泛化误差小的模型,在构建机器模型时,通常将数据集拆分为相互独立的训练数据集、验证数据集和测试数据集等,
ROC曲线和PR曲线是机器学习中两个常见的评估指标,在评价一个检测模型时通常需要绘制出其 ROC 曲线或 PR 曲线。只要我们有数据和模型,得到数据阀值,我们就可以在python中绘 制出我们的ROC和PR曲线。
PR曲线
原理:
PR曲线实则是以precision(精确率)和recall(召回率)这两个为变量而做出的一种评估二分类模型性能的曲线,以recall(召回率)为横坐标,precision(精确率)为纵坐标,反映了准确率随查全率的变化趋势。PR曲线常被用在信息提取领域,当我们的数据集中类别分布不均衡时我们可以用PR曲线代替ROC。
什么是精确率什么是召回率?
准确率(Accuracy)准确率是指分类正确的样本占总样本个数的比例。
精确率(recision,也叫查准率)表示预测为正例的样本中真正为正例的比例
召回率(recall,也叫查全率)表示所有真正实例中被正确预测为正例的比率
混淆矩阵

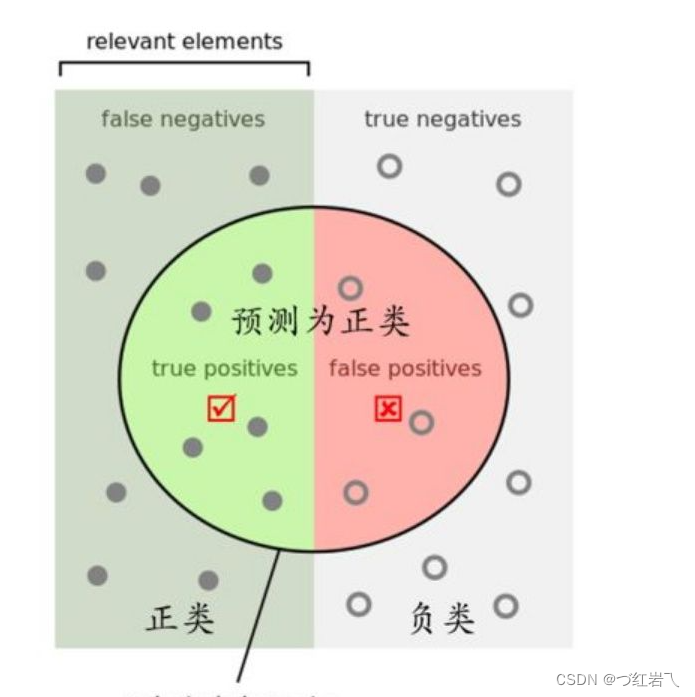
精确率
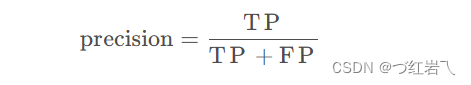
召回率
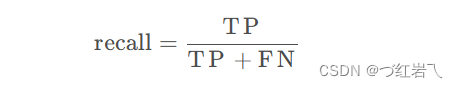
精确率和召回率的关系:
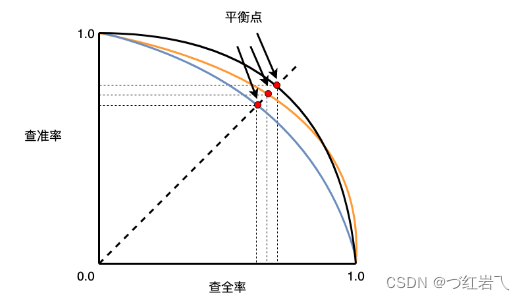
如上如所示,当PR曲线越靠近右上方时,表明模型性能越好,不同模型进行比较时,若一个模型的PR曲线被另一个模型的PR曲线完全包住则说明后者的性能优于前者。模型的PR曲线发生了交叉,则无法直接判断哪个模型更好。
PR曲线的绘制
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
#生成实例数据
#处理数据时经常需要从数组中随机抽取元素,这时候就需要用到np.random.choice()。
#numpy.random.choice(a, size=None, replace=True, p=None)
#从a(只要是ndarray都可以,但必须是一维的)中随机抽取数字,并组成指定大小(size)的数组
x = np.random.choice(2,size=1000,p=[0.7,0.3])
y = np.random.rand(1000)
#cumsum的作用主要就是计算轴向的累加和,根据公式计算Precision和Recall
TP = np.cumsum(x == 1 )
FP = np.cumsum(x == 0 )
precision = TP/(TP+FP)
recall = TP/np.sum(x)
# 绘制PR曲线
plt.xlabel(x)
plt.ylabel(y)
plt.xlabel('查全率(R)')
plt.ylabel('查准率(P)')
plt.plot(recall, precision, marker='.')
plt.grid(True)
plt.show()
plot(recall, precision)
# 积分计算平均精确度,设z = 0,通过二维面积法,下图有详解用法;
#def plot(recall, precision):
#z = 0
#for i in range(len(recall)-1):
#z += (recall[i+1] - recall[i]) * precision[i+1]
#plt.title('Average Precision: {:.3f}'.format(z))
分析:
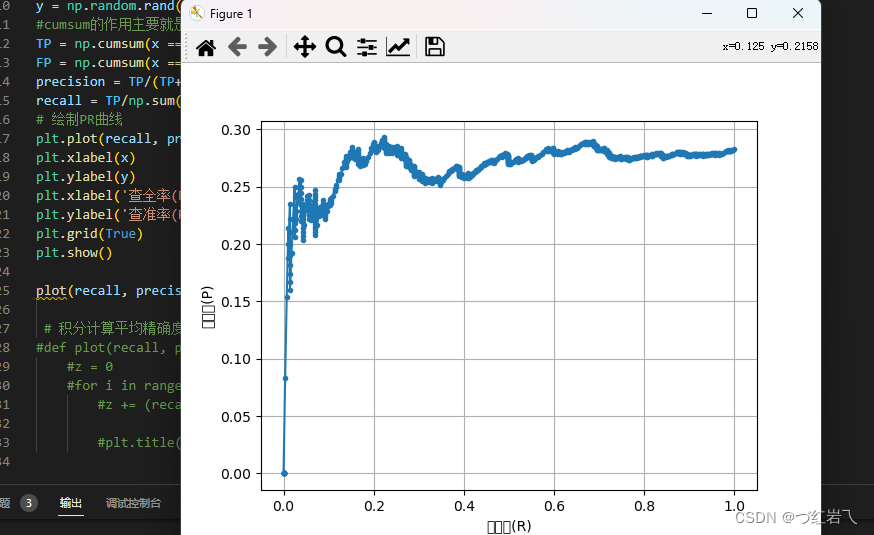
ROC曲线
原理:
在衡量学习器的泛化性能时,根据学习器的预测结果对样本排序,按此顺序逐个把样本作为正例进行输出,每次计算测试样本的真正率TPR,和假正率FPR并把这两项作为ROC的纵轴和横轴.
真正率(True Postive Rate)衡量实际值为正例的样本中被正确预测为正例的样本的比例
假正率(False Postive Rate)表示实际值为负例的样本中被错误的预测为正例的样本的比例

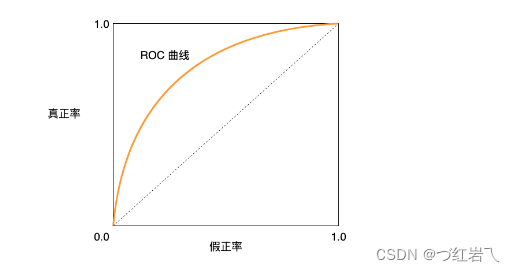
如上图所示,当ROC曲线接近于(1,0)点,表明模型泛化性能越好,越接近对角线的时候,表明此时模型的预测结果为随机预测结果。但此只是理想模型,在实际中ROC曲线没有这么光滑。
AUC (Area under Curve):ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好
ROC曲线的绘制
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
# auc的输入为很简单,就是fpr, tpr值
auc = metrics.auc(fpr, tpr)
#画图
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange',
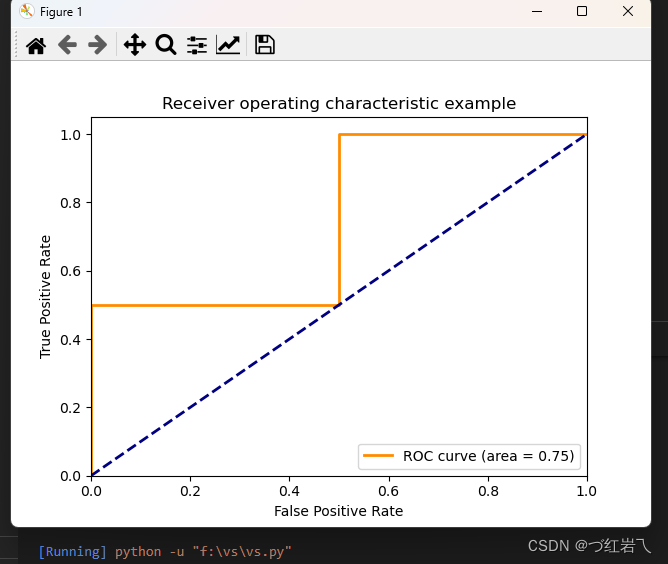
lw=lw, label='ROC curve (area = %0.2f)' % auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
分析:
多模型对比ROC绘制
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.model_selection import train_test_split
# 生成样本数据
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化分类器
classifiers = [
('Logistic Regression', LogisticRegression()),
('Decision Tree', DecisionTreeClassifier()),
('Random Forest', RandomForestClassifier())
]
# 遍历每个分类器,训练并绘制ROC曲线
for name, classifier in classifiers:
classifier.fit(X_train, y_train)
y_pred_proba = classifier.predict_proba(X_test)[:,1]
fpr, tpr, _ = roc_curve(y_test, y_pred_proba)
auc = roc_auc_score(y_test, y_pred_proba)
plt.plot(fpr, tpr, label=f'{name} (AUC = {auc:.2f})')
# 绘制基准线
plt.plot([0, 1], [0, 1], 'k--', label='Random Guess')
# 设置图例、标题、坐标轴标签等信息
plt.legend()
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
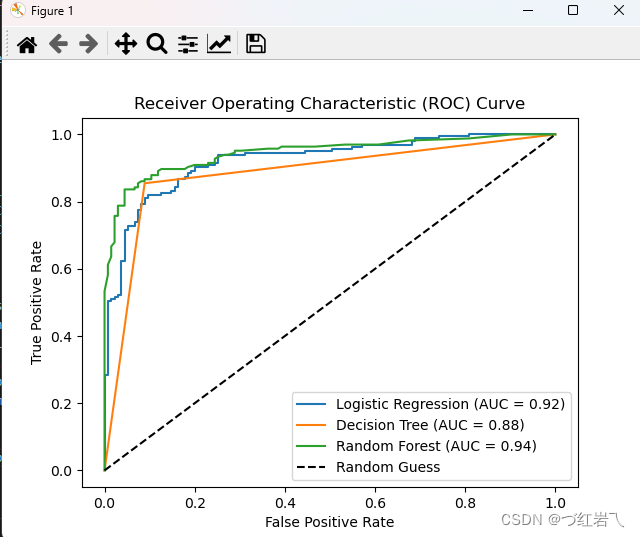
分析:
对于一条凸型ROC曲线来说,曲线越靠近左上角越好,越往下越糟糕,曲线 如果在虚线的下方,则证明模型完全无法使用。但是它也有可能是一条凹形的ROC曲线。对于一条凹型ROC曲线来 说,应该越靠近右下角越好,凹形曲线代表模型的预测结果与真实情况完全相反。
ROC曲线原理和代码演示_roc曲线评价模型代码-CSDN博客
此篇有完整的实现绘制过程,包含:
1. ,导入库,加载数据集
2.定义绘制模型拟合数据的效果图函数
3.训练模型
4.评估模型
5.绘制ROC
实验总结
-
PR曲线:当数据集类别分布非常不均衡的时候采用PR曲线
-
ROC曲线:主要应用于测试集中的样本分布的较为均匀的情况,且当测试集中的正负样本的分布变化的时候
PR曲线的纵轴,即查准率的分母,即预测为正例的数目会不断增大,而分子TP有上限,所以其会迅速下降,意味着模型性能迅速变差,可以体现类别不均衡对模型产生的影响。如果想要评估在相同的类别分布下正例的预测情况,PR曲线比较合适。PR曲线常被用在信息提取领域,当我们的数据集中类别分布不均衡时我们可以用PR曲线代替ROC。
而ROC曲线中横轴是在负例基础上计算,纵轴是在正例基础上计算,二者分母是不变的,分子在都在不断增加(和类别均衡时没有特别大的差异),没有很好地体现出样本类别分布不平衡对模型产生的影响,甚至导致对模型性能有错误的解释,因此此时不适用评估单个模型是好是坏。由于兼顾正例与负例,所以适用于评估分类器的整体性能。ROC曲线更适用于评估不同分类器的整体性能,ROC曲线还可以通过计算AUC值来综合评价分类器的性能。
过拟合
当学习器把训练样本学的“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降,这种现象称为过拟合。具体表现就是最终模型在训练集上效果好;在测试集上效果差。模型泛化能力弱。
过拟合的原因:
- 训练数据中噪音干扰过大,使得学习器认为部分噪音是特征从而扰乱学习规则。
- 建模样本选取有误,例如训练数据太少,抽样方法错误,样本label错误等,导致样本不能代表整体。
- 模型不合理,或假设成立的条件与实际不符。
- 特征维度/参数太多,导致模型复杂度太高。
过拟合的解决办法:
数据增强; 通过一定规则扩充数据;保留验证集;获取额外数据进行交叉验证;降低模型复杂度;增加噪音等
欠拟合
欠拟合是指对训练样本的一般性质尚未学好。在训练集及测试集上的表现都不好。
欠拟合的原因
1.模型复杂度过低
2.特征量过少
欠拟合的解决办法
减小正则化系数;增加模型复杂度;增加特征数等















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









