






评估分类模型性能是机器学习研究中的一个重要课题,在本文中,将着重讨论ROC曲线和PR曲线这两个常用的评估指标,介绍它们的原理和应用方法,并说明如何使用这些指标进行性能分析和比较。
一、选择数据集
1.读取数据集
这里使用 Scikit-learn 的 make_classification() 函数生成了一个人工分类数据集,其中包含 1000 个样本和 10 个特征,test_size=0.2表示将数据集中的 20% 作为测试集。
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 生成分类问题数据集
X, y = make_classification(n_samples=1000, n_features=10, random_state=10)
# 将数据集划分为训练集和测试集
train_features, test_features, train_labels, test_labels = train_test_split(X, y, test_size=0.2, random_state=10)
print("训练集特征:", train_features)
print("训练集标签:", train_labels)
打印数据集
2.进行分类
使用sklearn库中的已实现的knn进行分类
from sklearn.neighbors import KNeighborsClassifier
# 创建KNN分类器对象
clf = KNeighborsClassifier(n_neighbors=5)
# 使用训练数据集进行模型训练
clf.fit(train_features, train_labels)
# 使用测试数据集进行预测
y_hat = clf.predict_proba(test_features)[:, 1]
print("预测值:",y_hat)
print("真实值:",test_labels)打印预测值和真实值
二、绘制ROC曲线、PR曲线
1.混淆矩阵
混淆矩阵是用于衡量分类模型性能的一种可视化工具,基于混淆矩阵,可以计算各种评估指标,如准确率、召回率、精确率,以进一步评估模型的性能和效果。
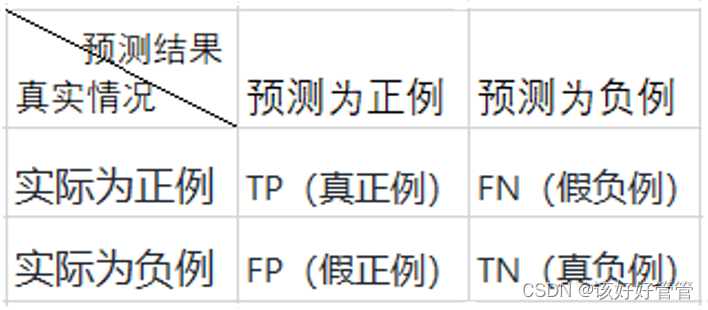
TP、FP、TN、FN是用于衡量二分类模型性能的四个基本指标:
TP(True Positive,真正例):表示实际为正例且被正确判定为正例的样本数量。
FP(False Positive,假正例):表示实际为负例但被错误判定为正例的样本数量。
TN(True Negative,真负例):表示实际为负例且被正确判定为负例的样本数量。
FN(False Negative,假负例):表示实际为正例但被错误判定为负例的样本数量。
2.ROC曲线
ROC曲线是一个由真阳率(TPR)和假阳率(FPR)组成的图形,在二分类问题中,模型根据观测数据将其分为正类和负类,并根据设定的阈值进行判断。对于不同的阈值,模型会得到一组TPR和FPR。其中,TPR也称为召回率,代表被正确判定为正例的样本比例,即TPR = TP / (TP + FN)。而FPR则代表被错误判定为正例的负例样本比例,即FPR = FP / (FP + TN)。
3.PR曲线
PR曲线是一个用于评估分类模型性能的指标。类似于ROC曲线,PR曲线也是描述分类模型在不同阈值下的性能表现的曲线。在二分类问题中,精确率表示被正确判定为正例的样本占所有被预测为正例的样本的比例,即Precision = TP / (TP + FP)。而召回率也称真阳率,则表示被正确判定为正例的样本占所有实际正例样本的比例,Recall = TP / (TP + FN)。
4.ROC曲线与PR曲线的区别
目标不同:ROC曲线关注真阳性率(TPR)和假阳性率(FPR)之间的权衡关系,而PR曲线关注查准率(Precision)和召回率(Recall)之间的权衡关系。
纵轴和横轴不同:ROC曲线的纵轴是TPR(召回率),横轴是FPR,而PR曲线的纵轴是Precision,横轴是Recall。
应用场景不同:ROC曲线适用于处理正负样本比例相差较大的问题,而PR曲线适用于处理正负样本比例接近的问题。
评估指标不同:根据ROC曲线可以计算AUC(Area Under the Curve),表示分类器在不同阈值下的性能综合。根据PR曲线可以计算平均准确率(Average Precision),表示分类器在召回率不同时的平均性能。
5.绘制ROC曲线和PR曲线
计算ROC曲线和PR曲线的数据点
# 计算ROC曲线和PR曲线的数据点
from sklearn.metrics import roc_curve, auc, precision_recall_curve, average_precision_score
fpr, tpr, thresholds = roc_curve(test_labels, y_hat)
roc_auc = auc(fpr, tpr)
precision, recall, thresholds = precision_recall_curve(test_labels, y_hat)
pr_avg = average_precision_score(test_labels, y_hat)
使用roc_curve函数计算ROC曲线的数据点,该函数接受真实标签test_labels和预测得分y_hat作为输入,并返回FPR、TPR和对应的阈值。同时,使用auc函数计算了ROC曲线的AUC值。AUC是评估二分类模型性能的常用指标之一,AUC就是ROC曲线下的面积。AUC的取值范围在0到1之间,越接近1表示模型性能越好,越接近0.5表示模型性能越差。
使用precision_recall_curve函数计算PR曲线的数据点,该函数同样接受真实标签test_labels和预测得分y_hat作为输入,并返回精确率、召回率和相应的阈值。使用average_precision_score函数计算平均准确率,值范围在0到1之间,越高表示模型性能越好。
6.绘制ROC曲线和PR曲线
# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.05])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
print("AUC:",roc_auc)
# 绘制PR曲线
plt.figure()
plt.step(recall, precision, color='darkorange', lw=2, where='post')
plt.plot([0, 1], [1, 0], color='navy', lw=2, linestyle='--')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.05])
plt.title('Precision-Recall curve')
plt.show()
print("avg:", pr_avg)其中,plt.figure() 创建一个新的图形窗口。
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})') 绘制ROC曲线。其中,fpr 和 tpr 分别代表假阳性率和真阳性率,即ROC曲线上的横纵坐标。曲线的颜色设定为橙色('darkorange'),线宽设定为2。同时,在标签中显示AUC的值,保留两位小数。
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') 绘制一条对角线。
plt.xlim([0.0, 1.05]) 和 plt.ylim([0.0, 1.05]) 分别设置x轴和y轴的取值范围为[0.0, 1.05]。
plt.xlabel('False Positive Rate') 和 plt.ylabel('True Positive Rate') 设置x轴和y轴的标签。
plt.title('Receiver Operating Characteristic') 设置图形的标题。
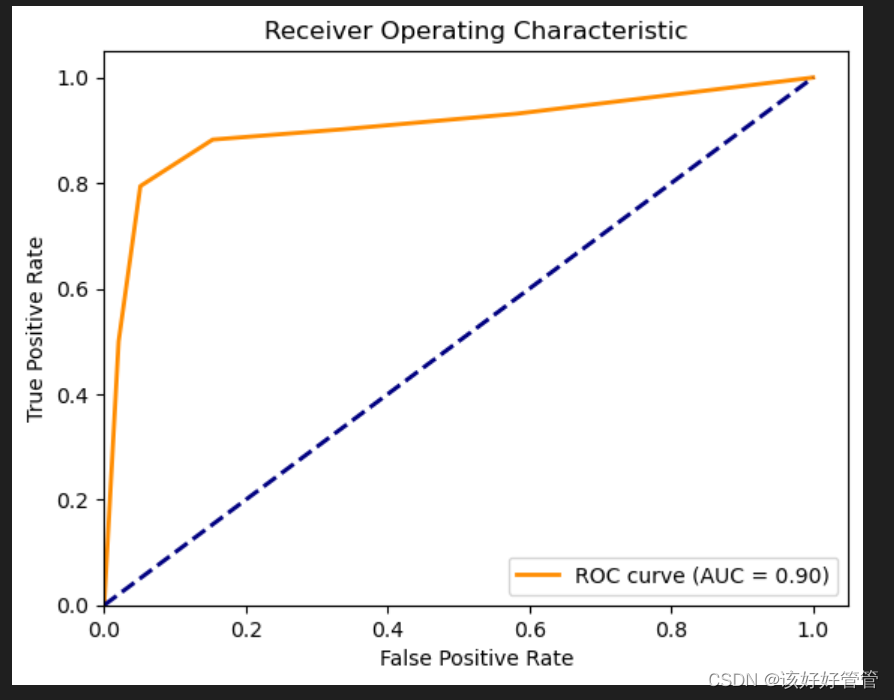
ROC曲线
PR曲线
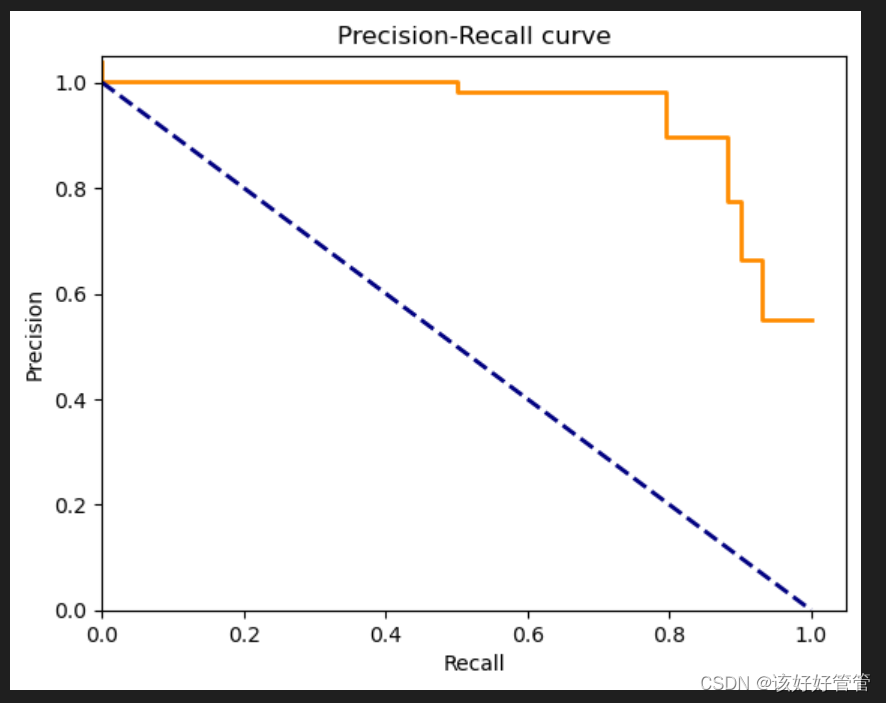

AUC值为0.9028表明该模型具有良好的分类能力,相对较高的真阳性率和较低的假阳性率。
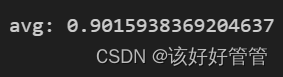
平均精度为0.9016表明该模型在处理二分类问题时具有较高的整体精度。
7.对不同的k值的knn进行比较
通过循环来遍历每个n_neighbors值并执行相应的操作
for n in n_neighbors_values:
clf = KNeighborsClassifier(n_neighbors=n)
clf.fit(train_features, train_labels)
y_hat = clf.predict_proba(test_features)[:, 1]
fpr, tpr, _ = roc_curve(test_labels, y_hat)
roc_auc = auc(fpr, tpr)
precision, recall, _ = precision_recall_curve(test_labels, y_hat)
pr_auc = average_precision_score(test_labels, y_hat)
plt.subplot(2, 1, 1)
plt.plot(fpr, tpr, lw=2, label=f'n_neighbors={n} (AUC = {roc_auc:.2f})')
plt.subplot(2, 1, 2)
plt.step(recall, precision, lw=2, where='post', label=f'n_neighbors={n} (AP = {pr_auc:.2f})')运行结果如下
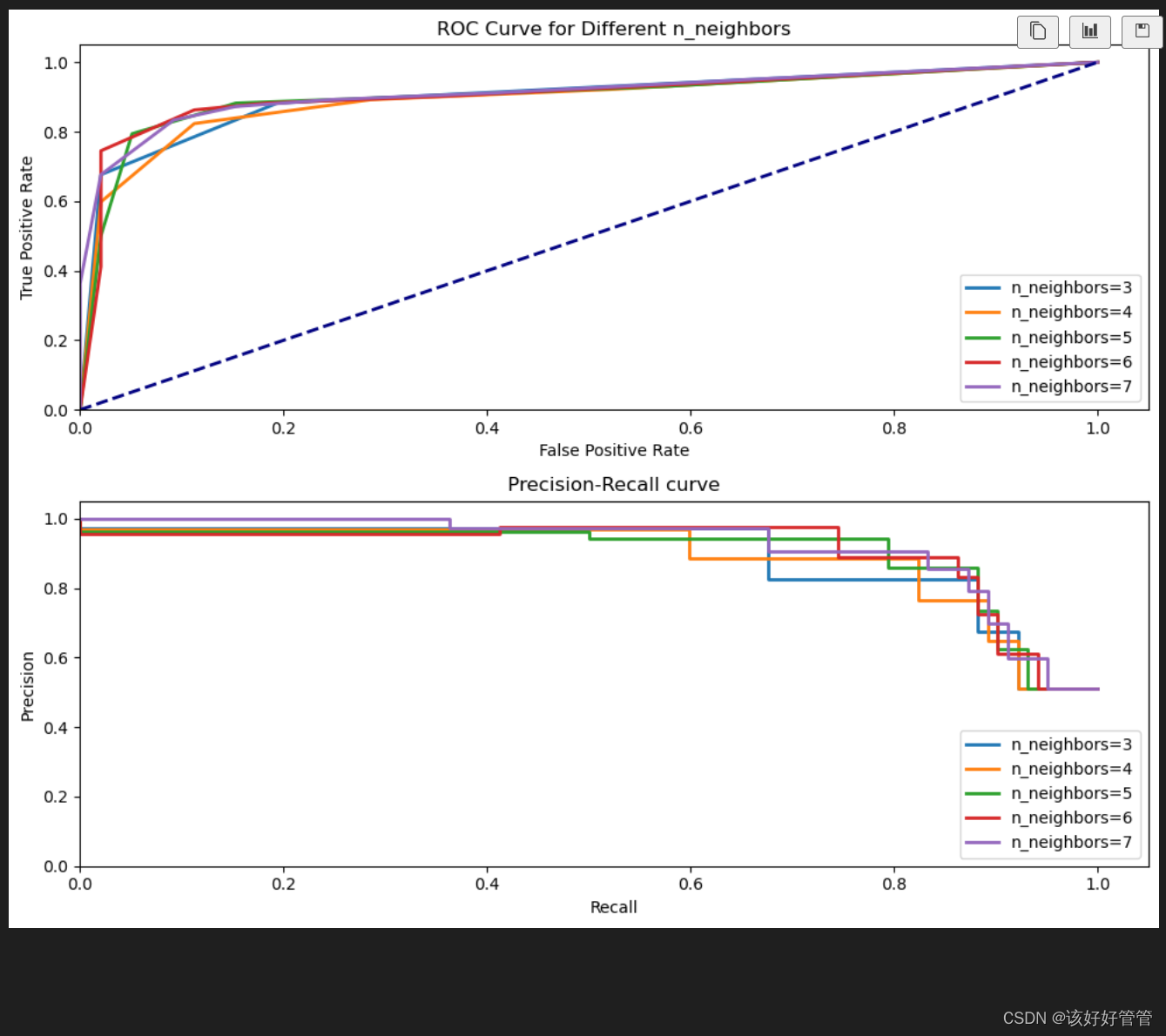

可以看出当n_neighbors=7时,AUC和Average Precision都达到最大值,说明KNN分类器对测试集进行分类效果非常稳定,分类结果的准确性较高。
三、总结
在本次实验中,探索了使用KNN模型对某个数据集进行分类的方法,将数据集分为训练集和测试集,使用KNN模型对测试集进行分类,并计算了AUC和Average Precision等性能指标。
通过实验,发现KNN模型在该数据集上具有较好的分类性能。接下来,进行了一些进一步的实验,调整K值,得出结论:当k=7时AUC与Average Precision最大,这意味着KNN模型在这个数据集上表现最佳。总之,这个实验增强了我对KNN模型的理解和掌握,并学习了如何绘制ROC和PR曲线。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









