









编译工具:PyCharm
一.数据清洗
转化数据类型、处理重复数据、处理缺失数据
import pandas as pd
df = pd.read_csv("/data.csv")
df.sample(10) # 用于随机获取数据并返回结果
df.head(10) # 查看前十条数据
df.tail(10) # 查看后十条数据
df.shape # 查看表格行列数
df.describe() # 查看数据的统计信息
df.dtypes # 查看每一列特征的数据类型
1.转换数据类型
pandas可以产生两种类型表格,DataFrame产生多行多列;Series产生多行单列的表格
# 转换数据类型
# pandas可以产生两种类型表格,DataFrame产生多行多列;Series产生多行单列的表格
import pandas as pd
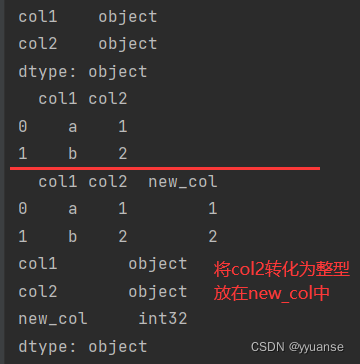
df = pd.DataFrame([{'col1': 'a', 'col2': '1'}, {'col1': 'b', 'col2': '2'}])
print(df.dtypes)
print(df)
# 将该列的数据类型转化为int类型
df['new_col'] = df['col2'].astype(int)
print(df)
print(df.dtypes)
print("---------Series创建多行单列表格--------")
# 多行单列表格
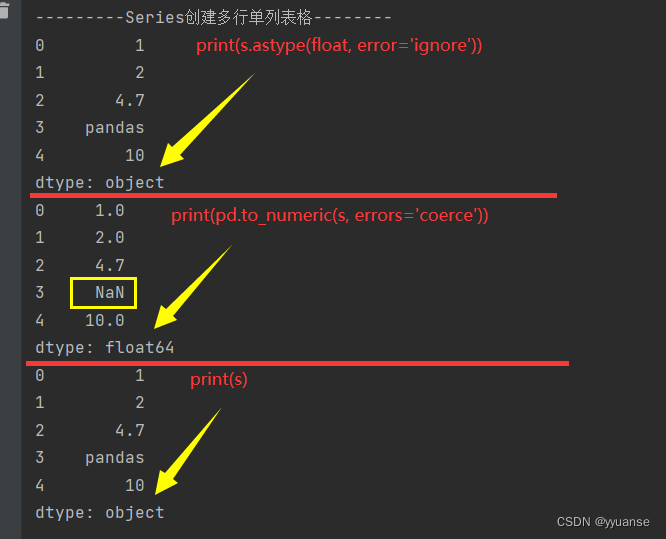
s = pd.Series(['1', '2', '4.7', 'pandas', '10'])
# 转化的时候忽略非法字符,缺点:忽略了但是数据依然存在,数据分析的时候会有问题
print(s.astype(float, errors='ignore'))
# 使用pd.to_numeric
print(pd.to_numeric(s, errors='coerce'))
print(s)
转换数据类型小练习
print("--------------------------------------------")
# 小练习:将下面的数据转成float类型,并且去掉'$'以及','
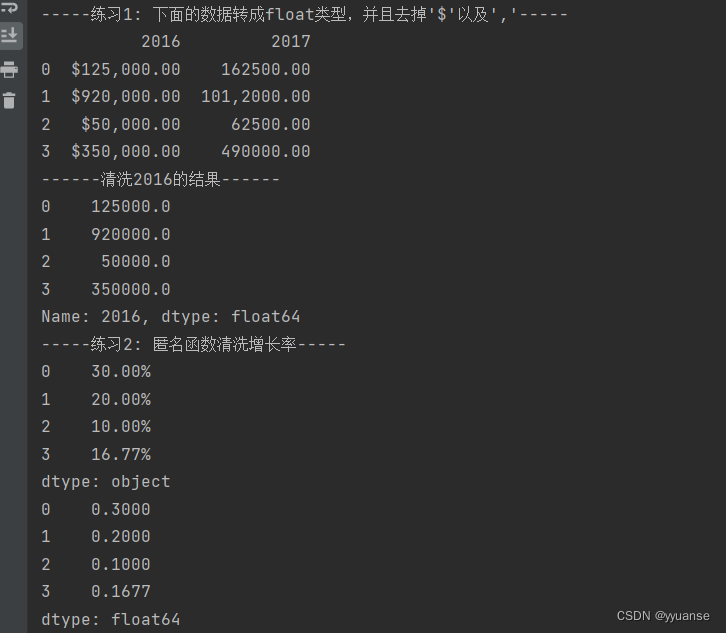
print("-----练习1: 下面的数据转成float类型,并且去掉'$'以及','-----")
df1 = pd.DataFrame([{'2016':'$125,000.00','2017':'162500.00'},
{'2016':'$920,000.00','2017':'101,2000.00'},
{'2016':'$50,000.00','2017':'62500.00'},
{'2016':'$350,000.00','2017':'490000.00'}])
print(df1)
# 定义函数
def convert_money(value):
new_value=value.replace("$","").replace(",","")
return float(new_value)
# 将'2016'这一列作为参数使用convert_money函数
print("------清洗2016的结果------")
print(df1['2016'].apply(convert_money))
# 匿名函数清洗增长率
print("-----练习2: 匿名函数清洗增长率-----")
df2 = pd.Series(['30.00%','20.00%','10.00%','16.77%'])
print(df2)
print(df2.apply(lambda x: float(x.replace("%","")) / 100 ))
# 将数据转换为浮点数类型
print("-----练习3: 数据转换为浮点数类型-----")
df3 = pd.Series(['500','700','125','175','Closed'])
# 注意是pandas.to_numeric而不是df3.to_numeric
print(pd.to_numeric(df3, errors='coerce'))
# 将原本数据用1或者0表示
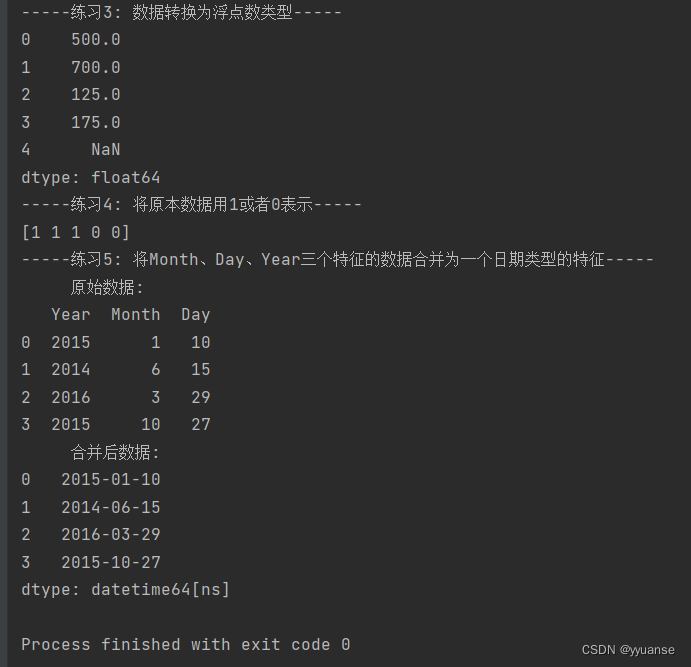
print("-----练习4: 将原本数据用1或者0表示-----")
df4 = pd.Series(['Y','Y','Y','N','N'])
# 需要引入numpy库内含许多数据运算函数
import numpy
print(numpy.where(df4 == 'Y', 1, 0))
# 将Month、Day、Year三个特征的数据合并为一个日期类型的特征
print("-----练习5: 将Month、Day、Year三个特征的数据合并为一个日期类型的特征-----")
df5 = pd.DataFrame([{'Year':2015,'Month': 1,'Day':10},
{'Year':2014,'Month': 6,'Day':15},
{'Year':2016,'Month': 3,'Day':29},
{'Year':2015,'Month': 10,'Day':27}])
print(" 原始数据:")
print(df5)
# 使用pandas库中自带的to_datetime
print(" 合并后数据:")
print(pd.to_datetime(df5[['Month', 'Day', 'Year']]))
相应的运行结果如下:
去除重复值小实验
# 小实验2,处理重复数据
print()
print("----------------------小实验2--------------------------")
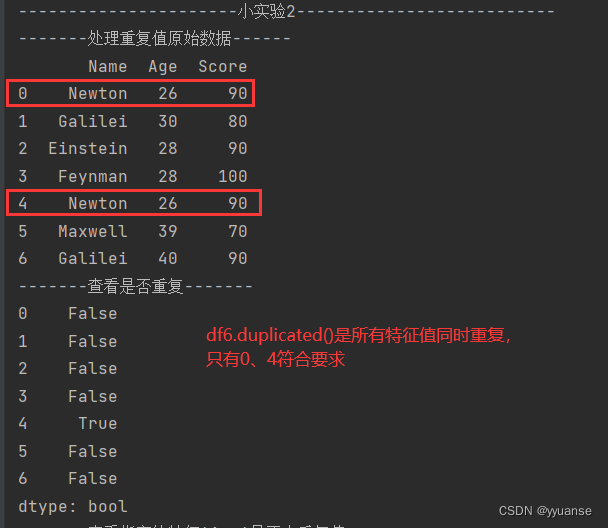
print("-------处理重复值原始数据------")
import pandas as pd
data = {
'Name':['Newton','Galilei','Einstein','Feynman','Newton','Maxwell','Galilei'],
'Age':[26,30,28,28,26,39,40],
'Score':[90,80,90,100,90,70,90]
}
df6 = pd.DataFrame(data,columns=['Name','Age','Score'])
print(df6)
print("-------查看是否重复,所有特征值都重复-------")
print(df6.duplicated())
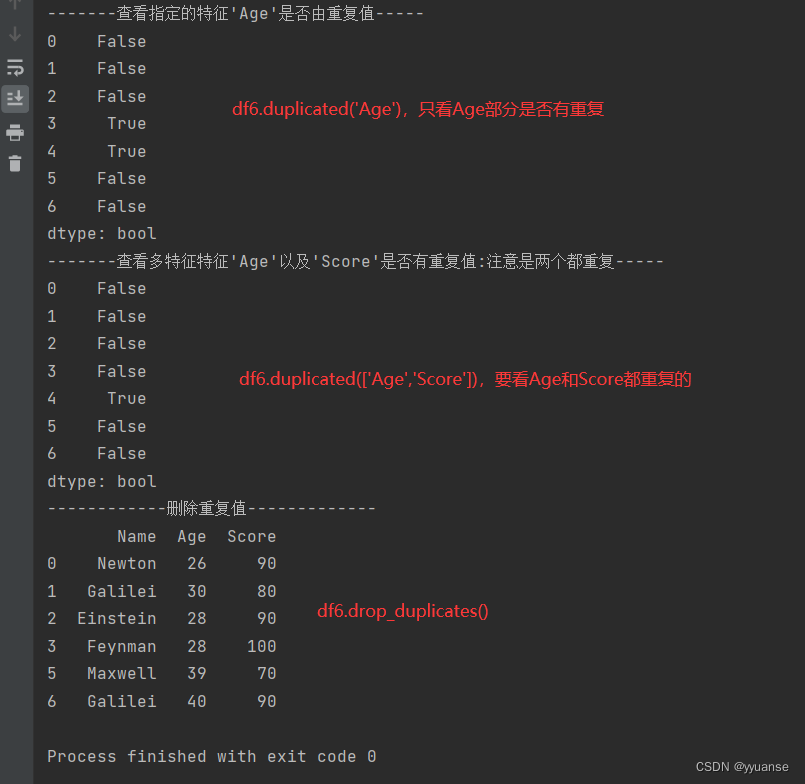
print("-------查看指定的当个特征'Age'是否由重复值-----")
print(df6.duplicated('Age'))
print("-------查看多特征特征'Age'以及'Score'是否有重复值:注意是两个都重复-----")
print(df6.duplicated(['Age','Score']))
print("------------删除重复值-------------")
new_df6 = df6.drop_duplicates()
print(new_df6)















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









